[CVPR2020] StarGAN v2
目录
- 网络改进
- 具体结构
- Generator
- Discriminator
- Style Encoder
- Mapping network
- 损失函数
- Adversarial objective
- Style reconstruction
- Style diversification
- Cycle consistency loss
- Full objective
- 训练过程
- 训练鉴别器
- 训练生成器
- 评价指标
- FID
- LPIPS
- 实验
- 代码笔记
- 我的思考
网络改进
StarGAN v1 中对attribute、domain的定义
We denote the terms attribute as a meaningful feature inherent in an image such as hair color, gender or age, and attribute value as a particular value of an attribute, e.g., black/blond/brown for hair color or male/female for gender. We further denote domain as a set of images sharing the same attribute value. For example, images of women can represent one domain while those of men represent another
StarGAN v2 中对domain、style的定义
domain implies a set of images that can be grouped as a visually distinctive category, and each image has a unique appearance, which we call style. For example, we can set image domains based on the gender of a person, in which case the style in- cludes makeup, beard, and hairstyle
Stargan v1 结构如下:
![[CVPR2020] StarGAN v2_第1张图片](http://img.e-com-net.com/image/info8/60251aea3f4f437598f2060e9044b7bf.jpg)
StarGAN v1 将有同样一个 attribute value 的一组图片作为一个的 domain。以CelebA为例,其attribute包括hair color(attribute values 有 black/blond/brown)、gender(attribute values 有 male/female)等。
问题在于,1、StarGAN 风格转换的图像部分很局限,多样性差;2、这里的attribute需要人工标出,没标出就无法学习,当存在多种style或domain时,很棘手。比如有一组全新domain的图片,你需要将你的图片转换成他的风格,那你需要单独标出.
StarGAN 改进版本,不需要具体标出style标签(attribute),只需1、输入源domain的图像,以及目标domain的一张指定参考图像(Style Encoder网络学习其style code),就可将源图像转换成 目标domain+参考图像style 的迁移图像;或者2、输入源domain的图像,以及随机噪声(mapping网络将其映射为指定domain的随机style code),就可将源图像转换成 目标domain+随机style 的迁移图像
Stargan v2 结构如下:
![[CVPR2020] StarGAN v2_第2张图片](http://img.e-com-net.com/image/info8/9e2d3a6be3774db098357bd0bd06d958.jpg)
改进过程如下表:
![[CVPR2020] StarGAN v2_第3张图片](http://img.e-com-net.com/image/info8/d657b2aec408416b9bb4e2dd74780592.jpg)
基于(A)StarGAN,改进尝试如下,每点改进效果见下图:
- (B)将原ACGAN+PatchGAN的鉴别器 换成 多任务鉴别器,使生成器能转换全局结构。
- (C)引入R1正则与AdIN增加稳定度
- (D)直接引入潜变量z增加多样性(无法有效,只能改变某一固定区域,而不是全局)
- (E)将(D)的改进换成 引入映射网络,输出为每个domain的style code
- (F)多样性正则
具体结构
Generator
对AFHQ数据集如下,4个下采样块,4个中间块以及4个上采样块,如下表所示。对CelebA HQ,下采样以及上采样块数加一。
![[CVPR2020] StarGAN v2_第4张图片](http://img.e-com-net.com/image/info8/29683602bcfa4bb5880a9a7ffa47206f.jpg)
其结构图如下:
![[CVPR2020] StarGAN v2_第5张图片](http://img.e-com-net.com/image/info8/1e2f02d7a9954370bde788d67ab14933.jpg)
其代码如下:
class Generator(nn.Module):
def __init__(self, img_size=256, style_dim=64, max_conv_dim=512, w_hpf=1):
super().__init__()
dim_in = 2**14 // img_size
self.img_size = img_size
self.from_rgb = nn.Conv2d(3, dim_in, 3, 1, 1)
self.encode = nn.ModuleList()
self.decode = nn.ModuleList()
self.to_rgb = nn.Sequential(
nn.InstanceNorm2d(dim_in, affine=True),
nn.LeakyReLU(0.2),
nn.Conv2d(dim_in, 3, 1, 1, 0))
# down/up-sampling blocks
repeat_num = int(np.log2(img_size)) - 4
if w_hpf > 0: #weight for high-pass filtering
repeat_num += 1
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
self.encode.append(
ResBlk(dim_in, dim_out, normalize=True, downsample=True))
self.decode.insert(
0, AdainResBlk(dim_out, dim_in, style_dim,
w_hpf=w_hpf, upsample=True)) # stack-like
dim_in = dim_out
# bottleneck blocks
for _ in range(2):
self.encode.append(
ResBlk(dim_out, dim_out, normalize=True))
self.decode.insert(
0, AdainResBlk(dim_out, dim_out, style_dim, w_hpf=w_hpf))
if w_hpf > 0:
device = torch.device(
'cuda' if torch.cuda.is_available() else 'cpu')
self.hpf = HighPass(w_hpf, device)
def forward(self, x, s, masks=None):
x = self.from_rgb(x)
cache = {}
for block in self.encode:
if (masks is not None) and (x.size(2) in [32, 64, 128]):
cache[x.size(2)] = x
x = block(x)
for block in self.decode:
x = block(x, s)
if (masks is not None) and (x.size(2) in [32, 64, 128]):
mask = masks[0] if x.size(2) in [32] else masks[1]
mask = F.interpolate(mask, size=x.size(2), mode='bilinear')
x = x + self.hpf(mask * cache[x.size(2)])
return self.to_rgb(x)
class AdaIN(nn.Module):
def __init__(self, style_dim, num_features):
super().__init__()
self.norm = nn.InstanceNorm2d(num_features, affine=False)
self.fc = nn.Linear(style_dim, num_features*2)
def forward(self, x, s):
h = self.fc(s)
h = h.view(h.size(0), h.size(1), 1, 1)
gamma, beta = torch.chunk(h, chunks=2, dim=1) ## 分成两块
return (1 + gamma) * self.norm(x) + beta
class ResBlk(nn.Module):
def __init__(self, dim_in, dim_out, actv=nn.LeakyReLU(0.2),
normalize=False, downsample=False):
super().__init__()
self.actv = actv
self.normalize = normalize
self.downsample = downsample
self.learned_sc = dim_in != dim_out
self._build_weights(dim_in, dim_out)
def _build_weights(self, dim_in, dim_out):
self.conv1 = nn.Conv2d(dim_in, dim_in, 3, 1, 1)
