数据分析从零开始实战 | 基础篇(五)
点击“简说Python”,选择“置顶/星标”公众号
福利干货,第一时间送达!

本文偏长(4k+字),实用性高,老表建议先收藏,然后转发朋友圈,然后吃饭、休闲时慢慢看,反复看,反复记,反复练。
零、写在前面
前面四篇文章讲了数据分析虚拟环境创建和pandas读写CSV、TSV、JSON、Excel、XML格式的数据,HTML页面读取,今天我们继续探索pandas。
数据分析从零开始实战
本系列学习笔记参考书籍:《数据分析实战》托马兹·卓巴斯
一、基本知识概要
1.SQLAlchemy模块安装
2.数据库PostgreSQL下载安装
3.PostgreSQL基本介绍使用
4.Pandas+SQLAlchemy将数据导入PostgreSQL
5.Python与各种数据库的交互代码实现
二、开始动手动脑
1、SQLAlchemy模块安装
安装SQLAlchemy模块(下面操作都是在虚拟环境下):
方法一:直接pip安装(最简单,安装慢,可能出错)
pip install SQLAlchemy
方法二:轮子(wheel)安装(比较简单,安装速度还可以,基本不出错)
在该网站下载(https://pypi.org/project/SQLAlchemy/1.3.3/)SQLAlchemy的.whl文件,然后移动到你的开发环境目录下。
pip install xxxxx.whl
方法三:豆瓣源安装(比较简单,安装速度快,方便,推荐)
pip install -i https://pypi.douban.com/simple/ SQLAlchemy

我是使用豆瓣源安装的,速度很快
2、数据库PostgreSQL下载安装
(1) 下载地址:https://www.enterprisedb.com/software-downloads-postgres

(2) 下载完成后,点击安装文件,基本上就是Next。

在这里插入图片描述
First ,安装目录,建议自己选择,不要安装在C盘。
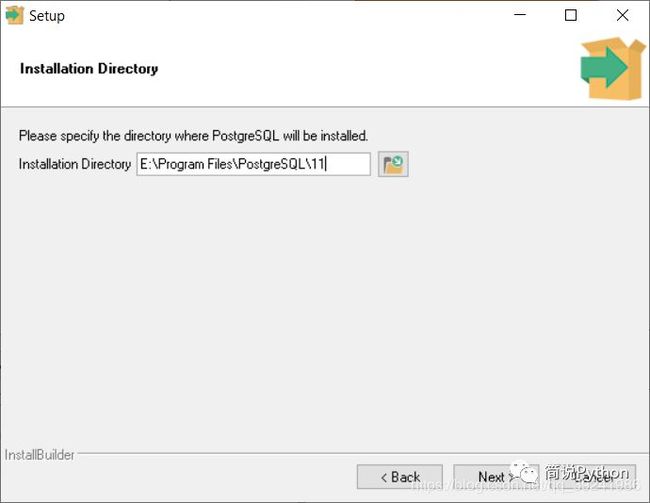
Second ,密码,可以设置简单点,毕竟只是用来自己学习。
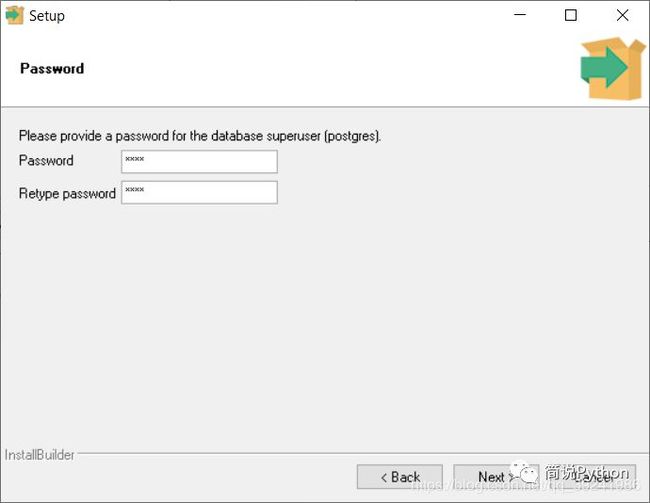
Third ,端口号,建议不要改,就用5432,改了容易和其他端口冲突,到时候自己又不知道怎么解决,麻烦。

