什么是深度学习?刘利刚老师讲的很好
什么是深度学习?
- 45分钟理解深度神经网络和深度学习
刘利刚
中国科学技术大学图形与几何计算实验室
http://staff.ustc.edu.cn/~lgliu
【绪言】
近年来,人工智能(Artificial Intelligence, AI)和深度学习(Deep Learning, DL)非常火爆,在各个领域得到了广泛的应用。在笔者所从事的计算机图形学领域,也出现了越来越多的使用深度学习方法来解决各种问题的研究工作。2018年7月初,笔者首次在第七届中国科学技术大学《计算机图形学前沿》暑期课程上讲授和分享了笔者从数学(函数逼近论)的角度来对基于深度神经网络(Deep Neural Network, DNN)的深度学习的理解和解释。之后,不断有学生来向笔者进一步询问和交流有关资料和问题。为了使学生们能够更好、更快理解和使用深度神经网络和深度学习,特撰写此文。
本文的目的是帮助非人工智能领域的学生(主要是计算机图形学领域的学生及笔者的学生)来搞懂深度学习(这里指狭义的深度学习,即基于DNN的深度学习)的基本概念和方法。笔者尝试用通俗的语言,从函数逼近论的角度来阐释深度神经网络的本质。由于笔者的主要研究领域为计算机图形学,而非人工智能领域,因此本文仅仅为笔者从外行的角度对基于DNN的深度学习的粗浅理解,而非人工智能领域对DNN和深度学习的权威解释。因而,笔者对其中的有些内容的理解是有限的,甚至是有误的。如有不当之处,还请读者指正!
一、 从数据拟合说起
在大学的《数学分析》、《微积分》或者《数值分析》中,大家都已学习并熟悉数据拟合问题及求解拟合问题的最小二乘法。
1.1. 数据拟合问题
在科学技术的各领域中,我们所研究的事件一般都是有规律(因果关系)的,即自变量集合![]() 与应变量集合
与应变量集合![]() 之间存在的对应关系通常用映射来描述
之间存在的对应关系通常用映射来描述![]() (特殊情况:实数集合
(特殊情况:实数集合![]() 到实数集合
到实数集合![]() 之间的映射称为函数)。这样能根据映射(函数)规律作出预测并用于实际应用。
之间的映射称为函数)。这样能根据映射(函数)规律作出预测并用于实际应用。
有些函数关系可由理论分析推导得出,不仅为进一步的分析研究工作提供理论基础,也可以方便的解决实际工程问题。比如,适合于宏观低速物体的牛顿第二运动定律![]() 就是在实际观察和归纳中得出的普适性力学定律。
就是在实际观察和归纳中得出的普适性力学定律。
但是,很多工程问题难以直接推导出变量之间的函数表达式;或者即使能得出表达式,公式也十分复杂,不利于进一步的分析与计算。这时可以通过诸如采样、实验等方法获得若干离散的数据(称为样本数据点),然后根据这些数据,希望能得到这些变量之间的函数关系,这个过程称为数据拟合(Data fitting),在数理统计中也称为回归分析(Regression analysis)。
这里值得提一下,在实际应用中,还有一类问题是输出的结果![]() 是离散型的(比如识别图片里是人、猫、狗等标签的一种),此时问题称为分类(Classification)。
是离散型的(比如识别图片里是人、猫、狗等标签的一种),此时问题称为分类(Classification)。
1.2. 数据拟合类型
我们先考虑最简单的情形,即实数到实数的一元函数![]() 。假设通过实验获得了
。假设通过实验获得了![]() 个样本点
个样本点![]() 。我们希望求得反映这些样本点规律的一个函数关系
。我们希望求得反映这些样本点规律的一个函数关系![]() ,如图1所示。
,如图1所示。
如果要求函数严格通过每个样本点,即
|
|
|
(1.1) |
则求解函数的问题称为插值问题(Interpolation)。
一般地,由于实验数据带有观测误差,因此在大部分情况下,我们只要求函数反映这些样本点的趋势,即函数靠近样本点且误差在某种度量意义下最小,称为逼近问题(Approximation)。若记在某点的误差为
|
|
|
(1.2) |
且记误差向量为![]() 。逼近问题就是要求向量
。逼近问题就是要求向量![]() 的某种范数
的某种范数![]() 最小。一般采用欧氏范数(
最小。一般采用欧氏范数(![]() 范数)作为误差度量的标准(比较容易计算),即求如下极小化问题:
范数)作为误差度量的标准(比较容易计算),即求如下极小化问题:
|
|
|
(1.3) |



图1. 数据拟合。左:输入的样本点;中:插值函数;右:逼近函数。
无论是插值问题还是逼近问题,一个首要的问题就是函数![]() 的类型的选择和表示问题,这是《函数逼近论》中的一个比较“纠结”的问题。
的类型的选择和表示问题,这是《函数逼近论》中的一个比较“纠结”的问题。
二、 函数逼近论简介
函数的表示是函数逼近论中的基本问题。在数学的理论研究和实际应用中经常遇到下类问题:在选定的一类函数中寻找某个函数![]() ,使它与已知函数
,使它与已知函数![]() (或观测数据)在一定意义下为最佳近似表示,并求出用
(或观测数据)在一定意义下为最佳近似表示,并求出用![]() 近似表示
近似表示![]() 而产生的误差。这就是函数逼近问题。
而产生的误差。这就是函数逼近问题。![]() 称为逼近函数或拟合函数。
称为逼近函数或拟合函数。
在函数逼近问题中,逼近函数![]() 的函数类可以有不同的选择;即使函数类选定了,在该类函数中确定
的函数类可以有不同的选择;即使函数类选定了,在该类函数中确定![]() 的方式仍然是各式各样的;
的方式仍然是各式各样的;![]() 对
对![]() 的近似程度(误差)也可以有各种不同的定义。我们分别对这些问题进行解释和讨论。
的近似程度(误差)也可以有各种不同的定义。我们分别对这些问题进行解释和讨论。
2.1. 逼近函数类
在实际问题中,首先要确定函数![]() 的具体形式。这不单纯是数学问题,还与所研究问题的运动规律及观测数据有关,也与用户的经验有关。一般地,我们在某个较简单的函数类中去寻找我们所需要的函数
的具体形式。这不单纯是数学问题,还与所研究问题的运动规律及观测数据有关,也与用户的经验有关。一般地,我们在某个较简单的函数类中去寻找我们所需要的函数![]() 。这种函数类叫做逼近函数类。
。这种函数类叫做逼近函数类。
逼近函数类可以有多种选择,一般可以在不同的函数空间(比如由一些基函数通过线性组合所张成的函数空间)中进行选择。如下是一些常用的函数类。
(1) 多项式函数类
![]() 次代数多项式,即由次数不大于
次代数多项式,即由次数不大于![]() 的幂基
的幂基![]() 的线性组合的多项式函数:
的线性组合的多项式函数:
|
|
|
(2.1) |
其中![]() 为实系数。
为实系数。
更常用的是由![]() 次Bernstein基函数来表达的多项式形式(称为Bernstein多项式或Bezier多项式):
次Bernstein基函数来表达的多项式形式(称为Bernstein多项式或Bezier多项式):
|
|
|
(2.2) |
其中Bernstein基函数![]()
(2) 三角多项式类
![]() 阶三角多项式,即由阶数不大于
阶三角多项式,即由阶数不大于![]() 的三角函数基的线性组合的三角函数:
的三角函数基的线性组合的三角函数:
|
|
|
(2.3) |
其中![]() 为实系数。
为实系数。
这些是常用的逼近函数类。在逼近论中,还有许多其他形式的逼近函数类,比如由代数多项式的比构成的有理分式集(有理逼近);按照一定条件定义的样条函数集(样条逼近);径向基函数(RBF逼近);由正交函数系的线性组合构成的(维数固定的)函数集等。
2.2. 万能逼近定理
在函数逼近论中,如果一组函数成为一组“基”函数,需要满足一些比较好的性质,比如光滑性、线性无关性、权性(所有基函数和为1)、局部支集、完备性、正性、凸性等。其中, “完备性”是指,该组函数的线性组合是否能够以任意的误差和精度来逼近给定的函数(即万能逼近性质)?
对于多项式函数类,我们有以下的“万能逼近定理”:
【定理2.1 (Weierstrass逼近定理)】对![]() 上的任意连续函数
上的任意连续函数![]() ,及任意给定的
,及任意给定的![]() ,必存在
,必存在![]() 次代数多项式
次代数多项式![]() ,使得
,使得
|
|
|
(2.4) |
|
|
|
|
Weierstrass逼近定理表明,只要次数![]() 足够高,
足够高,![]() 次多项式就能以任何精度逼近给定的函数。具体的构造方法有Bernstein多项式或Chebyshev多项式等,这里不详细展开。
次多项式就能以任何精度逼近给定的函数。具体的构造方法有Bernstein多项式或Chebyshev多项式等,这里不详细展开。
类似地,由Fourier分析理论(或Weierstrass第二逼近定理),只要阶数![]() 足够高,
足够高,![]() 阶三角函数就能以任何精度逼近给定的周期函数。这些理论表明,多项式函数类和三角函数类在函数空间是“稠密”的,这就保障了用这些函数类来作为逼近函数是“合理”的。
阶三角函数就能以任何精度逼近给定的周期函数。这些理论表明,多项式函数类和三角函数类在函数空间是“稠密”的,这就保障了用这些函数类来作为逼近函数是“合理”的。
2.3. 逼近函数类选择的“纠结”
在一个逼近问题中选择什么样的函数类作逼近函数类,这要取决于被逼近函数本身的特点,也和逼近问题的条件、要求等因素有关。
在实际应用中,这里其实存在着两个非常“纠结”的问题。
第一,选择什么样的逼近函数类?一般地,需要用户对被逼近对象或样本数据有一些“先验知识”来决定选择具体的逼近函数类。比如,如果被逼近的函数具有周期性,将三角函数作为逼近函数是个合理的选择;如果被逼近的函数具有奇点,将有理函数作为逼近函数更为合理,等等。
第二,即使确定了逼近函数类,选择多高的次数或阶数?比如,如果选择了多项式函数类,根据Lagrange插值定理,一定能找到一个![]() 次多项式来插值给定的
次多项式来插值给定的![]() 个样本点。但如果
个样本点。但如果![]() 较大,则这样得到的高次多项式很容易造成“过拟合”(Overfitting)。而如果选择的
较大,则这样得到的高次多项式很容易造成“过拟合”(Overfitting)。而如果选择的![]() 过小,则得到的多项式容易造成“欠拟合”(Underfitting)。如图2所示。过拟合或欠拟合函数在实际应用中是没有用的,因为它们的预测能力非常差!
过小,则得到的多项式容易造成“欠拟合”(Underfitting)。如图2所示。过拟合或欠拟合函数在实际应用中是没有用的,因为它们的预测能力非常差!

