(三)微众Fate-横向联邦学习实践-训练评估
总目录
(一)联邦学习-入门初识
(二)联邦学习-Fate单机部署
(三)微众Fate-横向联邦学习实践-训练评估
(四)微众Fate-横向学习联邦-预测
(五)微众Fate-横向联邦学习实践-在线预测
以经典的分类问题判断肿瘤良性恶性为例,使用横向联邦学习,基于逻辑回归进行训练。基于前一章已经部署好的单机Fate进行实践。
目录
- 1. 准备上传数据
- 2.编写上传数据配置upload_data_role.json
- 3. 上传数据
- 4. 建模
- 4.1 编写dsl配置
- 4.1.1 建模数据流定义
- 4.1.2 训练输入输出定义
- 4.1.2 评估输入输出定义
- 4.2 编写运行配置
- 4.2.1 定义建模角色以及运行模式
- 4.2.2 定义角色参数
- 4.2.2.1 guest角色参数
- 4.2.2.2 host角色参数
- 4.3 定义算法配置
- 5. 开始训练评估任务
- 6. 查看结果
- 6.1 查看dataio_0执行结果
- 6.2 查看dataio_1执行结果
- 6.3 查看分析训练结果
- 6.3.1 homo_lr_0
- 6.3.2 homo_lr_1
- 6.4 查看模型评估结果
- 6.4.1 homo_lr_0模型评估evalation_0 结果
- 6.4.2 homo_lr_1模型评估evalation_1 结果
1. 准备上传数据
我们直接使用Fate提供的案例数据目录在examples/data/breast_homo_guest.csv、examples/data/breast_homo_host.csv、
这里上传数据需要准备host以及guest两方的上传数据
根据官方解释在Fate的概念中分成3种角色,Guest、Host、Arbiter
Guest表示数据应用方,Host是数据提供方,在纵向算法中,Guest往往是有标签y的一方。arbiter是用来辅助多方完成联合建模的,主要的作用是用来聚合梯度或者模型,比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等,arbiter还参与以及分发公私钥,进行加解密服务等等。一般是由数据应用方Guest发起建模流程。
2.编写上传数据配置upload_data_role.json
编写host的上传配置文件upload_data_host.json
{
"file":"examples/data/breast_homo_host.csv",
"head":1,
"partition":10,
"work_mode":0,
"table_name":"fuqlaihomo_breast_host",
"namespace":"fuqlaihomo_breast_host"
}
字段说明:
- file: 文件路径
- head: 指定数据文件是否包含表头
- partition: 指定用于存储数据的分区数
- work_mode: 指定工作模式,0代表单机版,1代表集群版
- table_name&namespace: 存储数据表的标识符号
编写guest的上传配置文件upload_data_guest.json
{
"file":"examples/data/breast_homo_guest.csv",
"head":1,
"partition":10,
"work_mode":0,
"table_name":"homo_breast_guest",
"namespace":"homo_breast_guest"
}
3. 上传数据
上传数据命令:
python ${your_install_path}/fate_flow/fate_flow_client.py -f upload -c ${upload_data_json_path}
${your_install_path}: fate的安装目录
${upload_data_json_path}:上传数据配置文件路径
注:每个提供数据的集群(即guest和host)都需执行此步骤 运行此命令后,如果成功,将显示以下信息:
docker exec -it fate_python bash进入fate节点内部
导入训练数据、测试数据以及评估数据输入以下命令
python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_logistic_regression/upload_data_guest.json
python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_logistic_regression/upload_data_host.json
python fate_flow/fate_flow_client.py -f upload -c examples/federatedml-1.x-examples/homo_logistic_regression/upload_data_test.json
控制台显示以下提示表示上传成功
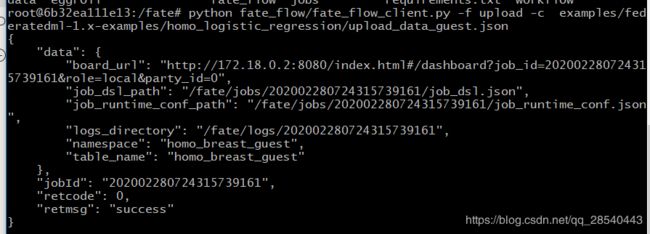
打开fate监控面板fate_board http://${boardhost}:8080
根据上传完之后的job_id查询得,刚刚上传的两个任务

