使用scrapy框架项目实践
任务说明:使用scrapy框架爬取58同城上面的租房信息,同时解密被加密的文字,最后将结果上传到MongoDB,期间启动中间件来反爬虫。
这里使用Python3.7开发(考虑到Python对汉字不太友好,这里选择Python3版本就是为了避免因为汉字而导致程序报错)
首先我们打开pycharm创建项目,创建好的项目目录如下图:

定义item
确定我们要爬取的内容,进入58同城的租房板块,进入租房页面类,下面就以此链接为例确定要抓取的内容

item.py代码如下
class RenthouseItem(scrapy.Item):
# 租金
rent_money = scrapy.Field()
# 押金
ya_jin = scrapy.Field()
# 租赁方式
rent_way = scrapy.Field()
# 房屋类型
house_style = scrapy.Field()
# 房屋朝向
house_toward = scrapy.Field()
# 房屋楼层
house_foor = scrapy.Field()
# 小区
xiao_qu = scrapy.Field()
# 区域
house_area = scrapy.Field()
# 详细区域
detail_area = scrapy.Field()
# 链接
url = scrapy.Field()
爬虫模块
链接提取
获取每个页面链接,回调函数实现网页的解析
allowed_domains = ['wh.58.com']
start_urls = ['https://wh.58.com/zufang/']
rules = (
Rule(LinkExtractor(allow=r'zufang/pn\d+/'), follow=True),
Rule(LinkExtractor(allow=r'zufang/\d+x\.shtml'), callback='parse_item'),
)
解析
#租金
rent_money :’//b[@class=“f36 strongbox”]/text()’
#押金
ya_jin : ‘//span[@class=“c_333”]/text()’
#租赁方式
rent_way : ‘//ul[@class=“f14”]/li[1]/span[2]/text()’
#房屋类型
house_style :’//ul[@class=“f14”]/li[2]/span[2]/text()’
#房屋朝向
house_toward : ‘//ul[@class=“f14”]/li[3]/span[2]/text()’ #朝向与楼层在一条信息内,注意要将其提取出来 例如(南 高层/共25层)
#房屋楼层
house_foor : ‘//ul[@class=“f14”]/li[3]/span[2]/text()’#楼层与朝向在一条信息内,注意要将其提取出来 例如(南 高层/共25层)
#小区
xiao_qu : response.xpath(’//ul[@class=“f14”]/li[4]/span[2]/a/text()’).extract()
#区域
house_area : ‘//ul[@class=“f14”]/li[5]/span[2]/a/text()’ #有两条信息,注意合并
#详细区域
detail_area : ‘//span[@class=“dz”]/text()’
#链接
url = response.url
字体解密
这里我们发现数字会出现两种不同的形式,一个是数字表示,另一种被加密,见下图:
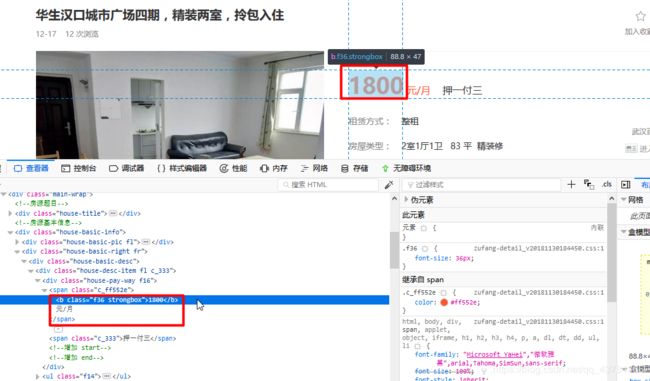
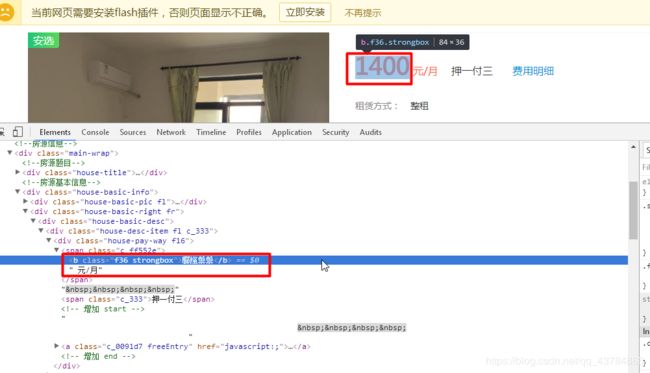
所以这里数字部分被加密,这里有具体解密方法(https://blog.csdn.net/LoveL_T/article/details/84647904)(https://blog.csdn.net/LoveL_T/article/details/84658930)
因此判断数字是否加密,得从页面源代码中查找图示内容,如果有,则被加密
 具体查找方法我们这里使用正则表达式
具体查找方法我们这里使用正则表达式
result = re.findall(r"base64\,(.*?)'\)", response.body_as_unicode(), re.S)
#response.body_as_unicode()返回一个Unicode编码的响应的body内容
现在说了这么多,上代码:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from rentHouse.items import RenthouseItem
import re
from fontTools.ttLib import TTFont
import base64
from io import BytesIO
class ZhuFangSpider(CrawlSpider):
name = 'zhu_fang'
allowed_domains = ['wh.58.com']
start_urls = ['https://wh.58.com/zufang/']
rules = (
Rule(LinkExtractor(allow=r'zufang/pn\d+/'), follow=True),
Rule(LinkExtractor(allow=r'zufang/\d+x\.shtml'), callback='parse_item'),
)
def parse_item(self, response):
result = re.findall(r"base64\,(.*?)'\)", response.body_as_unicode(), re.S)
# 租金
rent_money = self.get_rent_money(response,result)
