python实现梯度下降优化算法

友情链接
结合numpy及mnist库的简单神经网络演练
用numpy构造多种损失函数
使用Numpy实现简单二层神经网络
实现二层神经网络反向传播
文章目录
- 友情链接
- 前言
- 正文
- SGD
- 算法基础
- 优点
- 缺点
- 简单实现
- momentum
- 算法基础
- 优点
- 缺点
- 简单实现
- AdamGrad
- 算法基础
- 优点
- 缺点
- 简单实现
- RMSProp
- 算法基础
- 优点
- 缺点
- 简单实现
- Adam
- 算法基础
- 优点
- 实现
- 实践证明
- 总结
前言
在前面的博客中,我们已经能够基本完成一个简单神经网络的编写,通过使用反向传播的方式来有效地提高了计算速率。而前面构造的简单神经网络除了使用最普通的SGD外,像mini-batch一样对梯度下降法优化的方案非常多,并且这样的优化基本是基于SGD方式,因此一次迭代更新所需要的时间就会比BGD要大幅度短得多。
但是稍微了解SGD(随机梯度下降法)的都会知道,SGD虽然能够减小时间成本,但是随机性较大,落到局部最优点之前会出现震荡现象,因此就出现了本节要复习的多种优化方案。
正文
SGD
算法基础
在介绍其他方法之前,显然打好基础是非常的重要,SGD是由于BGD以及mini-batch消耗资源巨大的基础上提出的,对比前两者,其算法基础是根据某一点(或者说某一条训练数据)的梯度来更新权重参数的值,通过这样一条一条的进行梯度下降,最终到达局部最优点。
x t = x t − 1 − η α L α W x_t=x_{t-1}-η\frac{αL}{αW} xt=xt−1−ηαWαL
优点
(1)相比较于BGD与mini-batch,其训练数据时少了很多冗余重复的计算,速度更快
(2)不想SGD那样相对固定,可以灵活的向数据集中添加样本,而不必重新训练所有数据集
缺点
(1)由于每条数据求出的梯度并不是严格遵循最优梯度下降方向,因此精确度变低,需要迭代更多次
(2)损失会出现大的颠簸,不会迅速向最优值收敛
简单实现
传入两个参数params以及grads,分别对应权重参数集以及权重参数的梯度矩阵
@classmethod
# 随机梯度下降方法, 为固定参数方法,不做任何多余处理,通过对每个点的损失求参数梯度
# 更新权重参数,直至达到局部最优
def sgd(cls, params, grads, lr=0.01):
for key in params.keys():
params[key] -= lr * grads[key]
momentum
算法基础
momentum是结合动量定理来理解,由于震荡时的拐弯过于尖锐,所以如果模拟从高处向低处s型运动时,梯度如同加速度,而速度则是上一秒的速度减去这一秒的平均加速度,也就是说前面的梯度对后续梯度下降会产生一定的影响,这正是算法优化的最基本思想。而小球不会拐直角的原因主要由于摩擦阻力对小球的影响,让其有一定弧度的绕回。
v t = a v t − 1 − η α L α W v_t=av_{t-1}-η\frac{αL}{αW} vt=avt−1−ηαWαL
x t = x t − 1 + v t x_t = x_{t-1}+v_t xt=xt−1+vt
其中参数a可以理解为摩擦阻力系数,因为摩擦阻力一般与v成正比,(1-a)v_{t-1}即可以理解为摩擦阻力这一秒抵消掉的速度。

优点
(1)由于这种方式对于梯度方向不变的维度速度不断加快,而对于梯度方向变化的维度则起着一定的抑制作用,有效的抑制了震荡
缺点
(1)如同小球滚动一般,如果到达最低点的速度还没有减为0,则会上坡一段距离再返回,因此就会形成在最小值点来回震荡的现象
简单实现
@classmethod
# 动量方式优化SGD,通过加入一个超参数,模拟存在摩擦系数或者空气阻力的情况
# 不断削减损失值,减小SGD震荡程度
def momentum(cls, params, grads, lr=0.01, momentum=0.9):
if len(cls.momentum_v) == 0:
for key, val in params.items():
cls.momentum_v[key] = np.zeros_like(val)
for key in params.keys():
cls.momentum_v[key] = momentum * cls.momentum_v[key] - lr * grads[key]
params[key] += v[key]
AdamGrad
算法基础
全称Adaptive gradient algorithm,这是一种自适应学习率的算法,有时候我们就是希望在开始时步长可以大一些,而后续我们可以缩减学习步长,让其逐渐逼近局部最小值点。因此我们采用梯度平方和累加的方式,通过不断累加梯度的方式不断减小学习率,最终合理的达到局部最优解。
h t = h t − 1 + α L α W ∗ α L α W h_t=h_{t-1}+\frac{αL}{αW}*\frac{αL}{αW} ht=ht−1+αWαL∗αWαL
x t = x t − 1 − η 1 h t + ε α L α W x_t=x_{t-1}-η\frac{1}{\sqrt{h_t}+ε}\frac{αL}{αW} xt=xt−1−ηht+ε1αWαL
优点
(1)其动态调节学习率η的方式值得深思采纳
(2)对于大多数情况能够实现快速收敛
缺点
(1)经过不断迭代,学习率会达到非常小的情况,最后几乎停止更新