图2. 用不同次数的多项式拟合样本点(蓝色点)。
左:欠拟合;中:合适的拟合;右:过拟合。
这里有个概念需要提及一下。一个逼近函数“表达能力”体现在该函数的未知参数(即公式(2.1)-(2.3)中的系数)与样本点个数的差,也称为“自由度”。如果逼近函数的未知参数越多,则表达能力越强。然而,在实际的拟合问题中,逼近函数的拟合能力并非越强越好。因为如果只关注样本点处的拟合误差的话,非常强的表达能力会使得样本点之外的函数值远远偏离期望的目标,反而降低拟合函数的预测性能,产生过拟合,如图2 (右)所示。
人们发展出各种方法来减缓(不能完全避免)过拟合。比如,剔除样本点中的噪声(数据去噪)、增加样本点数据量(数据增广)、简化预测模型、获取额外数据进行交叉验证、或对目标函数进行适当的正则化等。在此不详细叙述。
在实际应用中,如何选择拟合函数的数学模型(合适的逼近函数类及其阶数),并不是一开始就能选好,往往须通过分析确定若干模型后,再经过实际计算、比较和调整才能选到较好的模型。需要不断的试验和调试(称为“调参”过程),是个需要丰富经验的“技术活”。
2.4. 最小二乘法(Least Squares Method)
假设通过分析我们已经确定了逼近函数类及其次数![]() 。记基函数(一般线性无关)为
。记基函数(一般线性无关)为![]() 。记
。记![]() 为这些基函数所张成的线性空间(函数空间)。则逼近函数
为这些基函数所张成的线性空间(函数空间)。则逼近函数![]() 可记为
可记为
|
|
|
(2.5) |
其中![]() 为待定权系数。
为待定权系数。
关于最小二乘法的一般提法是:对给定的一组样本点数据![]() ,要求在函数类
,要求在函数类![]() 中找一个函数
中找一个函数![]() ,使误差的
,使误差的![]() 模的平方
模的平方![]() ,即式(1.3),达到最小。
,即式(1.3),达到最小。
对于分析极小化误差(1.3),可得关于系数向量![]() 的法方程
的法方程
|
|
|
(2.6) |
从而可求得
|
|
|
(2.7) |
由于法方程是一个线性方程组,因此基于最小二乘法的函数求解也称为线性回归。
另外,我们可在误差项中加个权,表示不同点处的数据比重不同,此时称为加权最小二乘方法(Weighted least squares, WLS)。另外,还有移动最小二乘法(Moving least squares, MLS)等其他最小二乘法的改进方法。此处不详细叙述。
三、 稀疏表达和稀疏学习
在实际应用中, 2.3节中所述的两个“纠结”问题时有发生。人们发展出不同的方法来尝试解决。
3.1. 岭回归(Ridge Regression)
当数据量较少的情况下,最小二乘法(线性回归)容易出现过拟合的现象,法方程的系数矩阵![]() 会出现奇异(非满秩),此时回归系数会变得很大,无法求解。
会出现奇异(非满秩),此时回归系数会变得很大,无法求解。
这时在最小二乘法的结果(时(2.7))中加一个小扰动![]() ,使原先无法求广义逆的情况变成可以求出其广义逆,使得问题稳定并得以求解,即
,使原先无法求广义逆的情况变成可以求出其广义逆,使得问题稳定并得以求解,即
|
|
|
(3.1) |
事实上,这个解对应于如下极小化问题的解:
|
|
|
(3.2) |
其中![]() ,参数
,参数![]() 称为正则化参数(岭参数)。上述回归模型称为岭回归,其与最小二乘法的区别在于多了关于参数
称为正则化参数(岭参数)。上述回归模型称为岭回归,其与最小二乘法的区别在于多了关于参数![]() 的
的![]() 范数正则项。这一项是对
范数正则项。这一项是对![]() 的各个元素的总体的平衡程度,即限制这些权稀疏的方差不能太大。
的各个元素的总体的平衡程度,即限制这些权稀疏的方差不能太大。
实际应用中,如果岭参数![]() 选取过大,会把所有系数
选取过大,会把所有系数![]() 均最小化(趋向于0),造成欠拟合;如果岭参数
均最小化(趋向于0),造成欠拟合;如果岭参数![]() 选取过小,会导致对过拟合问题解决不当。因此岭参数
选取过小,会导致对过拟合问题解决不当。因此岭参数![]() 的选取也是一个技术活,需要不断调参。对于某些情形,也可以通过分析选择一个最佳的岭参数
的选取也是一个技术活,需要不断调参。对于某些情形,也可以通过分析选择一个最佳的岭参数![]() 来保证回归的效果,在此不详细叙述。
来保证回归的效果,在此不详细叙述。
3.2. Lasso回归(Least Absolute Shrinkage and Selection Operator)
Lasso回归的极小化问题为:
|
|
|
(3.3) |
其中![]() ,正则项为
,正则项为![]() 范数正则项。Lasso回归能够使得系数向量
范数正则项。Lasso回归能够使得系数向量![]() 的一些元素变为0(稀疏),因此得到的拟合函数为部分基函数的线性组合。
的一些元素变为0(稀疏),因此得到的拟合函数为部分基函数的线性组合。
3.3. 稀疏表达与稀疏学习
根据Lasso回归的分析,我们可通过对回归变量施加![]() 范数
范数![]() (
(![]() 范数为元素中非0元素的个数,在很多时候可以用
范数为元素中非0元素的个数,在很多时候可以用![]() 范数近似)的正则项,以达到对回归变量进行稀疏化,即大部分回归变量为0(少数回归变量非0)。这种优化称为稀疏优化。也就是说,对回归变量施加
范数近似)的正则项,以达到对回归变量进行稀疏化,即大部分回归变量为0(少数回归变量非0)。这种优化称为稀疏优化。也就是说,对回归变量施加![]() 范数能够“自动”对基函数进行选择,值为0的系数所对应的基函数对最后的逼近无贡献。这些非0的基函数反映了的样本点集合的“特征”,因此也称为特征选择。
范数能够“自动”对基函数进行选择,值为0的系数所对应的基函数对最后的逼近无贡献。这些非0的基函数反映了的样本点集合的“特征”,因此也称为特征选择。
通过这种方法,为了保证防止丢失一些基函数(特征),我们往往可以多选取一些基函数(甚至可以是线性相关的),使得基函数的个数比输入向量的维数还要大,称为“超完备”基(Over-complete basis)或过冗余基,在稀疏学习中亦称为“字典”。然后通过对基函数的系数进行稀疏优化,选择出合适(非0系数)的基函数的组合来表达逼近函数![]() 。
。
这在一定程度上克服了2.3节中所提出的两个“纠结”的问题。因为,这时可以选取较多的基函数及较高的次数,通过稀疏优化来选择(“学习”)合适的基元函数,也称为稀疏学习。另外,基函数(字典)和稀疏系数也可以同时通过优化学习得到,称为字典学习。
对于矩阵形式(比如多元函数或图像),矩阵的稀疏表现为矩阵的低秩(近似为核模很小),则对应着矩阵低秩求解问题。在此不详细叙述。
稀疏学习与最近十年来流行的压缩感知(Compressive sensing)理论与方法非常相关,也是机器学习领域的一种重要方法。其深厚的理论基础由华裔数学家陶哲轩(2006年国际数学家大会菲尔兹奖得主)、斯坦福大学统计学教授David Donoho(2018年国际数学家大会高斯奖得主)等人所建立,已成功用于信号处理、图像与视频处理、语音处理等领域。在此不详细展开介绍。
近年来,笔者及其团队成功地将稀疏学习的理论和方法推广用于三维几何建模与处理中,在计算机图形学领域已发表十余篇相关论文(包括在顶级期刊ACM Transactions on Graphics上发表了4篇论文)。有兴趣的读者可详细查看笔者的相关论文:
[3-1] Xu et al. Survey on Sparsity in Geometry Modeling and Processing. Graphical Models, 82, 160-180, 2015. (三维几何处理的稀疏优化方法的综述论文)
[3-2] Wang et al. Construction of Manifolds via Compatible Sparse Representations. ACM Transactions on Graphics, 35(2), Article 14: 1-10, 2016. (基于基函数稀疏选择的曲面生成)
[3-3] Xiong et al. Robust Surface Reconstruction via Dictionary Learning. ACM Transactions on Graphics (Proc. Siggraph Asia), 33(6), Article 1: 1-12, 2014. (基于字典学习的曲面重建)
[3-4] Zhang et al. Local Barycentric Coordinates. ACM Transactions on Graphics (Proc. Siggraph Asia), 33(6), Article 1: 1-12, 2014. (基于稀疏优化的局部重心坐标)
[3-5] Hu et al. Co-Segmentation of 3D Shapes via Subspace Clustering. Computer Graphics Forum (Proc. Symposium on Geometry Processing), 31(5): 1703-1713, 2012. (基于特征稀疏选择的三维形状共同分割)
[3-6] Jin et al. Unsupervised Upright Orientation of Man-Made Models. Graphical Models (Proc. GMP), 74(4): 99-108, 2012. (基于矩阵低秩优化的三维形状正向计算)

图3. 稀疏学习方法用于三维几何的建模与处理(笔者的工作)。
四、 高维的逼近函数
上面讨论了映射![]() 为一元函数
为一元函数![]() 的情形。上述的有关概念和方法同样可以推广至多元函数(
的情形。上述的有关概念和方法同样可以推广至多元函数(![]() )及向量值函数(
)及向量值函数(![]() )的情形(如图4)。
)的情形(如图4)。

图4. 不同情形(维数)的逼近函数。
左上:一元函数;右上:多元函数;左下:一元向量值函数;右下:多元向量值函数。
4.1. 多元函数
假设有多元函数![]() ,即
,即![]() ,的一组测量样本数据
,的一组测量样本数据![]() 。设
。设![]() 中的一组基函数为
中的一组基函数为![]() 。要求函数
。要求函数
|
|
|
(4.1) |
使得误差
|
|
|
(4.2) |
的平方和最小。这与式(1.3)和2.4节的极值问题完全一样。系数![]() , 同样通过求解法方程得到。上述过程称为多元函数的最小二乘拟合。
, 同样通过求解法方程得到。上述过程称为多元函数的最小二乘拟合。
在函数论中,高维空间![]() 中的基函数
中的基函数![]() 的构造也有许多方法。为了简便,在许多时候我们采用张量积形式的基函数,即每个基函数是各个维数的一元基函数的乘积形式。在计算机图形学和计算机辅助几何设计(CG&CAGD)领域经常采用。
的构造也有许多方法。为了简便,在许多时候我们采用张量积形式的基函数,即每个基函数是各个维数的一元基函数的乘积形式。在计算机图形学和计算机辅助几何设计(CG&CAGD)领域经常采用。
4.2. 向量值函数
如果因变量有多个,即![]() ,称为向量值函数。比如空间螺旋线的参数方程
,称为向量值函数。比如空间螺旋线的参数方程
|
|
|
(4.3) |
|
|
|
|

就是一个从一维到三维的向量值函数 。如果自变量的维数比应变量的维数低,则自变量可看作为应变量的参数。在式(4.3)中,变量
。如果自变量的维数比应变量的维数低,则自变量可看作为应变量的参数。在式(4.3)中,变量![]() 可看作为该螺旋线的参数。
可看作为该螺旋线的参数。
对于向量值函数,可以看成是多个一元函数或多元函数(一般共享基函数)即可,所有处理方法(包括最小二乘法)都是对每个函数分别操作的,与前面单个函数的处理方法完全一样。如果用数学方式来表达,前面的很多符号由向量变为矩阵的形式而已。详细可查看《数学分析》。
五、 参数曲线曲面拟合
前面讨论的函数所能表达的曲线比较简单,无法表达封闭和多值的曲线。因此,在计算机图形学和计算机辅助几何设计中常用参数曲线曲面(本质是向量值函数,见4.2节)来表达几何形状,用于几何造型。另外,在计算机图形学中还有一种利用隐函数![]() 来表达曲线的方式,也常用于造型中,这里不展开介绍。
来表达曲线的方式,也常用于造型中,这里不展开介绍。
5.1. 二维参数曲线
从数学来看,一条曲线的本征维度是一维的,不论是从哪个维度的空间来看。从直观来看,该曲线能被“拉”成为一条直线或线段;即,一条有端点的曲线能和一条线段建立1-1对应,如图5(左)所示。因此,嵌入到二维空间中的曲线可由单个参数来表达,即有如下形式的参数形式:
|
|
|
(5.1) |
|
|
|
|
其中![]() 为该曲线的参数,
为该曲线的参数,![]() ,
, ![]() 均为
均为![]() 的函数,分别表示曲线上对应于参数
的函数,分别表示曲线上对应于参数![]() 的点的两个坐标分量。一般参数曲线表达为
的点的两个坐标分量。一般参数曲线表达为![]() 。本质上,这是一个从
。本质上,这是一个从![]() 到
到![]() 的向量值函数
的向量值函数![]() 。
。
5.2. 三维参数曲面
类似地,一张二维流形曲面的本征维度是二维的。一张曲面能与平面上的一块区域建立1-1对应,如图5(右)所示。因此,嵌入到三维空间中的曲面可由两个参数来表达,即有如下形式的参数形式:
|
|
|
(5.2) |
|
|
|
|
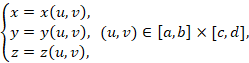
其中![]() 为该曲面的参数,
为该曲面的参数,![]() ,
, ![]() 均为
均为![]() 的二元函数,分别表示曲面上对应于参数
的二元函数,分别表示曲面上对应于参数![]() 的点的三个坐标分量。一般参数曲面表达为
的点的三个坐标分量。一般参数曲面表达为![]() 。本质上,这是一个从
。本质上,这是一个从![]() 到
到![]() 的向量值函数
的向量值函数![]() 。
。


图5. 参数曲线曲面。左:单参数曲线;右:双参数曲面。
5.3. 参数曲线曲面拟合
下面我们介绍如何使用参数曲线来拟合2D平面上的一组有序样本点。
参数曲线拟合的问题描述如下:给定平面上一组有序样本点![]() ,我们希望寻求一条拟合这些点的参数曲线关系
,我们希望寻求一条拟合这些点的参数曲线关系![]() 。
。
如需决定一条拟合曲线,首先需要确定每个样本点![]() 所对应的参数
所对应的参数![]() 。对于一组有序的样本点,所确定的一种参数分割,称之为这组样本点的参数化。参数化的本质就是找一组恰当的参数
。对于一组有序的样本点,所确定的一种参数分割,称之为这组样本点的参数化。参数化的本质就是找一组恰当的参数![]() 来匹配这一组样本点,以便使这条拟合出来的曲线美观、合理。
来匹配这一组样本点,以便使这条拟合出来的曲线美观、合理。
在参数曲线拟合中,样本点的参数化是个非常基本而重要的问题。不同的参数化,对拟合曲线的形状会产生很大的影响。图6显示了三种参数化(均匀参数化、弦长参数化和中心参数化)对拟合曲线形状的影响。

图6. 不同的参数化导致不同的参数曲线拟合结果。
类似地,如果利用参数曲面来拟合![]() 空间中给定的一组样本点,首先也需要确定这些样本点在
空间中给定的一组样本点,首先也需要确定这些样本点在![]() 平面上的参数化,如图7所示。在曲面参数化中,不仅需要建立样本点及其参数的一一对应,我们还希望参数区域的网格保持原始网格的一些重要的几何特性,比如角度、边长等。
平面上的参数化,如图7所示。在曲面参数化中,不仅需要建立样本点及其参数的一一对应,我们还希望参数区域的网格保持原始网格的一些重要的几何特性,比如角度、边长等。

