Docker >>『Docker容器与容器云』读书笔记-1
关于《Docker容器与容器云》的读书笔记,主要用于自己强化知识记忆,理解错误之处还望指出,有兴趣的同学也可以阅读原书。
基础命令与核心原理两部分
- 第二章 Docker基础
- Docker安装
- Docker参数解读
- 环境信息
- 生命周期管理
- 镜像仓库命令
- 镜像管理
- 容器运维操作
- 系统日志信息
- 第三章 Docker核心原理解读
- Docker背后内核知识
- 进行namespace API操作的四种方式
- 创建NS: 通过clone()在创建新进程的同时创建namespace
- 查看NS: 查看/proc/[pid]/ns文件
- 加入NS: 通过setns()加入一个已经存在的namespace
- 隔离NS: 通过unshare在原先进程上进行namespace隔离
- 延伸阅读: fork()系统调用
- namespace的六项隔离
- UTS namespace
- IPC namespace
- PID namespace
- PID namespace中的init进程
- 信号与init进程
- 挂载proc文件系统
- unshare()和setns()
- mount namespace
- network namespace
- user namespace
- cgroups资源限制
- cgroups是什么?
- cgroups的作用
- cgroups术语表
- 组织结构与基本规则
- 子系统简介
- cgroups实现方式及工作原理简介
- cgroups如何判断资源超限和超限之后的措施
- cgroup与任务之间的关联关系
- Docker在使用cgroup时的注意事项
- /sys/fs/cgroup/cpu/docker/下文件的作用
第二章 Docker基础
Docker安装
(略)
Docker参数解读
| 子命令分类 | 子命令 |
|---|---|
| Docker环境信息 | info, version |
| 容器生命周期管理 | create, exec, kill, pause, unpause, restart, start, stop, rm, run |
| 镜像仓库命令 | login, logout, pull, push, search |
| 镜像管理 | build, images, rmi, import, load, save, tag, commit |
| 容器运维操作 | attach, export, inspect, port, ps, rename, stats, top, wait, cp, diff, update |
| 容器资源管理 | volume, network |
| 系统日志信息 | events, history, logs |
Docker命令结构图:
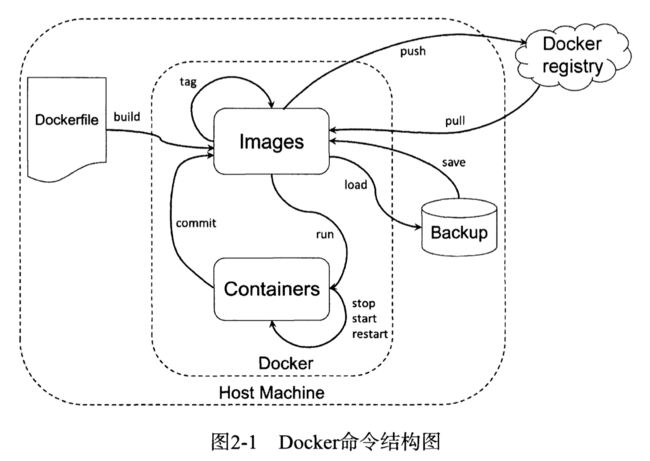
环境信息
# 环境信息
docker info
# 版本信息
docker version
生命周期管理
# 创建容器
docker run
options:
-i: 使用交互模式,始终保持输入流开放
-t: 分配一个伪终端,配合-i使用,进行交互操作
--name: 指定容器名
-c: 给运行中的容器分配cpu的share值(相对权重,与宿主机相关)
-m: 限制容器所有进程的内存总量
-v: 挂载volume,[host-dir]:[container-dir]:[rw|ro]
-p: 将容器端口暴露给宿主机,hostPort:containerPort
# 容器的启动
docker start
options:
-i: 使用交互模式,始终保持输入流开放
-a: 附加标准输入,标准输出或错误输出
# 容器的停止
docker stop
options:
-t: 容器停止前的等待时间
# 容器的重启
docker restart
options:
-t: 容器停止前的等待时间
镜像仓库命令
# 镜像拉取
docker pull [OPTIONS] NAME:[TAGS|@DIGEST]
# 镜像推送
docker push [OPTIONS] NAME[:TAG]
镜像管理
# 显示镜像列表
docker images [OPTIONS] [REPOSITORY[:TAG]]
# 镜像删除
docker rmi [OPTIONS] IMAGE [IMAGE...]