# 押金
ya_jin = self.get_ya_jin(response)
# 租赁方式
rent_way = self.get_rent_way(response)
# 房屋类型
house_style = self.get_house_style(response,result)
# 房屋朝向
house_toward = self.get_house_toward(response)
# 房屋楼层
house_foor = self.get_house_foor(response,result)
# 小区
xiao_qu = self.get_xiao_qu(response)
# 区域
house_area = self.get_house_area(response)
# 详细区域
detail_area = self.get_detail_area(response)
# 链接
url = response.url
item = RenthouseItem(rent_money = rent_money,ya_jin = ya_jin,rent_way = rent_way,house_style = house_style, house_toward = house_toward,
house_foor = house_foor,xiao_qu = xiao_qu,house_area = house_area,detail_area = detail_area,url = url)
yield item
def get_rent_money(self,response,result):
rent_money = response.xpath('//b[@class="f36 strongbox"]/text()').extract()
if len(rent_money) == 0:
return None
else:
if len(result) == 0:
return rent_money[0]
else:
ziti = rent_money[0]
code_str = result[0]
rent_money = self.jiema(ziti, code_str)
return rent_money
def get_ya_jin(self,response):
ya_jin = response.xpath('//span[@class="c_333"]/text()').extract()
if len(ya_jin) != 0:
return ya_jin[0]
else:
return None
def get_rent_way(self,response):
rent_way = response.xpath('//ul[@class="f14"]/li[1]/span[2]/text()').extract()
if len(rent_way) != 0:
return rent_way[0]
else:
return None
def get_house_style(self,response,result):
house_style = response.xpath('//ul[@class="f14"]/li[2]/span[2]/text()').extract()
if len(house_style) == 0:
return None
else:
if len(result) == 0:
return house_style[0].replace("\xa0","").replace(" ","")
else:
code_str = result[0]
zitis = re.findall(r"(.*?)室(.*?)厅(.*?)卫\s+(.*?)\s+平", house_style[0], re.S)[0]#通过正则表达式获取字体
data = []
for ziti in zitis:
house_style_date = self.jiema(ziti, code_str)
data.append(house_style_date)
house_style = "%s室%s厅%s卫%s平" % (data[0], data[1], data[2], data[3])
return house_style
def get_house_toward(self,response):
house_toward = response.xpath('//ul[@class="f14"]/li[3]/span[2]/text()').extract()[0].split("\xa0\xa0")
if len(house_toward) != 0:
return house_toward[0]
else:
return None
def get_house_foor(self,response,result):
house_foor = response.xpath('//ul[@class="f14"]/li[3]/span[2]/text()').extract()[0].split("\xa0\xa0")
if len(house_foor) == 0:
return None
else:
if len(result) == 0:
return house_foor[1]
else:
ziti = re.findall(r"共(.*?)层", house_foor[1], re.S)[0]
code_str = result[0]
floor = self.jiema(ziti, code_str)
print(floor)
house_foor = house_foor[1].replace(ziti, floor)
return house_foor
def get_xiao_qu(self,response):
xiao_qu = response.xpath('//ul[@class="f14"]/li[4]/span[2]/a/text()').extract()