self.conv2 = nn.Conv2d(dim_in, dim_out, 3, 1, 1)
if self.normalize:
self.norm1 = nn.InstanceNorm2d(dim_in, affine=True)
self.norm2 = nn.InstanceNorm2d(dim_in, affine=True)
if self.learned_sc:
self.conv1x1 = nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=False)
def _shortcut(self, x):
if self.learned_sc:
x = self.conv1x1(x)
if self.downsample:
x = F.avg_pool2d(x, 2)
return x
def _residual(self, x):
if self.normalize:
x = self.norm1(x)
x = self.actv(x)
x = self.conv1(x)
if self.downsample:
x = F.avg_pool2d(x, 2)
if self.normalize:
x = self.norm2(x)
x = self.actv(x)
x = self.conv2(x)
return x
def forward(self, x):
x = self._shortcut(x) + self._residual(x)
return x / math.sqrt(2) # unit variance ***
class AdainResBlk(nn.Module):
def __init__(self, dim_in, dim_out, style_dim=64, w_hpf=0,
actv=nn.LeakyReLU(0.2), upsample=False):
super().__init__()
self.w_hpf = w_hpf
self.actv = actv
self.upsample = upsample
self.learned_sc = dim_in != dim_out
self._build_weights(dim_in, dim_out, style_dim)
def _build_weights(self, dim_in, dim_out, style_dim=64):
self.conv1 = nn.Conv2d(dim_in, dim_out, 3, 1, 1)
self.conv2 = nn.Conv2d(dim_out, dim_out, 3, 1, 1)
self.norm1 = AdaIN(style_dim, dim_in)
self.norm2 = AdaIN(style_dim, dim_out)
if self.learned_sc:
self.conv1x1 = nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=False)
def _shortcut(self, x):
if self.upsample:
x = F.interpolate(x, scale_factor=2, mode='nearest')
if self.learned_sc:
x = self.conv1x1(x)
return x
def _residual(self, x, s):
x = self.norm1(x, s)
x = self.actv(x)
if self.upsample:
x = F.interpolate(x, scale_factor=2, mode='nearest')
x = self.conv1(x)
x = self.norm2(x, s)
x = self.actv(x)
x = self.conv2(x)
return x
def forward(self, x, s):
out = self._residual(x, s)
if self.w_hpf == 0:
out = (out + self._shortcut(x)) / math.sqrt(2)
return out
class HighPass(nn.Module):
def __init__(self, w_hpf, device):
super(HighPass, self).__init__()
self.filter = torch.tensor([[-1, -1, -1],
[-1, 8., -1],
[-1, -1, -1]]).to(device) / w_hpf
def forward(self, x):
filter = self.filter.unsqueeze(0).unsqueeze(1).repeat(x.size(1), 1, 1, 1)
return F.conv2d(x, filter, padding=1, groups=x.size(1))
其中HighPass相当于一个边缘提取网络,我写了一个测试如下:
img = cv2.imread('celeb.png')
img_ =torch.from_numpy((img)).float().unsqueeze(0).permute(0,3,1,2)
print(img_.shape)
hpf = HighPass(1,'cpu')
out = hpf(img_).permute(0,2,3,1).numpy()
plt.subplot(121)
plt.imshow(img[:,:,::-1])
plt.subplot(122)
plt.imshow(out[0][:,:,::-1])
plt.show()
HighPass Filter 的处理效果如下:
![[CVPR2020] StarGAN v2_第6张图片](http://img.e-com-net.com/image/info8/d86bc4df55314e17a3d0cbaaf3816b91.jpg)
Discriminator
![[CVPR2020] StarGAN v2_第7张图片](http://img.e-com-net.com/image/info8/0670abbdf8aa447b9a05b6154a37ad85.jpg)
其代码如下:
class Discriminator(nn.Module):
def __init__(self, img_size=256, num_domains=2, max_conv_dim=512):
super().__init__()
dim_in = 2**14 // img_size
blocks = []
blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]
repeat_num = int(np.log2(img_size)) - 2
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
blocks += [ResBlk(dim_in, dim_out, downsample=True)]
dim_in = dim_out
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, num_domains, 1, 1, 0)]
self.main = nn.Sequential(*blocks)
def forward(self, x, y):
out = self.main(x)
out = out.view(out.size(0), -1) # (batch, num_domains)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
out = out[idx, y] # (batch)
return out
输入为图像x以及它对应的domain y;鉴别器有multiple output branches,每个支干对应一个domain,该支干输出为一个值,即属于该domain 的概率,最终D的输出为x是否属于domain y的概率
Style Encoder
其结构与鉴别器相同,区别在于结构图中最后一个Linear层,鉴别器是用一个Conv1x1实现,Style Encoder是用多个nn.Linear()代替。代码如下:
class StyleEncoder(nn.Module):
def __init__(self, img_size=256, style_dim=64, num_domains=2, max_conv_dim=512):
super().__init__()
dim_in = 2**14 // img_size
blocks = []
blocks += [nn.Conv2d(3, dim_in, 3, 1, 1)]
repeat_num = int(np.log2(img_size)) - 2
for _ in range(repeat_num):
dim_out = min(dim_in*2, max_conv_dim)
blocks += [ResBlk(dim_in, dim_out, downsample=True)]
dim_in = dim_out
blocks += [nn.LeakyReLU(0.2)]
blocks += [nn.Conv2d(dim_out, dim_out, 4, 1, 0)]
blocks += [nn.LeakyReLU(0.2)]
self.shared = nn.Sequential(*blocks)
self.unshared = nn.ModuleList()
for _ in range(num_domains):
self.unshared += [nn.Linear(dim_out, style_dim)]
def forward(self, x, y):
h = self.shared(x)
h = h.view(h.size(0), -1)
out = []
for layer in self.unshared:
out += [layer(h)]
out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
s = out[idx, y] # (batch, style_dim)
return s
输入为图像x及其所属的domain y,输出为domain y下的x的风格编码s
Mapping network
8层MLP
![[CVPR2020] StarGAN v2_第8张图片](http://img.e-com-net.com/image/info8/b05684aca8b94440b8feb0f1fb48bac4.jpg)
代码如下:
class MappingNetwork(nn.Module):