# 容器删除
docker rm [OPTIONS] CONTAINER [CONTAINER...]
# 将容器保存为镜像
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
## 只能选择正在运行的容器(官方推荐使用build和Dockerfile创建镜像)
容器运维操作
# 连接容器进行交互
docker attach [OPTIONS] CONTAINER
# 查看容器和镜像的详细信息
docker inspect [OPTIONS] NAME|ID [NAME|ID...]
## 查看容器IP地址
docker inspect --format='{{.NetworkSettings.IPAddress}}' NAME
## 批量查看IP地址
for i in `docker ps -q`; do echo -n "$i "; docker inspect $i --format='{{.NetworkSettings.IPAddress}}'; done
# 查看容器的相关信息
docker ps [OPTIONS]
options:
-a: 全部显示
-l: 只查看最新创建的容器
系统日志信息
# 打印实时系统事件
docker events [OPTIONS]
# 打印镜像的历史版本信息
docker history [OPTIONS] IMAGE
# 打印容器中的进程日志
docker logs [OPTIONS] CONTAINER
第三章 Docker核心原理解读
Docker背后内核知识
namespace的六项隔离
| namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
进行namespace API操作的四种方式
- clone()
- setens()
- unshare()
- /proc下的部分文件
创建NS: 通过clone()在创建新进程的同时创建namespace
# 常见方式(Docker使用namespace最基本的方式)
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
# 与namespace相关的4个参数:
- child_func: 传入子进程运行的程序主函数
- child_stack: 传入子进程使用的栈空间
- flags: 表示使用哪些CLONE_*标志位。与namespace相关的见上表。
- args: 则可用于传入用户参数
@@备注@@
1.clone是linux系统调用fork()的一种最通用的方式,通过flags参数来控制多少功能。
2.flags有20多种CLONE_*参数,来控制clone的方方面面
查看NS: 查看/proc/[pid]/ns文件
# 最后一列为namespace编号
[root@sherlockV7 ns]# ll /proc/$$/ns <<-- $$shell中表示当前运行的进程ID号
总用量 0
lrwxrwxrwx. 1 root root 0 3月 15 21:20 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 3月 15 21:20 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 3月 15 21:20 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 3月 15 21:20 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 3月 15 21:20 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 3月 15 21:20 uts -> uts:[4026531838]
- 若两个进程的namespace编号相同,则在同一namespace下。
- 上述link表示,若该文件被打开,只要打开的文件描述符(fd)存在,则namespace下所有进程都结束也一直存在,后续进程可以再加进来
- Docker中,通过文件描述符定位和加入是常见的方式。
加入NS: 通过setns()加入一个已经存在的namespace
# 通过setns()函数加入已存在的namespace
int setns(int fd, int nstype);
- fd: 表示要加入的namespace的文件描述符
- nstype: 检测fd指向的namespace文件描述符是否符合要求。参数0为不检查
@@备注@@
1.通过setns()系统调用,进程从原有NS加入已存在NS中。
2.为不影响进程调用者,也为使新加入的pid NS生效。
3.setns()执行后,使用clone()创建子进程继续执行命令,结束原先进程。
4.Docker exec在已运行容器中执行新命令,就需要用到该方法
隔离NS: 通过unshare在原先进程上进行namespace隔离
