【Code】OGB:图机器学习的基准测试数据集
1.OGB
1.1 Overview
Open Graph Benchmark(以下简称 OGB)是斯坦福大学的同学开源的 Python 库,其包含了图机器学习(以下简称图 ML)的基准数据集、数据加载器和评估器,目的在于促进可扩展的、健壮的、可复现的图 ML 的研究。
OGB 包含了多种图机器学习的多种任务,并且涵盖从社会和信息网络到生物网络,分子图和知识图的各种领域。没有数据集都有特定的数据拆分和评估指标,从而提供统一的评估协议。
OGB 提供了一个自动的端到端图 ML 的 pipeline,该 pipeline 简化并标准化了图数据加载,实验设置和模型评估的过程。如下图所示:

下图展示了 OGB 的三个维度,包括任务类型(Tasks)、可扩展性(Scale)、领域(Rich domains)。

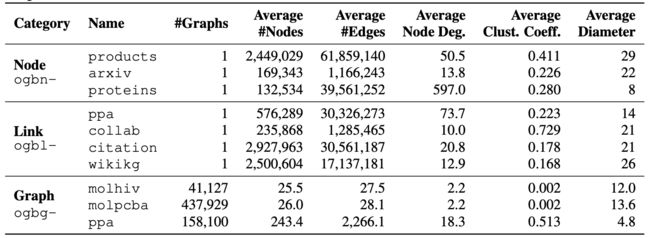
1.2 Dataset
来看一下 OGB 现在包含的数据集:

和数据集的统计明细:
1.3 Leaderboard
OGB 也提供了标准化的评估人员和排行榜,以跟踪最新的结果,我们来看下不同任务下的部分 Leaderboard。
节点分类:

链接预测:

图分类:
2.OGB+DGL
官方给出的例子都是基于 PyG 实现的,我们这里实现一个基于 DGL 例子。
2.1 环境准备
导入数据包
import dgl
import ogb
import math
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from ogb.nodeproppred import DglNodePropPredDataset, Evaluator
查看版本
print(dgl.__version__)
print(torch.__version__)
print(ogb.__version__)
0.4.3post2
1.5.0+cu101
1.1.1
cuda 相关信息
print(torch.version.cuda)
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.cuda.get_device_name(0))
print(torch.cuda.current_device())
10.1
True
1
Tesla P100-PCIE-16GB
0
2.2 数据准备
设置参数
device_id=0 # GPU 的使用 id
n_layers=3 # 输入层 + 隐藏层 + 输出层的数量
n_hiddens=256 # 隐藏层节点的数量
dropout=0.5
lr=0.01
epochs=300
runs=10 # 跑 10 次,取平均
log_steps=50
定义训练函数、测试函数和日志记录
def train(model, g, feats, y_true, train_idx, optimizer):
""" 训练函数
"""
model.train()
optimizer.zero_grad()
out = model(g, feats)[train_idx]
loss = F.nll_loss(out, y_true.squeeze(1)[train_idx])
loss.backward()
optimizer.step()
return loss.item()
@torch.no_grad()
def test(model, g, feats, y_true, split_idx, evaluator):
""" 测试函数
"""
model.eval()
out = model(g, feats)
y_pred = out.argmax(dim=-1, keepdim=True)
train_acc = evaluator.eval({
'y_true': y_true[split_idx['train']],
'y_pred': y_pred[split_idx['train']],
})['acc']
valid_acc = evaluator.eval({
'y_true': y_true[split_idx['valid']],
'y_pred': y_pred[split_idx['valid']],
})['acc']
test_acc = evaluator.eval({
'y_true': y_true[split_idx['test']],
'y_pred': y_pred[split_idx['test']],
})['acc']
return train_acc, valid_acc, test_acc
class Logger(object):
""" 用于日志记录
"""
def __init__(self, runs, info=None):
self.info = info
self.results = [[] for _ in range(runs)]
def add_result(self, run, result):
assert len(result) == 3
assert run >= 0 and run < len(self.results)
self.results[run].append(result)
def print_statistics(self, run=None):
if run is not None:
result = 100 * torch.tensor(self.results[run])
argmax = result[:, 1].argmax().item()
print(f'Run {run + 1:02d}:')
print(f'Highest Train: {result[:, 0].max():.2f}')
print(f'Highest Valid: {result[:, 1].max():.2f}')