图7. 三维曲面的参数化。
曲面参数化是计算机图形学中非常基础且重要的一个研究课题,也一直是研究热点之一。笔者及所在的课题组也在这个课题方面作了大量的工作,有兴趣的读者可详细查看笔者的相关论文:
(平面参数化)
[5-1] Ligang Liu, Lei Zhang, Yin Xu, Craig Gotsman, Steven J. Gortler. A Local/Global Approach to Mesh Parameterization. Computer Graphics Forum (Proc. Eurographics Symposium on Geometry Processing (SGP)), 27(5), 1495-1504, 2008.
[5-2] Ligang Liu, Chunyang Ye, Ruiqi Ni, Xiao-Ming Fu. Progressive Parameterizations. ACM Transactions on Graphics (Proc. Siggraph), 37(4), Article 41: 1-12, 2018.
(球面参数化)
[5-3] Xin Hu, Xiao-Ming Fu, Ligang Liu. Advanced Hierarchical Spherical Parameterizations. IEEE Transactions on Visualization and Computer Graphics, to appear, 2018.
[5-4] Chunxue Wang, Xin Hu, Xiaoming Fu, Ligang Liu. Bijective Spherical Parametrization with Low Distortion. Computers&Graphics (Proc. SMI), 58: 161-171, 2016.
[5-5] Chunxue Wang, Zheng Liu, Ligang Liu. As-Rigid-As-Possible Spherical Parameterization. Graphical Models (Proc. GMP), 76(5): 457-467, 2014.
(流形参数化)
[5-6] Lei Zhang, Ligang Liu, Zhongping Ji, Guojin Wang. Manifold Parameterization. Lecture Notes in Computer Science (Proc. Computer Graphics International), 4035, 160-171, 2006.
六、 从人工神经网络的观点来看拟合函数
为了讲清楚人工神经网络(Artificial Neural Network,ANN),下面我们先从神经网络的观点来看传统的拟合函数和曲线曲面。
6.1. 一元函数
对于一元的逼近函数![]()
|
|
|
(6.1) |
可以看成为如图8的三层神经网络,其中只有一个隐层。隐层上有![]() 个节点,激活函数分别为基函数
个节点,激活函数分别为基函数![]() (从这里我们将基函数称为“激活函数”)。输入层到隐层的权设为常值1(图8左),也可以看成为将输入层的值“直接代入”(不做任何变换,用虚线表示)到激活函数(图8右)。隐层到输出层的权为基函数的组合系数
(从这里我们将基函数称为“激活函数”)。输入层到隐层的权设为常值1(图8左),也可以看成为将输入层的值“直接代入”(不做任何变换,用虚线表示)到激活函数(图8右)。隐层到输出层的权为基函数的组合系数![]() 。
。
中间隐层的输出节点所形成的向量![]() 可看作为输入量的“特征”。
可看作为输入量的“特征”。
现在我们开始用机器学习的语言来描述数据拟合的过程。整个神经网络就是由中间节点的激活函数及权系数所决定的一个函数(6.1)。我们称样本点![]() , 为训练数据(Training set),称函数在训练数据上的误差度量为损失函数(Loss function)。通过训练数据来极小化损失函数得到权系数的过程称为“训练”或“学习”。如果损失函数取为(1.3)的形式,则网络的训练过程本质上就是前面所讲的最小二乘法(2.4节)。
, 为训练数据(Training set),称函数在训练数据上的误差度量为损失函数(Loss function)。通过训练数据来极小化损失函数得到权系数的过程称为“训练”或“学习”。如果损失函数取为(1.3)的形式,则网络的训练过程本质上就是前面所讲的最小二乘法(2.4节)。
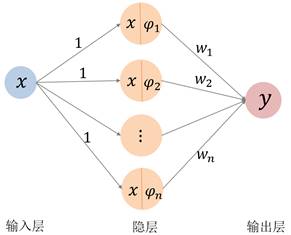

图8. 一元逼近函数的神经网络。左:输入层到隐层的权系数均为常值1;
右:输入层到隐层看成为“直接代入”(用虚线表示)。
6.2. 多元函数和向量值函数
考虑一般的逼近函数![]() 。设
。设![]() 中的一组基函数为
中的一组基函数为![]() 。则函数
。则函数![]() 可看成为如下图的一个三层的神经网络。注意这里隐层的激活函数都是
可看成为如下图的一个三层的神经网络。注意这里隐层的激活函数都是![]() 维函数,从输入层到隐层也是直接代入。输出层的各个分量
维函数,从输入层到隐层也是直接代入。输出层的各个分量![]() 共享隐层的激活函数。
共享隐层的激活函数。

图9. 多元函数和向量值函数的神经网络。从输入层到隐层是变量直接代入到激活函数。
6.3. 拟合曲线曲面
拟合曲线可以看作为一个多层的神经网络,如下图所示。输入层(样本点)到参数化是一个变换,可看成为一个神经网络;参数化到输出层是一个变换(单变量基函数组合),也是一个神经网络。输出层的两个分量共享基函数。
隐层1的激活函数为双变量基函数![]() ;隐层3的激活函数为单变量基函数
;隐层3的激活函数为单变量基函数![]() 。中间隐层(隐层1、2、3)的输出节点所形成的向量均可分别看作为输入量在不同维数空间的“特征”。
。中间隐层(隐层1、2、3)的输出节点所形成的向量均可分别看作为输入量在不同维数空间的“特征”。

图10. 拟合曲线的神经网络。输入层(样本点)到参数化是一个神经网络变换;
参数化到输出层是一个神经网络变换。
类似地,拟合曲面也可以看作为一个如下图的多层神经网络。

图11. 拟合曲面的神经网络。
从曲线曲面拟合的过程及神经网络结构来看,如果将整个网络进行优化,则拟合的过程是寻求样本点的参数化以及表达函数的基函数,使得拟合误差极小化。在这里,我们是知道给定样本点的“本征维数”,因此,人为设置了第一个隐层的维数为1(曲线)或2(曲面)。然而,在实际应用中,我们并不知道数据的本征维数,此时需要利用其他方法(比如流形学习或降维方法)来“检测”或“猜测”隐层的维数,或者直接根据经验来不断调参和测试。
需要提及的是,在计算机图形学中,传统的大部分方法是将参数化的问题和曲线曲面拟合问题分为两个问题来解决。有些工作专门做参数化,有些工作专门研究拟合问题。其中参数化的工作更为重要,直接决定了拟合曲线曲面的质量。此处不详述。
需要注意的是,本节只是从神经网络的观点来看曲线曲面的参数化和拟合的问题。在计算机图形学中,我们不是简单的通过上述网络来求参数化(单个样本点),而是要考虑更多的样本点一起来求解参数化。这个后面还会详细介绍。
七、 通用人工神经网络
有了上述的理解,我们现在来理解和解释人工神经网络就非常容易了。
7.1. 函数拟合回顾
回顾前面所述的函数逼近论中的函数拟合问题,始终是存在着两个“纠结”。一是选择什么样的逼近函数类,即选择什么类型的基函数?二是选择多高的次数或阶数?
另一方面,如果从图8或图9的神经网络的观点来看,网络的结构设置都存在着如下两个“纠结”:
1. 隐层中的节点中使用什么样的激活函数(基函数)?
2. 隐层中设置多少个节点(基函数的次数)?
在传统逼近论中,上述两个问题就没有好方法来解决(第一个问题针对具体问题可预先设定),是通过不断试错来看结果的好坏来决定的。这是因为,虽然有些基函数的性质很好,但是次数或阶数过高(比如多项式基或三角函数基),就会产生震荡,也容易产生过拟合,使得拟合函数的性态不好。因此,一般不会采用次数或结束太高的基函数。为此,人们发展了分段拟合方法,即将数据分为若干段,每段分别拟合,各段的拟合函数保证一定的光滑性,称为样条函数。在逼近论和计算机图形学领域,人们发展出了很多漂亮的样条的理论与方法。
对于参数类型的高维曲线曲面,还存在着参数化的问题,这时还存在另一个纠结,就是要设置多少个隐层(图10和图11)?
7.2. 使用简单元函数作为激活函数
为了克服上述两个纠结的问题,是否可以通过其他形式来生成“基函数”?注意到,对于任意一个非常值的一元函数![]() ,这里我们称为元函数,其沿着
,这里我们称为元函数,其沿着![]() 方向的平移函数
方向的平移函数![]() 以及沿着
以及沿着![]() 方向的伸缩函数
方向的伸缩函数![]() 都与原函数
都与原函数![]() 线性无关。也就是说,如果能有足够多的变换所生成的函数
线性无关。也就是说,如果能有足够多的变换所生成的函数![]() ,其线性组合所张成的函数空间就能有充分的表达能力。那么这些函数
,其线性组合所张成的函数空间就能有充分的表达能力。那么这些函数![]() (可能都线性无关)是否能构成逼近一般函数的“基函数”呢?
(可能都线性无关)是否能构成逼近一般函数的“基函数”呢?
一个自然的想法就是,我们能否以这个![]() 作为激活函数,让网络自动地去学习这些激活函数的变换
作为激活函数,让网络自动地去学习这些激活函数的变换![]() ,或者说去学习一些“基函数”,来表达所需要的拟合函数呢?这就是图12所示的神经元。变量
,或者说去学习一些“基函数”,来表达所需要的拟合函数呢?这就是图12所示的神经元。变量![]() 乘以一个伸缩,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入
乘以一个伸缩,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入![]() ;然后通过激活函数
;然后通过激活函数![]() 复合后成为该神经元的输出
复合后成为该神经元的输出![]() 。
。

图12. 一元(单变量)函数的神经元结构。
对于多变量的情形(多元函数),神经元的结构如图13所示。变量![]() 的线性组合,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入
的线性组合,加上一个平移(称为偏置“bias”),即变量的仿射变换,成为神经元的输入![]() ;然后通过激活函数
;然后通过激活函数![]() 复合后成为该神经元的输出
复合后成为该神经元的输出![]() 。
。
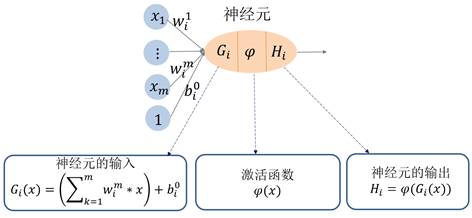
图13. 多元(多变量)函数的神经元结构。
不失一般性,我们下面就直接以多元函数的形式来介绍一般神经网络的结构。对于向量值函数(![]() 是多维的),则分别将
是多维的),则分别将![]() 的各个维数分别看作一个多元函数处理而已,这些函数共享节点(基函数)即可。
的各个维数分别看作一个多元函数处理而已,这些函数共享节点(基函数)即可。
7.3. 单隐层神经网络
一个多元函数的神经网络的结构如图14所示,有一个输入层,一个隐层及一个输出层。输入层除了变量![]() 外,还有一个常数节点1;隐层包含多个节点,每个节点的激活函数都是
外,还有一个常数节点1;隐层包含多个节点,每个节点的激活函数都是![]() ,隐层的输出就是输入层节点的线性组合加偏置(即仿射变换)
,隐层的输出就是输入层节点的线性组合加偏置(即仿射变换)![]() 代入到激活函数
代入到激活函数![]() 的复合函数
的复合函数![]() ;输出层是这些复合函数的组合
;输出层是这些复合函数的组合![]() 。
。
这个网络的所有权系数![]() ,
,![]() (输入层与隐层之间的权及偏置项)及
(输入层与隐层之间的权及偏置项)及![]() (隐层与输出层之间的权,此层一般不用偏置项)作为这个神经网络的参数变量,需要通过极小化损失函数来求解的。这个过程称为“训练”或“学习”。
(隐层与输出层之间的权,此层一般不用偏置项)作为这个神经网络的参数变量,需要通过极小化损失函数来求解的。这个过程称为“训练”或“学习”。
与前面所述的逼近论中的拟合函数类似,网络的隐层的节点数![]() 是需要通过不断调试和尝试来确定的。隐层的节点输出
是需要通过不断调试和尝试来确定的。隐层的节点输出![]() 称为输入数据
称为输入数据![]() )的“特征”。
)的“特征”。

