Python小知识 | 这些技能你不会?(二)
Python小知识
最近在看《零压力学Python》,巩固一下基础知识,意外收获到很多常用却不一定被注意的小知识,分享给大家,学到东西了点赞支持哦~
第一篇:点击这里查看第一篇python小技能
个人微信公众号,欢迎关注领取学习资源
[点击并拖拽以移动]

一、推导式
列表推导式是Python基础,好用,而又非常重要的功能,也是最受欢迎的Python特性之一。本质上可以把列表推导式理解成一种集合了变换和筛选功能的函数,通过这个函数把一个列表转换成另一个列表的过程。
(1) 普通推导式
# 简单列表推导式
list_test = [i for i in range(5)]
print(list_test)
# 生成偶数(1-10之间)
list_test = [i for i in range(1,11) if i%2==0]
print(list_test)
# 生成奇数(1-10之间)
list_test = [i for i in range(1,11) if i%2!=0]
print(list_test)
# 生成平方数(1-10之间)
list_test = [pow(i,2) for i in range(1,11)]
print(list_test)
'''
result:
[0, 1, 2, 3, 4]
[2, 4, 6, 8, 10]
[1, 3, 5, 7, 9]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
'''
(2)二维推导式
# 2-19所有的合数
list_test0 = {j for i in range(2,20) for j in range(i*i,20,i)}
print(list_test0)
# 2-19所有的质数
list_test1 = [i for i in range(2,20) if i not in list_test0]
print(list_test1)
'''
result:
{4, 6, 8, 9, 10, 12, 14, 15, 16, 18}
[2, 3, 5, 7, 11, 13, 17, 19]
'''
Python中还有字典推导式、元组推导式、集合推导式等,与列表推导式使用方式大致相同。
列表推导式的使用非常广泛,从实际使用经验来看,列表推导式使用的频率是非常高的,也是相当好用的。不过对于多层for循环,复杂筛选条件的,使用列表推导式不一定好,因为这样虽然节省了代码量,但同时让人读起来和理解起来更加困难,这个时候建议直接用多个普通for循环方式实现就可以了。
二、enumerate 和 format 函数
(1)enumerate 函数
基本介绍:enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
enumerate(sequence, start=0)
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置,默认为0。
- 基本使用
list_test = ['hello','world','!']
for i in enumerate(list_test):
# print(type(i)) result : 从上面可以看出,枚举后的,迭代出的单个对象为元组(tuple)。
- 索引与值分开
for index,values in enumerate(list_test):
# 注意:我这里 index是int类型的,所以用了str()转换成str类型
print(str(index)+':'+values)
result :
0:hello
1:world
2:!
(2)format函数
基本介绍:一种格式化字符串的函数 ,它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
- 基本操作
# 不设置指定位置,按默认顺序
str_test0 = '你好{}{}!'.format(',','极简XksA')
print(str_test0)
'''
result:
你好,极简XksA!
'''
# 设置指定位置,按默认顺序
str_test1 = 'Hell0{1}{0}!'.format('XksA',',')
print(str_test1)
'''
result:
Hell0,XksA!
'''
# 解析字典参数
dict_test = {'name':'XksA','age':21}
str_test2 = '我是{name},今年{age}岁!'.format(**dict_test)
print(str_test2)
'''
result:
我是XksA,今年21岁!
'''
# 选择列表/元组参数
list_test = ['you','XksA'] # ('you','XksA')
str_test3 = 'Do {0[0]} like {0[1]}?'.format(list_test)
print(str_test3)
'''
result:
Do you like XksA?
