Python正则表达式
认识一些元字符:
^匹配行首 匹配以tm开头 ^tm
$匹配行尾 匹配以tm结尾 tm^
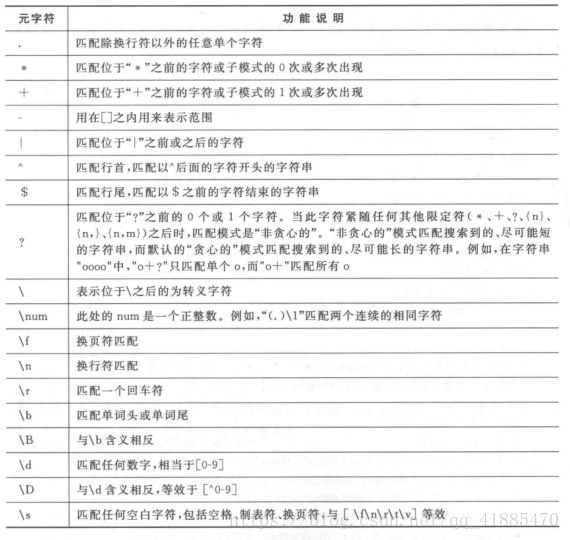

常用的元字符:
. 除换行符以外的字符
\s 任意kong空白
\d数字
\b单词开始或结束
^字符串开始
匹配以字母mr开头的单词 \bmr\w*\b
$匹配字符串结束
限定符:用于匹配一定数量的字母数字
匹配8位数字:^\d{8}$
? 匹配前面的字符1次或者0次 colou?r colour color
+匹配前面的字符1次或者多次 go+gle gogle google gooogle~·~~~~
*匹配前面的字符0次或者多次 go*gle ggle gogle google gooogle~·
{n}匹配前面的字符n次 go{2}gle google
{n,}匹配前面的字符最少n次 go{2,}gle google 到更多的o
{n,m}匹配前面的字符最少n次,最多m次
字符类:[ ]
[aeiou] 匹配任意一个英文yuan元音字母[.?!]匹配 . ? ! [0-9] 相当于 \d
排除字符: ^
[^a-zA-Z]匹配一个不是字母的字符
选择字符 | (前后相当于并列关系)
匹配身份证:15位数字 18位数字 或者17位数字加一位X
^\d{15}$|(^\d{18}$)|(^\d{17}(\d|X|x))
转义字符 \ 将 . ? \ 变为普通的字符
要匹配像 127.0.0.1 这样的IP
[1-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3} \将 .变为. (.可以匹配任意一个字符)
分组: ( ) 的作用,改变限定符的作用范围,如: | * ^
(six|four)th 可以匹配 sixth fourth
或者 (\. [1-9]{1,3}){3} 就是对 \.[1-9]{1,3} 进行重复
Python中使用正则表达式是将其作为模式字符串使用的。
匹配一个不是字母的一个字符的正则表达式: '[^a-zA-Z]'
匹配以字母m开头的单词的正则表达式转换为字符串模式,不可直接在两侧添加引号界定符,:'\bm\w*\b'
而是要'\\bm\\w*\\b' (参见前边的元字符)
我们可以使用原生字符串 r'\bm\w*\b' (同R)
使用re模块实现正则表达式:
使用re 模块时,先进行导入 import re
re.match(pattern, string ,[flags])
从字符串的开始进行匹配,如果在开始的位置匹配成功,返回Match对象,否则返回None
pattern 模式字符串,由要匹配的正则表达式转换而来
string 要匹配的字符串
[flags] 可选参数(控制匹配方式)
第一个字符串以mr_ 开头返回了一个 Match对象 第二个。
import re
pattern = r'mr_\w+'
strng = 'MR_SHOP mr_shop'
match = re.match(pattern, strng, re.I)
print("match对象\t", match)
print("匹配起始位置", match.start())
print("匹配结束位置", match.end())
print("匹配位置的元组", match.span())
print("要匹配的字符串", match.string)
print("匹配数据", match.group())
匹配起始位置 0
匹配结束位置 7
匹配位置的元组 (0, 7)
要匹配的字符串 MR_SHOP mr_shop
匹配数据 MR_SHOP
import re
pattern = r'(13[4-9]\d{8})|(15[01289]\d{8})$'
mobile = '13634222222'
match = re.match(pattern, mobile)
if match == None:
print(mobile, "不是移动的号码")
else:
print(mobile, '是中国移动手机号')
mobile = '13144222221'
match=re.match(pattern, mobile)
if match == None:
print(mobile, '不是有效的移动号')
else:
print(mobile, '是中国移动手机号')
13634222222 是中国移动手机号
13144222221 不是有效的移动号
search()方法进行匹配:在整个字符串中搜索第一个匹配的值,匹配成功则返回Match对象,否则返回None。
re.search(pattern, string, [flags])
import re
pattern = r'mr_\w'
string = 'MR_SHOP mr_shop'
match = re.search(pattern, string, re.I)
print(match)
print(match.start())
print(match.end())
print(match.span())
string2 = '项目名 MR_SHOP mr_shop'
match2 = re.search(pattern, string2, re.I)
print(match2)
0
4
(0, 4)
import re # 导入Python的re模块
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' # 模式字符串
about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。'
match = re.search(pattern,about) # 进行模式匹配
if match == None: # 判断是否为None,为真表示匹配失败
print(about,'@ 安全!')