def __init__(self, latent_dim=16, style_dim=64, num_domains=2):
super().__init__()
layers = []
layers += [nn.Linear(latent_dim, 512)]
layers += [nn.ReLU()]
for _ in range(3):
layers += [nn.Linear(512, 512)]
layers += [nn.ReLU()]
self.shared = nn.Sequential(*layers)
self.unshared = nn.ModuleList()
for _ in range(num_domains):
self.unshared += [nn.Sequential(nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, style_dim))]
def forward(self, z, y):
h = self.shared(z)
out = []
for layer in self.unshared:
out += [layer(h)]
out = torch.stack(out, dim=1) # (batch, num_domains, style_dim)
idx = torch.LongTensor(range(y.size(0))).to(y.device)
s = out[idx, y] # (batch, style_dim)
return s
输入为随机噪声z以及目标domain y,输出为对应的风格编码s
损失函数
Adversarial objective
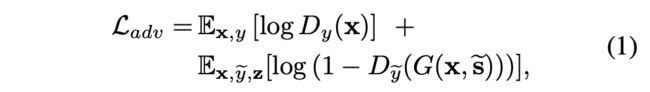
GAN的一般损失,具体实现上,第二项换成non-saturating adversarial loss(又称为 the - log D trick)【参考】
还使用了R1 正则 ,即该文的zero-centered gradient penalty,其公式如下,即鉴别器输出对真实图像的导数的模的平方:
![[CVPR2020] StarGAN v2_第9张图片](http://img.e-com-net.com/image/info8/4487ce81cc0245c4b6e6f18d7bd1e7e6.jpg)
Style reconstruction

意味着要求,转换后的图片也能编码出一致的style code
Style diversification
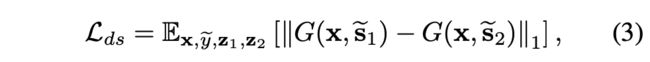
源自MSGAN(省去了分母项),尽可能使合成图像多样性高
Cycle consistency loss
 源自CycleGAN 的损失,保证两次转换后,图像能复原。
源自CycleGAN 的损失,保证两次转换后,图像能复原。
Full objective
总的损失如下:
![[CVPR2020] StarGAN v2_第10张图片](http://img.e-com-net.com/image/info8/fbc95fa6bcd64ca39acc9e8ed3667bc2.jpg)
训练过程
训练鉴别器
![[CVPR2020] StarGAN v2_第11张图片](http://img.e-com-net.com/image/info8/583dfbeff2bb4ef99a11b18304743e10.jpg)
计算loss后,更新D的参数
训练生成器
![[CVPR2020] StarGAN v2_第12张图片](http://img.e-com-net.com/image/info8/ededd67b04c344f09f4709de6a79c16c.jpg)
计算loss后,更新E、M、G的参数
评价指标
FID
Fréchet Inception Distance, NIPS2017,衡量真实图像分布与合成图像分布之间的差异( 具体是指,不同图像在InceptionV3 分类器的高维特征空间中分布密度的差异,该差异用Fréchet Distance进行计算,FID值越小越好)。Fréchet Distance计算公式如下,
![]()
代码见后文calculate_fid_given_paths函数
LPIPS
learned perceptual image patch similarity,CVPR2018 ,衡量影像的多样性(LPIPS越大多样性越高)
Our results indicate that networks trained to solve challenging visual prediction and modeling tasks end up learning a representation of the world that correlates well with perceptual judgments
![[CVPR2020] StarGAN v2_第13张图片](http://img.e-com-net.com/image/info8/dc8818826c0148a78c4f25f7285e231d.jpg)
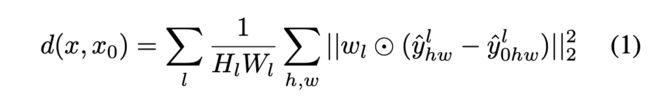
具体计算方法示意图与公式如上,实现上简单的说就是将两张图像输入到ImageNet上预训练的Alex网络,计算每层卷积特征【经归一化及通道层映射后(用1x1 conv)】的平均差异之和。代码见后文calculate_lpips_given_images函数。
另外,除本文中的两个指标外,之前常用的一个Inception Score的公式如下:
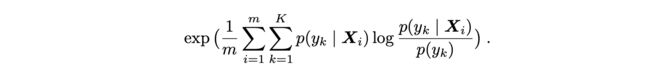
实验
数据集CelebA HQ, AFHQ
(1)Latent-guided synthesis
![[CVPR2020] StarGAN v2_第14张图片](http://img.e-com-net.com/image/info8/46894cc361b64eb1917a6a54a09fdb5c.jpg)
(2)Reference-guided synthesis
![[CVPR2020] StarGAN v2_第15张图片](http://img.e-com-net.com/image/info8/57a0980bb02947abbadd05bd91a464b0.jpg)
(3)Human evaluation
![[CVPR2020] StarGAN v2_第16张图片](http://img.e-com-net.com/image/info8/d50d2561d0df4cb683486f26a329bb3d.jpg)
代码笔记
- 代码主函数部分如下:
def main(args):
print(args)
cudnn.benchmark = True
torch.manual_seed(args.seed)
solver = Solver(args)
if args.mode == 'train':
assert len(subdirs(args.train_img_dir)) == args.num_domains
assert len(subdirs(args.val_img_dir)) == args.num_domains
loaders = Munch(src=get_train_loader(root=args.train_img_dir,
which='source',
img_size=args.img_size,
batch_size=args.batch_size,
prob=args.randcrop_prob,
num_workers=args.num_workers),
ref=get_train_loader(root=args.train_img_dir,
which='reference',
img_size=args.img_size,
batch_size=args.batch_size,
prob=args.randcrop_prob,
num_workers=args.num_workers),
val=get_test_loader(root=args.val_img_dir,
img_size=args.img_size,
batch_size=args.val_batch_size,
shuffle=True,
num_workers=args.num_workers))
solver.train(loaders)
1、输入参数arg 为python标准库推荐的 命令行解析模块 command-line parsing module,可以指定程序运行不同的设置,非常常用,一般用法为:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, required=True,
choices=['train', 'sample', 'eval', 'align'],
help='This argument is used in solver')
parser.add_argument('--train_img_dir', type=str, default='data/celeba_hq/train',
help='Directory containing training images')
args = parser.parse_args()
main(args)
2、torch.backends.cudnn.benchmark 对模型结构以及输入大小固定的算法有 加速作用,具体见该文章。(大意即当该标识位设置为True时,cudnn库会根据不同的模型设置与输入大小找出最优的卷积算法,但如果模型是变化的,则每次都要重新优化找到最佳算法(候选算法包括有GEMM,FFT等),反复寻找反而会浪费时间;当该标识位设置为False时,cudnn库会启发式地选择卷积算法,不一定最快。)(该标识位会影响结果精度,因为算法不同会导致卷积结果细微差别)
torch.backends.cudnn.benchmark = True #加速但不可复现
但该标识位会导致一定程度的不可复现,如果需要完全可复现,需使用以下语句:
torch.manual_seed(seed) # 如用到numpy的随机数,还需要另外设置
torch.backends.cudnn.deterministic = True #使用固定的卷积方式
torch.backends.cudnn.benchmark = False
3、 Munch 类能实现属性风格的访问,类似于Javascript,同时属于Dictionary的子类,有字典的所有特性。
>>> b = Munch()
>>> b.hello = 'world'
>>> b.hello
'world'
>>> b['hello'] += "!"