# 不启动新进程进行隔离NS操作
int unshare(int flags);
@@备注@@
1.功能类似clone,在原有的进程上运行,不需要启动新进程。
2.相当于跳出原有namespace进行操作。
3.Docker目前未用到该系统调用。
延伸阅读: fork()系统调用
- 当系统调用fork()函数时,系统会复制原有进程资源并创建新进程
- fork()调用一次, 可以有两次返回
- 通过返回值来区分父子进程:
- 父进程中,fork()返回新创建子进程的进程ID
- 子进程中,fork()返回0
- 如何出现错误,fork()返回一个负值
- 父进程会监控子进程的运行状态,并在子进程退出后才能正常退出,否则子进程会成为“孤儿”进程。
namespace的六项隔离
UTS namespace
说明
UTS:UNIX Time-sharing System
作用
提供了主机名和域名的隔离,使Docker拥有独立的主机名和域名
IPC namespace
说明
进程间通信(Inter-Process Communication, IPC)涉及的IPC资源包括:
- 信号量
- 消息队列
- 共享内存
申请IPC资源就申请了一个全局唯一的32位ID。
IPC namespace实际包括:
- 系统IPC标识符
- 实现POSIX消息队列的文件系统
作用
- 相同IPC namespace下,进程彼此可见;不同IPC namespace下的进程,则相互不可见。
- 实现了Docker,容器与宿主机、容器与容器之间的IPC隔离。
PID namespace
说明
- PID namespace会对进程PID重新标号,两个不同NS下的进程可以有相同的PID。
- 每个PID namespace都有自己的计数程序
- 内核为所有的PID namespace维护一个树状结构
- 顶层为系统初始时创建,名为root namespace
- 原先的PID namespace,名为parent namespace
- 新PID namespace,名为child namespace
- 延伸阅读:https://blog.csdn.net/zhangyifei216/article/details/49926459
- 父节点可以看子节点的进程,可以通过信号方式对子进程产生影响
- 子节点无法看到父节点PID namespace中的任何内容
结论
- 每个PID namespace中的第一个进程PID为1,类似init进程一样拥有特权,起特殊作用
- 一个PID namespace中的进程,无法通过kill或ptrace影响父节点或兄弟节点中进程,其他节点的PID在这个namespace中没有任何意义。「该PID namespace下的PID 1,在其父节点中的PID namespace中另有标号」
- 在新的PID namespace中重新挂载/proc文件系统,其下只显示同属该PID namespace中的进程
- 在root namespace中可以看到所有进程,并且递归所有子节点的进程
引申作用
外部监控Docker内进程方法:监控Docker daemon所在的PID namespace下的所有进程以及子进程,再进行筛选。
PID namespace确保进程顺利进行的额外工作
PID namespace中的init进程
容器中要实现类似init的资源监控与回收功能,维护后续启动进行的运行状态,确保最终回收子进程的资源。
信号与init进程
- 内核赋予PID namespace中的init进程–信号屏蔽的特权,防止被同PID NS下的其他进程误杀。
- 父节点的进程有权终止子节点的进程(只有SIGKILL和SIGSTOP信号有效)
- PID namespace下init进程被销毁后,同PID NS下的其他进程也会随之被销毁
- 容器中的init进程会进行信号捕获,接收到SIGTRME或SIGINT等信号,会对其子进程进行信息保存和资源回收等处理操作。
挂载proc文件系统
在新的PID namespace中使用ps命令能够看到所有进程,原因为与PID相关的proc文件系统(procfs)未挂载到原/proc不同的地方。只想看PID namespace本身进程时,需要重新挂载/proc。
mount -t proc proc /proc
unshare()和setns()
感觉跟之前解释的有出入,没看懂,先跳过后续补充。
mount namespace
说明
mount namespace通过隔离文件系统挂载点对文件系统的隔离提供支持
作用
不同mount namespace下的文件结构发生变化也互不影响。
查看挂载到当前ns中的文件系统
- /proc/[pid]/mounts
- /proc/[pid]/mountstats : 详细信息
挂载传播
进程创建mount namespace时,会把当前文件结构复制给新的namespace。新的ns中mount操作都只影响自身的文件系统,不外界不产生影响。但当父节点挂载外部设备后,子节点复制的目录结构却无法自动挂载,因为这种操作会影响父节点的文件系统。