else:
print(about,'@ 出现了危险词汇!')
about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。'
match = re.match(pattern,about) # 进行模式匹配
if match == None: # 判断是否为None,为真表示匹配失败
print(about,'@ 安全!')
else:
print(about,'@ 出现了危险词汇!')
我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。 @ 出现了危险词汇!
我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。 @ 安全!
findall()方法:在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回。
如果匹配成功,则返回包含匹配结构的列表,否则返回空列表。
re.findall(pattern, string, [flags])
搜索以 mr_ 开头的字符串
import re
pattern = r'mr_\w+'
string = 'MR_SHOP mr_shop'
match = re.findall(pattern, string, re.I)
print(match)
string1 = 'sdfdsMR_SHOP dsfsdf mr_shop'
match2 = re.findall(pattern, string)
print(match2)['MR_SHOP', 'mr_shop']
['mr_shop']
注意:
在指定模式的字符串中,包含分组,则返回与分组匹配的文本列表,例如:
import re
pattern = r'[1-9]{1,3}(\.[0-9]{1,3}){3}'
str1 = '127.0.0.1 192.168.1.66'
match = re.findall(pattern, str1)
print(match)['.1', '.66']
import re
pattern = r'([1-9]{1,3}(\.[0-9]{1,3}){3})'
str1 = '127.0.0.1 192.168.1.66'
match = re.findall(pattern, str1)
print(match)
for item in match:
print(item[0])[('127.0.0.1', '.1'), ('192.168.1.66', '.66')]
将整个模式字符串用一对小括号进行分组
127.0.0.1
192.168.1.66
字符串的替换:re.sub(pattern, repl ,string,[count], [flags])
pattern 将要替换的模式字符串
repl 表示替换的字符串
string 要被查找替换的原始字符串
count 可选参数,表示模式匹配后替换的最大次数
flags 可选参数,表示标志位,控制匹配方式(区分大小写?)
import re
pattern = r'1[34578]\d{9}'
string = '中奖号码为:84978981 联系电话是: 13611111111'
result = re.sub(pattern, '1XXXXXXXXX', string)
print(result)
中奖号码为:84978981 联系电话是: 1XXXXXXXXX
import re # 导入Python的re模块
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' # 模式字符串
about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan。\n'
sub = re.sub(pattern,'@_@',about) # 进行模式替换
print(sub)
about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。'
sub = re.sub(pattern,'@_@',about) # 进行模式替换
print(sub)
我是一名程序员,我喜欢看@_@方面的图书,想研究一下@_@。
我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。
正则表达式分割字符:re.split(pattern, string , [maxsplit], [flags])
pattern 模式字符串
string 要匹配的字符串
[maxsplit] 最大的拆分次数
flags 标志位,控制匹配方式
import re
str1 = '@明日科技 @扎克伯格 @俞敏洪'
pattern = r'\s*@'
list1 = re.split(pattern,str1) # 用空格和@或单独的@分割字符串
print('您@的好友有:')
for item in list1:
if item != "": # 输出不为空的元素
print("\n",item) # 输出每个好友名
您@的好友有:
明日科技
扎克伯格
俞敏洪