(2)学习率不断减小容易陷入局部最小值而跳不出来,显得有些强制收敛的意思
简单实现
@classmethod
# AdaGrad(Adaptive Gradient Algorithm)这种方式采用衰减学习率的方式来不断减小学习率
# 从而使得在接近最小值点是不会发生偏离震荡,对于低频的参数会进行较大的更新,实现了学习率的自动更新
# 缺点是最终学习率会陷入停滞状态
def adaGrad(cls, params, grads, lr=0.01):
if len(cls.adagrad_h) == 0:
for key, val in params.items():
cls.adagrad_h[key] = np.zeros_like(val)
for key in params.keys():
cls.adagrad_h[key] += grads[key] * grads[key]
params[key] -= lr * grads[key] / (np.sqrt(cls.adagrad_h[key]) + 1e-7)
RMSProp
算法基础
这种方法正是为了解决学习率急剧下降的问题,是对于AdamGrad的优化算法。其主要思想采用的是指数加权平均的思想,通过制定参数β,来平均1/(1-β)个近来梯度,通过对指数的不断乘方,使得前面传来的梯度影响不断减小,最终忽略,而不至于出现学习率快速递减的现象。
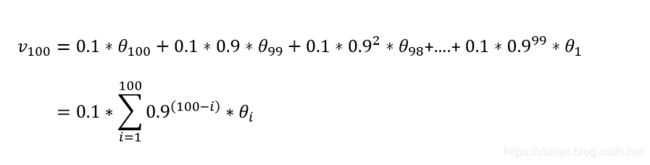
如上的例子,当β=0.9时,(0.9)11 ≈ 0.3,几乎减小到可以忽略的地步,这样就相当于对前面10项进行加权平均的得数,指数加权平均得名因此而来。
h t = β ⋅ h t − 1 + ( 1 − β ) ⋅ α L α W ∗ α L α W h_t=β·h_{t-1}+(1-β)·\frac{αL}{αW}*\frac{αL}{αW} ht=β⋅ht−1+(1−β)⋅αWαL∗αWαL
x t = x t − 1 − η 1 h t + ε α L α W x_t=x_{t-1}-η\frac{1}{\sqrt{h_t}+ε}\frac{αL}{αW} xt=xt−1−ηht+ε1αWαL
优点
(1)与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。
(2)允许使用一个更大的学习率η来开始一开始的迭代,从而加快逼近局部最小值。
缺点
(1)在实际使用中似乎存在着一定的问题,对于β的参数设定较为难以考察
简单实现
@classmethod
# 为了克服AdaGrad最终学习率陷入停滞状态,因此出现了AdaGrad的优化算法
# 使用了指数加权平均的方式,减小前面权重的同时对当前权重进行累加,防止出现学习率急剧衰减的情况
def rmsProp(cls, params, grads, lr=0.01, b=0.9):
if len(cls.rms_h) == 0:
for key, val in params.items():
cls.rms_h[key] = np.zeros_like(val)
for key in params.keys():
cls.rms_h[key] = b * cls.rms_h[key] + (1.0 - b) * (grads[key]*grads[key])
params[key] -= lr * grads[key] / (np.sqrt(cls.rms_h[key]) + 1e-7)
Adam
算法基础
Adam可以说是Momentum以及RMSProp的结合算法,同时设定两个可调参数β1以及β2,既保存了梯度平均,又保存了梯度平方和平均,下降过程中保持较稳定的趋势,并且损失下降速度也比SGD要快了很多。
v t = β 1 v t − 1 + ( 1 − β 1 ) α L α W v_t=β_1v_{t-1}+(1-β_1)\frac{αL}{αW} vt=β1vt−1+(1−β1)αWαL
h t = β 2 h t − 1 + ( 1 − β 2 ) ( α L α W ) 2 h_t = β_2h_{t-1}+(1-β_2)(\frac{αL}{αW})^2 ht=β2ht−1+(1−β2)(αWαL)2
X t = X t − 1 − η v t h t 2 + ε X_t = X_{t-1}-η\frac{v_t}{\sqrt{h_t^2}+ε} Xt=Xt−1−ηht2+εvt
优点
(1)属于算法优化方法,损失下降速度较快,效果较好
(2)对于多数深度学习算法有着非常好的效果
实现
@classmethod
# 该方法相当于Momentum与RMSProp算法,同时使用了动量方式以及指数加权平均
# 该方法既减缓震荡又能动态调整学习率,多种神经网络算法都使用此方式
def adam(cls, params, grads, lr=0.01, b1=0.9, b2=0.99):
if len(cls.adam_h)==0 or len(cls.adam_v) == 0:
for key, val in params.items():
cls.adam_h[key] = np.zeros_like(val)
cls.adam_v[key] = np.zeros_like(val)
for key in params.keys():
# 包含了一步偏差校正
cls.adam_v[key] = (b1 * cls.adam_v[key] + (1.0 - b1) * grads[key])