引入挂载传播概念,定义挂载对象之间的关系:
- 共享关系:如果两个挂载对象为此关系,那么一个对象的挂载事件会传播到另一个对象,反之亦然。
- 从属关系:如果两个挂载对象为此关系,那么一个对象的挂载事件会传播到另一个对象,反之则不行。在此关系中,从属对象是事件的接受者。
系统会用这些关系来决定将任何挂载对象中的挂载事件如何传播到其他挂载对象。
挂载状态分类:
- 共享挂载(share): 传播事件的挂载对象
- 从属挂载(slave): 接收传播事件的挂载对象
- 共享/从属挂载(shared and slave): 同时兼有上述两种特征的挂载对象
- 私有挂载(private): 既不传播也不接收传播事件的挂载对象
- 不可绑定挂载(unbindable): 不允许执行绑定复制的挂载对象
mount各类挂载状态示意图
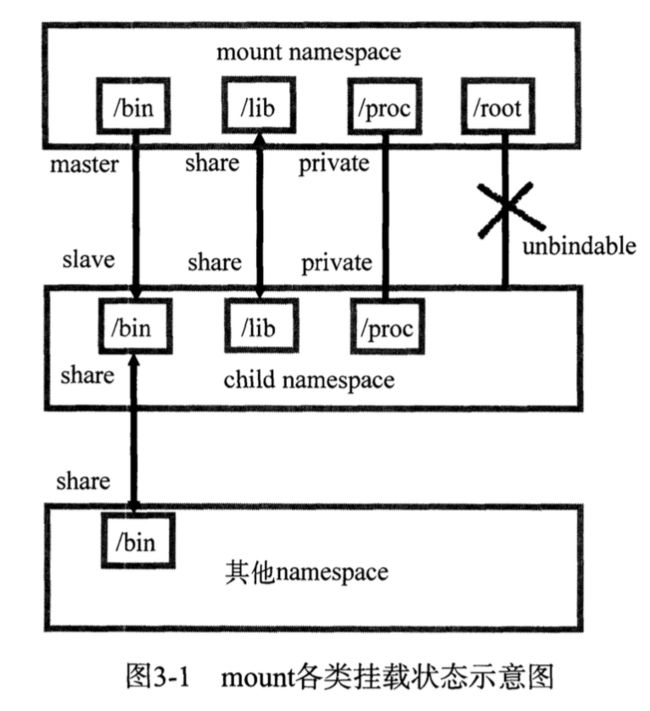
- 上层mount namespace中/bin目录与child namespace通过master slave方式1 进行挂载传播。当/bin目录发生变化时,挂载事件会自动传播到child namespace中。
- /lib目录使用完全的共享挂载传播,各M_NS之间的变化相互影响。
- /proc目录使用私有挂载传播,各M_NS之间相互隔离。
- /root目录使用不可绑定挂载方式,一般都为管理员所有。
network namespace
作用
主要提供关于网络资源的隔离,包括:
- 网络设备
- IPv4和IPv6协议栈
- IP路由表
- 防火墙
- /proc/net目录
- /sys/class/net目录
- 套接字(socket)
- 等等
虚拟网络设备对(veth pair)
由于一个物理网络设备最多存在于一个namespace中,可以通过创建veth pair(有两端,类似管道,如果数据从一端传入另一端也能接收到,反之亦然)在不同的namespace间创建通道,已达到通信的目的。
容器实现网络隔离的过程
- 创建一个veth pair
- 一端放置在新namespace中,通常命名为eth0
- 一端放置在原先的namespace中,连接物理设备
- 再通过把多个设备接入网桥或进行路由转发,来实现通信目的
veth pair创建前,新旧namespace如何通信
- Docker daemon启动容器
- 假设容器的初始化进程称为init
- Docker daemon与init通过pipe(管道)进行通信,init在一端循环等待
- Docker daemon在宿主机上创建veth pair
- 一端绑定到docker0网桥上
- Docker daemon将veth设备信息发送给init
- init结束等待,将另一端接入新创建的namespace进程中
- 最后将"eth0"启动起来
物理设备分配给新建namespace时的注意点
- 物理设备默认分配给最初的root namespace
- 也可以将多余的物理设备也可以分配给新建namespace
- 新建namespace被释放时,物理网卡会返回到root namespace中,而非创建该进程的父进程所在的namespace中
user namespace
作用
user namespace主要隔离了安全相关的标识符(identifier)和属性(attribute),包括:
- 用户ID
- 用户组ID
- root目录
- key(指密钥)
- 特殊权限
简单理解
一个普通用户的进程通过clone()创建的新进程在新user namespace中可以拥有不同的用户和用户组。也就意味,一个进程在容器外属于没特权的普通用户,但它创建的容器进程却属于拥有所有权限的超级用户。
验证结论
- user namespace被创建后,该namespace下的首个进程被赋予全部权限,以便完成所有必要的初始化工作,不会因权限不足出错
- 从namespace内部观察UID和GUID会与外部不同,当内部初始user与外部namespace某用户建立映射后,可以保证涉及外部namespace操作时,系统可以检验其权限(发送信号量或操作某文件).用户组同样也要建立。
- 用户在新namespace中有全部权限,但在创建它的父namespace中不含任何权限。即便父NS是root用户所在的namespace也同样如此。
- user namespace的创建也是嵌套的树状结构,类似于PID namespace。
Docker方面的应用
- Docker不仅使用user namespace,还使用了user NS涉及的Capabilities机制
- Linux把超级用户相关的高级权限划分为不同的单元,称为Capability
- 管理员可以独立对特殊的capability进行使用和禁止
cgroups资源限制
强大的内核工具 —— cgroups
cgroups不仅可以限制被namespace隔离起来的资源,还可以为资源设置权重、计算使用量、操控(进程或线程)任务启停等。
cgroups是什么?