print(f' Final Train: {result[argmax, 0]:.2f}')
print(f' Final Test: {result[argmax, 2]:.2f}')
else:
result = 100 * torch.tensor(self.results)
best_results = []
for r in result:
train1 = r[:, 0].max().item()
valid = r[:, 1].max().item()
train2 = r[r[:, 1].argmax(), 0].item()
test = r[r[:, 1].argmax(), 2].item()
best_results.append((train1, valid, train2, test))
best_result = torch.tensor(best_results)
print(f'All runs:')
r = best_result[:, 0]
print(f'Highest Train: {r.mean():.2f} ± {r.std():.2f}')
r = best_result[:, 1]
print(f'Highest Valid: {r.mean():.2f} ± {r.std():.2f}')
r = best_result[:, 2]
print(f' Final Train: {r.mean():.2f} ± {r.std():.2f}')
r = best_result[:, 3]
print(f' Final Test: {r.mean():.2f} ± {r.std():.2f}')
加载数据
device = f'cuda:{device_id}' if torch.cuda.is_available() else 'cpu'
device = torch.device(device)
# 加载数据,name 为 'ogbn-' + 数据集名
# 自己可以打印出 dataset 看一下
dataset = DglNodePropPredDataset(name='ogbn-arxiv')
split_idx = dataset.get_idx_split()
g, labels = dataset[0]
feats = g.ndata['feat']
g = dgl.to_bidirected(g)
feats, labels = feats.to(device), labels.to(device)
train_idx = split_idx['train'].to(device)
2.3 GCN
实现一个基本的 GCN,这里对每一层都进行了一个 Batch Normalization,去掉的话,精度会下降 2% 左右。
from dgl.nn import GraphConv
class GCN(nn.Module):
def __init__(self,
in_feats,
n_hiddens,
n_classes,
n_layers,
dropout):
super(GCN, self).__init__()
self.layers = nn.ModuleList()
self.bns = nn.ModuleList()
self.layers.append(GraphConv(in_feats, n_hiddens, 'both'))
self.bns.append(nn.BatchNorm1d(n_hiddens))
for _ in range(n_layers - 2):
self.layers.append(GraphConv(n_hiddens, n_hiddens, 'both'))
self.bns.append(nn.BatchNorm1d(n_hiddens))
self.layers.append(GraphConv(n_hiddens, n_classes, 'both'))
self.dropout = dropout
def reset_parameters(self):
for layer in self.layers:
layer.reset_parameters()
for bn in self.bns:
bn.reset_parameters()
def forward(self, g, x):
for i, layer in enumerate(self.layers[:-1]):
x = layer(g, x)
x = self.bns[i](x)
x = F.relu(x)
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.layers[-1](g, x)
return x.log_softmax(dim=-1)
model = GCN(in_feats=feats.size(-1),
n_hiddens=n_hiddens,
n_classes=dataset.num_classes,
n_layers=n_layers,
dropout=dropout).to(device)
evaluator = Evaluator(name='ogbn-arxiv')
logger = Logger(runs)
for run in range(runs):
model.reset_parameters()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(1, 1 + epochs):
loss = train(model, g, feats, labels, train_idx, optimizer)
result = test(model, g, feats, labels, split_idx, evaluator)
logger.add_result(run, result)
if epoch % log_steps == 0:
train_acc, valid_acc, test_acc = result
print(f'Run: {run + 1:02d}, '
f'Epoch: {epoch:02d}, '
f'Loss: {loss:.4f}, '
f'Train: {100 * train_acc:.2f}%, '
f'Valid: {100 * valid_acc:.2f}% '
f'Test: {100 * test_acc:.2f}%')
logger.print_statistics(run)
logger.print_statistics()
Run: 01, Epoch: 50, Loss: 1.1489, Train: 68.71%, Valid: 68.93% Test: 68.32%
Run: 01, Epoch: 100, Loss: 1.0565, Train: 71.29%, Valid: 69.61% Test: 68.03%
Run: 01, Epoch: 150, Loss: 1.0010, Train: 72.28%, Valid: 70.57% Test: 70.00%
Run: 01, Epoch: 200, Loss: 0.9647, Train: 73.18%, Valid: 69.79% Test: 67.97%
Training time/epoch 0.2617543590068817
Run 01:
Highest Train: 73.54
Highest Valid: 71.16
Final Train: 73.08
Final Test: 70.43
Run: 02, Epoch: 50, Loss: 1.1462, Train: 68.83%, Valid: 68.69% Test: 68.50%
Run: 02, Epoch: 100, Loss: 1.0583, Train: 71.17%, Valid: 69.54% Test: 68.06%
Run: 02, Epoch: 150, Loss: 1.0013, Train: 71.98%, Valid: 69.71% Test: 68.06%
Run: 02, Epoch: 200, Loss: 0.9626, Train: 73.23%, Valid: 69.76% Test: 67.79%
Training time/epoch 0.26154680013656617
Run 02:
Highest Train: 73.34
Highest Valid: 70.87
Final Train: 72.56
Final Test: 70.42
Run: 03, Epoch: 50, Loss: 1.1508, Train: 68.93%, Valid: 68.49% Test: 67.14%
Run: 03, Epoch: 100, Loss: 1.0527, Train: 70.90%, Valid: 69.75% Test: 68.77%
Run: 03, Epoch: 150, Loss: 1.0042, Train: 72.54%, Valid: 70.71% Test: 69.36%
Run: 03, Epoch: 200, Loss: 0.9679, Train: 73.13%, Valid: 69.92% Test: 68.05%
Training time/epoch 0.26173179904619853
Run 03:
Highest Train: 73.44
Highest Valid: 71.04
Final Train: 73.06
Final Test: 70.53
Run: 04, Epoch: 50, Loss: 1.1507, Train: 69.02%, Valid: 68.81% Test: 68.09%
Run: 04, Epoch: 100, Loss: 1.0518, Train: 71.30%, Valid: 70.19% Test: 68.78%
Run: 04, Epoch: 150, Loss: 0.9951, Train: 72.05%, Valid: 68.20% Test: 65.38%
Run: 04, Epoch: 200, Loss: 0.9594, Train: 72.98%, Valid: 70.47% Test: 69.26%
Training time/epoch 0.2618525844812393
Run 04:
Highest Train: 73.34
Highest Valid: 70.88
Final Train: 72.86
Final Test: 70.60
Run: 05, Epoch: 50, Loss: 1.1500, Train: 68.82%, Valid: 69.00% Test: 68.47%
Run: 05, Epoch: 100, Loss: 1.0566, Train: 71.13%, Valid: 70.15% Test: 69.47%
Run: 05, Epoch: 150, Loss: 0.9999, Train: 72.48%, Valid: 70.88% Test: 70.27%
Run: 05, Epoch: 200, Loss: 0.9648, Train: 73.37%, Valid: 70.51% Test: 68.96%
Training time/epoch 0.261941517829895
Run 05:
Highest Train: 73.37
Highest Valid: 70.93
Final Train: 72.77
Final Test: 70.24
Run: 06, Epoch: 50, Loss: 1.1495, Train: 69.00%, Valid: 68.76% Test: 67.89%
Run: 06, Epoch: 100, Loss: 1.0541, Train: 71.24%, Valid: 69.74% Test: 68.21%