其他没有说到的就默认设置,Next,Next,Next~安装过程一般10分钟左右,不要急。
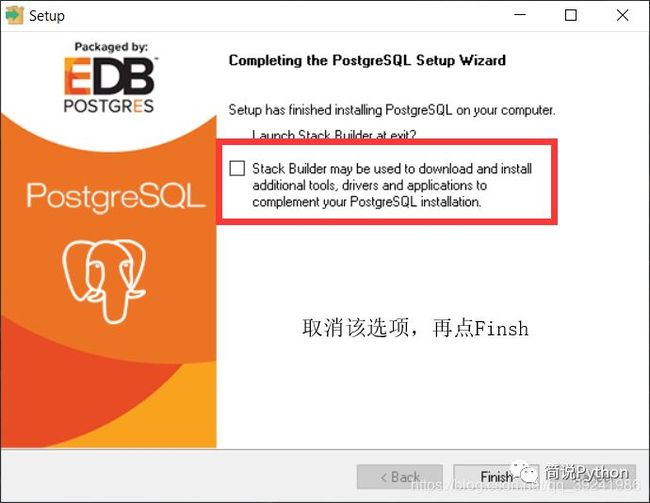
Finally ,安装完成后,取消图上的选项框,图上的意思是在后台启动Stack Builder(堆栈生成器),没有必要。
最后推荐几个相关学习网站
Postgre 社区:https://www.postgresql.org/community/
Postgre官方文档: https://www.postgresql.org/docs/
易百 Postgre 学习教程:https://www.yiibai.com/postgresql
3、PostgreSQL基本介绍使用
(1) PostgreSQL特点


以上内容截取自 易百 Postgre 学习教程。
(2) 利用PostgreSQL创建一个数据库
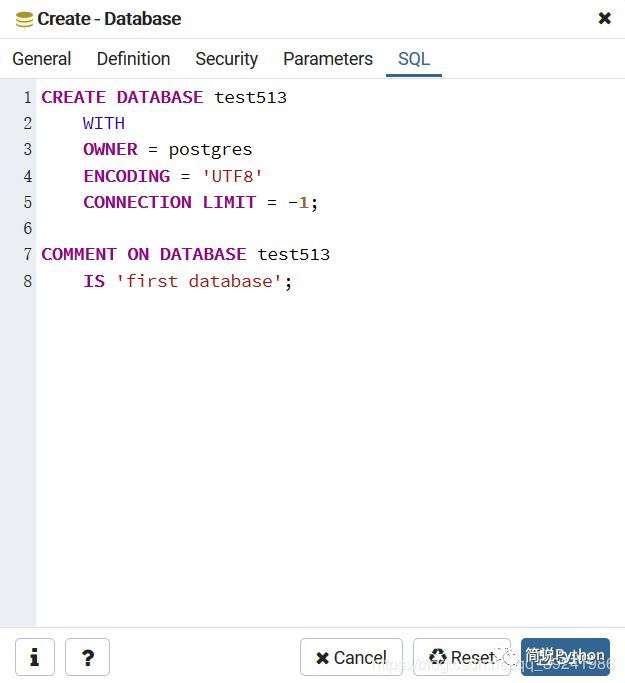
a .打开pgADmin4,发现这个图形化操作界面是一个Web端的,先会要求输入密码,就是安装时候设置的密码。
点击Servers->PostgreSQL 11->Databases->右键->Create->Database。