官方定义
- cgroups是Linux内核提供的一种机制
- 这种机制可根据需求把一系列系统任务及其子任务整合或分隔到按资源划分不同的组内
- 从而为系统资源管理提供一个统一的框架
简单理解
cgroups可以限制、记录任务组所使用的物理资源(包括CPU、Memory、IO等),为容器实现虚拟化提供了基本保证,是构建Docker等一系列虚拟化工具的基石。
对于开发者,cgroups有以下4个特点
- cgroups的API以伪文件系统方式实现,用户态程序可通过文件操作实现cgroups的组织管理
- cgroups的组织管理单元,可以细粒度到线程级别,用户可以创建、销毁cgroup,从而实现资源再分配和管理
- 所有资源管理的功能都以子系统的方式实现,接口统一
- 子任务创建之初与其父任务处于同一个cgroups的控制组
cgroups的作用
主要目的是为了不同用户层面的资源管理,提供一个统一化的接口。主要提供以下四大功能:
- 资源限制:cgroups可对任务使用的资源总额进行限制。如设定应用运行时的内存上限,超出配额后发出OOM(Out Of Memory)提示.
- 优先级分配:通过分配cpu时间片数量和磁盘IO、带宽大小,相当于控制任务运行的优先级。
- 资源统计:cgroups可以统计系统的资源使用量,如cpu使用时长、内存用量等,这些功能非常适用于计费。
- 任务控制:cgroups可以对任务执行挂起、恢复等操作。
cgroups术语表
- task(任务):在术语中,任务表示系统的一个进程或线程
- cgroup(控制组):cgroups中的资源控制都以cgroup为单位实现。cgroup表示按某种资源控制标准划分成的任务组,包含一个或多个子系统。一个任务可以加入某个cgroup,也可以从某cgroup迁移到另一个cgroup中。
- subsystem(子系统):cgroups中的子系统就是一个资源调度控制器。如cpu子系统可以控制cpu时间分配,内存子系统可以限制cgroups内存使用量。
- hierarchy(层级):层级是由一系列cgroup以树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。层级中cgroup节点可以包含零或多个子节点,子节点继承父节点挂载的子系统。整个操作系统可以有多个层级。
组织结构与基本规则
组织结构
- 系统中的多个cgroup构成的层级并非单根结构,可以允许存在多个
- 如果只有一个层级,那所有任务都将被迫绑定其上的所有子系统,会给某些任务造成不必要的限制
基本规则
- 规则1:同一层级可以被附加一个或多个子系统。
- 规则2:一个子系统可以附加到多个层级,当且仅当目标层级只有唯一一个子系统时2。
- 规则3:
- 系统每次新建一个层级时,该系统上的所有任务默认加入这个新建层级的初始化cgroup,也成为root cgroup。
- 对于创建的每个层级,任务也只能存在于其中一个cgroup中。即一个任务不能存在同层级的不同cgroup中,否则任务会在添加时,被从第一个cgroup移除,但是可以存在不同层级的多个cgroup中。
- 规则4:任务在fork/clone自身时,创建的子任务默认与原任务在同一cgroup,但子任务允许被移动到其他cgroup中。即fork/clone后,子任务与父任务间在cgroup方面互不影响。
子系统简介
子系统就是cgroups的资源控制,每种子系统独立控制一种资源。目前Docker中,使用了9种子系统。net_cls子系统在内核中已经广泛使用,但是Docker中没有使用。
- blkio:可以为块设备设定输入/输出的限制。(物理驱动设备:磁盘、固态硬盘、USB)
- cpu:使用调度程度来控制任务对cpu的使用
- cpuacct:自动生成cgroups中,任务对cpu资源使用情况的报告
- cpuset:为cgroups中的任务分配独立的cpu和内存
- devices:可以开启或关闭cgroup中的任务对设备的访问
- freezer:可以挂起或恢复cgroup中的任务
- memory:可以设定cgroup中任务对内存使用量的限定,并自动生成这些任务对内存资源的使用报告
- perf_event:使用后可以使cgroup中的任务进行统一的性能测试