'''
- format的骚操作
table_head = ['id','name','age']
content = [[1,'XksA',21],[2,'Python',17],[3,'Java',13]]
head = '{0[0]:^8}{0[1]:^8}{0[2]:^8}'.format(table_head)
print(head)
for i in content:
content_test = '{0[0]:^8}{0[1]:^8}{0[2]:^8}'.format(i)
print(content_test)
'''
result :
id name age
1 XksA 21
2 Python 17
3 Java 13
'''
- 语法解析
| 格式设置 | 基本含义 |
|---|---|
| {:>n} | 将字段宽度设置为n,字段打印出来时向左对齐 |
{:| 将字段宽度设置为n,字段打印出来时向右对齐 |
|
| {:^n} | 将字段宽度设置为n,字段打印出来时居中显示 |
三、文件操作
(1)open函数
python open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
open(name, mode, buffering)
nam为必填参数,其他选填
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。
所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。
如果 buffering 的值取 1,访问文件时会寄存行。
如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。
如果取负值,寄存区的缓冲大小则为系统默认。
(2)读写文件
a.原文件内容:
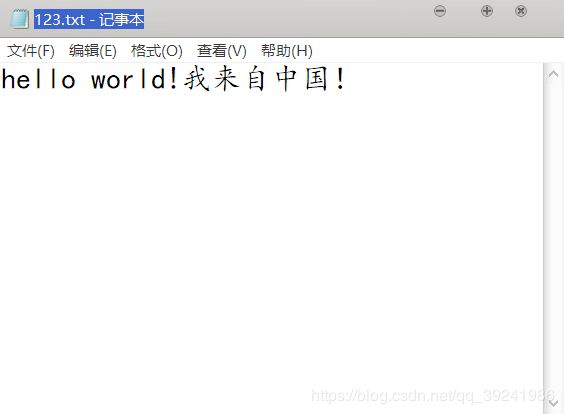
b.文件目录:I:\123.txt
c.读文件
with open(r'I:\123.txt') as file:
# 读文件
content = file.read()
print(content)
'''
result :
hello world!我来自中国!
'''
注意:这里也可以直接open生成IO流对象,不用with,但这个时候使用完,一定要记得close掉IO流,避免资源浪费。
d.写文件
with open(r'I:\123.txt',mode='r+') as file:
# 写文件
file.write('欢迎关注极简XksA,Python学习乐园~')
# 写完后再读
content = file.read()
print(content)
'''
result :
欢迎关注极简XksA,Python学习乐园~
'''
注意:在写文件时,必须标注写格式"a+",“r+”,"wb+“等,不然无法写入,如果不修改mode,默认为"r”,只读,强制写入会报错io.UnsupportedOperation: not writable。
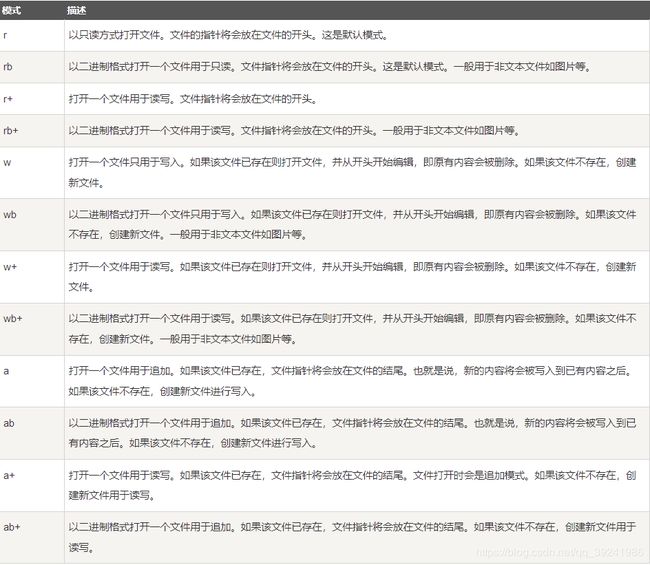
(3)基本读写格式表
四、局部变量与全局变量
(1)局部变量与全局变量
局部变量只对该变量所在函数有效,不会影响或修改函数外面的同名变量,所以可以看作,局部变量优先于全局变量被使用。
示例:
g_test = 10
def sum():
a0 = 9
g_test = 10-a0
print("局部变量g_test值为:"+str(g_test))
sum()
print("全局变量g_test值为:"+str(g_test))
'''
result:
局部变量g_test值为:1
全局变量g_test值为:10
'''
可以明显看出,此时函数域与全局域中g_test不相同,虽然我们在函数sum里修改了g_test的值,但对全局变量g_test并没有影响。
(2)global关键字
global关键字,被global标记的变量表示为全局变量,另外global不会创建指定的变量,因此我们还是需要在某个地方创建该变量,可在全局域中给变量赋值定义,也可以在函数域中赋值定义。
示例:
g_test = 10 # 全局变量
def sum():
global g_test # 注明后面出现的g_test为全局变量
g_test = 4 # 全局变量
print("函数域中g_test值为:"+str(g_test))
sum()
print("全局域中g_test值为:"+str(g_test))
'''
result:
函数域中g_test值为:4
全局域中g_test值为:4
'''
可以明显看出,此时函数域与全局域中g_test相同了,也就是我们能在函数里操作全局变量了。
灵活应用这些基本操作,让你的工作学习事半功倍。