sqlserver聚集索引和非聚集索引并存
前面两篇文章讲解了一个数据表只存在聚集索引和只存在非聚集索引的情况,接下来我们来讨论一下当聚集索引和非聚集索引同时存在的情况,这种情况也是大多数表都存在的情况。
CREATE TABLE Department11(
DepartmentID int IDENTITY(1,1) NOT NULL PRIMARY KEY,
Name NVARCHAR(200) NOT NULL,
GroupName NVARCHAR(200) NOT NULL,
Company NVARCHAR(300),
ModifiedDate datetime NOT NULL DEFAULT (getdate())
)
CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department11](Name,[GroupName])DepartmentID是主键,即聚集索引。Name和GroupName是非聚集索引。接下来往表中插入数据:
DECLARE @i INT
SET @i=1
WHILE @i <= 1000
BEGIN
INSERT INTO Department11( name, [Company], groupname )
VALUES ( '销售部'+CAST(@i AS VARCHAR(200)), '中国你好有限公司XX分公司', '销售组'+CAST(@i AS VARCHAR(200)) )
SET @i = @i + 1
END创建用来存储表内部存储信息的表:
CREATE TABLE [dbo].[DBCCResult11](
[PageFID] [nvarchar](200) NULL,
[PagePID] [nvarchar](200) NULL,
[IAMFID] [nvarchar](200) NULL,
[IAMPID] [nvarchar](200) NULL,
[ObjectID] [nvarchar](200) NULL,
[IndexID] [nvarchar](200) NULL,
[PartitionNumber] [nvarchar](200) NULL,
[PartitionID] [nvarchar](200) NULL,
[iam_chain_type] [nvarchar](200) NULL,
[PageType] [nvarchar](200) NULL,
[IndexLevel] [nvarchar](200) NULL,
[NextPageFID] [nvarchar](200) NULL,
[NextPagePID] [nvarchar](200) NULL,
[PrevPageFID] [nvarchar](200) NULL,
[PrevPagePID] [nvarchar](200) NULL
) INSERT INTO DBCCResult11 EXEC ('DBCC IND(indextest,Department11,-1) ')
select * from DBCCResult11表的内部存储信息如下:
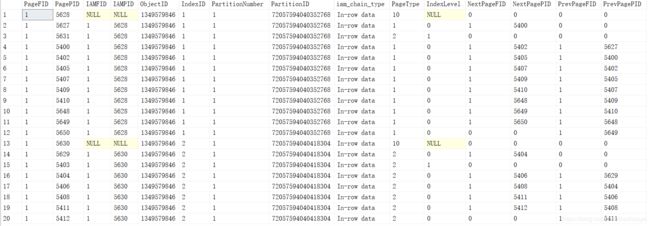
关于这个表的字段的介绍,我的前两篇文章都有介绍,在网上也可以查到,这里就不再重复了。
下面我们看一下非聚集索引页的信息:
dbcc page('indextest',1,5629,3) 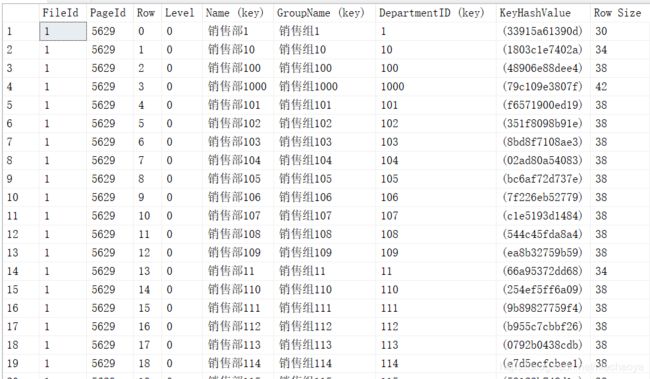
和只有非聚集索引的表相比,没有了RID,多了一个DepartmentID聚集索引的键值。
再看一下聚集索引页:
dbcc page('indextest',1,5631,3) 
聚集索引的索引页和只有聚集索引的时候一样。
那么对于上面的非聚集索引页的信息,msdn给出了下面的解释:
如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。
如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。
此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。
SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行
书签查找
之所以会出现书签查找,是因为表中建立了非聚集索引,而select查找的字段不在非聚集索引列中。所以数据库要根据非聚集索引的行定位指针或聚集索引的键值去堆表或者聚集索引的叶子节点数据页中去查询。
根据上面的描述,书签查询只可能出现在非聚集索引或非聚集索引和聚集索引并存的表中,而不会出现在只有聚集索引的表中,因为只有聚集索引的表的数据页全都在叶子节点中。
那么书签查找具体是怎么查找的呢?
select [ModifiedDate] from [dbo].[Department11] where GroupName='销售组12'按道理来说这条语句应该先走非聚集索引扫描,然后走书签查找,但是当数据量很少的时候,比如我只插入了1000条数据,这个查询会走聚集索引扫描,因为当数据量少的时候,走聚集索引扫描IO次数更少。
现在我把表中的数据变成10000行,再次运行这个查询,结果如下:
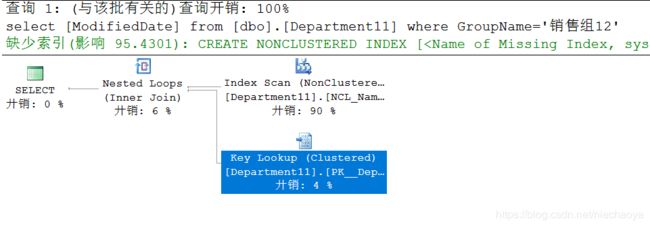
这个查询流程就和我上面描述的一样了。那么这个Nested Loops(Inner Join)是什么呢?
在讨论聚集索引的时候我们说过,根据键值查询我们只能查询到这个键值所在的数据页,并不能定位到行。那我们怎么才能定位到行呢?
在非聚集索引的数据页中可以根据GroupName获取DepartmentID的值,然后根据DepartmentID的值去聚集索引的索引页中查询,在定位到某个数据页后,再使用DepartmentID的值和数据页中所有的DepartmentID做匹配查询,即Inner Join。