【Python爬虫入门级】爬取彼岸图网整站4K原图
先获取4k图片各个目录的首页链接,抓取4k风景、4k美女…这一栏就可以了。
对http://pic.netbian.com发送一个get请求,分析请求回来的数据包,解析出各个分类首页链接!
查看下载原图按钮的请求路径,发现这个是js动态绑定的事件,然后去找js源码!
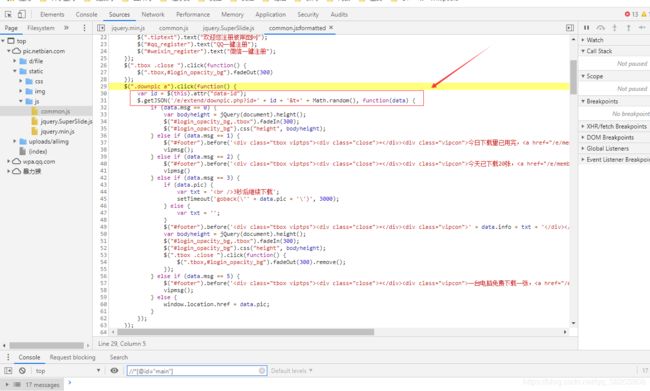
通过js源码,我们可以发现,他是获取按钮上的data-id数值,发送一个 /e/extend/downpic.php?id= data-id &t= 0-1随机数字 请求,获取一个json数据,json数据里面携带了三个内容:
- msg:整数,判断用户状态的(是否会员,是否用完下载次数,是否未登录用户第一次下载)
- info: 文本信息
- pic: 图片真实链接
然后带着会员信息的cookies请求它就可以,会员每天限制下载200张!破解限制暂时没有研究,暂时没这个需求!我只是单纯的想一键快速下载一些美图做电脑锁屏界面的幻灯片而已!
代码如下:
import json
import os
import random
import sys
from concurrent.futures.thread import ThreadPoolExecutor
import pymysql
from lxml import etree
from requests import *
class Spider:
def __init__(self):
self.cookies = self.readCookies()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
self.indexUrl = "http://pic.netbian.com"
self.catelogue = self.getCatalogue()
# 每天限量只能下载200张
self.downCount = 0
self.ddir = 'D:\\Data\\照片\\彼岸图网\\'
def readCookies(self):
cookies = {}
with open("cookie.txt", "r", encoding="utf-8") as f:
while True:
c = f.readline()
if c is not None:
c = c.strip()
if len(c) == 0:
break
else:
c = c.split("=")
cookies[c[0]] = c[1]
else:
break
return cookies
def reqGet(self, url):
html = get(url, headers=self.headers, cookies=self.cookies).content.decode("gbk")
return html
def getImg(self, url):
return get(url, headers=self.headers, cookies=self.cookies)
def getCatalogue(self):
index = self.reqGet(self.indexUrl)
h = etree.HTML(index)
href = h.xpath('//div[@class="classify clearfix"]/a/@href')
title = h.xpath('//div[@class="classify clearfix"]/a/text()')
return zip(title, href)
def getRealUrl(self, href):
"""
('阿尔卑斯山风景4k高清壁纸3840x2160', 'http://pic.netbian.com/downpic.php?id=21953&classid=53')
"""
dh = self.reqGet(self.indexUrl + href)
h = etree.HTML(dh)
dataId = h.xpath('//div[@class="downpic"]/a/@data-id')[0]
title = h.xpath('//div[@class="photo-hd"]/h1/text()')[0]
url = "{0}/e/extend/downpic.php?id={1}&t={2}".format(self.indexUrl, dataId, random.random())
msg = self.reqGet(url)
return title, self.indexUrl + json.loads(msg)['pic']
def getPicUrls(self, url=None, html=None):
if html is None:
html = self.reqGet(url)
h = etree.HTML(html)
hrefs = h.xpath('//ul[@class="clearfix"]/li/a/@href')
realHrefs = []
for href in hrefs:
realHrefs.append(self.getRealUrl(href))
return realHrefs
def getMaxPage(self, html):
h = etree.HTML(html)
pages = h.xpath('//div[@class="page"]/a/text()')
return int(pages[-2].strip())
def saveToDB(self, category, v, i):
url = "%s%sindex_%d.html" % (self.indexUrl, v, i)
if i == 1:
url = "%s%sindex.html" % (self.indexUrl, v)
nus = self.getPicUrls(url=url)
for nu in nus:
self.add(category, nu[0], nu[1])