图14. 多元(多变量)函数的单隐层神经网络结构。
整个网络的学习过程本质上就是在学习所有的系数参数。最后得到的拟合函数![]() 为一些函数的线性组合表达。这些组合函数
为一些函数的线性组合表达。这些组合函数![]() 实质上就是表达函数
实质上就是表达函数![]() 的“基函数”!
的“基函数”!
从函数逼近论的角度,我们可以这样来理解神经网络:神经网络的学习过程本质上是在学习基函数!这些基函数是通过激活函数![]() 通过平移和伸缩(变量的仿射变换)来得到的!
通过平移和伸缩(变量的仿射变换)来得到的!
当然,天下没有免费的午餐。以前函数逼近论无法解决的两个“纠结”这里仍然存在:
第一个纠结是如何选取基函数?这里使用激活函数,然后学习其变换来得到。
第二个纠结是选择多少个基函数?这里为隐层的神经元个数。
从这个观点来看,神经网络本质上就是传统的逼近论中的逼近函数的一种推广。它不是通过指定的理论完备的基函数来表达函数的,而是通过简单的基元函数(激活函数)的不断变换得到的“基函数”来表达函数的。实质上是二层复合函数。
此时,我们当然要问个问题:将函数![]() 经过充分多的平移和伸缩(包括它们的组合
经过充分多的平移和伸缩(包括它们的组合![]() )所线性张成的函数空间,其表达能力有多强?这个函数空间是否在所有函数空间是稠密的?如果问题是正确的,那么就是说,对于任何一个给定的函数,总能找到函数
)所线性张成的函数空间,其表达能力有多强?这个函数空间是否在所有函数空间是稠密的?如果问题是正确的,那么就是说,对于任何一个给定的函数,总能找到函数![]() 的多次平移和缩放的函数,其线性组合能够逼近给定的这个函数;也就是说,图14中的神经网络只要隐层的节点数足够多,该网络所表达的函数就能逼近任意的函数。
的多次平移和缩放的函数,其线性组合能够逼近给定的这个函数;也就是说,图14中的神经网络只要隐层的节点数足够多,该网络所表达的函数就能逼近任意的函数。
幸运的是,上述猜想在很多情况下是成立的!有以下的万能逼近定理所保证。
7.4. 万能逼近定理
记![]() 为
为![]() 空间中的单位立方体,我们在这个定义域中来描述万能逼近定理。记
空间中的单位立方体,我们在这个定义域中来描述万能逼近定理。记![]() 为
为![]() 上的连续函数空间,
上的连续函数空间,![]() 为
为![]() 上的可测函数空间,
上的可测函数空间,![]() 为
为![]() 上相对测度
上相对测度![]() 的可积函数空间(即
的可积函数空间(即![]() )。
)。
设给定一元激活函数![]() ,首先给出如下定义。
,首先给出如下定义。
【定义7.1】称函数![]() 为压缩函数,如果
为压缩函数,如果![]() 单调不减,且满足
单调不减,且满足
![]() ,
, ![]() .
.
【定义7.2】称函数![]() 为可分辨的,若对于有限测度
为可分辨的,若对于有限测度![]() ,由
,由
![]() ,
,
可得到![]()
【定义7.3】记
![]()
为所有由激活函数变换及线性累加所构成的![]() 维函数空间(即具有
维函数空间(即具有![]() 个节点的单隐层神经网络所表达的
个节点的单隐层神经网络所表达的![]() 维函数)。
维函数)。
【定理7.1】若![]() 是压缩函数,则
是压缩函数,则![]() 在
在![]() 中一致稠密,在
中一致稠密,在![]() 中按如下距离
中按如下距离![]() 下稠密:
下稠密:
![]() .
.
【定理7.2】若![]() 是可分辨的,则
是可分辨的,则![]() 在
在![]() 中按连续函数距离下稠密。
中按连续函数距离下稠密。
【定理7.3】若![]() 是连续有界的非常值函数,则
是连续有界的非常值函数,则![]() 在
在![]() 中稠密。
中稠密。
【定理7.4】若![]() 是无界的非常值函数,则
是无界的非常值函数,则![]() 在
在![]() 中稠密。
中稠密。
上述定理这里就不详细解释,稍微有些实分析和泛函分析的基础就能看懂。用通俗的话来说,就是:对任意给定的一个![]() 中的函数
中的函数![]() ,只要项数
,只要项数![]() 足够多,
足够多,![]() 中就存在一个函数
中就存在一个函数![]() ,使得
,使得![]() 在一定精度下逼近
在一定精度下逼近![]() 。也就是说,图14所表达的单隐层的神经网络所表达的
。也就是说,图14所表达的单隐层的神经网络所表达的![]() 维函数能够逼近
维函数能够逼近![]() 中的任意一个函数。
中的任意一个函数。
根据上述定理可知,函数![]() 只要满足一定条件即可作为一个合适的激活函数。但还是存在着一个巨大的“纠结”,就是隐层中的节点数量该取多大,仍是未知的。在实际中,这个是要不断通过测试和调试来决定的,这个过程称为“调参”。
只要满足一定条件即可作为一个合适的激活函数。但还是存在着一个巨大的“纠结”,就是隐层中的节点数量该取多大,仍是未知的。在实际中,这个是要不断通过测试和调试来决定的,这个过程称为“调参”。
定理7.1-7.4的详细证明可见以下论文。
[7-1] K. Hornik, et al. Multilayer feedforward networks are universal approximations. Neural Networks, 2: 359-366, 1989.
[7-2] G. Cybenko. Approximation by superpositions of a sigmoidal function. Math. Control Signals System, 2: 303-314, 1989.
[7-3] K. Hornik. Approximation capabilities of multilayer feedforward networks. Neural Networks, 4: 251-257, 1991.
7.5. 深度神经网络:多隐层神经网络
将上述的神经网络的隐层进一步推广到多层,即可得到多隐层的神经网络,即深度神经网络(深度的意思就是多层)。其网络结构如图15所示。
由于每相邻的两层的节点都是全部连接的,因此在机器学习领域,也叫做全连接神经网络或多层感知机(Multi-Layer Perceptron, MLP)。
图15只是显示了![]() 的函数的神经网络的结构。对于一般的
的函数的神经网络的结构。对于一般的![]() 的向量值函数,只要将最后输出层多几个节点即可,即,每个维度分量都是一个
的向量值函数,只要将最后输出层多几个节点即可,即,每个维度分量都是一个![]() 的函数,共享了前面的所有网络层结构。
的函数,共享了前面的所有网络层结构。
每个隐层的输出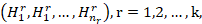 都可以看成输入数据
都可以看成输入数据![]() 在不同维数空间
在不同维数空间![]() 下的 “特征”。
下的 “特征”。
注意不要在输出层使用激活函数。因为最后的输出就是那些基函数的线性组合表达即可。
从数学上看,深度神经网络就是一个多层复合函数。万有逼近定理仍然成立。

图15. 多元(多变量)函数的深度神经网络结构。
类似地,深度神经网络也能很强地表达![]() 中的任意的函数。在具体应用中,选用多少个隐层,每一隐层选用多少节点,这些都是需要根据损失函数的进行不断调试的。这个过程也称为“调参”。
中的任意的函数。在具体应用中,选用多少个隐层,每一隐层选用多少节点,这些都是需要根据损失函数的进行不断调试的。这个过程也称为“调参”。
八、 深入理解深度神经网络
8.1. 激活函数
由7.4节中的万能逼近定理可知,激活函数的选择可以很多种。常用的激活函数如图16所示。
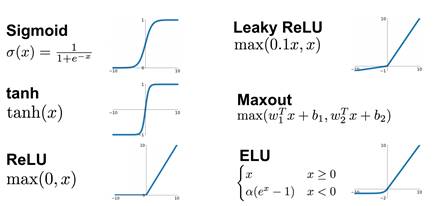
图16. 常用的激活函数。
在早期,Sigmoid函数和tanh函数是人们经常使用的激活函数。近年来,随着神经网络的隐层不断增加后,人们偏向于使用ReLU函数作为激活函数,这是因为ReLU函数的在x轴正向的导数是1,不容易产生梯度消失问题(见8.3节)。这里值得一提的是,如果使用ReLU函数作为激活函数,则最后生成的拟合函数为分片线性函数。
关于激活函数的解释和讨论,机器学习领域及互联网上有很多文章进行过解释,都是解释为“激活函数的主要作用是提供网络的非线性建模能力,提供了分层的非线性映射学习能力”等等。我们从逼近论的角度,将非线性激活函数解释为拟合函数的“基函数”生成器(如果激活函数为线性的,则无法生成表达非线性函数的基!),训练神经网络就是在学习这些基函数,这是一种全新的观点,也是非常容易理解的。
8.2. 反向传播算法(BP优化算法)
从数学上看,深度神经网络就是一个多层复合函数。在机器学习中,这个复合函数的好坏依赖于对目标函数最大化或者最小化的过程,我们常常把最小化的目标函数称为损失函数(Loss function),它主要用于衡量机器学习模型(此处为深度神经网络)的预测能力。常见的损失函数有均方误差(L2误差)、平均绝对误差(L1误差)、分位数损失、交叉熵、对比损失等。损失函数的选取依赖于参数的数量、异常值、机器学习算法、梯度下降的效率、导数求取的难易和预测的置信度等若干方面。这里就不展开讨论。
给定了一批训练数据,计算神经网络的问题就是通过极小化损失函数来找到网络中的所有权值参数(包括偏置参数)。这个过程本质上就是利用这个神经网络函数来拟合这些数据,这个过程也称为“训练”或“学习”。
误差反向传播算法(Error Back Propagation,BP)是神经网络训练时采用的一种通用方法。本质是随机梯度下降法。最早见于如下论文:
[8-1] David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by back-propagating errors. Nature, 323(99): 533-536, 1986.
由于整个网络是一个复合函数,因此,训练的过程就是不断地应用“复合函数求导”(链式法则)及“梯度下降法”。反向传播算法从神经网络的输出层开始,利用递推公式根据后一层的误差计算本层的误差,通过误差计算本层参数的梯度值,然后将差项传播到前一层。然后根据这些误差来更新这些系数参数。
值得一提的是,梯度下降法并不是唯一的优化方法。也有不少人使用其他优化方法,比如ADMM方法,来作为优化器优化深度神经网络的求解。
8.3. 什么是好的激活函数?
由万能逼近定理可知,只要网络规模设计得当,使用非线性函数作为激活函数(比如8.1节中常用的激活函数)的逼近能力都能够得到保证。
然后,由上一节的反向传播算法可知,算法过程中计算误差项时每一层都要乘以本层激活函数的导数,因此,会发生很多次的导数连乘。如果激活函数的导数的绝对值小于1,多次连乘之后误差项很快会衰减到接近于0;而参数的梯度值由误差项计算得到,从而导致前面层的权重梯度接近于0,参数不能得到有效更新,这称为“梯度消失”问题。与之相反,如果激活函数导数的绝对值大于1,多次连乘后权重值会趋向于非常大的数,这称为“梯度爆炸”。长期以来,这两个问题一直困扰神经网络层次无法变得很深。
最近几年,ReLU函数被经常使用作为深度神经网络的激活函数。有两个主要理由:
1) 该函数的导数为sgn(忽略在0处不可导的情形),计算简单,在正半轴导数为1,有效的缓解了梯度消失问题;
2) 虽然它是一个分段线性函数,但它具有非线性逼近能力;使用ReLU激活函数的深度网络的本质是用分段(分片)线性函数(超平面)去逼近目标。
后来,人们在ReLU的基础上又改进得到各种其他形式的激活函数,包括ELU、PReLU等。
8.4. 多个隐层的几何意义
现在我们已经理解了深度神经网络的本质,就是一个复杂的多层复合函数。训练的过程就是在求激活函数变换得到的“基函数”,因此,训练神经网络的本质就是在“学习基函数”。这跟稀疏学习中的“字典学习”非常类似。殊途同归!
我们来看一下深度神经网络所表达的拟合函数与传统所用的拟合函数(2.1节)的类比与区别:
(1) 传统的拟合函数是在某一函数类(由某些具有良好性质的基函数所张成的函数空间)中进行选择。基函数是预先给定的,个数也是预先设定的(或者稀疏选择的)。系统的求解变量是基函数组合系数;
(2) 神经网络所表达的拟合函数是由某一激活函数对变量的平移和伸缩变换而来,个数是预先设定的(神经元个数)。系统的求解变量是基函数的变换,因此可以看成是在学习基函数;
(3) 传统的拟合函数也是一种神经网络(见第6节),因此也可以拓展成深度网络(复合函数),但问题是次数或阶数经过复合后会变得非常高,更易造成过拟合;
(4) 多层神经网络中的不同层所用的激活函数也可以使用传统的基函数。因此,还可推广为更一般的深度神经网络。
那么为何要用多个隐层呢?事实上,通过6.3节的内容就不难理解了。每个隐层就是将前一层的数据作为输入(当然也包括输入层数据)在当前这个维数的空间中的一种映射,本质上就是在做“参数化”!
如果当前层的维数小于上一层的维数,就相当于将上一层的数据参数化到低维空间中。当然也可以参数化到高维空间,以提高自由度。
在6.3节中,对于三维曲面,我们已知它是二维流形,因此,我们知道将其映射到二维作为参数域就很自然了。因此有了图11这样的网络结构。
但对于一般的数据(比如人脸数据),是在背景空间(ambient space)上观测的,可能数据的维数非常高(比如1000x1000的图像按照像素个数的维数达到100万维)。但这些数据并不会充满整个高维空间,会具有低维的结构(称为本征维数),即数据落在一个低维子空间(或低维流形)上,并呈现一定的概率分布。从数据的角度来看,一个嵌入到高维空间的低维流形本质上就是一个参数曲面,参数域是那个低维空间。因此,将高维数据参数化到低维的空间是可行的。
这里也出现了两个纠结的问题。
第一,对于一个实际数据拟合问题,应该设置多少个隐层?
第二,每个隐层应该设置多少个节点(该隐层的维数)?
在机器学习领域,隐层的层数称为网络的深度,隐层的维数成为网络的宽度。对于基于深度神经网络的学习,到底是越深越好,还是越宽越好?
从数学上来看,网络越深,表示一个复杂的函数可以经过多次参数化的变换,映射到最终的目标。这个是合理的。举个例子,比如我们想将一个三维网格曲面参数化到一个平面,如果这个输入的曲面比较复杂,开口(参数化边界)很小,则要将曲面一次性展开(![]() 到
到![]() 的映射)比较困难。此时,可以多进行几次从
的映射)比较困难。此时,可以多进行几次从![]() 到
到![]() 的映射,将曲面先在
的映射,将曲面先在![]() 慢慢张开,每次张开的映射比较容易表达和计算。最后再映射到
慢慢张开,每次张开的映射比较容易表达和计算。最后再映射到![]() 上就相对容易了,当然还可进行多次从
上就相对容易了,当然还可进行多次从![]() 到
到![]() 的映射,生成更好的参数化。注意其中任何一个映射都可以是用一个神经网络来表达。
的映射,生成更好的参数化。注意其中任何一个映射都可以是用一个神经网络来表达。

图17. 带有特征的曲面的拟合。(a) 原始输入三维数据;(b) 为(a)的简单参数化(Floater参数化);(c) 为优化过后的参数化;(d) 最后的拟合曲面。
在计算机图形学中,我们针对曲面展开及拟合问题,在如下的工作中用到了这种思想。
[8-2] Linlin Xu, Ruimin Wang, Zhouwang Yang, Jiansong Deng, Falai Chen, Ligang Liu. Surface Approximation via Sparse Representation and Parameterization Optimization. Computer-Aided Design (Proc. SPM), 78: 179-187, 2016.
如图17所示,(a) 为一个带有尖锐特征的输入点云,如果将其简单参数化为(b),在其上构建的拟合曲面很难表现曲面的尖锐特征。这时我们对(b)中的参数化再做一个映射(优化)为(c),这时在其上做的拟合曲面则能很好地表现出尖锐特征。注意,这里生成拟合曲面的基函数中我们采用了非光滑基函数(采用非光滑基函数来表现曲面特征的思想首次在我们的如下论文中所采用)。因此,上述工作本质上是一个使用5层神经网络(3个隐层)来优化拟合曲面。
[8-3] Ruimin Wang, Ligang Liu, Zhouwang Yang, Kang Wang, Wen Shan, Jiansong Deng, Falai Chen. Construction of Manifolds via Compatible Sparse Representations. ACM Transactions on Graphics, 35(2), Article 14: 1-10, 2016.
这里顺便提一下,在计算机图形学中,最近一些年有不少工作在做曲面参数化的优化工作(比如满足无翻转、低扭曲等约束)。从机器学习的观点来看,就是在做更多的参数映射的优化计算。当然,这些工作并不能简单地看成一个深度神经网络来做。这是因为,对参数化的问题,我们是知道曲面(所有数据)的整体结构的,而不只是一些离散的采样点。因此,我们在做参数化优化的时候,我们可以充分利用曲面的整体结构来得到一些几何度量来满足各种约束,而这些是神经网络优化所做不到的!
总之,对于第一个问题,隐层越多,表示网络越深,确实会使得最后的映射带来更好的表现。其数学本质是将输入数据不断在不同的空间中进行参数化映射。最后得到的映射(可能非常复杂的映射)表达为若干个相对简单映射的复合。对于多隐层的解释和讨论,机器学习领域及网上有很多文章进行过解释,大部分都解释为“提取数据的特征”等等。我们从逼近论的角度(结合三维曲面拟合的例子),将多隐层优化看成数据在不同维数空间的参数化,是非常容易直观理解的。
对第二个问题,每个隐层的具体的节点数或维数,该如何设置呢?对于一般的数据这个就很难直观确定了,一般要根据经验。当然,也有一些办法来进行指导,我们将在下一节中解释。
8.5. 流形学习(数据降维)简介
对于一般的数据,我们并不知道其本征维数(即参数域空间),那么映射(参数化)到多少维空间是合适的呢?
事实上,这个也是个非常纠结的问题!这个问题就是寻求高维数据的本征维数,在机器学习领域称为流形学习(Manifold learning),或降维问题(Dimension reduction)。如图18所示,数据是在三维空间给出的(B),每个点是3个坐标,看起来是三维数据;但其本质上位于三维空间的一张曲面上,即二维流形曲面上(A),其本征维数是2。因此,可以将其一一映射到平面上(C)。