b .输入数据库名称,其他默认,注释自己随便写,我写的first database,表示我的第一个数据库。
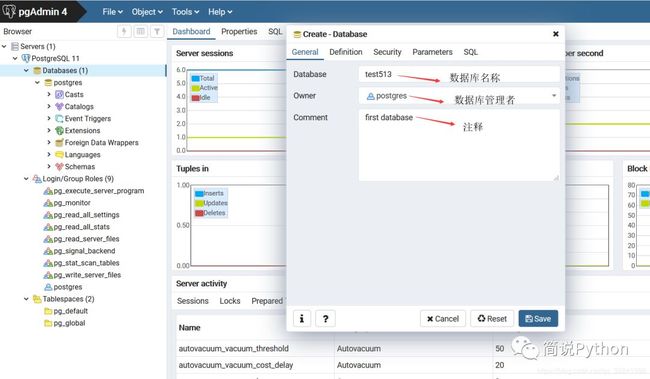
我们还可以看一下数据库创建的语句,点击弹框中的SQL即可。
4、Pandas+SQLAlchemy将数据导入Postgre
(1) Python操作代码
import pandas as pd
import sqlalchemy as sa
# 读取的CSV文件路径
r_filepath = r"H:\PyCoding\Data_analysis\day01\data01\realEstate_trans.csv"
# 数据库鉴权
user = "postgres" # 数据库用户名
password = "root" # 数据库密码
db_name = "test513" # 数据库名称
# 连接数据库
engine = sa.create_engine('postgresql://{0}:{1}@localhost:5432/{2}'.format(user, password, db_name))
print(engine)
# 读取数据
csv_read = pd.read_csv(r_filepath)
# 将 sale_date 转成 datetime 对象
csv_read['sale_date'] = pd.to_datetime(csv_read['sale_date'])
# 将数据存入数据库
csv_read.to_sql('real_estate', engine, if_exists='replace')
print("完成")
# 可能报错:ModuleNotFoundError: No module named 'psycopg2'
# 解决方法:pip install psycopg2
(2) 代码解析
engine = sa.create_engine('postgresql://{0}:{1}@localhost:5432/{2}'.format(user, password, db_name))
sqlalchemy的create_engine函数,创建一个数据库连接,参数为一个字符串,字符串的格式是:数据库类型://数据库用户名:数据库密码@服务器IP(如:127.0.0.1)或者服务器的名称(如:localhost):端口号/数据库名称
其中
csv_read.to_sql('real_estate', engine, if_exists='replace')
pandas的to_sql函数,将数据(csv_read中的)直接存入postgresql,第一个参数指定了存储到数据库后的表名,第二个参数指定了数据库引擎,第三个参数表示,如果表real_estate已经存在,则替换掉。
(3) 运行结果
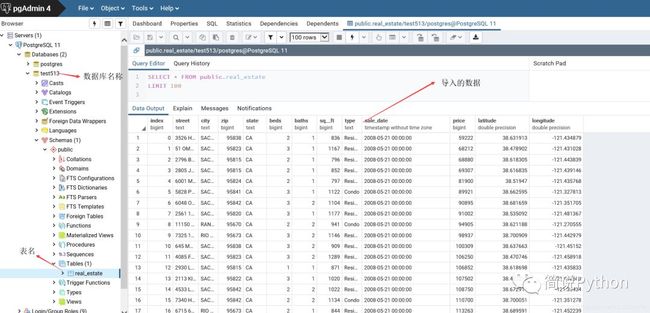
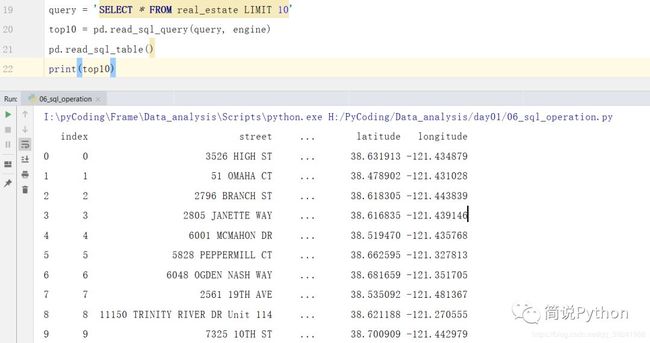
此外,pandas库还提供了数据库查询操作函数read_sql_query,只需传入查询语句和数据库连接引擎即可,源码注释为Read SQL query into a DataFrame.,意思是:把数据库查询的内容变成一个DataFrame对象返回。
query = 'SELECT * FROM real_estate LIMIT 10'
top10 = pd.read_sql_query(query, engine)
print(top10)
5、Python与各个数据库的交互代码
a . Python 与 MySql
# 使用前先安装 pymysql 模块 :pip install pymysql
# 导入 pymysql 模块
import pymysql
#连接数据库,参数说明:服务器,用户名,数据库密码,数据库名称
db = pymysql.connect("localhost","root","root","db_test")
#使用cursor()方法创建一个游标对象