Run: 06, Epoch: 150, Loss: 0.9947, Train: 71.89%, Valid: 69.81% Test: 69.77%
Run: 06, Epoch: 200, Loss: 0.9579, Train: 73.45%, Valid: 70.50% Test: 69.60%
Training time/epoch 0.2620268513758977
Run 06:
Highest Train: 73.70
Highest Valid: 70.97
Final Train: 73.70
Final Test: 70.12
Run: 07, Epoch: 50, Loss: 1.1544, Train: 68.93%, Valid: 68.81% Test: 67.97%
Run: 07, Epoch: 100, Loss: 1.0562, Train: 71.17%, Valid: 69.79% Test: 68.45%
Run: 07, Epoch: 150, Loss: 1.0016, Train: 72.41%, Valid: 70.65% Test: 69.87%
Run: 07, Epoch: 200, Loss: 0.9627, Train: 73.12%, Valid: 69.97% Test: 68.20%
Training time/epoch 0.2620680228301457
Run 07:
Highest Train: 73.40
Highest Valid: 71.02
Final Train: 73.08
Final Test: 70.49
Run: 08, Epoch: 50, Loss: 1.1508, Train: 68.89%, Valid: 68.42% Test: 67.68%
Run: 08, Epoch: 100, Loss: 1.0536, Train: 71.24%, Valid: 69.24% Test: 67.01%
Run: 08, Epoch: 150, Loss: 1.0015, Train: 72.36%, Valid: 69.57% Test: 67.76%
Run: 08, Epoch: 200, Loss: 0.9593, Train: 73.42%, Valid: 70.86% Test: 70.02%
Training time/epoch 0.2621182435750961
Run 08:
Highest Train: 73.43
Highest Valid: 70.93
Final Train: 73.43
Final Test: 69.92
Run: 09, Epoch: 50, Loss: 1.1457, Train: 69.17%, Valid: 68.83% Test: 67.67%
Run: 09, Epoch: 100, Loss: 1.0496, Train: 71.45%, Valid: 69.86% Test: 68.53%
Run: 09, Epoch: 150, Loss: 0.9941, Train: 72.51%, Valid: 69.38% Test: 67.02%
Run: 09, Epoch: 200, Loss: 0.9587, Train: 73.49%, Valid: 70.35% Test: 68.59%
Training time/epoch 0.2621259101231893
Run 09:
Highest Train: 73.64
Highest Valid: 70.97
Final Train: 73.22
Final Test: 70.46
Run: 10, Epoch: 50, Loss: 1.1437, Train: 69.16%, Valid: 68.43% Test: 67.17%
Run: 10, Epoch: 100, Loss: 1.0473, Train: 71.43%, Valid: 70.33% Test: 69.29%
Run: 10, Epoch: 150, Loss: 0.9936, Train: 71.98%, Valid: 67.93% Test: 65.06%
Run: 10, Epoch: 200, Loss: 0.9583, Train: 72.93%, Valid: 68.05% Test: 65.43%
Training time/epoch 0.26213142466545103
Run 10:
Highest Train: 73.44
Highest Valid: 70.93
Final Train: 73.44
Final Test: 70.26
All runs:
Highest Train: 73.46 ± 0.12
Highest Valid: 70.97 ± 0.09
Final Train: 73.12 ± 0.34
Final Test: 70.35 ± 0.21
3.Conclusion
目前,OGB 才刚刚起步,5 月 4 号刚发布第一个主要版本,未来还会扩展到千万级别节点的数据集。OGB 这样的多样且统一的基准的出现对 GNN 来说是非常重要的一步,希望也能形成与 NLP、CV 等领域类似的 Leaderboard,不至于每次论文都是在 Cora, CiteSeer 等玩具型数据集上做实验了。
4.Reference
- Hu, Weihua et al. “Open Graph Benchmark: Datasets for Machine Learning on Graphs.” ArXiv abs/2005.00687 (2020): n. pag.
- 《Open Graph Benchmark》
- 《Github: snap-stanford/ogb》
- 《Github: dmlc/dgl》
- Presentation and Discussion: Open Graph Benchmark
关注公众号跟踪最新内容:阿泽的学习笔记。
