NLP实战之keras+LSTM进行京东评论情感分析python
情感分析
文本情感分析(Sentiment Analysis)是自然语言处理(NLP)中常见的也是很重要的一环,又称意见挖掘、倾向性分析等。它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。它包括情感分类(情感倾向分析)、情感检索、情感抽取等。
我们今天只来练一练情感分类。所谓情感分类,指的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“好评”和“差评”这两个词,就属于不同的情感倾向。与文本分类不同的是,情感分类不基于内容本身,而是基于文本持有的情感态度。
那么基于机器学习或是深度学习的情感分类方法的主要流程包括:数据处理——提取文本情感特征——构建分类器分类。下面我们将详细介绍如何使用深度学习模型中的LSTM模型来实现文本的情感分类。不想看我啰嗦的之间点这里下载数据和全部代码哦!
预分析数据
我们用到的语料是京东评论数据集,这里是数据啦~ 提取码:iu43。
首先我们来看一看数据,好评和差评的数据分别存储在两个Excel里,样式如下图:

其中好评样本有10677条,差评有10428条,样本类别算均衡。我们接下来看看语句长度的分布情况:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 设置matplotlib绘图时的字体
my_font = font_manager.FontProperties(fname="/Library/Fonts/Songti.ttc")
# 读取数据
neg=pd.read_excel('D:/S/Learn/NLP/Jingdong/neg.xls',header=None,index=None)
pos=pd.read_excel('D:/S/Learn/NLP/Jingdong/pos.xls',header=None,index=None)
df=np.concatenate((pos[0], neg[0]))
#%%句子长度分布直方图
Num_len=[len(text) for text in df]
bins_interval=10#区间长度
bins=range(min(Num_len),max(Num_len)+bins_interval-1,bins_interval)#分组
plt.xlim(min(Num_len), max(Num_len))
plt.title("Probability-distribution")
plt.xlabel('Interval')
#plt.ylabel('Probability')
# 频率分布normed=True,频次分布normed=False
#prob,left,rectangle = plt.hist(x=Num_len, bins=bins, normed=True, histtype='bar', color=['r'])#分布直方图
plt.ylabel('Cumulative distribution')
prob,left,rectangle = plt.hist(x=Num_len, bins=bins,normed=True,cumulative=True, histtype='step', color=['r'])#累计分布图
plt.show()
分别得到预料中句子长度的分布直方图和累计分布图:


因为LSTM接受的句子长度或者叫序列长度都是固定的,所以在后面数据处理中我们需要将句子裁剪出一样的长度,我们根据语料的累积分布情况求样本中90%概率的句子长度作为裁剪后句子的统一长度。
#%%求分位点
import math
def quantile_p(data, p):
data.sort()
pos = (len(data) + 1)*p
#pos = 1 + (len(data)-1)*p
pos_integer = int(math.modf(pos)[1])
pos_decimal = pos - pos_integer
Q = data[pos_integer - 1] + (data[pos_integer] - data[pos_integer - 1])*pos_decimal
return Q
quantile=0.90#选取分位数
Q=quantile_p(Num_len,quantile)
print("\n分位点为%s的句子长度:%d." % (quantile, Q))
得到结果:
数据预处理
接下来我们正式开始我们的项目,当前我们的数据还是中文文本状,所以我们按照一般步骤进行结巴分词、利用Word2Vec求词向量、训练数据集和测试数据集分割。需要注意的三个小地方:(代码中已经注释的很详细啦,详细步骤就不多说啦)
- 我们当前的数据分别在两个文件中,我们需要合并,并且按照好评和差评添加标注1/0;
- 我们设置一个最小词频为10,令词频数小于10的词对应索引为0,而后令对应的词向量为零向量,目的是舍弃这些词频过小的生僻词;
- 注意按照上面我们求出的句子长度188进行统一。
import yaml
import sys
from sklearn.cross_validation import train_test_split
import multiprocessing
import numpy as np
from gensim.models import Doc2Vec
from gensim.corpora.dictionary import Dictionary
from gensim.models import Word2Vec
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
from keras.layers.core import Dense, Dropout,Activation
from keras.models import model_from_yaml
np.random.seed(1337) # For Reproducibility
import jieba
import pandas as pd
sys.setrecursionlimit(1000000)#递归的最大深度
#%% set parameters:
vocab_dim = 100
n_iterations = 1 # ideally more..