>>> b.hello
'world!'
>>> b.foo = Munch(lol=True)
>>> b.foo.lol
True
>>> b.foo is b['foo']
True
定义的Munch对象loaders中包含了src、ref 以及 val 的 dataloader,可以方便地调用。
get_train_loader函数部分如下:
def get_train_loader(root, which='source', img_size=256,
batch_size=8, prob=0.5, num_workers=4):
print('Preparing DataLoader to fetch %s images '
'during the training phase...' % which)
crop = transforms.RandomResizedCrop(
img_size, scale=[0.8, 1.0], ratio=[0.9, 1.1])
rand_crop = transforms.Lambda(
lambda x: crop(x) if random.random() < prob else x)
transform = transforms.Compose([
rand_crop,
transforms.Resize([img_size, img_size]), ## 上步已有resize,这行多点多余
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]),
])
if which == 'source':
dataset = ImageFolder(root, transform)
elif which == 'reference':
dataset = ReferenceDataset(root, transform)
else:
raise NotImplementedError
sampler = _make_balanced_sampler(dataset.targets)
return data.DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers,
pin_memory=True,
drop_last=True)
训练数据的预处理包括1)随机裁剪后缩放到256固定大小;2)随机水平翻转;3)像素归一化 (均值方差为0.5)
1、对应source的dataset函数使用torchvision.datasets.ImageFolder产生。数据集CelebA HQ的文件夹包括female 和male 两个folder,folder下为对应的文件,因而该dataset函数返回为(x,y)对应取出来的图像以及其对应的domain标签。
2、对应source的dataset函数使用ReferenceDataset产生,其定义如下,返回两张参考图像以及其对应的label:
class ReferenceDataset(data.Dataset):
def __init__(self, root, transform=None):
self.samples, self.targets = self._make_dataset(root)
self.transform = transform
def _make_dataset(self, root):
domains = os.listdir(root)
fnames, fnames2, labels = [], [], []
for idx, domain in enumerate(sorted(domains)):
class_dir = os.path.join(root, domain)
cls_fnames = listdir(class_dir)
fnames += cls_fnames
fnames2 += random.sample(cls_fnames, len(cls_fnames))
labels += [idx] * len(cls_fnames)
return list(zip(fnames, fnames2)), labels
def __getitem__(self, index):
fname, fname2 = self.samples[index]
label = self.targets[index]
img = Image.open(fname).convert('RGB')
img2 = Image.open(fname2).convert('RGB')
if self.transform is not None:
img = self.transform(img)
img2 = self.transform(img2)
return img, img2, label
def __len__(self):
return len(self.targets)
这里返回两张ref 图像,是为了后续训练生成器时,计算diversity sensitive loss。
3、_make_balanced_sampler定义如下:
def _make_balanced_sampler(labels):
class_counts = np.bincount(labels)
class_weights = 1. / class_counts
weights = class_weights[labels]
return WeightedRandomSampler(weights, len(weights))
np.bincount如其名所示,用法示例如下:
# 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7
x = np.array([0, 1, 1, 3, 2, 1, 7])
# 索引0出现了1次,索引1出现了3次......索引5出现了0次......
np.bincount(x)
#因此,输出结果为:array([1, 3, 1, 1, 0, 0, 0, 1])
# 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7
x = np.array([7, 6, 2, 1, 4])
# 索引0出现了0次,索引1出现了1次......索引5出现了0次......
np.bincount(x)
#输出结果为:array([0, 1, 1, 0, 1, 0, 1, 1])
在这里即对数据集中不同的label计数,计算其占比后对采样器赋相应的倒数权重以进行均衡。
该函数返回torch.utils.data.WeightedRandomSampler作为torch.utils.data.DataLoader的sampler参数,该参数预先就采样好了一个epoch中的数据;一个类似的是batch_sampler预先采样好一个batch中的数据;
4、pin_memory=True
pin_memory 即锁页内存,当计算内存充足时,设置该标识位为True可提高Tensor移到GPU的速度。(默认为False)
Solver类
初始化函数如下:
class Solver(nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.nets, self.nets_ema = build_model(args)
# below setattrs are to make networks be children of Solver, e.g., for self.to(self.device)
for name, module in self.nets.items():
utils.print_network(module, name)
setattr(self, name, module)
for name, module in self.nets_ema.items():
setattr(self, name + '_ema', module)
if args.mode == 'train':
self.optims = Munch()
for net in self.nets.keys():
if net == 'fan':
continue
self.optims[net] = torch.optim.Adam(
params=self.nets[net].parameters(),
lr=args.f_lr if net == 'mapping_network' else args.lr,
betas=[args.beta1, args.beta2],
weight_decay=args.weight_decay)
self.ckptios = [
CheckpointIO(ospj(args.checkpoint_dir, '{:06d}_nets.ckpt'), **self.nets),
CheckpointIO(ospj(args.checkpoint_dir, '{:06d}_nets_ema.ckpt'), **self.nets_ema),
CheckpointIO(ospj(args.checkpoint_dir, '{:06d}_optims.ckpt'), **self.optims)]
else:
self.ckptios = [CheckpointIO(ospj(args.checkpoint_dir, '{:06d}_nets_ema.ckpt'), **self.nets_ema)]
self.to(self.device)
for name, network in self.named_children():
# Do not initialize the FAN parameters
if ('ema' not in name) and ('fan' not in name):
print('Initializing %s...' % name)
network.apply(utils.he_init)
1、torch.device
用于表示torch.Tensor在或者将会被分配到哪个设备上,
>>> torch.device('cuda:0')
device(type='cuda', index=0)
>>> torch.device('cpu')
device(type='cpu')
>>> torch.device('cuda') # 不指定数字,默认为当前 cuda device
device(type='cuda')
2、build_model定义了所有网络,包括Generator,MappingNetwork,StyleEncoder,Discriminator
def build_model(args):
generator = Generator(args.img_size, args.style_dim, w_hpf=args.w_hpf)
mapping_network = MappingNetwork(args.latent_dim, args.style_dim, args.num_domains)
style_encoder = StyleEncoder(args.img_size, args.style_dim, args.num_domains)
discriminator = Discriminator(args.img_size, args.num_domains)
generator_ema = copy.deepcopy(generator)
mapping_network_ema = copy.deepcopy(mapping_network)
style_encoder_ema = copy.deepcopy(style_encoder)
nets = Munch(generator=generator,
mapping_network=mapping_network,