- net_cls:Docker没有直接使用它。它通过使用等级识别符(classid)标记网络数据包。从而运行Linux流量控制程序(TC)识别具体cgroup中的数据包。
cgroups实现形式
表现为一个文件系统,通过mount挂载文件系统,就可以查看到下面的各类子系统。
以cpu为例:
# cpu子系统挂载路径
[root@sherlockV7 cpu]# pwd
/sys/fs/cgroup/cpu
# 挂载该子系统的控制组下的文件
[root@sherlockV7 cpu]# ls
cgroup.clone_children cgroup.sane_behavior cpuacct.usage_percpu cpu.rt_period_us cpu.stat release_agent user.slice/
cgroup.event_control cpuacct.stat cpu.cfs_period_us cpu.rt_runtime_us docker/ system.slice/
cgroup.procs cpuacct.usage cpu.cfs_quota_us cpu.shares notify_on_release tasks
# Docker daemon会在每个子系统控制组目录下创建名为docker的控制组,
# 容器则以ID为名称在docker控制组目录下分别创建控制组,
# 并将容器中的所有进程号写入控制组的tasks中,
# 再在控制文件(cpu.cfs_quota_us)中写入预设的限制参数值。
# Docker组的层级目录如下:
[root@sherlockV7 docker]# tree .
.
├── cgroup.clone_children
├── cgroup.event_control
├── cgroup.procs
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_percpu
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.rt_period_us
├── cpu.rt_runtime_us
├── cpu.shares
├── cpu.stat
├── d314400633f9281e8d028b4dfb41e82ecc6ed67211bc604ad0054bd747ad7d41
│ ├── cgroup.clone_children
│ ├── cgroup.event_control
│ ├── cgroup.procs
│ ├── cpuacct.stat
│ ├── cpuacct.usage
│ ├── cpuacct.usage_percpu
│ ├── cpu.cfs_period_us
│ ├── cpu.cfs_quota_us
│ ├── cpu.rt_period_us
│ ├── cpu.rt_runtime_us
│ ├── cpu.shares
│ ├── cpu.stat
│ ├── notify_on_release
│ └── tasks
├── notify_on_release
└── tasks
cgroups实现方式及工作原理简介
cgroups的实际本质是给任务挂上钩子,当任务运行过程中涉及某种资源时,就会触发钩子上附带的子系统进行检测,根据资源类型不同,使用对应的技术进行资源限制和优先级分配。
cgroups如何判断资源超限和超限之后的措施
对于不同系统资源,cgroups提供统一的接口对资源进行控制和统计,但限制的具体方式不尽相同。
以memory子系统为例:
判断资源超限
-
在"mm_struct"结构体(描述内存状态)记录所属cgroup。
-
当进程需申请更多内存时,触发cgroup用量检测。
-
用量超过cgroup限额时,拒绝用户的内存申请。
-
否则,给予相应内存并在cgroup统计信息中记录。
超限之后
-
内存超出cgroup最大限额之后
-
若设置了OOM Control(内存超限控制),进程会收到OOM信号并结束
-
否则进程会被挂起,进入睡眠状态,直至cgroup中其他进程释放足够内存资源为止。
-
Docker默认开启OOM Control
cgroup与任务之间的关联关系
-
并不直接关联,cgroup与任务之间是多对多关系。
-
通过中间结构把双方关联信息记录起来。
-
