Python3-正则表达式-创建、匹配Regex对象
用正则表达式查找文本模式
字符串中查找电话号码。只知道模式: 3个数字,一个短横线,4个数字,一个短横线,再是4个数字。例如:010-8888-8888,或010.8888.8888或(010) 8888-8888
还有分机010-8888-8888 转456 该怎么办呢?????可以创建函数,来检查字符串是否匹配模式,添加更多的代码来处理额外的模式,但还有更简单的方法。
正则表达式,简称为regex,是文本模式的描述方法。\d是一个正则表达式,表示一位数字字符,即任何一位0到9的数字。python使用正则表达式:
\d\d\d-\d\d\d\d-\d\d\d\d,来匹配。但正则表达式可以复杂很多,例如:
在 一个模式后加上花括号包围的3({3}),就是说,”匹配这个模式3次”。所以较短的正则表达式\d{3}-\d{4}-\d{3},也匹配正确的电话号码格式。
创建正则表达式对象
python中所有正则表达式的函数都在re模式中。在交互式环境中输入一下代码,导入该模块:
![]()
向re.compile()传入一个字符串值,表示正则表达式,它将返回一个Regex模式对象(或者就简称Regex对象)。
要创建一个Regex对象来匹配电话号码模式,就在交互式环境中输入以下代码:
匹配Regex对象
Regex对象的search()方法查找传入的字符串,寻找该正则表达式的所有匹配。如果字符串中没有找到该正则表达式模式,search()方法将返回None。如果找到了该模式,search()方法将返回一个Match对象。Match对象有一个group()方法,它返回被查找字符中实际匹配的文本。

利用括号分组
向group()方法传入0或不传入参数,将返回整个匹配的文本,传入1或2就可以匹配文本的不同部分。

如果要一次就获取所有的分组,使用groups()方法。

用管道匹配多个分组
字符|称为”管道”,希望匹配许多表达式中的一个时,就可以使用它

假设希望匹配’Batman’、’Batmobile’、’Batbat’中任意一个。因为所有这些字符串都以Bat开始,所以如果能够只指
定一次前缀,就很方便,可以通过括号实现。

方法调用mo.group()返回了完全匹配的文本’Batmobile’,而mo.group(1)只是返回第一个括号分组内的匹配文本’mobile’。通过使用管道字符和分组括号,可以指定几种可选的模式,让正则表达式去匹配。
用问号实现可选匹配
有时候,想匹配的模式是可选的。就是说,不论这段文本在不在,正则表达式都会认为匹配。字符?表明它前面的分组在这个模式中是可选的。例如:

正则表达式中的(wo)?部分表明,模式wo是可选的分组。该正则表达式匹配的文本中,wo将出现零次或一次。这就是为什么正则表达式既匹配’Batwoman’,又匹配’Batman’。
利用电话号码,让正则表达式寻找包含区号或不包含区号的电话号码。

可以认为 “匹配这个问号之前的分组零次或一次”
如果需要匹配真正的问号字符,就使用转义字符\?
用星号匹配零次或多次
*(称为星号)意味着“匹配零次或多次”,既星号之前的分组,可以在本文中出现任意次,它可以完全不存在,或一次又一次的重复。

对于’Batman’,正则表达式的(wo*)部分匹配wo的零个实例。对于’Batwoman’,(wo)*匹配wo的一个实例。
对于’Batwowowowoman’,(wo)*匹配wo的4个实例。
如果需要匹配真正的星号字符,就在正则表达式的星号字符前加上倒斜杠,即*。
用加号匹配一次或多次
*意味着’匹配零次或多次’,+(加号)则意味着’匹配一次或多次’。星号不要求分组出现在匹配的字符串中,但加号不同,加号前面的分组必须’至少出现一次’。这不是可选的。

正则表达式Bat(wo)+man 不会匹配字符串’The Adventures of Regex’,因为加号要求WO至少出现一次。
如果需要匹配真正的加号字符,在加号前面加上倒斜杠转义: +。
用花括号匹配特定次数
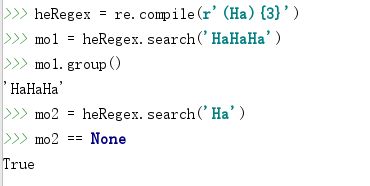
如果想要一个分组重复特定次数,就在正则表达式中该分组的后面,跟上花括号包围的数字。例如,正则表达式(Ha){3},将匹配字符串’HaHaHa’,但不会匹配’HaHa’,因为后者只重复了(Ha)分组俩次。
除了一个数字,还可以指定一个范围,即在花括号中写下一个最小值、一个逗号和一个最大值。例如,正则表达式(Ha){3,5}将匹配3次至5次的’Ha’。
也可以不写花括号中的第一个或第二个数字,不限定最小值或最大值。例如:(Ha){3,}将匹配3次或更多次实例。花括号让正则表达式更简短。
贪心和非贪心匹配
在字符串’HaHaHaHaHa’中,因为(Ha){3,5}可以匹配3个、4个或5个实例,你可能会想,为什么在前面花括号的例子中,Match对象的group()调用会返回’HaHaHaHaHa’,而不是更短的可能结果。毕竟,’HaHaHa’和
‘HaHaHaHaHa’也能够有效地匹配正则表达式(Ha){3,5}。
python的正则表达式默认是’贪心’的,这表示在有二义的情况下,它们会尽可能匹配最长的字符串。花括号的’非贪心’版本匹配尽可能最短的字符串,即在结束的花括号后跟着一个问号。
在交互式环境中输入一下代码,注意在查找相同字符串时,花括号的贪心形式和非贪心形式之间的区别:

请注意,问号在正则表达式中可能有俩种含义: 声明非贪心匹配或表示可选的分组。这两种含义是完全无关的。
findall()方法
除了search()方法外,Regex对象也有一个findall()方法。search()将返回一个Match对象,包含被查找字符串中的’第一次’匹配的文本,而findall()方法将返回一组字符串,包含被查找到字符串中的所有匹配。
看看search()返回Match对象只包含一次出现的匹配文本。

另一方面,findall()不是返回一个Match对象,而是返回一个字符串列表,只要在正则表达式中没有分组,列表中的每个字符串都是一段被查找的文本,它匹配该正则表达式。在交互式环境中输入以下代码:

如果在正则表达式中有分组,那么findall将返回元组的列表,每个元组表示一个找到的匹配,其中的项就是正则表达式中每个分组的匹配字符串。为了看看findall()的效果.

作为findall()方法的返回结果的总结,记住下面两点:
1.如果调用在一个没有分组的正则表达式上,例如[‘010-8888-8888’,’010-6666-6666’]。
2.如果调用在一个没有分组的正则表达式上,例如(\d\d\d)-(\d\d\d\d)-(\d\d\d\d),方法findall()将返回一个字符串的元组的列表,(每个分组对应一个字符串),例如[(‘010’,’8888’,’8888’),(‘010’,’6666’,’6666’)]。
字符分类
在前面电话号码正则表达式的例子中,你知道\d可以代表任何数字。也就是说,\d是正则表达式(0|1|2|3|4|5|6|7|8|9)的缩写。有许多这样的’缩写字符分类’,
常用字符分类的缩写代码:
缩写字符分类 表示
\d 0到9的任何数字
\D 除0到9的数字以外的任何字符
\w 任何字母,数字或下划线字符,可以认为是匹配,单词,字符,
\W 除字母,数字和下划线以外的任何字符
\s 空格,制表符或换行符,可以认为是匹配,空白 ,字符
\S 除空格,制表符和换行符以外的任何字符,字符分类对于缩短正则表达式很有用,字符分类[0-5]匹配数字0到5,这比输入(0|1|2|3|4|5)要短很多。

正则表达式\d+\s\w+匹配的文本有一个或多个数字(\d+),接下来是一个空白字符(\s),接下来是一个或多个字母,数字,下划线字符(\w+)。findall()方法将返回所有匹配该正则,表达式的字符串,放在一个列表中。
建立自己的字符分类
有时候你想匹配一组字符,但缩写的字符分类(\d\w\s等)太宽泛。你可以用方括号定义自己的字符分类。例如,[aeiouAEIOU]字符分类,将匹配所有元音字符,不论大小写。

也可以使用短横表示字母或数字的范围。例如,字符分类[a-zA-Z0-9]将匹配所有小写字母,大写字母和数字。
请注意,在方括号内,普通的正则表达符号不会被解释,这意味着,你不需要前面加上倒斜杠转义. 、*、?或()字符。例如,字符分类将匹配数字0到5和一个句点。你不需要将它写成[0-5.]。
通过在字符分类的左方括号后加上一个插入字符(^),就可以得到’非字符类’。非文字符类,将匹配不在这个字符类中的所有字符。

现在,不是匹配所有元音字符,而是匹配所有非元音字符。
插入字符和美元字符
可以在正则表达式的开始处使用插入符号(^),表明匹配必须发生在被查找文本开始处。类似的,可以在正则表达的末尾加上美元符号($),表示该字符,必须以这个正则表达式的模式结束。可以同时使用^和$, 表明整个字符串必须匹配该模式,也就是说,只匹配该字符串的某个子集是不够的。

正则表达式r’^\d+$’匹配从开始到结束都是数字的字符串。
通配字符
在正则表达式中,.(句点)字符称为”通配符”。它匹配除了换行之外的所有字符。
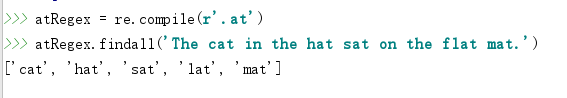
要记住,句点字符只匹配一个字符,这就是为什么在前面的例子中,对于文本flat,只匹配lat。要匹配真正的句点,就是用倒斜杠转义:\.。
用点-星匹配所有字符,
有时候想要匹配所有字符串,例如,假定想要匹配字符串,’FirstName’,接下来是任意文本,接下来是‘Last Name:’,然后又是任意文本。可以用点-星(.*)表示”任意文本,回忆一下,句点字符表示“除换行外所有单个字符”,星号字符表示,“前面字符出现零次或多次”。