选择具体的任务查看详细信息
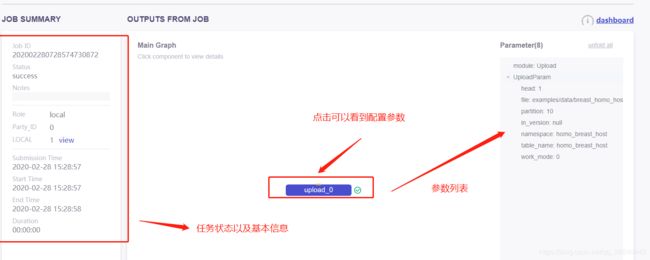
4. 建模
4.1 编写dsl配置
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的领域特定语言 (DSL) 来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
为了尝试多一点的组件,我们的实践将涵盖训练以及评估模型。
4.1.1 建模数据流定义
使用dataio组件,基于上一步上传好的数据定义建模数据输入/输出
这个例子里面定义了两个dataio,分别输出训练数据以及评估数据
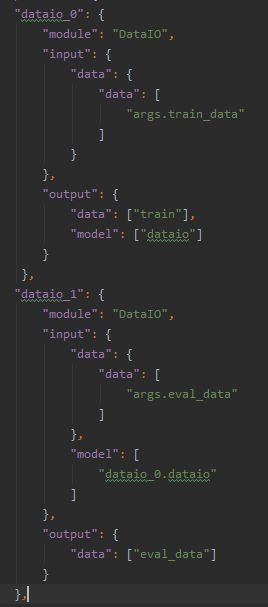
组件结构体具体说明:https://github.com/FederatedAI/FATE/blob/master/doc/dsl_conf_setting_guide_zh.md
4.1.2 训练输入输出定义