每个任务结构体task_struct都包含一个指针,
-
可查询到对应cgroup情况
-
也可查询各个子系统状态
-
-
同时子系统状态中也包含找到任务的指针。
-
不同类型的子系统按需定义自身的控制信息结构体,最终将子系统状态指针包含进去。
-
最后内核通过container_of(通过结构体成员找到结构体本身)等宏定义来获取相应的结构体,关联到任务,以达到资源限制的目的。
内核开发者通过VFS(虚拟文件系统转换器)接口实现cgroup的文件系统,并将各个子系统的实现都封装到文件系统的各项操作中。
Docker在使用cgroup时的注意事项
实际使用过程中,Docker需通过挂载cgroup文件系统新建一个层级结构,挂载时指定要绑定的子系统。把cgroup文件系统挂载上以后,就可以像操作文件一样对cgroups的层级进行浏览和操作管理(包括权限管理和子文件管理等)。
注意事项
- 若新建层级结构要绑定的子系统与目前已经存在层级结构完全相同,则新的挂载会重用原有那一套(指向相同css_net)。否则,如果要绑定的子系统已经被别的层级绑定,就会返回挂载失败的错误。正常下,挂载完成后层级就被激活并与相应子系统关联,可以开始使用。
- 新的子系统无法绑定到已激活的层级上,或从已激活层级上解除某子系统绑定。
- 当一个顶层cgroup文件系统被卸载时,若其中创建过深层的后代cgroup目录,则上层cgroup被卸载了,层级也是激活状态,后代cgroup配置仍有效。递归式卸载层级中所有cgroup,那个层级才会被真正删除。
- 在创建的层级中创建文件夹,就类似于fork一个后代cgroup,后代cgroup继承原有cgroup中的配置属性,也可以根据需求对参数进行调整。
/sys/fs/cgroup/cpu/docker/下文件的作用
以资源开头的文件都是用来限制这个cgroup下任务的可用配置文件,一个cgroup创建完成,不管绑定何种子系统,其目录下都会生成以下几个文件用来描述cgroup相应信息。同样,把相应信息写入配置文件就可以生效。
-
tasks:
- 文件记录所有该cgroup中任务的TID(所有进程或线程的ID)
- 文件不保证TID有序。
- TID写入文件表示任务加入该cgroup
- 若该任务所在任务组与其不在同一个cgroup,则cgroup.procs文件记录该任务的任务组ID(TGID), 该任务组其他任务不受影响。
-
cgroup.procs:
- 文件记录所有该cgroup中的TGID(线程组ID),即线程组第一个进程的PID。
- 文件不保证TGID有序或无重复。
- 写入TGID意味把与其相关的线程都加到这个cgroup中。
-
notify_on_release:
- 表示是否在cgroup中最后一个任务退出时通知运行release_agent
- 默认情况为0,表示不允许。1为允许。
-
release_agent:
- 指定release agent的执行脚本文件路径
- 该文件在最顶层cgroup目录中存在
- 用于自动化删除无用的cgroup
挂载状态分类中并没有提到master slave方式,这其实是上述从属挂载概念中隐藏的信息。下面引用外部资料说明:MS_SLAVE – This propagation type sits midway between shared and private. A slave mount has a master—a shared peer group whose members propagate mount and unmount events to the slave mount. However, the slave mount does not propagate events to the master peer group.原文地址:http://hustcat.github.io/mount-namespace-and-mount-propagation/ ↩︎
规则2中的解释说明没有理解明白,明显感觉与规则1说明上有冲突的地方,同一层级可以被附加多个子系统,但是规则2却说,子系统附加多个层级时,必须保证目标层级只有这个唯一一个子系统。难道是说,子系统与其他子系统附加到一个层级,或者是这子系统附加到多个层级,这两种情况只能选择一种吗?先跳过,后面有解答后再回来标注。 ↩︎