【Python | 边学边敲边记】第九次: Item+Pipeline数据存储

一、写在前面
好久没更新了,快半个月了,也少有读者催着更新,于是乎自己就拖啊,为公众号出路想方设法,着实是有点迷失自我,废话不多说了。
今天是爬虫系列第9篇,上一篇
二、你不得不知道的 Knowledge
1. 本篇涉及到的英文单词
1. item
英 [ˈaɪtəm] 美 [ˈaɪtəm]
n.项目;条,条款;一则;一件商品(或物品)
adv.又,同上
2.crawl
英 [krɔ:l] 美 [krɔl]
vi.爬行;缓慢行进;巴结
n.缓慢的爬行;〈美俚〉跳舞,自由式游泳;养鱼(龟)池
3.pipeline
英 [ˈpaɪplaɪn] 美 [ˈpaɪpˌlaɪn]
n.管道;输油管道;渠道,传递途径
vt.(通过管道)运输,传递;为…安装管道
4.meta
英 ['metə] 美 ['metə]
abbr.(Greek=after or beyond) (希腊语)在…之后或超出;[辨证法]元语言
2.Item作用
Item主要用于定义爬取的数据结构,自己指定字段存储数据,统一处理,创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field,不用区分数据类型,数据类型取决于赋值时原始数据的数据类型,它的使用方法和字典类似。
3.Pipeline作用
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,Pipeline主要作用是将return的items写入到数据库、文件等持久化模块。
4.Scrapy中Request函数的mate参数作用
Request中meta参数的作用是传递信息给下一个函数,使用过程可以理解成把需要传递的信息赋值给这个叫meta的变量,但meta只接受字典类型的赋值,因此要把待传递的信息改成"字典”的形式,如果想在下一个函数中取出 value,只需得到上一个函数的meta[key]即可。
三、看代码,边学边敲边记Scrapy Item和Pipeline应用
1. 目前项目目录

2.前情回顾
实在是本系列上一篇(
1.批量、翻页爬取
2.已经爬取到数据基本介绍,见下面数据表
| 变量中文名 | 变量名 | 值类型 |
|---|---|---|
| 文章标题 | title | str |
| 发布日期 | create_time | str |
| 文章分类 | article_type | str |
| 点赞数 | praise_number | int |
| 收藏数 | collection_number | int |
| 评论数 | comment_number | int |
3.在Item.py中新建一个JobboleArticleItem类,用来存放文章信息
class JobboleArticleItem(scrapy.Item):
front_img = scrapy.Field() # 封面图
title = scrapy.Field() # 标题
create_time = scrapy.Field() # 发布时间
url = scrapy.Field() # 当前页url
article_type =scrapy.Field() # 文章分类
praise_number = scrapy.Field() # 点赞数
collection_number = scrapy.Field() # 收藏数
comment_number = scrapy.Field() # 评论数
4.增加文章封面图获取
(1)页面分析
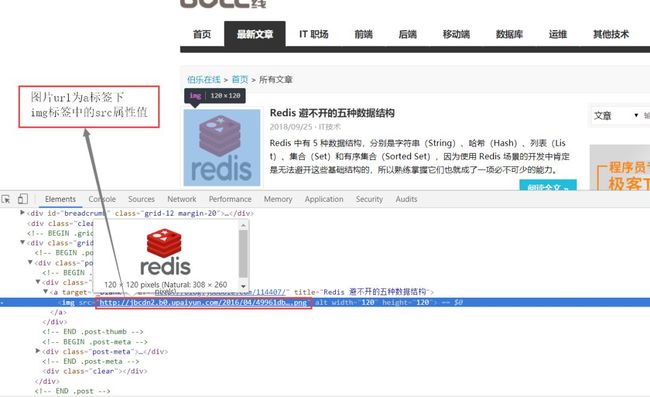
(2)jobbole.py中修改parse函数Request函数的mate参数传递获取到的image_url。
def parse(self, response):
# 1.获取单页面a标签内容,返回Selector对象
post_urls = response.xpath('//*[@id="archive"]/div/div[1]/a')
# 2.获取文章url、封面图url、下载页面内容和图片
for post_node in post_urls:
# 2.1 获取单页面文章url
image_url = post_node.css("img::attr(src)").extract_first("")
# 2.2 获取单页面文章url
post_url = post_node.css("::attr(href)").extract_first("")
# 2.3 提交下载
yield Request(url= parse.urljoin(response.url,post_url),meta={"front_img":image_url},callback= self.parse_detail)
# 3.获取翻页url和翻页下载
next_url = response.css(".next::attr(href)").extract()
if next_url != []:
next_url = next_url[0]
yield Request(url= parse.urljoin(response.url,next_url),callback= self.parse)
(3)Debug调试