图18. 流行学习。(图片来自论文[8-5])
提到流形学习,不能不提到如下的两篇开山之作(同时发在Science 2000的文章):
[8-4] Roweis, Sam T and Saul, Lawrence K. Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500). 2000: 2323-2326.
[8-5] Tenenbaum, Joshua B and De Silva, Vin and Langford, John C. A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500). 2000: 2319-2323.
流形学习在本世纪初的前一个十年是一个研究热点(由上面两篇Science论文带起来的)。至今已发展出了许多方法,从简单的线性方法,比如PCA;到后面的非线性方法,比如局部线性嵌入(LLE),等距映射法(Isomap),Laplace特征映射,局部保投影法(LPP)等。这里不详细介绍。
需要指出的是,正如第6节所讲的三维曲面参数化的计算,我们计算数据的本征维数的时候,是需要利用所有数据的信息及其几何或拓扑结构一起来分析的,而不能像神经网络训练那样,仅仅将数据灌到神经网络中去更新权系数。
8.6. 端对端学习(End-to-end learning)
在传统的机器学习中,很多任务的输入数据的维数都非常大,不易直接处理。往往需要先降到合适的维数,然后再选择合适的预测模型来做拟合。
传统机器学习的流程一般由两个主要的模块组成。第一个模块称为特征工程,将原始输入数据(高维向量)变换为一个低维向量,即,用这个低维向量来作为表达输入数据的特征(或描述子,feature or descriptor)。不同的人有不同的方法来计算这个低维特征,称为特征抽取(Feature extraction),如图19显示了不同的图像特征抽取方法。各种计算的特征都有一定的实用范围,因此,有人就提出如何选择或组合各种特征得到更好的特征,这是特征工程的另一个子问题,称为特征选择(Feature selection)。针对三维形状分割,我们发现对三维局部块的众多描述子并不是串联起来一起使用更好,而是针对不同的形状的部位使用不同的描述子会更好,于是我们使用稀疏选择的方法来选择形状描述子用于形状分割,详细可见如下论文。
[8-6] Ruizhen Hu, Lubin Fan, Ligang Liu. Co-Segmentation of 3D Shapes via Subspace Clustering. Computer Graphics Forum (Proc. Symposium on Geometry Processing), 31(5): 1703-1713, 2012.
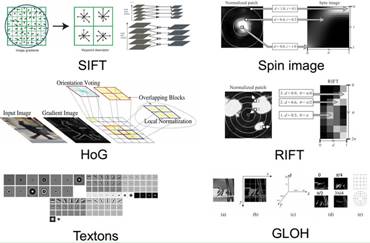
图19. 图像的各种特征抽取方法。
由于这种特征是通过人为设计的算法来得到的,因此这种特征称为人工特征(Hand-crafted features)。人工特征的抽取需要人们对输入数据的认知或者领域知识(Domain knowledge),因此在很多情况下会局限于人的经验和认知。
第二个模块称为预测模型,即选用什么样的预测方法来拟合给定的数据,我们前面所讲的拟合就是指这个过程。预测模型的目标就是希望学习到的模型在预测未知目标时越精确越好。一般要考虑模型的复杂度及精确度等因素。在机器学习领域有非常多的方法,这里不一一介绍。
上述两个模块中的每个模块都是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的,如图20(上)所示。
特征提取的好坏异常关键,甚至比预测模型还重要。举个例子,对一系列人的数据分类,分类结果是性别(男或女),如果你提取的特征是头发的颜色,无论分类算法如何,分类效果都不会好;如果你提取的特征是头发的长短,这个特征就会好很多,但是还是会有错误;如果你提取了一个超强特征,比如染色体的数据,那你的分类基本就不会错了。
这就意味着,特征需要足够的经验去设计,这在数据量越来越大的情况下也越来越困难。于是就出现了端到端的网络,特征可以自己去学习。所以特征提取这一步也就融入到算法当中,不需要人来干预了。即不需要将任务分为多个步骤分步去解决,而是从输入端的数据直接得到输出端的结果。前面介绍的深度神经网络就是一个端到端的学习方法。如图20(下)所示。
端到端学习的好处在于,使学习模型从原始输入到最终输出,直接让数据“说话”,不需人工设计的模块;给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。

图20. 非端到端的学习(上)与端到端的学习(下)。
但端到端学习也有不足。第一,端到端的深度神经网络需要大量的样本数据才能工作得很好,因此很多公司都在花费大量的人力物力去生成标注数据(一般通过人工标注,催生了很多专门做数据标注的外包公司);第二,人工设计的特征并不是都不能用的,有些人工特征还是能代表着人类智能的,是可以用来作为合理的特征的,而端到端的学习无法用这些特征。当然,通过适当的改造和结合,也可以集成人工特征到深度神经网络中,这里就不展开讨论。
8.7. 深度学习成功的原因
基于深度神经网络的端到端学习在最近几年取得很大的成功,被大量应用与计算机视觉、语音识别、自然语音处理、医学图像处理等领域中。从数学本质上来看,神经网络就是一个映射函数而已,在上世纪50年代就有了感知机,但为什么以前没有火呢? 主要有以下的两方面的原因。
第一,之前没有那么大规模的数据量;
第二,以前的工程技术(先进优化算法及支持大规模并行计算的GPU硬件)无法求解的很深的神经网络。
因此,在上个世纪90年代,各种浅层模型大行其道,比如只有一层隐层的支撑向量机(Support Vector Machine,SVM)以及没有隐层的逻辑回归方法(Logistic Regression,LR)等。
直到最近几年,随着各种传感器的大量使用以及移动互联网的广泛应用,能够获取和产生海量(PB级甚至ZB级)的数据(比如文本、图像、语音等)。特别是ImageNet图像数据库的诞生以及基于该数据库的各种竞赛,直接将计算机视觉领域中的深度学习的研究与应用推向了“落地”,催生了大量的计算机视觉的人工智能公司。
8.8. 过拟合
自从深度学习火了后,各种深度神经网络(或CNN网络)随之产生了,比如2012年的AlexNet有8层;2014年的VGG-19有19层;2014年的GoogleNet有22层;2015年的ResNet有152层!甚至还出现了上千层的深度神经网络!
从数学上可知,拟合函数所带的参数的个数与样本数据的个数之间的差代表着这个拟合函数的“自由度”。网络越来越“深”后,拟合模型中的可调整参数的数量就非常大,通常能达到百万计甚至几十亿级。因此,层数很大的深度网络(模型过于复杂)能够表达一个自由度非常大的函数空间,甚至远高于目标函数空间(过完备空间),即自由度远大于0。这样就很容易导致过拟合(Overfitting),如前面所讨论过的图2(右)所示。
过拟合可以使得拟合模型能够插值所有样本数据(拟合误差为0!)。但拟合误差为0不代表模型就是好的,因为模型只在训练集上表现好;由于模型拟合了训练样本数据中的噪声,使得它在测试集上表现可能不好,泛化性能差。为此,人们采取了不同的方法来缓解过拟合(无法完全避免),比如正则化、数据增广、Dropout、网络剪枝等。
在使用深度神经网络来做深度学习的应用中,很多工作都是直接使用现有的深度神经网络,或者改造现有的深度神经网络。如果网络设计不够好,大部分结果都可能有过拟合的现象。
在实际应用中,我们可以挑选样本数据中的一部分作为训练数据集,其他的作为测试数据集。如果网络在训练数据集上表现好(即损失函数很小),而在测试数据集上表现不够好,那么就可能发生了过拟合,此时就适当减少网络的层数或者节点数。这个过程是需要有耐心,可能需要花费很长时间才能调到一个合适的网络。需要靠感觉、经验和运气。因此,有人戏称调试深度神经网络的过程为“炼丹”。
8.9. 类比神经科学的解释
我们已从函数逼近论的角度来解释了人工神经网络本质是传统逼近函数的一个推广,由人工选取基函数到自动学习基函数,由人工提取特征到自动计算特征(参数化),能够较容易理解人工神经网络学习是如何工作的。
在机器学习领域,人们从生物神经网络的角度来解释和理解人工神经网络的工作原理,将人工神经网络看成为一个可以模拟人脑工作行为的函数。
在生物神经科学(Neuroscience,包括脑科学、认知神经科学等)的研究中,人们发现,人体的神经元通过树突接受信号。这些信息或信号随后被传递到脑细胞或细胞体。在细胞体内部,所有的信息将被加工生成一个输出。当该输出结果达到某一阈值时,神经元就会兴奋,并通过轴突传递信息,然后通过突触传递到其他相连的神经元。神经元间传输的信号量取决于连接的强度。如图21(左)。
我们来类比人工神经网络:如果把树突想象成人工智能网络中基于突触感知器的被赋予了权重的输入。然后,该输入在人工智能网络的“细胞体”(神经元)中相加。如果得出的输出值大于阈值单元,那么神经元就会“兴奋”(激活),并将输出传递到其它神经元,如图21(右)。

图21. 左:人脑神经元结构;右:从生物神经网络类比得出的人工神经元结构。
(图片来自互联网)
在计算机视觉领域,人们也从视觉神经科学(Visual Neuroscience)中类比来解释了在计算机视觉领域用得最多的卷积神经网络(CNN)的工作机理。
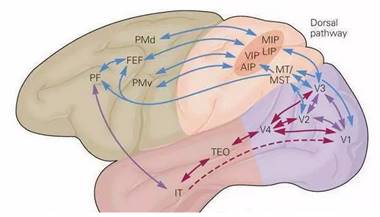
图22. 视觉皮层结构。(图片来自互联网)
由视觉机理的研究发现,动物大脑的视觉皮层具有分层结构。眼睛将看到的景象成像在视网膜上,视网膜把光学信号转换成电信号,传递到大脑的视觉皮层(Visual cortex),视觉皮层是大脑中负责处理视觉信号的部分。1959年,有科学家进行了一次实验,他们在猫的大脑初级视觉皮层内插入电极,在猫的眼前展示各种形状、空间位置、角度的光带,然后测量猫大脑神经元放出的电信号。实验发现,当光带处于某一位置和角度时,电信号最为强烈;不同的神经元对各种空间位置和方向偏好不同。这一成果后来让他们获得了诺贝尔奖。
目前已经证明,视觉皮层具有层次结构。从视网膜传来的信号首先到达初级视觉皮层(primary visual cortex),即V1皮层。V1皮层简单神经元对一些细节、特定方向的图像信号敏感。V1皮层处理之后,将信号传导到V2皮层。V2皮层将边缘和轮廓信息表示成简单形状,然后由V4皮层中的神经元进行处理,它颜色信息敏感。复杂物体最终在IT皮层(inferior temporal cortex)被表示出来。
卷积神经网络可以看成是上面这种机制的简单模仿。它由多个卷积层构成,每个卷积层包含多个卷积核,用这些卷积核从左向右、从上往下依次扫描整个图像,得到称为特征图(feature map)的输出数据。网络前面的卷积层捕捉图像局部、细节信息,有小的感受野,即输出图像的每个像素只利用输入图像很小的一个范围。后面的卷积层感受野逐层加大,用于捕获图像更复杂,更抽象的信息。经过多个卷积层的运算,最后得到图像在各个不同尺度的抽象表示(由底层到高层的特征表达),如图23所示。
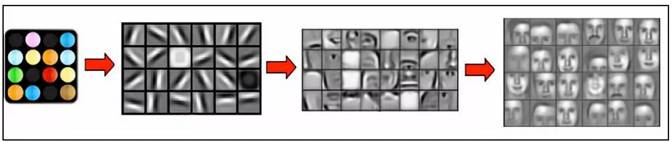
图23. 基于卷积神经网络的深度学习所得到的人脸图像的分层特征。
(图片来自于Stanford大学的论文)
笔者认为,利用神经科学的神经元或神经网络来解释深度学习中的人工神经网络,这仅仅是类比而已。从我们的分析可知,深度学习中的人工神经网络并没有真正的认知和学习!如果我们人类对自己的认知系统无法完全了解的话,我们是很难发展出真正的人工智能技术。
8.10. 深度人工神经网络的局限:保持结构的映射
我们从数学上理解了深度人工神经网络本质上是表达不同维数空间之间的一个映射(函数)。给了一些样本点后,通过调整网络的参数权系数,不断极小化损失函数,从而达到最好的拟合结果得到了拟合函数。
这个拟合过程只极小化了逐点的误差或者累积逐点误差,而无法考虑点与周围点之间的其他信息(比如邻域几何结构、局部几何度量、流形的整体拓扑结构等)。如果要考虑点之间的几何与拓扑的结构信息,则深度人工神经网络就无能为力(当然一定要改造也是可以的),这时就需要其他的数学方法了。有点像数学分析中,逐点收敛和一致收敛,逐点连续和一致连续的区别。
例如,前面介绍的流形学习中,LLE方法保持每个样本点与它相邻的多个点的线性组合(体现了局部线性)来重构低维空间的点的分布,相当于用分段的线性面片近似代替复杂的几何形状,样本投影到低维空间保持这种线性重构关系,如图24(左)所示。Isomap方法希望保持数据在低维空间的映射之后能够保持流形上的测地线距离,即全局的几何结构,如图24(右)所示。