n_exposures = 10 #词频数少于10的截断
window_size = 7
batch_size = 32
n_epoch = 4
input_length = 188 #LSTM输入 注意与下长度保持一致
maxlen = 188#统一句长
cpu_count = multiprocessing.cpu_count()
#%%加载训练文件
def loadfile():
neg=pd.read_excel('D:/S/Learn/NLP/Jingdong/neg.xls',header=None,index=None)
pos=pd.read_excel('D:/S/Learn/NLP/Jingdong/pos.xls',header=None,index=None)
combined=np.concatenate((pos[0], neg[0]))
y = np.concatenate((np.ones(len(pos),dtype=int), np.zeros(len(neg),dtype=int)))#添加标注
return combined,y
#%%对句子进行分词,并去掉换行符
def tokenizer(text):
text = [jieba.lcut(document.replace('\n', '')) for document in text]
return text
#%%创建词语字典,并返回每个词语的索引,词向量,以及每个句子所对应的词语索引
def create_dictionaries(model=None,
combined=None):
if (combined is not None) and (model is not None):
gensim_dict = Dictionary()
gensim_dict.doc2bow(model.wv.vocab.keys(),allow_update=True)
w2indx = {v: k+1 for k, v in gensim_dict.items()}#所有频数超过10的词语的索引
w2vec = {word: model[word] for word in w2indx.keys()}#所有频数超过10的词语的词向量
def parse_dataset(combined):
data=[]
for sentence in combined:
new_txt = []
for word in sentence:
try:
new_txt.append(w2indx[word])
except:
new_txt.append(0)
data.append(new_txt)
return data
combined=parse_dataset(combined)
combined= sequence.pad_sequences(combined, maxlen=maxlen)#前方补0 为了进入LSTM的长度统一
#每个句子所含词语对应的索引,所以句子中含有频数小于10的词语,索引为0
return w2indx, w2vec,combined
else:
print('No data provided...')
#%%创建词语字典,并返回每个词语的索引,词向量,以及每个句子所对应的词语索引
def word2vec_train(combined):
model = Word2Vec(size=vocab_dim,#特征向量维度
min_count=n_exposures,#可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
window=window_size,#窗口大小,表示当前词与预测词在一个句子中的最大距离是多少
workers=cpu_count,#用于控制训练的并行数
iter=n_iterations)
model.build_vocab(combined)#创建词汇表, 用来将 string token 转成 index
model.train(combined,total_examples=model.corpus_count,epochs=10)
model.save('D:/S/Learn/NLP/Jingdong/Word2vec_model.pkl')#保存训练好的模型
index_dict, word_vectors,combined = create_dictionaries(model=model,combined=combined)
return index_dict, word_vectors,combined#word_vectors字典类型{word:vec}
#%%最终的数据准备
def get_data(index_dict,word_vectors,combined,y):
n_symbols = len(index_dict) + 1 # 所有单词的索引数,频数小于10的词语索引为0,所以加1
embedding_weights = np.zeros((n_symbols, vocab_dim))#索引为0的词语,词向量全为0
for word, index in index_dict.items():#从索引为1的词语开始,对每个词语对应其词向量
embedding_weights[index, :] = word_vectors[word]
x_train, x_test, y_train, y_test = train_test_split(combined, y, test_size=0.2)
print(x_train.shape,y_train.shape)
return n_symbols,embedding_weights,x_train,y_train,x_test,y_test
模型构建
得到了上面处理好的数据后,我们开始后见我们的模型,主要网络为Embedding层、LSTM层、LR层。详细的都在代码中注释咯~
#%%定义网络结构
def train_lstm(n_symbols,embedding_weights,x_train,y_train,x_test,y_test):
print('Defining a Simple Keras Model...')
model = Sequential() # or Graph or whatever #堆叠
#嵌入层将正整数(下标)转换为具有固定大小的向量
model.add(Embedding(output_dim=vocab_dim,#词向量的维度
input_dim=n_symbols,#字典(词汇表)长度
mask_zero=True,#确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值
weights=[embedding_weights],
input_length=input_length)) # Adding Input Length#当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
#输入数据的形状为188个时间长度(句子长度),每一个时间点下的样本数据特征值维度(词向量长度)是100。
model.add(LSTM(output_dim=50, activation='sigmoid', inner_activation='hard_sigmoid'))
#输出的数据,时间维度仍然是188,每一个时间点下的样本数据特征值维度是50
model.add(Dropout(0.5))
model.add(Dense(1))#全连接层
model.add(Activation('sigmoid'))
print('Compiling the Model...')