将dataio_0的输出对象作为训练的输入数据对象,输出横向联邦学习逻辑回归训练模型以及训练数据。
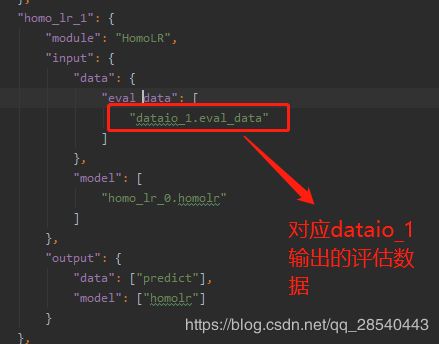
同理对评估数据进行训练定义,将dataio_1的输出对象以及homo_lr0的训练模型作为评估的输入数据对象,输出横向联邦学习逻辑回归训练模型以及评估数据。
4.1.2 评估输入输出定义
对评估数据集基于homo_lr_0输出的模型进行训练并且输出预测结果以及模型。
4.2 编写运行配置
运行配置主要是用于指定guest、host、arbiter运行dsl任务相关配置,具体查看https://github.com/FederatedAI/FATE/blob/master/doc/dsl_conf_setting_guide_zh.md
4.2.1 定义建模角色以及运行模式
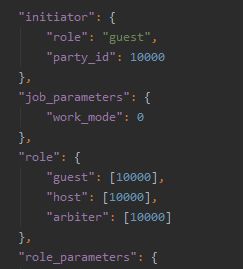
4.2.2 定义角色参数
主要包括data数据结构定义以及组件配置按照角色区份。
4.2.2.1 guest角色参数
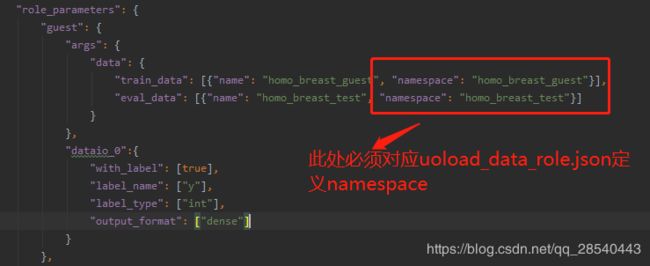
4.2.2.2 host角色参数
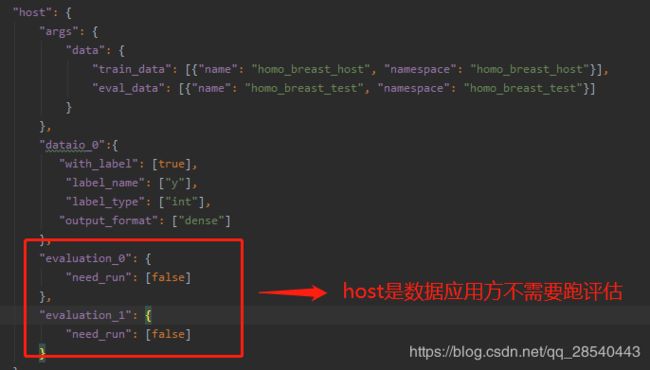
4.3 定义算法配置
具体查看算法参数https://github.com/FederatedAI/FATE/blob/master/federatedml/param
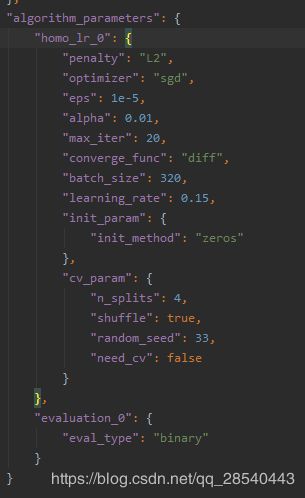
5. 开始训练评估任务
具体命令如下:
python {fate_install_path}/fate_flow/fate_flow_client.py -f submit_job -c ${runtime_config} -d ${dsl}
c${runtime_config}:运行配置文件路径
${dsl}:dsl文件路径
控制台输出命令:
python fate_flow/fate_flow_client.py -f submit_job -c examples/federatedml-1.x-examples/homo_logistic_regression/test_homolr_evaluate_job_conf.json -d examples/federatedml-1.x-examples/homo_logistic_regression/test_homolr_evaluate_job_dsl.json
控制台与监控面板显示如下信息
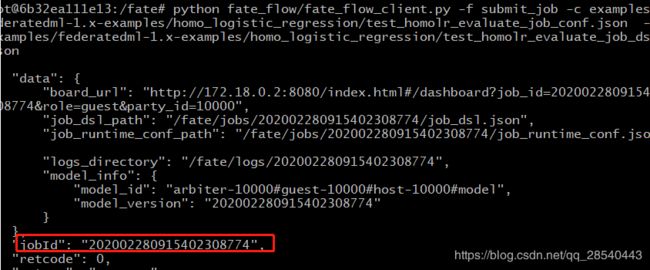
显示运行进度:
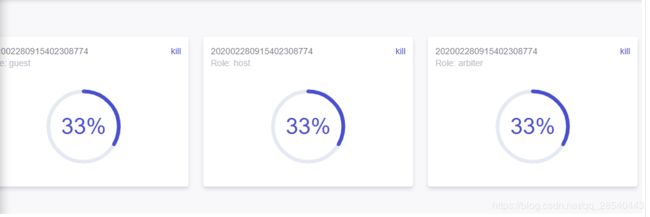
6. 查看结果
通过监控面板查看job执行结果 ,通过job_id查询对应任务
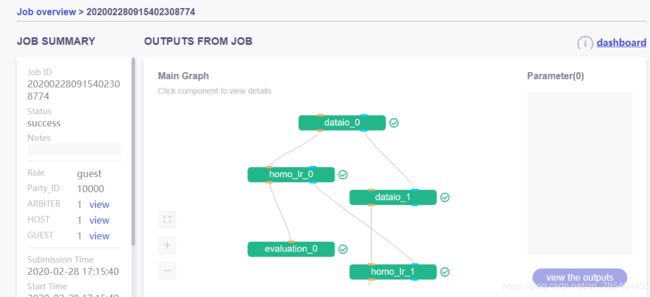
可以看到建模的每个过程组成的DAG图
6.1 查看dataio_0执行结果
根据dsl定义的输出我们点击"view the outputs"查看结果如何
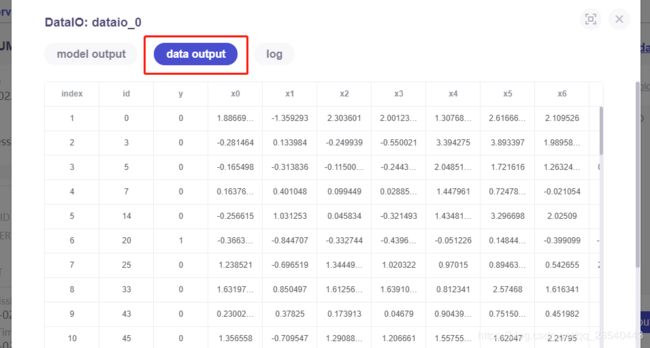
由于输出类型是data类型,可以在"data output"看到输入的数据列表项如上
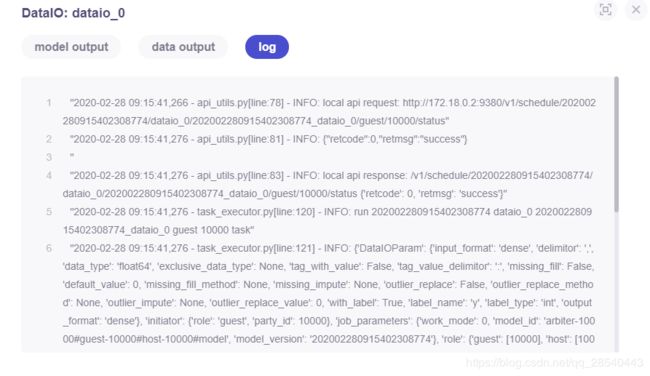
点击"log"可以查看日志
6.2 查看dataio_1执行结果
dataio_1是用于评估的数据,数据输出结果如下