cursor = db.cursor()
#使用execute()方法执行SQL语句
cursor.execute("SELECT * FROM test_table")
#使用fetall()获取全部数据
data = cursor.fetchall()
#关闭游标和数据库的连接
cursor.close()
db.close()
b . Python 与 MongoDB
# 使用前先安装 pymongodb 模块 :pip install pymongodb
# 导入 pymogodb 模块
import pymongo
# 连接数据库,参数说明:服务器IP,端口号默认为27017
my_client = pymongo.MongoClient(host="127.0.0.1",port=27017)
# 直接通过数据库名称索引,有点像字典
my_db = my_client["db_name"]
# 连接 collection_name 集合,Mongodb里集合就相当于Mysql里的表
my_collection = my_client["collection_name"]
datas = my_collection .find() # 查询
for x in datas :
print(x)
c . Python 与 Sqlite
# 使用前先安装 sqlite3 模块 :pip install sqlite3
'''
sqlite数据库和前面两种数据库不一样,它是一个本地数据库
也就是说数据直接存在本地,不依赖服务器
'''
# 导入 sqlite3 模块
import sqlite3
# 连接数据库,参数说明:这里的参数就是数据文件的地址
conn = sqlite3.connect('test.db')
#使用cursor()方法创建一个游标对象
c = conn.cursor()
#使用execute()方法执行SQL语句
cursor = c.execute("SELECT * from test_table")
for row in cursor:
print(row)
#关闭游标和数据库的连接
c.close()
conn.close()
三、送你的话
1、还是说说赞赏
真的不为了钱(我赚钱有别的路子,不然哪来的钱给大家发福利),我只是觉得看着赞赏区人多,够有面子,写作学习动力大,所以希望大家根据自己对文章的看法,自己想赞赏多少就赞赏多少,当然,你要觉得文章太差,不赞赏也没关系。
该系列上一篇文章60人赞赏,够面。
2、开始谈谈趋势
a:我一个月前开始尝试买股票理财,报了班,没赚太多钱,大佬带的挺好的,只是自己有时候看消息不及时(毕竟准备考研,不能时时刻刻盯着手机);
b:一个半月前我找了几个愿意学习的朋友构建了一个简说学习交流群(目前有Python、Java、Linux三个方向),每三周为一期,现在第一期已经结束,反馈挺好的,具体数据我在朋友圈已经发了;
c:知识星球和极客时间,要说我是看着他们长大的有点太过了,但是,我应该是见证了他们一步步的变大变强,首先说一下知识星球,最近更新后有了关注功能,就这一个变动,加上stormzhang张哥的话,知识星球的免费星球多了不知道多少,同时也为知识星球带来的是一大批用户;再说一下极客时间,我朋友圈都知道,我推荐过很多次极客时间的课,原因三点--课程质量高、便宜、我还能拿点返现,而且极客时间的课程如今越来越精良,覆盖面也越来越广,对大多数人来说是好事。
这三个方面说出来,我不知道大家会思考些什么,我想说的是:钱可以生钱,但自己要有度(比如我理财,只会拿一部分钱去做)、组队学习比一个人苦学好的多(不要太相信自己的自制力,也就可以骗骗自己)、不要固化思想(多思考,脑袋就不会绣)、知识付费还没过去,过去了对大家也没什么好处(你自己应该知道线下课程有多贵)、个人IP建不建无所谓,东西要学点到脑子里(吹的再牛皮,也是要见人的)。
踏实的人更容易过好生活,本文完。
我是老表,支持我请转发分享本文。
/今日无留言打卡/
如觉得文章有用,请留言:我爱Python 或者 Python666
(最后,赞赏一元鼓励,谢谢)

在看和转发
也是一种认可