style_encoder=style_encoder,
discriminator=discriminator)
nets_ema = Munch(generator=generator_ema,
mapping_network=mapping_network_ema,
style_encoder=style_encoder_ema)
if args.w_hpf > 0:
fan = FAN(fname_pretrained=args.wing_path).eval()
nets.fan = fan
nets_ema.fan = fan
return nets, nets_ema
这里copy.deepcopy()为深拷贝,对模型generator创建一个独立的复制generator_ema。该复制用于之后训练时对模型参数做滑动平均(文章没有解释原因)
def moving_average(model, model_test, beta=0.999):
for param, param_test in zip(model.parameters(), model_test.parameters()):
param_test.data = torch.lerp(param.data, param_test.data, beta)
输入model 是真正在训练的模型(参数一直更新),model_test (XXX_ema) 为滑动平均值,torch.lerp() 计算结果为 beta * (model_test- model)+ model
此外,这其中还定义了一个预训练好的人脸关键点模型FAN(ICCV2019 AdaptiveWingLoss),其作用为产生关键部位的mask,使得原图像mask区域在转换后仍能得以保留(文章没有提及,在issue部分提到)。
mask如下:
实质上,这个mask确定的就是content,即人脸哪些部分在转换过程中是不变的(保留的关键原图像信息,也就是合成后的人脸让我们觉得还是那个人的部分信息);人脸其余部分则可通过GAN进行多样化转换。
这里就是我看完文章后,很疑惑的部分:模型到底是如何确定哪些该转换,哪些部分不变。之前通过观察文章中的合成图像,我发现不变的content: 脸型、脸摆的角度、表情;变化的style: 头发、肤色、背景; 而看过代码后才发现,就是通过这个mask来确定了不变的content,而这个mask以外的,就是变化的style
除了这个mask指定不变的内容,感觉文章就没有什么非常新的东西了;基于AdIN的style code 之前就有了,通过噪声映射为潜变量增加多样性的工作也很多。不过文章开源就很棒
网络结构如下:
class FAN(nn.Module):
def __init__(self, num_modules=1, end_relu=False, num_landmarks=98, fname_pretrained=None):
super(FAN, self).__init__()
self.num_modules = num_modules
self.end_relu = end_relu
# Base part
self.conv1 = CoordConvTh(256, 256, True, False,
in_channels=3, out_channels=64,
kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = ConvBlock(64, 128)
self.conv3 = ConvBlock(128, 128)
self.conv4 = ConvBlock(128, 256)
# Stacking part
self.add_module('m0', HourGlass(1, 4, 256, first_one=True))
self.add_module('top_m_0', ConvBlock(256, 256))
self.add_module('conv_last0', nn.Conv2d(256, 256, 1, 1, 0))
self.add_module('bn_end0', nn.BatchNorm2d(256))
self.add_module('l0', nn.Conv2d(256, num_landmarks+1, 1, 1, 0))
if fname_pretrained is not None:
self.load_pretrained_weights(fname_pretrained)
def load_pretrained_weights(self, fname):
if torch.cuda.is_available():
checkpoint = torch.load(fname)
else:
checkpoint = torch.load(fname, map_location=torch.device('cpu'))
model_weights = self.state_dict()
model_weights.update({k: v for k, v in checkpoint['state_dict'].items()
if k in model_weights})
self.load_state_dict(model_weights)
def forward(self, x):
x, _ = self.conv1(x)
x = F.relu(self.bn1(x), True)
x = F.avg_pool2d(self.conv2(x), 2, stride=2)
x = self.conv3(x)
x = self.conv4(x)
outputs = []
boundary_channels = []
tmp_out = None
ll, boundary_channel = self._modules['m0'](x, tmp_out)
ll = self._modules['top_m_0'](ll)
ll = F.relu(self._modules['bn_end0']
(self._modules['conv_last0'](ll)), True)
# Predict heatmaps
tmp_out = self._modules['l0'](ll)
if self.end_relu:
tmp_out = F.relu(tmp_out) # HACK: Added relu
outputs.append(tmp_out)
boundary_channels.append(boundary_channel)
return outputs, boundary_channels
@torch.no_grad()
def get_heatmap(self, x, b_preprocess=True):
''' outputs 0-1 normalized heatmap '''
x = F.interpolate(x, size=256, mode='bilinear')
x_01 = x*0.5 + 0.5
outputs, _ = self(x_01)
heatmaps = outputs[-1][:, :-1, :, :]
scale_factor = x.size(2) // heatmaps.size(2)
if b_preprocess:
heatmaps = F.interpolate(heatmaps, scale_factor=scale_factor,
mode='bilinear', align_corners=True)
heatmaps = preprocess(heatmaps)
return heatmaps
@torch.no_grad()
def get_landmark(self, x):
''' outputs landmarks of x.shape '''
heatmaps = self.get_heatmap(x, b_preprocess=False)
landmarks = []
for i in range(x.size(0)):
pred_landmarks = get_preds_fromhm(heatmaps[i].cpu().unsqueeze(0))
landmarks.append(pred_landmarks)
scale_factor = x.size(2) // heatmaps.size(2)
landmarks = torch.cat(landmarks) * scale_factor
return landmarks
3、 setattr用于设置属性的值。self.nets为字典对象,里面包含了各个模型网络,我们需要直接使各个模型为Solver类的属性,以使得后续可使用self.to(device)将模型参数分配到GPU上。
我也写了小程序测试了一下,不加setattr确实对分配到GPU有影响。原因在于self.to()只能将float型参数移动到GPU,无法移动字典类型。另外一个知识点是nn.Module的 .to()是inplace操作,而Tensor的.to()是在拷贝上操作。
import torch
import torch.nn as nn
from munch import Munch
class A(nn.Module):
def __init__(self):
super().__init__()
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.net = Munch(src = nn.Conv2d(1,1,3),
ref = torch.rand((4,1,1,1)),
val = torch.rand((4,1,1,1)))
###注释: 不加下两行,数据在CPU上,加了之后在GPU上
# for name, module in self.net.items():
# setattr(self, name, module)
self.kk=torch.zeros(2,2)
for i in self.net['src'].parameters():
print(i.data.device)
break
self.to(self.device)
for i in self.net['src'].parameters():
print(i.data.device)
break
a = A()
4、CheckpointIO类 用于保存、加载模型,定义如下:
class CheckpointIO(object):
def __init__(self, fname_template, **kwargs):
os.makedirs(os.path.dirname(fname_template), exist_ok=True)
self.fname_template = fname_template
self.module_dict = kwargs
def register(self, **kwargs): ## 该函数没有使用过
self.module_dict.update(kwargs) ## a.update(b) 为将字典b添加到字典a
def save(self, step):
fname = self.fname_template.format(step)
print('Saving checkpoint into %s...' % fname)
outdict = {}
for name, module in self.module_dict.items():
outdict[name] = module.state_dict()
torch.save(outdict, fname)
def load(self, step):
fname = self.fname_template.format(step)
assert os.path.exists(fname), fname + ' does not exist!'