model.compile(loss='binary_crossentropy',
optimizer='adam',metrics=['accuracy'])
print("Train...")
model.fit(x_train, y_train, batch_size=batch_size, nb_epoch=n_epoch,verbose=1, validation_data=(x_test, y_test))
print("Evaluate...")
score = model.evaluate(x_test, y_test,
batch_size=batch_size)
yaml_string = model.to_yaml()
with open('D:/S/Learn/NLP/Jingdong/lstm.yml', 'w') as outfile:
outfile.write( yaml.dump(yaml_string, default_flow_style=True) )
model.save_weights('D:/S/Learn/NLP/Jingdong/lstm.h5')
print('Test score:', score)
训练
接下来就是训练啦~
#%%
#训练模型,并保存
def train():
print('Loading Data...')
combined,y=loadfile()
print(len(combined),len(y))
print('Tokenising...')
combined = tokenizer(combined)
print('Training a Word2vec model...')
index_dict, word_vectors,combined=word2vec_train(combined)
print('Setting up Arrays for Keras Embedding Layer...')
n_symbols,embedding_weights,x_train,y_train,x_test,y_test=get_data(index_dict, word_vectors,combined,y)
print(x_train.shape,y_train.shape)
train_lstm(n_symbols,embedding_weights,x_train,y_train,x_test,y_test)
train()
我们得到这样的结果:
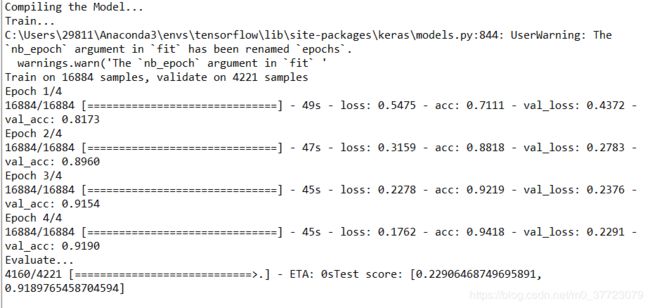
测试集上的得分是0.9189765458704594。
测试
我们可以再做个小测试,我们随便给一个句子,然后按照上面这个标准的过程就行数据处理利用保存好的模型进行测试:
#%%测试模型
def input_transform(string):
words=jieba.lcut(string)
words=np.array(words).reshape(1,-1)
model=Word2Vec.load('D:/S/Learn/NLP/Jingdong/Word2vec_model.pkl')
_,_,combined=create_dictionaries(model,words)
return combined
def lstm_predict(string):
print('loading model......')
with open('D:/S/Learn/NLP/Jingdong/lstm.yml', 'r') as f:
yaml_string = yaml.load(f)
model = model_from_yaml(yaml_string)
print('loading weights......')
model.load_weights('D:/S/Learn/NLP/Jingdong/lstm.h5')
model.compile(loss='binary_crossentropy',
optimizer='adam',metrics=['accuracy'])
data=input_transform(string)
data.reshape(1,-1)
#print data
result=model.predict_classes(data)
if result[0][0]==1:
print(string,' positive')
else:
print(string,' negative')
#%%测试
if __name__=='__main__':
#train()
#string='电池充完了电连手机都打不开.简直烂的要命.真是金玉其外,败絮其中!连5号电池都不如'
# string='牛逼的手机,从3米高的地方摔下去都没坏,质量非常好'
# string='酒店的环境非常好,价格也便宜,值得推荐'
# string='手机质量太差了,傻逼店家,赚黑心钱,以后再也不会买了'
# string='我傻了'
# string='你傻了'
# string='屏幕较差,拍照也很粗糙。'
# string='质量不错,是正品 ,安装师傅也很好,才要了83元材料费'
string='东西非常不错,安装师傅很负责人,装的也很漂亮,精致,谢谢安装师傅!'#1
#train()
lstm_predict(string)
得到结果:

大概就是这样啦,有待优化~