图24. 流形学习。左:保持局部的几何信息(LLE);右:保持全局的距离信息(Isomap)。
(图片分别来自于论文[8-4]和[8-5])
再如,在计算机图形学和几何处理领域,我们做的很多映射(比如三维网格曲面的参数化),也需要保持曲面上的某些几何性质(保角度、保面积、保形等),也发展出许多不同的求解映射的方法和技巧。例如,以下两个工作是我们做的有关三维曲面参数化到二维平面的工作,第一个工作是曲面参数化工作的经典方法之一,已经被集成到3D System公司的建模软件以及著名的计算几何算法CGAL库(The Computational Geometry Algorithms Library)中。第二个工作是今年我们最新的一个工作,能快速生成无翻转和低扭曲的网格参数化,论文即将在下周的Siggraph 2018会议上汇报。
[8-7] Ligang Liu, Lei Zhang, Yin Xu, Craig Gotsman, Steven J. Gortler. A Local/Global Approach to Mesh Parameterization. Computer Graphics Forum (Proc. Eurographics Symposium on Geometry Processing (SGP)), 27(5), 1495-1504, 2008.
[8-8] Ligang Liu, Chunyang Ye, Ruiqi Ni, Xiao-Ming Fu. Progressive Parameterizations. ACM Transactions on Graphics (Proc. Siggraph), 37(4), Article 41: 1-12, 2018.
在计算机图形学中,有时我们也需要将三维空间的二维流形曲面映射到另一个规则二维流形曲面,比如球面上,这时称为球面参数化。如读者有兴趣可阅读我们如下的3篇有关球面参数化的工作。
[8-9] Xin Hu, Xiao-Ming Fu, Ligang Liu. Advanced Hierarchical Spherical Parameterizations. IEEE Transactions on Visualization and Computer Graphics, to appear, 2018.
[8-10] Chunxue Wang, Xin Hu, Xiaoming Fu, Ligang Liu. Bijective Spherical Parametrization with Low Distortion. Computers&Graphics (Proc. SMI), 58: 161-171, 2016.
[8-11] Chunxue Wang, Zheng Liu, Ligang Liu. As-Rigid-As-Possible Spherical Parameterization. Graphical Models (Proc. GMP), 76(5): 457-467, 2014.
另外,在计算机图形学及计算机辅助几何设计领域,我们还有独特的曲线和函数的构造方法,如通过Bernstein基函数构造的Bezier曲线曲面,通过B样条基构造的B样条曲线曲面(分段Bezier曲线曲面),以及更一般的非均有有理B样条曲线曲面,通过控制顶点就能很直观控制曲线曲面的形状,而且发展出非常完备的理论及设计方法,如图25所示。这些独特的曲线曲面的构造方法也是我们领域独特的,已成为现代工业中产品曲面造型的工业标准(标准数学表达)。
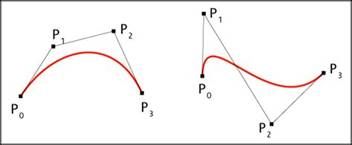

图25. NURBS曲线曲面:产品曲面造型的工业标准。(图片来源与互联网)
九、 实战深度神经网络学习
由于本文是面向非机器学习专业介绍深度学习的,因此,笔者在这里只是大致介绍一下各种基于深度神经网络的学习方法的实际技巧,不详细展开讨论,有兴趣的读者可查阅更专业的书籍或论文。
9.1. 看懂各种深度神经网络结构
从数学上来看,深度神经网络仅仅是一种函数的表达形式,是复杂的多层复合函数。由于它有大量的可调参数,而且近年来随着大数据、优化算法和并行计算GPU硬件的发展,使得用大规模的神经网络来逼近和拟合大数据成为可能。至今,不同领域的研究工作者及产业界工作者已将深度神经网络应用到各行各业的各个问题,而且提出了各种形式、各种结构的深度网络结构,使人眼花缭乱,似乎难以捉摸。但事实并非如此!
万变不离其宗,神经网络就是一个多层复合函数。网络结构发生改变,就是说函数的复合形式发生了变化。因此,只要掌握了这条原则,各种复杂的神经网络你就能轻松看懂。亦可参考互联网上的“一文看懂25个神经网络模型”一文。

图26. 多层神经网络所表达的函数:可以看成前面的若干层网络所表达的函数(蓝色)与后面若干层网络所表达的函数(红色)的复合。
简单地说,看懂各种神经网络结构只需看懂如下3个要素(具体解释就不详细展开了):
(1) 神经元与激活函数:神经元接收什么数据,通过什么样的激活函数输出数据。人们发明了许多不同种类的神经元,比如,池化神经元和插值神经元(Pooling and interpolating cells)、概率神经元(Mean and standard deviation cells)、循环神经元(Recurrent cells )、长短期记忆神经元(Long short term memory cells)、门控循环神经元(Gated recurrent cells)等。不管什么样形式和名称的神经元,我们只要搞明白神经元是通过什么样的函数来将接收数据变为输出数据,不同之处就在接收数据和激活函数不同而已,如图21(右)所示。
(2) 神经网络结构:不同的神经网络就是不同的多层复合形式的函数。比如,卷积神经网络(Convolutional Neural Network,CNN)就是一种限于局部感受野来改造的神经网络(线性组合特殊化为局部区域的卷积操作,且增加了池化(Pooling)层),特别适合于文本、图像及视频类数据的深度学习。再比如,残差神经网络(Residual Neural Network,ReNN)有一种特殊的连接,可以把数据从某一隐层传至后面几层(通常是2到5层)。该网络的目的不是要找输入数据与输出数据之间的映射,而是致力于构建输入数据与输出数据+输入数据之间的映射函数。本质上,它在结果中增加一个恒等函数,并跟前面的输入一起作为后一层的新输入。类似地,其他的神经网络结构也很容易看懂的,比如AutoEncoder,GAN,Variational GAN等。
(3) 神经网络的组合:一个多层的神经网络就是一个多次复合的函数。中间的任何一层的输出都可以看成为原始输入数据的一个特征。如图26所示,一个多层神经网络所表达的函数:可以看成前面的若干层网络所表达的函数(蓝色)与后面若干层网络所表达的函数(红色)的复合。因此,在任何的一个中间层,可以修改输出的特征向量、可以插入一个其他的神经网络(将该特征向量作为输入,或与其他网络的特征向量进行叠加、运算等)等等。如果将神经网络看成为积木,整个组合过程就像在“搭积木”。这样就可以发明和产生无穷无尽的网络结构(比如,并行网络、累加网络等等很多网络名称)。在实际应用中,需要根据问题本身的特点来合理设计网络的结构。具体哪种网络结构合理,有无最好,都是组要根据问题本身思考和试验的,主要是要看损失函数的误差以及在应用中的效果来决定的。这个我们在后面还会进一步讨论。
9.2. 如何调试深度神经网络?
一个深度神经网络所表达的函数具有成千上万个参数,为了让损失函数在训练数据上达到最小,就需要设计合理的网络来拟合这些数据。在优化的过程中,要保证迭代收敛也是必要的。
一般地,调试较大的深度神经网络所花费的时间和劳力比调试传统程序要多,而且要有耐心!因为如果最后的结果不好(损失函数很大或者不收敛),如果确认你的代码无bug,那么原因只有一个,就是你所调的网络还不够好(orz)!
在调试神经网络的过程中,有太多不确定的因素需要你去仔细思考并小心翼翼地去调试,而这些大部分都需要靠直觉、经验和少许运气来调试决定的,比如:
(1) 需要选取多大的神经网络(也就是选用什么样的拟合函数)?具体地,网络要多少层?每层多少节点?这个只能凭直觉或经验了。简单点的话,就套用现成的网络结构,或者再经过一些修改即可。从函数的自由度来看,网络的参数个数与数据大小不应相差太大。
(2) 初始化。对于高度非线性的函数的最优化,一个非常重要的因素就是如何挑选一个好的初始化?
(3) 在优化过程中,如何判断优化过程是否收敛?
(4) 是否发生了过拟合?
(5) … ….
以下有些简单的小经验分享下:
(1) 一定要可视化你的结果!这样有助于你在训练过程中发现问题。你应该明确的看到这些数据:损失函数的变化曲线、权重直方图、变量的梯度等。不能只看数值,一定要可视化!
(2) 网络不是越深越好!不要一上来就用VGG19, ResNet50等标准的大网络,可能你的问题只要几层就能解决问题。
(3) 先建立一个较小的网络来解决核心问题,然后一步一步扩展到全局问题。
(4) 先用小样本做训练,有了感觉后,再调试大的训练数据。
(5) 如果在几百次迭代后,迭代还没开始收敛,那么就要终止迭代,不要傻等了!要考虑修改你的网络了。
(6) 注意避免梯度消失或梯度爆炸。
(7) 另外,在互联网上还能找到许多网友们分(tu3)享(cao2)的实用调网络的经验,读者可自行去查找学习。
值得提醒的是,上述分享的各个经验没有绝对的对与错,须将它们当作经验去学习和使用即可。需要根据你自己的实际问题来设计和调试你的深度神经网络。
即便对于行家来说,调试较大的神经网络也是一项艰巨的任务。数百万个参数在一起决定的函数,一个微小的变化就能毁掉所有辛勤工作的成果。然而不进行调试以及可视化,一切就只能靠运气,最后可能浪费掉大把的青春岁月。
正因为这些原因,调试深度神经网络被认为是个不可解释的“黑箱子”,优化网络的过程成为“调参”,也被戏称为“炼丹”,是个需要丰富经验的“技术活”。
9.3. 深度学习开发工具
要学习和使用基于深度神经网络的深度学习,门槛并不高。你大不必从头开始自己搭建神经网络系统和实现优化算法。近几年来,很多大公司和科研机构都在研究自己的深度学习框架,且推出了不少深度学习开发平台(如图27),深度学习的开发框架和工具也越来越多,使得应用深度学习的入门门槛越来越低。使用好的开发工具,可让使用者减少底层开发的工作量,而将重点关注于深度学习应用逻辑的开发及模型的优化上,提高开发效率。