print('Loading checkpoint from %s...' % fname)
if torch.cuda.is_available():
module_dict = torch.load(fname)
else:
module_dict = torch.load(fname, map_location=torch.device('cpu'))
for name, module in self.module_dict.items():
module.load_state_dict(module_dict[name])
**kwargs表示输入为多个关键词的参数(可以理解成字典),CheckpointIO中对应输入为Munch类(属于字典类)的self.nets以及self.optims。还有一种是*args表示输入为多个无名参数。这两个常用于函数定义中,可增加代码灵活性。
5、nn.Module类中.named_children()返回子模块名及子模块本身;.apply(fn)将fn迭代地应用到该模块及其子模块,最典型的用法就是用于模型初始化。
solver.train()StarGAN v2在 CelebA HQ数据集上训练代码如下:
def train(self, loaders):
args = self.args
nets = self.nets
nets_ema = self.nets_ema
optims = self.optims
# fetch random validation images for debugging
fetcher = InputFetcher(loaders.src, loaders.ref, args.latent_dim, 'train')
fetcher_val = InputFetcher(loaders.val, None, args.latent_dim, 'val')
inputs_val = next(fetcher_val)
# resume training if necessary
if args.resume_iter > 0:
self._load_checkpoint(args.resume_iter)
# remember the initial value of ds weight
initial_lambda_ds = args.lambda_ds
print('Start training...')
start_time = time.time()
for i in range(args.resume_iter, args.total_iters):
# fetch images and labels
inputs = next(fetcher)
x_real, y_org = inputs.x_src, inputs.y_src
x_ref, x_ref2, y_trg = inputs.x_ref, inputs.x_ref2, inputs.y_ref
z_trg, z_trg2 = inputs.z_trg, inputs.z_trg2
masks = nets.fan.get_heatmap(x_real) if args.w_hpf > 0 else None
# train the discriminator
d_loss, d_losses_latent = compute_d_loss(
nets, args, x_real, y_org, y_trg, z_trg=z_trg, masks=masks)
self._reset_grad()
d_loss.backward()
optims.discriminator.step()
d_loss, d_losses_ref = compute_d_loss(
nets, args, x_real, y_org, y_trg, x_ref=x_ref, masks=masks)
self._reset_grad()
d_loss.backward()
optims.discriminator.step()
# train the generator
g_loss, g_losses_latent = compute_g_loss(
nets, args, x_real, y_org, y_trg, z_trgs=[z_trg, z_trg2], masks=masks)
self._reset_grad()
g_loss.backward()
optims.generator.step()
optims.mapping_network.step()
optims.style_encoder.step()
g_loss, g_losses_ref = compute_g_loss(
nets, args, x_real, y_org, y_trg, x_refs=[x_ref, x_ref2], masks=masks)
self._reset_grad()
g_loss.backward()
optims.generator.step()
# compute moving average of network parameters
moving_average(nets.generator, nets_ema.generator, beta=0.999)
moving_average(nets.mapping_network, nets_ema.mapping_network, beta=0.999)
moving_average(nets.style_encoder, nets_ema.style_encoder, beta=0.999)
# decay weight for diversity sensitive loss
if args.lambda_ds > 0:
args.lambda_ds -= (initial_lambda_ds / args.ds_iter)
# print out log info
if (i + 1) % args.print_every == 0:
elapsed = time.time() - start_time
elapsed = str(datetime.timedelta(seconds=elapsed))[:-7]
log = "Elapsed time [%s], Iteration [%i/%i], " % (elapsed, i + 1, args.total_iters)
all_losses = dict()
for loss, prefix in zip([d_losses_latent, d_losses_ref, g_losses_latent, g_losses_ref],
['D/latent_', 'D/ref_', 'G/latent_', 'G/ref_']):
for key, value in loss.items():
all_losses[prefix + key] = value
all_losses['G/lambda_ds'] = args.lambda_ds
log += ' '.join(['%s: [%.4f]' % (key, value) for key, value in all_losses.items()])
print(log)
# generate images for debugging
if (i + 1) % args.sample_every == 0:
os.makedirs(args.sample_dir, exist_ok=True)
utils.debug_image(nets_ema, args, inputs=inputs_val, step=i + 1)
# save model checkpoints
if (i + 1) % args.save_every == 0:
self._save_checkpoint(step=i + 1)
# compute FID and LPIPS if necessary
if (i + 1) % args.eval_every == 0:
calculate_metrics(nets_ema, args, i + 1, mode='latent')
calculate_metrics(nets_ema, args, i + 1, mode='reference')
1、InputFetcher类定义如下:
class InputFetcher:
def __init__(self, loader, loader_ref=None, latent_dim=16, mode=''):
self.loader = loader
self.loader_ref = loader_ref
self.latent_dim = latent_dim
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.mode = mode
def _fetch_inputs(self):
try:
x, y = next(self.iter)
except (AttributeError, StopIteration):
self.iter = iter(self.loader)
x, y = next(self.iter)
return x, y
def _fetch_refs(self):
try:
x, x2, y = next(self.iter_ref)
except (AttributeError, StopIteration):
self.iter_ref = iter(self.loader_ref)
x, x2, y = next(self.iter_ref)
return x, x2, y
def __next__(self):
x, y = self._fetch_inputs()
if self.mode == 'train':
x_ref, x_ref2, y_ref = self._fetch_refs()
z_trg = torch.randn(x.size(0), self.latent_dim)
z_trg2 = torch.randn(x.size(0), self.latent_dim)
inputs = Munch(x_src=x, y_src=y, y_ref=y_ref,
x_ref=x_ref, x_ref2=x_ref2,
z_trg=z_trg, z_trg2=z_trg2)
elif self.mode == 'val':
x_ref, y_ref = self._fetch_inputs()
inputs = Munch(x_src=x, y_src=y,
x_ref=x_ref, y_ref=y_ref)
elif self.mode == 'test':
inputs = Munch(x=x, y=y)
else:
raise NotImplementedError
return Munch({k: v.to(self.device)
for k, v in inputs.items()})
try部分用于不断从loader中取出数据,第一次进入try,因为还没定义迭代器,所以产生AttributeError,进入except部分定义self.iter;当取完迭代器中所有数据后,再次进入try取数据,会产生StopIteration而进入except重新加载loader迭代器。含有__next__()函数的对象都可以看成一个迭代器。可以使用next()依次访问其中的内容。
2、训练鉴别器,分两部分,以latent code为输入以及以refenrence为输入。compute_d_loss函数定义如下:
def compute_d_loss(nets, args, x_real, y_org, y_trg, z_trg=None, x_ref=None, masks=None):
assert (z_trg is None) != (x_ref is None)
# with real images
x_real.requires_grad_() ## autograd 开始记录该Tensor上的operation
out = nets.discriminator(x_real, y_org) #D判断real/fake
loss_real = adv_loss(out, 1) # 交叉熵
loss_reg = r1_reg(out, x_real)
# with fake images
with torch.no_grad():
if z_trg is not None:
s_trg = nets.mapping_network(z_trg, y_trg)
else: # x_ref is not None
s_trg = nets.style_encoder(x_ref, y_trg)
x_fake = nets.generator(x_real, s_trg, masks=masks)
out = nets.discriminator(x_fake, y_trg)
loss_fake = adv_loss(out, 0)
loss = loss_real + loss_fake + args.lambda_reg * loss_reg
return loss, Munch(real=loss_real.item(),
fake=loss_fake.item(),
reg=loss_reg.item())
2.1、.requires_grad_()表示让autograd 开始记录该Tensor上的operation。(类似的.requires_grad返回该Tensor是否计算梯度的bool状态),对x_real进行该操作的原因是后续计算r1_reg需要求out对x_real的导数。
2.2、r1_reg源自该文的zero-centered gradient penalty,其公式如下,即鉴别器输出对真实图像的导数的模的平方:
代码如下:
def r1_reg(d_out, x_in):
# zero-centered gradient penalty for real images
batch_size = x_in.size(0)
grad_dout = torch.autograd.grad(
outputs=d_out.sum(), inputs=x_in,
create_graph=True, retain_graph=True, only_inputs=True
)[0]
grad_dout2 = grad_dout.pow(2)
assert(grad_dout2.size() == x_in.size())
reg = 0.5 * grad_dout2.view(batch_size, -1).sum(1).mean(0)
return reg
2.3、with torch.no_grad()下的内容不计算梯度。这样做是因为当前只训练鉴别器,除鉴别器外的其他模型无需产生梯度用于反向传播。可以减少计算以显存占用。
3、训练生成器,同样分两部分,以latent code为输入以及以refenrence为输入。
def compute_g_loss(nets, args, x_real, y_org, y_trg, z_trgs=None, x_refs=None, masks=None):
assert (z_trgs is None) != (x_refs is None)
if z_trgs is not None:
z_trg, z_trg2 = z_trgs
if x_refs is not None:
x_ref, x_ref2 = x_refs
# adversarial loss
if z_trgs is not None:
s_trg = nets.mapping_network(z_trg, y_trg)
else:
s_trg = nets.style_encoder(x_ref, y_trg)
x_fake = nets.generator(x_real, s_trg, masks=masks)
out = nets.discriminator(x_fake, y_trg)
loss_adv = adv_loss(out, 1)
# style reconstruction loss
s_pred = nets.style_encoder(x_fake, y_trg)
loss_sty = torch.mean(torch.abs(s_pred - s_trg))
# diversity sensitive loss
if z_trgs is not None:
s_trg2 = nets.mapping_network(z_trg2, y_trg)
else:
s_trg2 = nets.style_encoder(x_ref2, y_trg)
x_fake2 = nets.generator(x_real, s_trg2, masks=masks)
x_fake2 = x_fake2.detach()
loss_ds = torch.mean(torch.abs(x_fake - x_fake2))
# cycle-consistency loss
masks = nets.fan.get_heatmap(x_fake) if args.w_hpf > 0 else None
s_org = nets.style_encoder(x_real, y_org)
x_rec = nets.generator(x_fake, s_org, masks=masks)
loss_cyc = torch.mean(torch.abs(x_rec - x_real))
loss = loss_adv + args.lambda_sty * loss_sty \
- args.lambda_ds * loss_ds + args.lambda_cyc * loss_cyc
return loss, Munch(adv=loss_adv.item(),
sty=loss_sty.item(),
ds=loss_ds.item(),
cyc=loss_cyc.item())
值得注意的是,在以latent_code为输入时,优化了generator、mapping_network以及style_encoder;但在以reference img为输入时,只优化了generator(为何不优化style_encoder??)。
4、calculate_metrics用于计算FID以及LPIPS,定义如下
@torch.no_grad()
def calculate_metrics(nets, args, step, mode):
print('Calculating evaluation metrics...')