点-星使用’贪心’模式:他总是匹配尽可能多的文本,要用”非贪心”模式匹配所有文本,就是使用点-星和问号。像和大括号一起使用时那样,问号告诉,python用非贪心模式匹配。


两个正则表达式都可以翻译成”匹配一个左尖括号,接下来是任意字符,接下来是一个右尖括号’。但是字符串’<\to serve man> for dinner.>’对右尖括号有两种可能的匹配。在非贪心的正则表达式中,python匹配最短可能的字符串:’<\to serve man>’。在贪心版本中,python匹配最长可能的字符串:<\to serve man>for dinner.>’。
用句点字符匹配换行
点-星将匹配出换行之外的所有字符。通过传入re.DOTALL作为re.compile()的第二个参数,可以让句点匹配所有字符,包括换行字符。


正则表达式noNewlineRegex在创建时没有向re.compile()传入re.DOTALL,它将匹配所有字符,直到第一个换行符。但是,newlineRegex在创建时向re.compile()传入了re.DOTALL,它将匹配所有字符。这就是为什么newlineRegex.search()调用匹配完整的字符串,包括其中的换行字符。
正则表达式符号复习
? 匹配零次或一次前面的分组
* 匹配零次或多次前面的分组
+ 匹配一次或多次前面的分组
{n} 匹配n次前面的分组
{n,} 匹配n次或更多前面的分组
{,m} 匹配零次到m次前面的分组
{n,m} 匹配至少n次、至多m次前面的分组
{n,m}?或+?对前面的分组进行非贪心匹配
^spam意味着字符串必须以spam开始。
spam$意味着字符串必须以spam结束。
. 匹配所有字符,换行符除外。
\d、\w和\s 分别匹配数字,单词和空格
\D、\W和\S 分别匹配出数字单词和空格外的所有字符
[abc] 比配方括号内的任意字符
[^abc] 匹配不在方括号内的任意字符
不区分大小写的匹配
通常,正则表达式用你指定的大小写匹配文本。例如,下面的正则表达式匹配完全不同的字符串:

但是,有时候你只关心匹配字母,不关心他们是小写或大写,要让正则表达式不区分大小写,可以向re.compile()传入re.IGNORECASE或re.I,作为第二个参数。

用sub()方法替换字符串
正则表达式不仅能找到文本模式,而且能够用新的文本替换掉这些模式。Regex对象的sub()方法需要传入两个参数。第一个参数是一个字符串,用于取代发现的匹配。第二个参数是一个字符串,既正则表达式。sub()方法返回替换完成后的字符串。

有时候,你可能需要使用匹配的文本本身,作为替换的一部分。在sub()的第一个参数中,可以输入\1\2\3……。表示”在替换中输入分组1、2、3……的文本”。
例如,假定想要隐去密探的姓名,只显示他们姓名的第一字母。要做到这一点,可以使用正则表达式Agent(\w)\w*,传入r’\1****’作为sub()的第一个参数。字符串中的\1将由分组1匹配的文本所替代,也就是正则表达式的(\w)分组。

管理复杂的正则表达式
如果要匹配的文本模式很简单,正则表达式就很好。但匹配复杂的文本模式,可能需要长的、费解的正则表达式。你可以告诉re.compile(),忽略正则表达式字符串中的空白符和注释,从而缓解这一点。要实现这种详细模式,可以向re.compile()传入变量re.VERBOSE,作为第二个参数。
不必使用这样难以阅读的正则表达式:
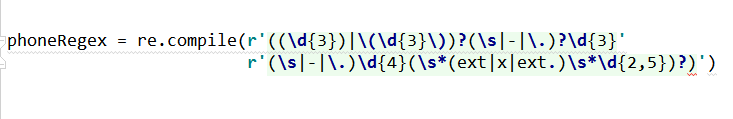
可以将正则表达式放在多行中,并加上注释,像这样:
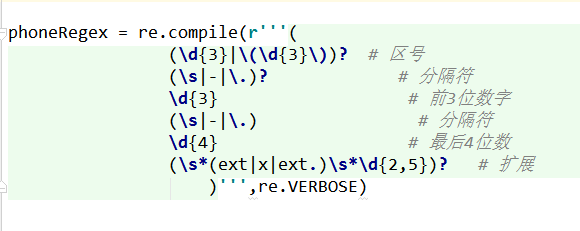
请注意,前面的例子使用了三重引号(”’),创建了一个多行字符串。这样就可以将正则表达式定义放在多行中,让它更可读。
正则表达式字符串中的注释规则,与普通的python代码一样: #符号和它后面直到行末的内容,都被忽略。而且,表示正则表达式的多行字符串中,多余的空白字符也不认为是要匹配的文本模式的一部分。这让你能够组织正则表达式,让它更可读。