图27. 基于深度神经网络的深度学习的开发工具。(图片来自互联网)
这里简单介绍几款大家常用的深度学习开发工具包,基本都是开源的。
(1) TensorFlow, 由Google公司发布。支持多CPU及多GPU并行化运行,并支持CNN,RNN等主要的深度学习模型。Github社区人气最火的深度学习开源项目。
(2) Caffe,由加拿大Berkeley BVLC实验室发布。使用最广泛的深度学习工具之一,提供C++,Python,Matlab等语言接口。
(3) Torch,基于 Lua 脚本语言的工具,支持 iOS、 Android 等嵌入式平台。
(4) Theano,基于Python语言开发的深度学习开源仿真平台。
(5) Keras,基于Python语言开发的,底层库使用Theano或TensorFlow。其模块化特性非常适合刚入门的初学者快速实验并测试深度学习网络的性能,同时也开放提供对底层的修改。
关于这些开发工具包的使用,互联网上(包括Github)有非常丰富的教材和使用文档,读者有兴趣可以自行查阅学习。
9.4. 深度神经网络专用芯片
深度神经网络专用芯片(使用GPU+DNN的专用芯片)是一种特殊用途的处理器,它能够使得深度神经网络的训练更快,具有更高的性能和更低的功耗。DNN 专用芯片在性能和能源消耗方面的好处是显著的,DNN专用芯片的广泛使用还需要神经网络体系结构的标准化和对不同DNN框架的支持。国外的一些公司,包括Google、Nvidia、Intel等公司,已经开发和部署了DNN专用芯片,为基于DNN的应用程序提供了极高的性能。国内也有不少公司(如寒武纪、阿里巴巴等)在从事DNN专用芯片的研发,也已经达到国际前沿水平。
十、 深度神经网络的能力与局限
深度学习真有智能吗?遗憾的是,没有!
10.1. 基于深度神经网络的深度学习的本质再回顾
在本文,笔者从函数逼近论的角度已详细剖析了基于深度神经网络的深度学习,归纳为以下4个基本点:
(1) 深度神经网络(DNN)仅仅是一个函数;
(2) 基于DNN的深度学习也仅仅是个数据拟合(最小二乘回归)的过程;
(3) 拟合过程是在学习基函数;
(4) 多层映射是在做参数化。
因此,基于DNN的深度学习并不是个“黑箱子”,而是很清楚地可被解释的!具体的应用过程中,选多少层、选多少基的问题在逼近论中就是没有很好的解决方案,这是逼近论中就存在的问题,并不是深度网络带来的问题!
从数学本质来看,深度学习是在做最小二乘回归;其他的机器学习方法也是基于最小二乘回归的其他回归方法或者统计方法。
从应用性来看,还有以下一些对基于深度神经网络的深度学习的本质的说明:
(1) 基于DNN的深度学习实际上在做拟合和统计,网络结构设计需要靠直觉、技巧和经验以及运气;
(2) 激活函数和损失函数的选择也很重要;
(3) DNN的层数、各层的神经元个数决定了该函数的参数;一般的DNN都具有非常多的参数;
(4) DNN适合拟合大规模数据;对小规模数据,不建议用DNN;
(5) 任何一个中间隐层的输出向量都可以作为输入数据的特征(在该维数上的),也是输入数据的参数化;
(6) DNN可以任意拼装、组合成各种复杂的网络结构;
(7) 大部分论文中的DNN结果都可能是过拟合;因此,很容易出现误判的情况(输入的轻微变化,比如给图片加少量噪声,结果就相差很大),容易犯大错;
(8) DNN是以成败论英雄的,需要在实际应用中好才是真的好,而这个永远不知道。
需要再提一下的是,本文所讨论的基于DNN的深度学习只是深度学习的一种方法而已。还有其他的深度学习,比如南京大学周志华老师团队所提的深度森林等方法。
10.2. 深度神经网络具有“智能”吗?
从上面的剖析来看,基于DNN的深度学习实质上就是对样本数据集的拟合而已!显而易见,它仅仅是一个由数据驱动的产生的拟合器或分类器,根本不是一个“认知系统”!我们并没有看出来它有任何“智能”(即对数据所呈现的规律、知识的理解)的存在!对人工神经网络的研究可能仍然是几十年前的进展,只不过现在网络的规模变大了(数据大了,优化强了)而已!
从逼近论的角度来看,如果数据足够大,多到足以(稠密)覆盖整个目标函数,那么简单的最近邻查找或者局部线性插值的性能就足够好了。此时,笔者猜测,深度学习的性能与最近邻查找的性能可能相差无几!
举个例子,市面上出现了许多种类的所谓的“智能机器人”,声称可以与人进行自由对话。建议读者去测试一下这些对话机器人,你们就会发现,这些机器人的问答系统基本没有理解(只有少数有少量简单的理解)。如果对于在其数据库中存在的问题或类似的问题,机器人能够回答得比较合理;如果遇上需要逻辑推理的问题,这些机器人基本就答非所问,或者王顾左右而言他,甚至开始“卖萌”了。有空去逗逗这些对话机器人也是蛮有意思的事。
对于自动翻译等机器人,只要有足够的两种语言的对应词条或句子(比如有些公司的词库数据库非常庞大,达到亿级),就能“翻译”(拟合)得还不错,达到一定的实用水准。但从本质上来讲,这些翻译算法并没有真正理解语言本身!
关于深度学习,我们要有清醒的认识:
1) 深度学习模型需要大量的训练数据,才能有较好的效果;因为这些学习模型都在做数据拟合或回归,或者是在做统计;
2) 实际问题中,往往会遇到小样本问题,采用传统的简单的机器学习方法,则可以很好地解决了,没必要非得用复杂的深度学习方法;
3) 神经网络看起来来源于人脑神经元的启发,但绝不是人脑的模拟!它只是一个复合函数!举个例子,给一个三四岁的小孩看过几只猫之后,他就能识别其他的猫。也就是说,人类的学习过程往往不需要大规模的训练数据,而现在的深度神经网络的学习方法显然不是对人脑的模拟。
这几年各种媒体的大量夸张的报道和宣传(即使是战胜人类的围棋算法AlphaGo,也并不是真正的人工智能,而仅仅是机器在一定的游戏规则下的策略计算能力),极度夸大了人工智能的进展,让很多大众误认为“强人工智能”已经来临,甚至产生不必要的恐慌。
事实上,现在的人工智能的进展仍然很小,正如清华大学人工智能研究院院长张钹院士在2018年全球人工智能与机器人峰会(CCF-GAIR)上的报告上所指出的:“人工智能刚刚起步,离真正的人工智能还很遥远… 我们必须走向具有理解的人工智能,这才是真正的人工智能。”
10.3. 深度学习在工业界的应用
虽然近几年发展起来的基于DNN的深度学习并未产生真正的智能。但由于现在有大量的数据,基于数据驱动的深度学习方法可以在很多领域确实得到了落地的应用。特别是在计算机视觉领域,比如人脸识别、图像分割与识别等,该领域做了很多年的一些问题的研究工作,瞬间就被深度学习所击败!深度学习取得了巨大的成功!因此,我们仍能使用深度学习解决不少问题。
近几年,催生了大量的人工智能公司,分布在安防、医疗、金融、智能机器人、自动驾驶、智能芯片、智能家居等领域;各高校也纷纷构建了人工智能研究院或大数据学院等;各学会成立了人工智能相关的专业委员会;国家也纷纷出台了有关人工智能的政策与文件,包括《新一代人工智能发展规划》,鼓励人工智能方面的人才培养(从娃娃抓起)和产业落地。在科研领域,大量的研究工作者和学生都涌进到人工智能领域,在一些人工智能或计算机视觉领域的会议的投稿量迅速增加,参加会议的人数达到历史新高。
但残酷的事实是,绝大部分的人工智能公司都是“伪人工智能”,他们或者仅仅在做着数据标注的工作,因为标注数据的多少决定着拟合函数的“智能”!另外,已经有些公司因未能找到合适的盈利模式而倒闭。前几年对深度学习及智能的期望并未达到人们及投资者的预期目标。今年年初,李开复曾指出:“2018年是AI泡沫破裂之年”。
从两年前人工智能热潮的爆发,到现在热潮逐渐退去,人们也越来越趋于冷静来认识人工智能,对其研究与应用逐渐趋于务实。笔者也希望人工智能能真正快速发展,让人类的生活变得越来越美好!
10.4. 深度学习与人工智能的关系
1956年,几个计算机科学家相聚在达特茅斯会议,提出了“人工智能”(Artificial Intelligence, AI)的概念,梦想着用计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。人工智能研究领域范围很广,包括专家系统、机器学习、进化计算、模糊逻辑、计算机视觉、自然语言处理、推荐系统等,如图27 (左)。
机器学习(Machine Learning, ML)是一种实现人工智能的方法。其基本做法是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。传统的机器学习算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等等。从学习方法上来分,机器学习算法可以分为监督学习(如分类问题)、无监督学习(如聚类问题)、半监督学习、集成学习、深度学习和强化学习等。
深度学习(Deep Learning, DL)是一种实现机器学习的技术,是解决特征表达的一种学习过程。现在常指利用深度神经网络的深度学习。在很早就有人提过,但由于当时训练数据量不足、计算能力落后,因此深度学习的效果不尽如人意;直到近几年,深度学习才较好地实现了各种任务。事实上,除了基于深度神经网络的深度学习,还有其他形式(比如深度森林)的深度学习方法。
因此,机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术,而深度神经网络是实现深度学习的一种具体的实现工具,如图28(右)所示。简而言之,从范畴来讲,他们的关系如下:
深度神经网络 < 深度学习 < 机器学习 < 人工智能


图28. 左:人工智能的研究范畴;右:人工智能、机器学习和深度学习的关系。
(图片来自互联网)
但残酷的事实是,近几年流行的基于深度神经网络的深度学习仅仅是一个数据拟合器,并不存在着分析与理解等智能的能力。现有的技术和方法离真正的人工智能还非常遥远!
十一、 三维几何数据
在计算机图形学中,我们研究的对象是三维(3D)形状对象,即虚拟空间中的数字化的物理实体。表达3D对象的3D几何数据是继声音、图像、视频之后的第四代数字可视媒体(如图29),已逐渐具有越来越广泛的应用。
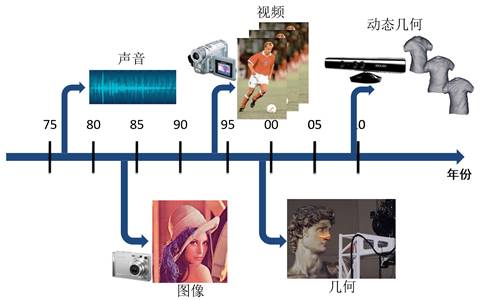
图29. 四代可视媒体的发展:声音、图像、视频、3D几何。
11.1. 3D 数据的重要性
地球上的人及所有动物都有两只眼睛,每只眼睛类似于一台照相机,看到的是场景在视网膜(成像平面)上的投影图像,如图30(左)。两只眼睛位置不同,就产生对同一场景的视差,从而在大脑生成了场景的立体和3D信息(双目立体视觉原理),如图30(右)。

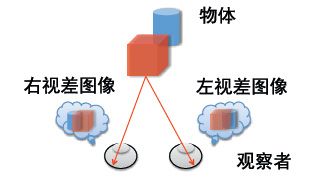
图30. 左:单眼看到的是图像,为三维世界在成像平面上的投影影像;右:人类及动物的两只眼睛通过双眼的视差产生了对场景物体的立体和三维的信息。(图片来自于互联网)
因此,人类及动物的视觉感知系统是具有立体的特性。世界是三维的,3D模型提供了世界及所有物体的全方位、全息的表达,能提供比二维图像更丰富、更全面的空间信息(比如猎鹰能在几公里外判断草地上一只兔子的远近和方位,以便做出下一步的飞行行为)。而单眼(如果以前存在的话)动物则因无法分辨物体的远近,而无情地被自然法则所淘汰。
计算机视觉通过对图像的理解和分析已经能够解决非常多的任务(比如物体检测、分割、识别、检索等)。但在很多实际应用中,如果涉及到空间关系分析以及与3D环境和物体的理解、交互和创造,则光靠2D图像信息是不够的,此时必须依赖场景的3D信息,比如数字城市中的空间关系分析、机器人抓取3D物体、虚拟和增强现实、物联网数据的空间关联等,如图31所示。在这些应用中,仅仅靠图像信息是无法很快完成各项任务的。

图31. 三维数据在很多实际应用场景中是必不可少的信息。
11.2. 3D数据集
随着3D物体的扫描与采集手段的日益增多(特别是近几年快速发展的深度相机,比如Microsoft Kinect、Intel RealSense、Google Project Tango、Apple Primesense、Asus Xtion等)、未来可采集3D信息的移动终端(去年iPhoneX上已有深度相机)的普及、以及互联网上3D模型的创造与分享,3D数据(包括RGB-D数据)将日益丰富。
至今,已有许多研究机构构建并公布了一些3D数据集,比如:
ShapeNet数据集:包含了约300多万个3D模型(3000多类物体),每个模型有语义注释。这是当前最大的一个三维模型数据集;其子集ShapeNetCore具有一些手工的标注;
ModelNet数据集:包含了12多个3D模型(662类),包含两个子集Model10和ModelNet40;
ShapeGoogle数据集:包含了近600个非刚性3D模型,用于检索测试;
SHREC数据集:包含了上千个非刚性3D模型,包括不少人的模型和合成数据集;
Watch-N-Patch数据集:由Cornell大学和Stanford大学公布,主要是人体3D模型数据。
还有一些高校和研究机构公开了一些RGB-D数据集,包括Princeton大学(415个室内场景,990万个标记图像),纽约大学(464个室内场景),Cornell大学(24个办公室场景,28个居家室内场景),Washington大学(14个室内场景)等。
另外,瑞士苏黎世大学发布了一个使用LiDAR(激光3D扫描)扫描的40个办公室场景的高精度3D场景模型数据集。
11.3. 3D形状描述子
类似于2D图像,人们也需要对3D模型数据进行分类与识别、分割与建模、匹配与检索等。完成这些任务的关键就是如何定义和计算3D模型的形状描述子(Shape descriptors)或特征(Features)。
至今,人们已提出了各种基于全局和局部的形状几何属性的空间分布或统计信息的3D形状描述子(如图32所示)。这些形状描述子都是针对某种特定的应用或某些特定的3D模型类型而提出的,同时满足所有应用及所有模型类型的3D形状描述子还没有。在实际应用中,应根据物体类型和具体应用来选择合适的形状描述子(特征选择)。比如,笔者如下论文使用稀疏选择的方法来选择合适的形状描述子用于3D 形状分割。
[11-1] Ruizhen Hu, Lubin Fan, Ligang Liu. Co-Segmentation of 3D Shapes via Subspace Clustering. Computer Graphics Forum (Proc. Symposium on Geometry Processing), 31(5): 1703-1713, 2012.
11.4. 3D几何数据的深度学习的挑战
随着3D数据(包括单个模型以及场景模型)的日益流行和丰富,如何利用上述丰富的3D数据集来完成分析和处理3D形状数据,已成为研究工作者及产业工作者的关注焦点和研究热点。因此,3D形状的特征提取方法也逐步从上述的人工定义特征方法到基于深度学习的特征学习方法的发展。
相对于图像与视频处理,3D几何数据的深度学习方法在近几年才开始有了一些工作和进展,但仍面临着一些挑战。
(1) 3D数据集较小
相比于ImageNet等千万级数据量的2D图像数据集,现在的3D模型数据集的数量很少,仍未达到“大数据”的规模。另外,3D数据的标注也是较为困难的。
(2) 3D数据是非结构化的
图像和视频都是结构化数据,是线性结构的,可以表达为一个向量或矩阵。但3D模型数据是非结构化的(如图33所示),每个顶点的邻域数是非固定的,从拓扑上看是一个图(Graph),无法直接使用深度神经网络。
(3) 3D数据的复杂性
相对于图像和视频,3D模型还有其他一些复杂性,包括:
(a) 正向姿态性:图像基本都是正向拍摄的,但是3D模型的姿态可以是任意的,如何消除姿态的影响仍有挑战。为了方便,一般会预先将数据集中的模型统一正朝向;
(b) 表达不统一:图像就是一个矩阵结构,表达非常统一;但是3D模型有不同的表达方式,比如点云、网格、体素、隐函数、CSG树等(如图34),使得需要对不同表达的数据进行不同的处理;
(c) 数据不完整:由于采集设备的精度问题,有些3D数据(比如RGBD数据)中存在着大量的噪声和游离点;由于遮挡关系,有些3D数据不够完全,存在着空洞;还有些3D数据的采样密度不均匀,造成不同部位的信息不对称。
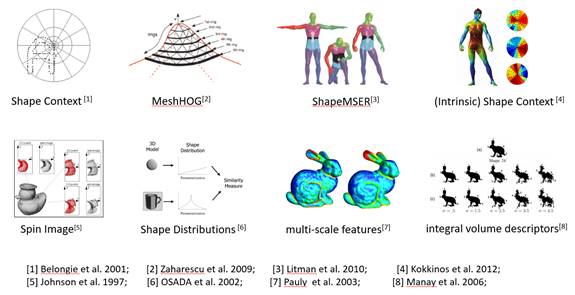

