问答
1,
\d,\w,\s,[a-zA-Z0-9],\b,.,*,+,?,x{3},^$分别是什么?
查询链接
- \d:匹配数字;

- \w:匹配单词字符(字母、数字、下划线);

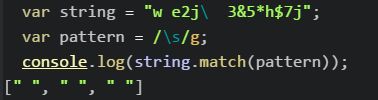
- \s:查找空白字符(空格、换行、tab、回车);
- [a-zA-Z0-9]:匹配字母(包括大小写)以及数字0-9;

- \b:匹配单词边界(\bX表示若X前为字符串开头或者空格则匹配,X\b表示结尾);

- .:匹配任意字字符(除了换行和行结束符);

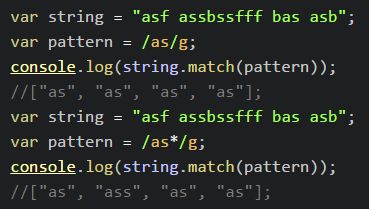
- *:包含零个或者多个前面的字符串(贪婪模式, 尽可能多的取前面字符串);
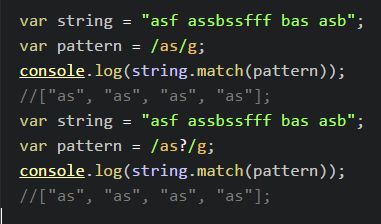
- ?:包含个零或者多个前面的字符串(非贪婪模式, 尽可能少的取前面字符串);
-
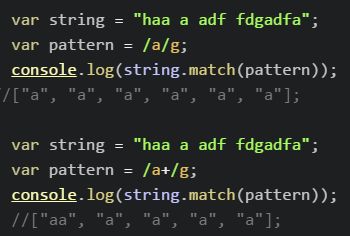
+:包含一个或者多个前面的字符串;
X{3}:匹配包含序列数为3 的X;
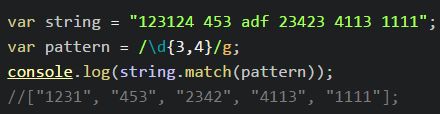
- ^a$:匹配任何以a开头和结尾的字符串;