def savePicInfoToDB(self):
executor = ThreadPoolExecutor(max_workers=64)
for c, v in self.catelogue:
html = self.reqGet(self.indexUrl + v)
if not os.path.exists("%s%s" % (self.ddir, c)):
os.mkdir("%s%s" % (self.ddir, c))
print("%s%s" % (self.ddir, c))
maxPage = self.getMaxPage(html)
for i in range(1, maxPage + 1):
executor.submit(self.saveToDB, c, v, i)
executor.shutdown(wait=True)
def getConn(self):
conn = pymysql.Connect(
host="127.0.0.1",
port=3306,
charset='utf8',
user='root',
password='toor',
db='photos'
)
return conn
def add(self, category, filename, url):
try:
conn = self.getConn()
cursor = conn.cursor()
sql = "INSERT INTO purl VALUES ('{0}', '{1}', '{2}')".format(category, filename, url)
cursor.execute(sql)
conn.commit()
print(filename + " was added to database successfully")
except:
sys.stderr.write(filename + " was existed!\n")
finally:
cursor.close()
conn.close()
def downPic(self):
executor = ThreadPoolExecutor(max_workers=32)
sql = "select * from purl"
conn = self.getConn()
cursor = conn.cursor()
cursor.execute(sql)
result = cursor.fetchall()
for index in range(0, len(result)):
if self.downCount > 200:
print("finished today, welcome come back tomorrow!")
break
executor.submit(self.download, result[index])
executor.shutdown(wait=True)
cursor.close()
conn.close()
def download(self, cnu):
path = "{0}{1}\{2}.jpg".format(self.ddir, cnu[0], cnu[1])
if os.path.exists(path) and os.path.getsize(path) > 10000:
return
print("download... " + path)
rimg = self.getImg(cnu[2])
if (rimg.status_code != 200 or len(rimg.content) <= 1024):
print("invalid img!")
return
with open(path, "wb") as f:
f.write(rimg.content)
self.downCount += 1
print("finished!!! " + path)
def start(self):
# self.savePicInfoToDB()
self.downPic()
if __name__ == '__main__':
spider = Spider()
spider.start()
cookies文件格式
__cfduid=d11bb9aef064748361448bf6b0
zkhanecookieclassrecord=%2C54%2C56%2C58%2C59%2C
PHPSESSID=4h3pj2pgtehd1ov21filr
zkhanreturnurl=http%3A%2F%2Fpic.netbian.com%2Fe%
zkhanpaymoneybgid=1
zkhanmlusername=qq_qzuser65
zkhanmluserid=1323
zkhanmlgroupid=3
zkhanmlrnd=DKGnGE5vDBzO6
zkhanmlauth=207c40c91bf650aa2d6dd9d8e4e
mysql文件
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for purl
-- ----------------------------
DROP TABLE IF EXISTS `purl`;
CREATE TABLE `purl` (
`category` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`url`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
以上示例的cookie等号右边数据纯属瞎编乱造,示例的仅仅是cookies文件的格式
如果您也想把图片真实链接存储起来,别忘了更改您的数据库地址、用户名和密码哦,不过这个案例中,用mongodb存储更为合适些。对了,运行程序前需要先更改self.ddir为您的图片存储路径,和with open(“40.cookie.txt”, “r”, encoding=“utf-8”) as f: 中40.cookie为您的cookie文件路径。
运行结果


神仙姐姐放大还是很清晰,抓取的应该是原图!

新手博客,看看热闹就行,别当真!