初识图数据与图数据库
一、图形数据库
定义:a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data – independent of the way the data is stored internally. It’s really the model and the implemented algorithms that matter.(使用图形结构进行语义查询的数据库,包含节点、边和属性来表示和存储数据——与数据在内部存储的方式无关。真正重要的是模型和实现的算法。)
注意,这里只是说数据模型是图结构的,没有说数据的存储也一定要是图结构的。
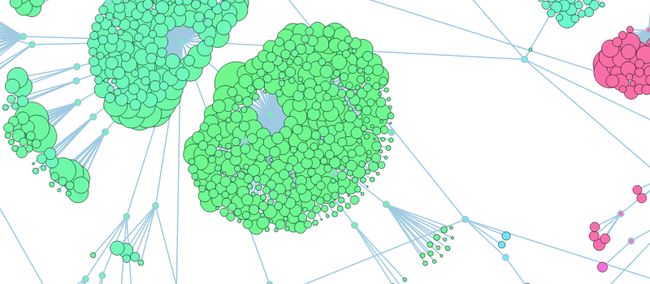
二、图形数据库和关系数据库分析对比
NoSQL(Not Only SQL)数据库泛指非关系型的数据库。数据库常常可以用来处理传统的关系型数据库所难以解决的一系列问题。通常情况下,这些NoSQL数据库分为Graph,Document,Column Family以及Key-Value Store等四种,这四种类型的数据库分别使用了不同的数据结构来记录数据,所适用的场景也不尽相同。
其中图形数据库和其它的NoSQL数据库非常不同:丰富的关系表示,完整的事务支持,却没有一个纯正的横向扩展解决方案。
在使用关系型数据库时常常会遇到一系列非常复杂的设计问题。这种彼此关联的关系常常会非常复杂,而且在两个实体之间常常同时存在着多个不同的关系。在尝试使用关系型数据库对这些关系进行建模时,我们首先需要建立表示各种实体的一系列表,这些表常常需要通过一系列关联表将它们关联起来,我们需要大量的关联表来记录这一系列复杂的关系。在更多实体引入之后,我们将需要越来越多的关联表,从而使得基于关系型数据库的解决方案繁琐易错。
这主要是因为关系型数据库是以为实体建模这一基础理念设计的,并没有提供对这些实体间关系的直接支持。需要创建一个关联表以记录这些数据之间的关联关系,而且关联表常常不用来记录除外键之外的其它数据,也就是说这些关联表也仅仅是通过关系型数据库所已有的功能来模拟实体之间的关系。这种模拟导致了两个非常糟糕的结果:数据库需要通过关联表间接地维护实体间的关系,导致数据库的执行效能低下;同时关联表的数量急剧上升。
在需要描述大量关系时,传统的关系型数据库已经不堪重负。它所能承担的是较多实体但是实体间关系略显简单的情况。而对于这种实体间关系非常复杂,常常需要在关系之中记录数据,而且大部分对数据的操作都与关系有关的情况,原生支持了关系的图形数据库才是正确的选择。它不仅仅可以为我们带来运行性能的提升,更可以大大提高系统开发效率,减少维护成本。
在一个图形数据库中,数据库的最主要组成主要有两种,结点集和连接结点的关系。结点集就是图中一系列结点的集合,比较接近于关系数据库中所最常使用的表。而关系则是图形数据库所特有的组成。因此对于一个习惯于使用关系型数据库开发的人而言,如何正确地理解关系则是正确使用图形数据库的关键。
图形数据库对数据进行抽象的方式实际上和关系型数据库非常接近。每个结点仍具有标示自己所属实体类型的标签,也既是其所属的结点集,并记录一系列描述该结点特性的属性。除此之外,我们还可以通过关系来连接各个结点。
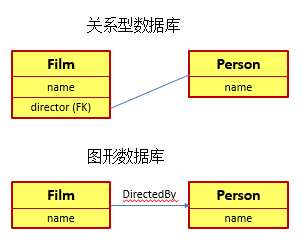
在表示关系的时候,关系型数据库和图形数据库就有很大的不同了:
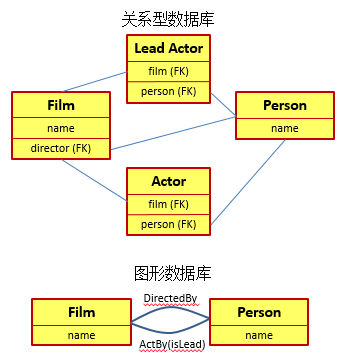
从上图中可以看到,在需要表示多对多关系时,我们常常需要创建一个关联表来记录不同实体的多对多关系,而且这些关联表常常不用来记录信息。如果两个实体之间拥有多种关系,那么我们就需要在它们之间创建多个关联表。而在一个图形数据库中,我们只需要标明两者之间存在着不同的关系,例如用DirectBy关系指向电影的导演,或用ActBy关系来指定参与电影拍摄的各个演员。同时在ActBy关系中,我们更可以通过关系中的属性来表示其是否是该电影的主演。而且从上面所展示的关系的名称上可以看出,关系是有向的。如果希望在两个结点集间建立双向关系,我们就需要为每个方向定义一个关系。
也就是说,相对于关系数据库中的各种关联表,图形数据库中的关系可以通过关系能够包含属性这一功能来提供更为丰富的关系展现方式。因此相较于关系型数据库,图形数据库的用户在对事物进行抽象时将拥有一个额外的武器,那就是丰富的关系:

虽然在一个图数据库中常常拥有结点集的概念,但是它已经不再作为图数据库的最重要抽象方式了。甚至从某些图形数据库已经允许软件开发人员使用Schemaless结点这一点上来看,它们已经将结点集的概念弱化了。反过来,我们思考的角度就应该是结点个体,以及这些个体之间所存在的一系列关系。
但是并不代表可以随便定义各个结点所具有的数据。最为常用的一个准则就是:Schemaless这种灵活度能为你带来好处。例如相较于强类型语言,弱类型语言可以为软件开发人员带来更大的开发灵活度,但是其维护性和严谨性常常不如强类型语言。同样地,在使用Schemaless结点时也要兼顾灵活性和维护性。
这样我们就可以在结点中添加多种多样的关系,而不用像在关系型数据库中那样需要担心是否需要通过更改数据库的Schema来记录一些外键。这进而允许软件开发人员在各结点间添加多种多样的关系。
简单地说,单一事物应该被抽象为一个结点,而同一类型的结点被记录在同一个结点集中。结点集内各结点所包含的数据可能有一些不同,如一个人可能有不同的职责并由此通过不同的关系和其它结点关联。例如一个人既可能是演员,可能是导演,也可能是演员兼导演。在关系型数据库中,我们可能需要为演员和导演建立不同的表。而在图形数据库中,这三种类型的人都是人这个结点集内的数据,而不同的仅仅是它们通过不同的关系连接到不同的结点上。也就是说,在图形数据库中,结点集并不会像关系型数据库中的表一样粒度那么小。
一旦抽象出了各个结点集,我们就需要找出这些结点之间所可能拥有的关系。这些关系不仅仅是跨结点集的。有时候,这些关系是同一结点集内的结点之间的关系,甚至是同一结点指向自身的关系。

这些关系通常都具有一个起点和终点。也就是说,图形数据库中的关系常常是有向的。如果希望在两个结点之间创建一个相互关系,如Alice和Bob彼此相识,我们就需要在他们之间创建两个KNOW_ABOUT关系。其中一个关系由Alice指向Bob,而另一个关系则由Bob指向Alice。虽然图中的关系是单向的,但是关系在起点和终点都可以被查找到。
---------------------------------------------------------------------------------------------------------------------------------
部分内容来源于网络,若有侵权可以联系博主哦~Thanks♪(・ω・)ノ
继续加油ヾ(◍°∇°◍)ノ゙