assert mode in ['latent', 'reference']
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
domains = os.listdir(args.val_img_dir)
domains.sort()
num_domains = len(domains)
print('Number of domains: %d' % num_domains)
lpips_dict = OrderedDict()
for trg_idx, trg_domain in enumerate(domains):
src_domains = [x for x in domains if x != trg_domain]
if mode == 'reference':
path_ref = os.path.join(args.val_img_dir, trg_domain)
loader_ref = get_eval_loader(root=path_ref,
img_size=args.img_size,
batch_size=args.val_batch_size,
imagenet_normalize=False,
drop_last=True)
for src_idx, src_domain in enumerate(src_domains):
path_src = os.path.join(args.val_img_dir, src_domain)
loader_src = get_eval_loader(root=path_src,
img_size=args.img_size,
batch_size=args.val_batch_size,
imagenet_normalize=False)
task = '%s2%s' % (src_domain, trg_domain)
path_fake = os.path.join(args.eval_dir, task)
shutil.rmtree(path_fake, ignore_errors=True)
os.makedirs(path_fake)
lpips_values = []
print('Generating images and calculating LPIPS for %s...' % task)
for i, x_src in enumerate(tqdm(loader_src, total=len(loader_src))):
N = x_src.size(0)
x_src = x_src.to(device)
y_trg = torch.tensor([trg_idx] * N).to(device)
masks = nets.fan.get_heatmap(x_src) if args.w_hpf > 0 else None
# generate 10 outputs from the same input
group_of_images = []
for j in range(args.num_outs_per_domain):
if mode == 'latent':
z_trg = torch.randn(N, args.latent_dim).to(device)
s_trg = nets.mapping_network(z_trg, y_trg)
else:
try:
x_ref = next(iter_ref).to(device)
except:
iter_ref = iter(loader_ref)
x_ref = next(iter_ref).to(device)
if x_ref.size(0) > N:
x_ref = x_ref[:N]
s_trg = nets.style_encoder(x_ref, y_trg)
x_fake = nets.generator(x_src, s_trg, masks=masks)
group_of_images.append(x_fake)
# save generated images to calculate FID later
for k in range(N):
filename = os.path.join(
path_fake,
'%.4i_%.2i.png' % (i*args.val_batch_size+(k+1), j+1))
utils.save_image(x_fake[k], ncol=1, filename=filename)
lpips_value = calculate_lpips_given_images(group_of_images)
lpips_values.append(lpips_value)
# calculate LPIPS for each task (e.g. cat2dog, dog2cat)
lpips_mean = np.array(lpips_values).mean()
lpips_dict['LPIPS_%s/%s' % (mode, task)] = lpips_mean
# delete dataloaders
del loader_src
if mode == 'reference':
del loader_ref
del iter_ref
# calculate the average LPIPS for all tasks
lpips_mean = 0
for _, value in lpips_dict.items():
lpips_mean += value / len(lpips_dict)
lpips_dict['LPIPS_%s/mean' % mode] = lpips_mean
# report LPIPS values
filename = os.path.join(args.eval_dir, 'LPIPS_%.5i_%s.json' % (step, mode))
utils.save_json(lpips_dict, filename)
# calculate and report fid values
calculate_fid_for_all_tasks(args, domains, step=step, mode=mode)
4.1 OrderedDict为有序字典, shutil.rmtree删除整个文件夹
4.2 calculate_lpips_given_images定义如下:
@torch.no_grad()
def calculate_lpips_given_images(group_of_images):
# group_of_images = [torch.randn(N, C, H, W) for _ in range(10)]
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
lpips = LPIPS().eval().to(device)
lpips_values = []
num_rand_outputs = len(group_of_images)
# calculate the average of pairwise distances among all random outputs
for i in range(num_rand_outputs-1):
for j in range(i+1, num_rand_outputs):
lpips_values.append(lpips(group_of_images[i], group_of_images[j]))
lpips_value = torch.mean(torch.stack(lpips_values, dim=0))
return lpips_value.item()
同一输入产生10种不同输出,然后计算这些输出两两成对的距离。LPIPS()类定义如下,
class LPIPS(nn.Module):
def __init__(self):
super().__init__()
self.alexnet = AlexNet()
self.lpips_weights = nn.ModuleList()
for channels in self.alexnet.channels:
self.lpips_weights.append(Conv1x1(channels, 1))
self._load_lpips_weights()
# imagenet normalization for range [-1, 1]
self.mu = torch.tensor([-0.03, -0.088, -0.188]).view(1, 3, 1, 1).cuda()
self.sigma = torch.tensor([0.458, 0.448, 0.450]).view(1, 3, 1, 1).cuda()
def _load_lpips_weights(self):
own_state_dict = self.state_dict()
if torch.cuda.is_available():
state_dict = torch.load('metrics/lpips_weights.ckpt')
else:
state_dict = torch.load('metrics/lpips_weights.ckpt',
map_location=torch.device('cpu'))
for name, param in state_dict.items():
if name in own_state_dict:
own_state_dict[name].copy_(param)
def forward(self, x, y):
x = (x - self.mu) / self.sigma
y = (y - self.mu) / self.sigma
x_fmaps = self.alexnet(x)
y_fmaps = self.alexnet(y)
lpips_value = 0
for x_fmap, y_fmap, conv1x1 in zip(x_fmaps, y_fmaps, self.lpips_weights):
x_fmap = normalize(x_fmap)
y_fmap = normalize(y_fmap)
lpips_value += torch.mean(conv1x1((x_fmap - y_fmap)**2))
return lpips_value
4.3 calculate_fid_for_all_tasks定义如下
def calculate_fid_for_all_tasks(args, domains, step, mode):
print('Calculating FID for all tasks...')
fid_values = OrderedDict()
for trg_domain in domains:
src_domains = [x for x in domains if x != trg_domain]
for src_domain in src_domains:
task = '%s2%s' % (src_domain, trg_domain)
path_real = os.path.join(args.train_img_dir, trg_domain)
path_fake = os.path.join(args.eval_dir, task)
print('Calculating FID for %s...' % task)
fid_value = calculate_fid_given_paths(
paths=[path_real, path_fake],
img_size=args.img_size,
batch_size=args.val_batch_size)
fid_values['FID_%s/%s' % (mode, task)] = fid_value
# calculate the average FID for all tasks
fid_mean = 0
for _, value in fid_values.items():
fid_mean += value / len(fid_values)
fid_values['FID_%s/mean' % mode] = fid_mean
# report FID values
filename = os.path.join(args.eval_dir, 'FID_%.5i_%s.json' % (step, mode))
utils.save_json(fid_values, filename)
calculate_fid_given_paths定义如下:
@torch.no_grad()
def calculate_fid_given_paths(paths, img_size=256, batch_size=50):
print('Calculating FID given paths %s and %s...' % (paths[0], paths[1]))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
inception = InceptionV3().eval().to(device)
loaders = [get_eval_loader(path, img_size, batch_size) for path in paths]
mu, cov = [], []
for loader in loaders:
actvs = []
for x in tqdm(loader, total=len(loader)):
actv = inception(x.to(device))
actvs.append(actv)
actvs = torch.cat(actvs, dim=0).cpu().detach().numpy()
mu.append(np.mean(actvs, axis=0))
cov.append(np.cov(actvs, rowvar=False))
fid_value = frechet_distance(mu[0], cov[0], mu[1], cov[1])
return fid_value
frechet_distance定义如下
def frechet_distance(mu, cov, mu2, cov2):
cc, _ = linalg.sqrtm(np.dot(cov, cov2), disp=False)
dist = np.sum((mu -mu2)**2) + np.trace(cov + cov2 - 2*cc)
return np.real(dist)
scipy.linalg.sqrtm计算矩阵开方
我的思考
1、论文的行文以及代码思路都参考了StyleGAN v1
2、与MUNIT区别: a. 并没有将图像完全解耦成style code 与 content code,使用的是G(x,s),而非MUNIT的G(c,s) ; b. 多domain映射; c. 增加了style diversity loss与 R1 正则; d. 增加Mapping网络,将噪声z 映射为style code
与MUNIT相同: a. style rec loss; b. img rec loss;