Debug结果我们可以看出,mate的值成功随response传入到parse_detail函数中,那么我们就可以在parse_detail函数中解析获取到front_img。
(4)补全parse_detail函数代码
# 初始化一个item对象
article_item = JobboleArticleItem()
# 文章封面图
front_img = response.mate.get("front_img","")
·
·
·(为之前获取标题/日期/标签等代码)
# 数据存储到Item中
article_item['title'] = title
article_item['create_time'] = create_time
article_item['article_type'] = article_type
article_item['praise_number'] = praise_number
article_item['collection_number'] = collection_number
article_item['comment_number'] = comment_number
article_item['front_img'] = front_img
article_item['url'] = response.url
# 将item传递到Pipeline中
yield article_item
至此Item相关代码功能就写好了,后面我们对在Pipeline中进行实际数据存储操作。setting.py,激活PipelineITEM_PIPELINES,找到相应位置,去除注释即可)
ITEM_PIPELINES = {
key : value
}
key : 表示pipeline中定义的类路径
value : 表示这个pipeline执行的优先级,
value值越小,从jobbole.py传过
来的Item越先进入这个Pipeline。

上面操作我们就激活了Pipeline,接下来我们可以Debug一下,看看效果:

果然,Debug后Item传入了Pipeline,后面我们可以处理数据、存储数据。
创建表格
CREATE TABLE `bole_db`.`article` (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`title` VARCHAR(100) NULL,
`create_time` VARCHAR(45) NULL,
`article_type` VARCHAR(50) NULL,
`praise_number` INT NULL,
`collection_number` INT NULL,
`comment_number` INT NULL,
`url` VARCHAR(100) NULL,
`front_img` VARCHAR(150) NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8
COMMENT = '伯乐在线文章信息';
存储数据
pipeline.py中:
class MysqlPipeline(object):
def __init__(self):
# 数据库连接
self.conn = pymysql.connect(host="localhost", port=3306, user="root", password="root", charset="utf8",
database="bole_db")
self.cur = self.conn.cursor()
# 插入数据
def sql_insert(self,sql):
self.cur.execute(sql)
self.conn.commit()
def process_item(self, item, spider):
# 存入mysql数据库
sql_word = "insert into article (title,create_time,article_type,praise_number,collection_number,comment_number,url,front_img) values ('{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}')".format(item["title"],item["create_time"],item["article_type"],item["praise_number"],item["collection_number"],item["comment_number"],item["url"],item["front_img"])
self.sql_insert(sql_word)
return item
setting.py中:
# 第67行开始
ITEM_PIPELINES = {
'spider_bole_blog.pipelines.SpiderBoleBlogPipeline': 300,
'spider_bole_blog.pipelines.MysqlPipeline':100
}
运行结果
我仅仅运行了1分钟,就爬下来并存储了1000条数据,而且没有被反爬掉,这个效率,让我知道,学习Scrapy没得错,可以看出Scrapy框架的强大。
四、后言
这个系列的确是太久没更新了,给大家回顾一下之前讲了些什么吧!
往期精彩
进学习交流群
扫码加X先生微信进学习交流群[福利多多]


温馨提示
欢迎大家转载,转发,留言,点赞支持X先生。
文末广告点一下也是对X先生莫大的支持。
做知识的传播者,随手转发。


原创不易,谢谢大家。