2,贪婪模式和非贪婪模式指什么?
- 贪婪模式:在满足要求的基础上尽可能多的取值;
- 非贪婪模式:在满足要求的基础上尽可能少的取值;
代码题
1,写一个函数trim(str),去除字符串两边的空白字符
function trim(str){
return str.replace(/^\s+|\s+$/g,"");
}
2,使用实现 addClass (el, cls)、hasClass(el, cls)、 removeClass (el,cls),使用正则。ps: 视频里问题纠正
/* \b指的是单词边界,包括 开头、结尾、空格分割、中横线分割
所以对于 hunger-valley 中的 hunger 会被认为是一个单词,但
hunger-valley整体才是一个 class, 所以 hasClass的判断不能用 \b*/
function hasClass(el, cls) {
var reg =newRegExp('(\\s|^)'+cls+'(\\s|$)')
return reg.test(el.className);
}
//提示: el为dom元素相当于任务16中的obj,cls为操作的class,相当于任务16中的className,el.className获取el元素的class
function hasClass(el, cls) {
//左边是开头或者空格,右边是结尾或者空格
var reg = new RegExp('(\\s|^)' + cls + '(\s|$)', 'g');
return reg.test(el.className);
}
function addClass(el, cls) {
var reg = new RegExp('(\\s|^)' + cls + '(\s|$)', 'g');
if (!reg.test(el.className)) {
el.className = el.className + ' ' + cls;
}
}
function removeClass(el, cls) {
var reg = new RegExp('(\\s|^)' + cls + '(\s|$)', 'g');
//先替换成空格 再去掉多余的空格
if (reg.test(el.className)) {
el.className = el.className.replace(reg, ' ').replace(/\s{2,}/g, ' ');
}
}
3,写一个函数isEmail(str),判断用户输入的是不是邮箱
function isEmail(str){
if(/\S+[@]{1}(\S)+(\S)+[\.]{1}(\S)+(\w)+/.test(str)==true){
return str;
}else{
console.log("wrong");
}
}
4,写一个函数isPhoneNum(str),判断用户输入的是不是手机号
function isPhoneNum(str){
if(/^[1]+[0-9]{10}/.test(str)==true){
return str;
}else{
console.log("wrong");
}
}
5,写一个函数isValidUsername(str),判断用户输入的是不是合法的用户名(长度6-20个字符,只能包括字母、数字、下划线)
function isValidUserName(str){
if(/^\w{4,20}$/.test(str)==true){
return str;
}
console.log("wrong");
}
6,写一个函数isValidPassword(str), 判断用户输入的是不是合法密码(长度6-20个字符,只包括大写字母、小写字母、数字、下划线,且至少至少包括两种)
- 排除法:
function isValidPassword(str){
if(str.length<6||str.length>20){
console.log("wrong");
}
if(/\W/.test(str)){
console.log("wrong");
}
if(/(^\d+$)|(^_+$)|(^[A-Z]+$)|(^[a-z]+$)/g.test(str)){
console.log("wrong");
}
return str;
}
- 正面进攻法:
function isValidPassword(str){
if(/^\w{6,20}$/.test(str)){
if(/(^\d+$)|(^_+$)|(^[a-z]+$)|(^[A-Z]+$)/g.test(str)){
console.log("wrong");
}else{
return st
}
}else{
return false;
}
}
7,写一个正则表达式,得到如下字符串里所有的颜色(#121212)
var re = /*正则...*/
var subj = "color: #121212; background-color: #AA00ef; width:12px; bad-colors: f#fddee #fd2 "
alert( subj.match(re) )
// #121212,#AA00ef
- 答案:
var re = /#\w{6}/g
var subj = "color: #121212; background-color: #AA00ef; width: 12px; bad-colors: f#fddee #fd2 ";
alert( subj.match(re) ) // #121212,#AA00ef
//[a-fA-F0-9]是 十六进制数字使用的字符;
8,下面代码输出什么? 为什么? 改写代码,让其输出hunger, world。
var str = 'hello "hunger" , hello "world"';
var pat = /".*"/g;
str.match(pat); //输出[""hunger" , hello "world""]
原因:*使得正则表达式为贪婪模式,浏览器识别过程为:找到hunger前面的‘ " ’,再找到world后面的‘ " ’,则这之间的内容均被 “ . ”代替,因此输出
""hunger" , hello "world""。
进一步解释-
修改版:
var str = 'hello "hunger" , hello "world"'; var pat = /".*?"/g; str.match(pat); //输出:[""hunger"", ""world""];
9,补全如下正则表达式,输出字符串中的注释内容. (可尝试使用贪婪模式和非贪婪模式两种方法)
str = '.. .. .. '
re = /.. your regexp ../
str.match(re) // '', ''
非贪婪模式:
方法一:
str = '.. .. .. '
re = /<[\w\W]?>/g;
str.match(re) // '', ''
方法二:
str = '.. .. .. '
re = /<[^\r]?>/g; //这里的^表示非,这句话表示选取非空格的部分。
str.match(re) // '', ''-
贪婪模式:
str = '.. .. .. ' re = /<[^\r]*?>/g; str.match(re) // '', ''
10,补全如下正则表达式
var re = /* your regexp */
var str = '<> '
str.match(re)
// '', '', ''
方法一:(显示问题,请去掉空格方可正常运行)
var re = /<+[ ^> ]+>/g;
var str = '<> '
str.match(re) 输出://'', '', ''
方法二:(显示问题,请去掉空格方可正常运行)
var re = /<+[ ^> ]+?>/g;
var str = '<> '
str.match(re) 输出://'', '方法三:
var re = /<\w.*?>/g;
var str = '<> '
console.log(str.match(re))
输出: // "", "", ""