cls.adam_h[key] = (b2 * cls.adam_h[key] + (1.0 - b2) * (grads[key]*grads[key]))
params[key] -= lr * cls.adam_v[key] / (np.sqrt(cls.adam_h[key]) + 1e-7)
实践证明
分析完了理论,当然需要通过实践来分析一下各个梯度下降算法的迭代效果,因此还是使用熟悉的mnist数据来对我们前面博客的反向传播二层神经网络进行迭代:
我们实践中依然比较推荐使用mini-batch来选择一批数据来进行训练,因为对于神经网络来说,如果每次只是放入一条数据,那么可能权重更改会非常小,甚至超出了float保存的最大范围,就无法更改权重,即无法进行训练。(这里没有加入rmsProp)
# 迭代次数
iter_num = 2000
# 初始学习率
lr = 0.01
# mini-batch抽取数据量
batch_size = 200
(X_train, Y_train), (X_test, Y_test) = load_mnist(one_hot_label=True)
epoch = max(X_train.shape[0] / batch_size, 1)
m = 1
methods= {"sgd": ["o", 'r'], "momentum": ["d", "b"], "adaGrad": ["x", "y"], "adam": ["s", "black"]}
# 使用mnist数据测试下降能力
fig = plt.figure(111)
for name, val in methods.items():
loss_history = []
# 每次使用一种梯度下降前创建一个新的神经网络,重新进行训练
network = TwoLayer(input_layer_size=784, hidden_layer_size=100, output_layer_size=10)
for i in range(iter_num):
x_batch_num = np.random.choice(X_train.shape[0], batch_size)
x_batch = X_train[x_batch_num]
y_batch = Y_train[x_batch_num]
# 获取神经网络梯度
grads = network.gradient(x_batch, y_batch)
# 反射方式调用相关梯度下降函数
getattr(GradientMethod, name)(network.params, grads)
loss_history.append(network.last_layer.loss)
# 每隔一定时间输出一下训练准确率
if (i+1)%epoch == 0:
print("iter_time: "+str(i+1)+" methods: "+name+" current loss:"+str(loss_history[i])+\
" accuracy:"+str(network.get_accuracy(X_test, Y_test)))
print("iter_time: " + str(2000) + " methods: " + name + " current loss:" + str(loss_history[i]) + \
" accuracy:" + str(network.get_accuracy(X_test, Y_test)))
plt.plot(np.arange(len(loss_history)), loss_history, c=val[1])
plt.legend([name for name in methods.keys()])
plt.show()
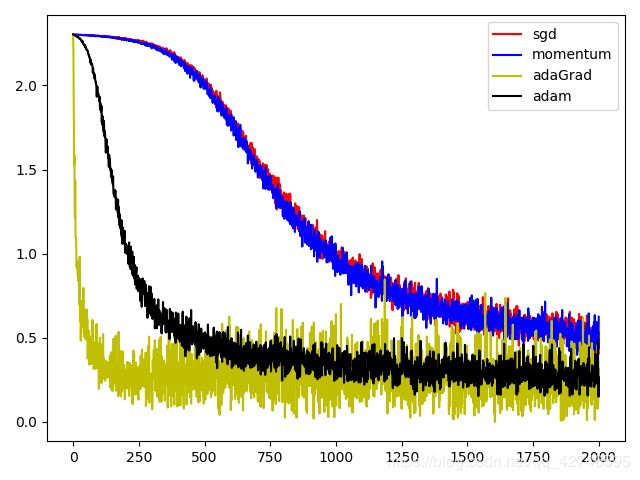
打印出的不同梯度下降的测试集准确率统计如下(只展示最终结果):
iter_time: 2000 methods: sgd current loss:0.480851670890771 accuracy:0.8736
iter_time: 2000 methods: momentum current loss:0.48494613357437694 accuracy:0.8713
iter_time: 2000 methods: adaGrad current loss:0.45390115929663927 accuracy:0.9628
iter_time: 2000 methods: adam current loss:0.2246958390517225 accuracy:0.9242
以及相应的损失波动图:
总结
通过简单测试我们可以了解这几种梯度下降算法的特点
(1)BGD与Momentum的loss下降趋势基本一致,momentum主要是对BGD震荡的优化,从图中基本可以看出loss的波动momentum要比BGD小一些
(2)AdaGrad对于少量数据的训练时,开始的下降速度非常快,但是后期由于学习率减小较快,因此损失基本不再减小,波动也比较大;但是从准确率来看,AdaGrad的预测准确率确实最高的,这说明对于少量迭代,其效率远超其他算法。(不过如果将迭代次数从2000到达20000,AdaGrad将不占优势)
(3)Adam方式显然相比于BGD和Momentum要快得多,并且随着迭代进行,其损失的波动也越来越小,并且准确率也较高,并且随着迭代次数的增大,其准确率保持持续提升的能力较强,因此深度学习中Adam可以说优于其他算法。