图32. 各种人工3D形状描述子。

图33. 二维图像与三维网格的数据结构的区别。

图34. 三维几何数据的不同表达。
十二、 智能图形处理:三维数据的深度学习
3D图形作为一种新型的可视媒体数据类型,同样可以利用人工智能和深度学习的方法来进行分析和处理,融合大数据、并行计算及人工智能技术的最新进展以提高计算机图形学算法及系统易用性及效率,称为智能图形处理。
近几年,已有越来越多的研究工作将机器学习和深度学习的方法应用于3D数据。本节仅就3D形状描述子方面做一个简略的介绍。
应用深度学习来自动抽取3D形状特征主要有以下3种方法:第一种,基于传统的人工特征(维数一致了)来进行更抽象的形状特征的学习和抽取;这种方法是非端到端的;第二种,将3D数据转化为规整结构数据(欧氏区域),然后再应用深度学习方法抽取形状特征,称为显式方法;第三种,将深度神经网络改造成能够处理非欧氏区域数据,称为隐式方法。下面分别从方法论上进行简单介绍。
12.1. 基于人工特征的特征学习方法
由于传统卷积无法直接作用于3D形状,早期的方法避开了直接以3D形状作为输入的训练,而是先从3D模型中提取一些人工特征(称为低级特征,如图32),再把这些特征输入到神经网络中进行学习,获得新的抽象特征(称为高级特征),如图35所示。

图35. 基于人工特征的特征学习方法。
[12-1] Zhige Xie, Kai Xu, Ligang Liu, Yueshan Xiong. 3D Shape Segmentation and Labeling via Extreme Learning Machine. Computer Graphics Forum (Proc. SGP), 33(5): 85-95, 2014.
[12-2] Kan Guo, Dongqing Zou, and Xiaowu Chen. 3D mesh labeling via deep convolutional neural networks. ACM Transactions on Graphics, 35, 1, 2015.
[12-3] Zhenyu Shu, Chengwu Qi, Shiqing Xin, Chao Hu, Li Wang, Yu Zhang, Ligang Liu. Unsupervised 3D Shape Segmentation and Co-segmentation via Deep Learning. Computer Aided Geometric Design (Proc. GMP), 43: 39-52, 2016.
人工定义的特征很大程度上取决于人的经验。因此,基于人工特征的特征学习方法并不是端到端的深度学习方法。另外,各种人工特征向量的排列也会改变特征矩阵及其卷积后的结果,对结果产生如何的影响也不清楚。
12.2. 非本征方法
这种方法是将3D数据进行合适的变换,将其变换到一个欧氏空间的规则区域,以便适用于深度神经网络。此类方法改变了3D网格模型的形态,本质上也改变了数据分布空间,是为了适应传统CNN或MLP对拓扑的要求而提出的折衷解决方法,因此成为基于欧氏空间的学习方法或非本征方法,如图36所示。
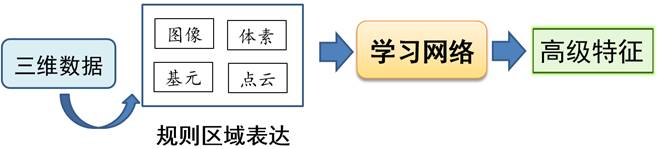
图36. 非本征深度学习方法。
变换的区域和方法主要有以下几种。
(1) 图像区域。最简单的方法就是将3D模型数据投影到平面形成图像。
(a) 多视图图像:将3D模型往多个视角方向投影生成多幅图像,比如[12-4, 12-5];
(b) 全景图像:将3D模型往平面投影生成一幅全景图,比如[12-6];
(c) 参数化图像:将3D模型的2D参数化看成为一幅图像,比如[12-7, 12-8]。
(2) 体素区域。
(a) 类比于图像中的像素,将3D形状看作三维体素网格的0,1分布,比如[12-9, 12-10, 12-11]。由于体素的个数是三次方增长,因此,体素的分辨率无法太大,一般连128x128x128的分辨率做起来都很困难。
(b) 只将模型表面用体素来表达,而省去内部体素的存储,并且利用八叉树的形式来存储,可以有效地提高体素的分辨率及模型的表达精度,比如[12-12]。
(3) 基元组合。三维形状还可以表示成一些基本单元的组合,如矩形块、圆柱、圆锥、球等,然后利用网络来学习这些基本体块的参数,比如[12-13, 12-14]。
(4) 点云。直接将3D数据看成点的集合。将每个点看作一个神经元节点,节点包含点的坐标或法向等信息,然后利用深度神经网络提取点的特征。这里要克服点及点邻域的顺序无关性等。比如[12-14, 12-15, 12-16, 12-18]。
[12-4] Su, H. and S. Maji, et al. (2015). Multi-view convolutional neural networks for 3D shape recognition. ICCV.
[12-5] Xie, Z. and K. Xu, et al. (2015). Projective Feature Learning for 3D Shapes with Multi‐View Depth Images. CGF.
[12-6] Shi, B. and S. Bai, et al. (2015). Deeppano: Deep panoramic representation for 3‐D shape recognition. IEEE Signal Processing Letters.
[12-7] Sinha, A., Bai, J., Ramani, K., et al. (2016). Deep learning 3D shape surfaces using geometry images. ECCV.
[12-8] Maron, H. and Galun, M. (2017). Convolutional Neural Networks on Surfaces via Seamless Toric Covers. SIGGRAPH.
[12-9] Qi, C. R. and H. Su, et al. (2016). Volumetric and multi-view cnns for object classification on 3D data. CVPR.
[12-10] Brock, A. and T. Lim, et al. (2016). Generative and discriminative voxel modeling with convolutional neural networks. NIPS.
[12-11] Wu, Z., and Song, S. et al. (2015). 3d shapenets: a deep representation for volumetric shapes. CVPR.
[12-12] Wang, P. S. and Liu, Y. et al. (2017). O-cnn: octree-based convolutional neural networks for 3d shape analysis. TOG.
[12-13] J. Li, K. Xu, et al. Grass: Generative recrusive autoencoders for shape structures. ACM Trans. on Graph., 36(4), 2017.
[12-14] S. Tulsiani et al. Learning shape abstraction by assembling volumetric primitives. CVPR, 2017.
[12-15] Garcia-Garcia, A. and Gomez-Donoso, F. et al. (2016). PointNet: A 3D Convolutional Neural Network for real-time object class recognition. IJCNN.
[12-16] Qi, C. R. and H. Su, et al. (2017). PointNet: Deep learning on point sets for 3D classification and segmentation. CVPR.
[12-17] Qi, C. R. and Yi, L. et al. (2017). PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. CVPR.
[12-18] Yangyan Li, Rui Bu, Mingchao Sun, and Baoquan Chen (2018). PointCNN. arXiv:1801.07791.
12.3. 本征方法
本征方法直接将三维形状看成二维流形(Manifold)或由点组成的图(Graph),顶点之间的距离不再是欧氏距离,然后直接将卷积定义在这样的数据结构上,称为非欧氏空间学习的方法或本征方法,如图37。两种典型的网络为测地卷积网络(Geodesic CNN, GCNN)和图卷积网络(Graph-based CNN),如图38,可参考[12-19, 12-20, 12-21, 12-22]。
[12-19] Masci, J. and Boscaini, D. et al. (2015). Geodesic convolutional neural networks on Riemannian manifolds. ICCV.
[12-20] Monti, F. and Boscaini, D., Masci. (2016). Geometric deep learning on graphs and manifolds using mixture model CNNs. arXiv preprint arXiv:1611.08402.
[12-21] Boscaini, D. and Masci, J. et al. (2016). Learning shape correspondence with anisotropic convolutional neural networks. NIPS.
[12-22] Yi, L. and Su, H. et al. (2017). Syncspeccnn: Synchronized spectral CNN for 3d shape segmentation. CVPR.

图37. 本征深度学习方法。

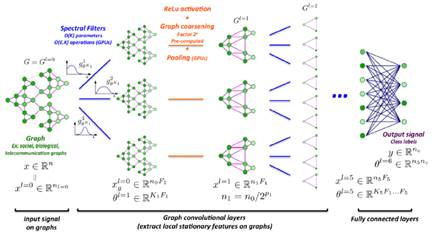
图38. 本征深度学习的具体方法。左:测地卷积;右:图卷积网络。
12.4. 端到端的生成模型
在上面的工作中,深度学习用于解决3D形状的识别、分割、匹配和对应等问题。近年来,越来越多的工作致力于3D 模型的构建和生成(大部分都是使用生成-对抗网络GAN)。由于可以自动生成大量的3D模型,对于扩充3D模型数据集具有重要的意义,非常值得大家关注。
这里简略介绍一下端到端的3D模型生成的一些工作。所谓端到端的生成模型,就是输入是简单易获得的,输出是三维模型,中间无需其他操作。例如,可以从输入的一张照片输出三维体素模型[12-23, 12-24]、点云模型[12-25]、或者网格模型及其参数化[12-26];[12-27]利用级联的图卷积网络由粗到精逐渐细化网格模型;[12-28]由手绘草图生成参数化的夸张人脸模型。
[12-23] J. Wu et al. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. Advances in Neural Information Processing Systems, 82-90, 2016.
[12-24] J. Li et al. Grass: Generative recursive autoencoders for shape structures. Siggraph 2017.
[12-25] H. Fan et al. A point set generation network for 3D object reconstruction from a single image. CVPR 2017.
[12-26] T. Groueix et al. AltasNet: A papier approach to learning 3D surface generation. arXiv: 1802.05384, 2018.
[12-27] N. Wang et al. Pixel2Mesh: Generating 3D mesh models form single RGB iamges. arXiv: 1804.01654.
[12-28] X. Han et al. DeepSketch2Face: A deep learning based sketching systems for 3D face and caricature modeling. Siggraph 2017.
【后记】
此文分享了笔者对基于深度神经网络的深度学习的理解,从逼近论的角度深入浅出地解释了深度学习的原理、逐步打开了这个“黑盒子”,了解了整个调试深度网络的“炼丹”过程,是个需要丰富经验的“技术活”。机器学习还有很多其他重要的方法,比如非监督学习和强化学习等,笔者就不一一进行介绍了。
从本文的分析可知,基于深度神经网络的深度学习背后的运行原理主要基于数据驱动的函数拟合,采用的是“经验主义”的实用方法(底层是数学的最小二乘回归方法,上层是一些统计方法);它离真正的人工智能,即能通过图灵测试(Turing Testing)的智能机器还很远。近几年人工智能的“火”可能是一场“虚火”!
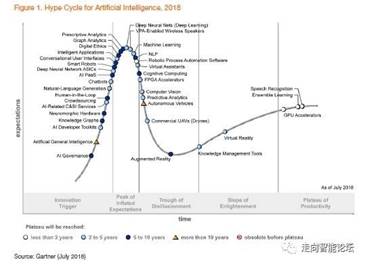
图39. Gartner 2018人工智能技术成熟度曲线。(图片来源于互联网)
五年前(2013年4月),《麻省理工学院技术评论》杂志将深度学习列为2013年十大突破性技术(Breakthrough Technology)之首。经过前几年的高速发展,根据Gartner在7月刚发布的2018人工智能技术成熟度曲线(如图39),深度神经网络及深度学习已从前几年的爬坡阶段到达顶部。未来,相信人们将会更冷静地来看待及发展相关的技术和应用。
最近,有人提出“可微编程(Differentiable Programming)”的概念,就是将神经网络当成一种语言(而不是一个简单的机器学习的方法),来描述我们客观世界的规律。甚至Yann LeCun曾在Facebook的文章中说道:“Deep Learning Is Dead. Long Live Differentiable Programming!”(深度学习已死,可微编程永生) 这个概念的提出又将神经网络提高了一个层次。
本文完稿核对时,笔者发现文中有些数学符号(比如![]() 等)存在着重复定义与使用,但根据上下文并不影响阅读和理解,因此笔者就不花时间去修正了,在此说明下。
等)存在着重复定义与使用,但根据上下文并不影响阅读和理解,因此笔者就不花时间去修正了,在此说明下。
再次声明下,笔者的主要研究领域为计算机图形学,而非人工智能领域,因此本文仅仅为笔者从外行的角度对基于深度神经网络的深度学习的粗浅理解,而非人工智能领域对深度神经网络和深度学习的权威解释。笔者对其中的有些内容的理解是有限的,甚至是有误的。因此,该文仅供读者参考,不作为专业资料!如有不当之处,还请读者指正!
【致谢】
笔者在学习深度神经网络及深度学习的过程中,阅读了许多相关的书籍和论文(比如周志华老师的《机器学习》一书和李宏毅老师的课件等)以及微信订阅号(比如《SigAI》、《人工智能学家》、《深度学习大讲堂》、《老顾谈几何》等),在此表示感谢。也感谢舒振宇、徐凯、韩晓光、沈小勇、胡瑞珍等同行、以及笔者实验室的同事(张举勇、傅孝明、杨周旺等)和学生(陈明佳、方清、杜冬、石磊、欧阳文清、刘中远等),与他们的交流和讨论也让笔者受益匪浅。
最后,希望您能从本文受益。祝您健康、快乐、成功!
刘利刚
中国科学技术大学图形与几何计算实验室(http://gcl.ustc.edu.cn)
个人主页:http://staff.ustc.edu.cn/~lgliu
电子邮箱:[email protected]
2018年8月8日