6.3 查看分析训练结果
6.3.1 homo_lr_0
homo_lr_0是分别在guest,host训练homo_breast_guest以及homo_breast_host得出最终模型
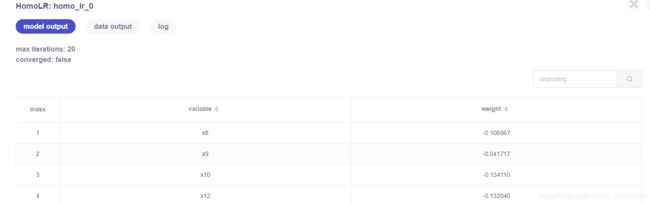
最大迭代次数为20
是否收敛:false
下面表格列出所有特征variable以及通过LR分类得出特征对应权值weight
下面还有一个曲线图,表示LR损失函数值随着迭代次数的变化
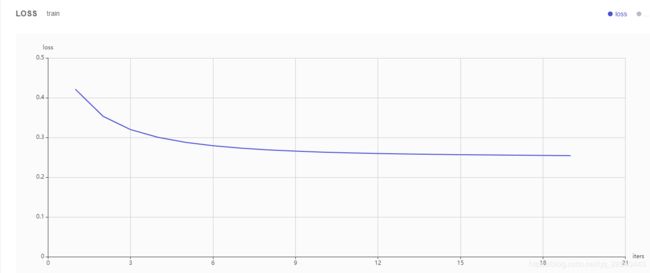
查看data output 训练结果如下

id:id
label: 标签值,真实结果
predict_result: 预测结果
predict_score: 预测得分
predict_detail:预测结果的细节
6.3.2 homo_lr_1
home_lr_1是基于homo_lr_0预测test数据集的结果。
输出模型结果如下:

查看data output 训练结果如下:

6.4 查看模型评估结果
6.4.1 homo_lr_0模型评估evalation_0 结果
模型评估结果如下:
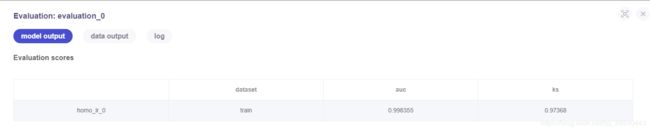
这里的auc值、ks值显示训练数据集的正样本概率以及好坏样本累计差异率
下面是几种常见评估曲线
| 序号 | 中文 | 简称 | 描述 |
|---|---|---|---|
| 1 | 受试者特征工作曲线 | ROC | 用于描述模型分辨能力,对角线以上的图形越高越好, ROC=0.5表示模型的预测能力与随机结果没有差别 |
| 2 | 洛伦兹曲线 | K-S | KS用于模型风险区分能力进行评估,指标衡量的是好坏样本累计分部之间的差值。好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。 |
| 3 | Lift曲线 | Lift | Lift图衡量的是,与不利用模型相比,模型的预测能力“变好”了多少,lift(提升指数)越大,模型的运行效果越好。 |
| 4 | 增益图 | Gain | Gain图是描述整体精准度的指标。 |
| 5 | 召回率 | Precison Recall | 针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。 |
| 6 | 精确率 | Accuracy | 精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是对的 |

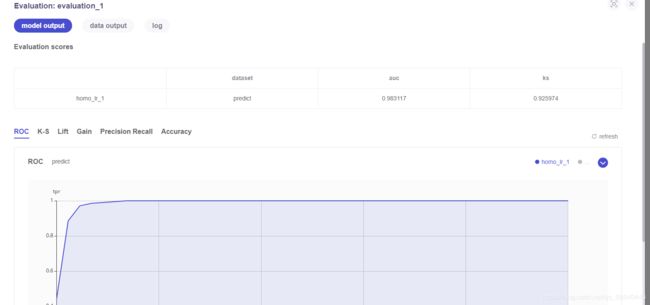
6.4.2 homo_lr_1模型评估evalation_1 结果
homo_lr_1使用homo_lr_0训练的模型对test数据集进行预测,得出的结果如下图,相对evalation_0各部分指标略有下降。
下一篇:(四)微众Fate-横向联邦学习-预测