Kaggle入门之泰坦尼克号生还预测
Kaggle入门之泰坦尼克号生还预测
Kaggle网址:https://www.kaggle.com/
数据集下载地址:https://github.com/Hujiang213/Kaggle-Titanic
比赛说明
RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并导致了更好的船舶安全规定。
造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,比如女人,孩子和上流社会。
在这个挑战中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
分析过程
1、数据准备与分析
import pandas
train_data = pandas.read_csv("C:\\Users\\asus-pc\\Downloads\\train.csv")
train_data.head(10)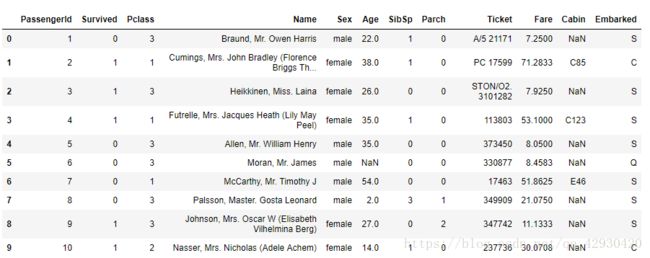
初探数据集,打开csv文件,想查看前十行数据(也可用Excel打开查看所有的数据)
这是典型的dataframe格式,数据总共有12列,其中Survived字段表示的是该乘客是否获救,其余都是乘客的个人信息,包括:
PassengerId —> 乘客编号
Survived —>是否生还,是为1,否为0
Pclass —> 船票等级(1/2/3等舱位)
Name —> 乘客姓名
Sex —> 性别
Age —> 年龄
SibSp —> 堂兄弟/姐妹个数
Parch —> 父母与儿女个数
Ticket —> 船票编号
Fare —> 票价
Cabin —> 客舱号
Embarked —> 登船港口(S/C/Q港口)
从Excel发现,数据集中年龄有少部分缺失(年龄是比较重要的数据),先进行填补之后,我们看一下数据的描述性统计结果:
train_data["Age"] = train_data["Age"].fillna(train_data["Age"].median())
train_data.describe()
观察描述性统计结果,一共有891条记录。mean字段告诉我们,大概38.38%的人最后获救了。在填补年龄数据之后,,乘客的平均年龄在29岁左右,年龄最小的不到半岁,年龄最大的则有80岁。其他未能统计的数据列,将在接下来的数据预处理中进行整理。
2、数据预处理
剔除无意义的船票编号跟缺失值太多的舱位信息后,对非数值型数据(“Sex”,“Embarked”)转化为数值型数据。
train_data["Sex"].unique()
train_data.loc[train_data["Sex"] == "male", "Sex"] = 0
train_data.loc[train_data["Sex"] == "female", "Sex"] = 1
# 性别“男”是0,“女”是1
train_data["Embarked"].unique()
train_data["Embarked"] = train_data["Embarked"].fillna('S')
train_data.loc[train_data["Embarked"] == "S", "Embarked"] = 0
train_data.loc[train_data["Embarked"] == "C", "Embarked"] = 1
train_data.loc[train_data["Embarked"] == "Q", "Embarked"] = 2
# 三个登船港口分别是0、1、23、简单分析数据关系
(1)船票等级与是否生存的关系 Pclass

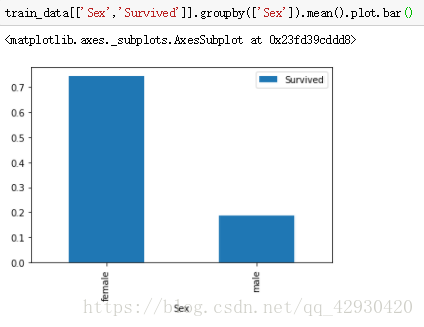
(2) 性别与是否生存的关系 Sex
(3)年龄分布
# 总体年龄分布
import matplotlib.pyplot as plt
plt.figure(figsize=(12,5))
plt.subplot(121)
train_data['Age'].hist(bins=70)
plt.xlabel('Age')
plt.ylabel('Num')
4、建模分析(随机森林)
刚开始跟大多数人使用的方法一样,用逻辑回归进行建模分析与评估,我这里省略一些步骤,用预测结果超过80%的随机森林来建模。
from sklearn.ensemble import RandomForestClassifier
from sklearn import cross_validation
from sklearn.cross_validation import KFold
# 用来预测的关键列
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# 先初始化算法
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
# 生成交叉验证库,将测试集进行切分交叉验证取平均
kf = KFold(train_data.shape[0], n_folds=3, random_state=1) #将m个样本平均分成3份进行交叉验证
predictions = []
for train, test in kf:
train_predictors = (train_data[predictors].iloc[train,:])
train_target = train_data["Survived"].iloc[train]
alg.fit(train_predictors, train_target)
test_predictions = alg.predict(train_data[predictors].iloc[test,:])
predictions.append(test_predictions)
scores = cross_validation.cross_val_score(alg, train_data[predictors], train_data["Survived"], cv=kf)
print(scores.mean())未调整RandomForestClassifier里的参数时,准确率约为78.5%。调整参数,训练好模型之后,接下来就是进行预测了,首先得把test.csv文件中的数据进行预处理:
test_data = pandas.read_csv("C:\\Users\\asus-pc\\Downloads\\test.csv")
test_data["Age"] = test_data["Age"].fillna(train_data["Age"].median())
test_data["Fare"] = test_data["Fare"].fillna(test_data["Fare"].median())
test_data.loc[test_data["Sex"] == "male", "Sex"] = 0
test_data.loc[test_data["Sex"] == "female", "Sex"] = 1
test_data["Embarked"] = test_data["Embarked"].fillna("S")
test_data.loc[test_data["Embarked"] == "S", "Embarked"] = 0
test_data.loc[test_data["Embarked"] == "C", "Embarked"] = 1
test_data.loc[test_data["Embarked"] == "Q", "Embarked"] = 2这里的预处理跟前面的差不多,接下来就是把test.csv的数据弄进模型里进行预测,生成预测文件:
from pandas import DataFrame,Series
alg = RandomForestClassifier(random_state=1, n_estimators=100, min_samples_split=6, min_samples_leaf=2)
kf = KFold(train_data.shape[0], n_folds=3, random_state=1)
alg.fit(train_predictors, train_target)
predictions = alg.predict(test_data[predictors])
df = DataFrame([test_data.PassengerId,Series(predictions)],index=['PassengerId','Survived'])
df.T.to_csv("C:\\Users\\asus-pc\\Downloads\\yuce1.csv",index=False)
scores = cross_validation.cross_val_score(alg, train_data[predictors], train_data["Survived"], cv=kf)
print(scores.mean())![]()
调整好参数后,预估的准确率达到83%。这时就可以在Kaggle提交预测文件了,结果如下:

准确率达到77.033%,还是一个挺不错的成绩。
5、模型评估与优化
使用几个机器学习模型进行模型融合的话,可以让预测结果更准确。
6、可能遇到的问题与解决方法
(1)sklearn.cross_validation 0.18版本废弃警告

主要意思是说在0.18版本中,cross_validation被废弃了。但实际测试感觉功能并为受影响,可以正常使用,只是有提示信息。