if len(xiao_qu) != 0:
return xiao_qu[0]
else:
return None
def get_house_area(self,response):
house_area = response.xpath('//ul[@class="f14"]/li[5]/span[2]/a/text()').extract() # 有两条,注意合并
if len(house_area) != 0:
return " ".join(house_area)
else:
return None
def get_detail_area(self,response):
detail_area = response.xpath('//span[@class="dz"]/text()').extract()
if len(detail_area) != 0:
return detail_area[0].replace(" ","").replace("\n","")
else:
return None
'''破解字体加密'''
def make_font_file(self,base64_string: str):
# 将base64编码的字体字符串解码成二进制编码
bin_data = base64.decodebytes(base64_string.encode())
return bin_data
def jiema(self,ziti, code_str):
result = []
code_ziti = []
# ByteIO把一个二进制内存块当成文件来操作
font = TTFont(BytesIO(self.make_font_file(code_str)))
# 找出基础字形名称的列表,例如:uniE648,uniE183......
c = font['cmap'].tables[0].ttFont.tables['cmap'].tables[1].cmap
for i in range(len(ziti)):
# 找出每一个字对应的16进制编码
code = int(ziti[i].encode("unicode-escape").decode()[-4:], 16)
code_ziti.append(code)
for code in code_ziti:
# 根据code键找出c字典中对应的值减一
x = int(c[code][-2:]) - 1
# result.append(x)
result.append(str(x))
return "".join(result) if len(result) != 0 else None
以上过程就包括了数据的解析,还有字体解密整过过程
定制item piplines
我们需要将爬虫爬取的item里面的数据上传到MongoDB数据库里,完整内容如下:
import pymongo
class RenthousePipeline(object):
def __init__(self):
client = pymongo.MongoClient(host="localhost",port=27017)
db = client["58tong_cheng"]
self.sheet = db["zu_fang_infos"]
def process_item(self, item, spider):
self.sheet.insert(dict(item))
return item
在settings.py中激活item piplines
ITEM_PIPELINES = {
'rentHouse.pipelines.RenthousePipeline': 300,
}
突破反爬虫
这里采用动态设置Request的User-Agent字段,以此来突破反爬虫对User-Agent字段的检查
在middlewares.py写入
from random import choice
class RandomUserAgent(object):
def __init__(self,agents):
self.agent_list = agents
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings.getlist("USER_AGENTS"))
def process_request(self,request,spider):
request.headers.setdefault("User-Agent",choice(self.agent_list))
USER_AGENTS是写在settings.py当中的User-Agent列表
 在settings.py中激活中间件
在settings.py中激活中间件
DOWNLOADER_MIDDLEWARES = {
'rentHouse.middlewares.RandomUserAgent': 500,
}
禁用cookie,设置settings文件中的COOKIES_ENABLED = False
设置下载延时和自动限速
RANDOM_DOWNLOAD_DELAY = True
DOWNLOAD_DELAY = 3
#下载延迟时间为0.5到1.5之间的一个随机数乘以DOWNLOAD_DELAY,但是这样访问网站的时间延迟会有一定的相似性,也会有被发现的危险
#为了应对这种风险,则设置自动限速,通过自动限速可以根据Scrapy服务器及爬取的网站的负载自动限制爬虫速度
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY =5 #初始下载延时默认为5秒
AUTOTHROTTLE_MAX_DELAY = 10 #在高速延迟情况下最大的下载延迟,默认为60秒
结尾
我们来看看MongoDB类的数据,看看是否解码成功
这个是页面信息

未解密情况下爬取的内容 ,可以看到数字部分被加密
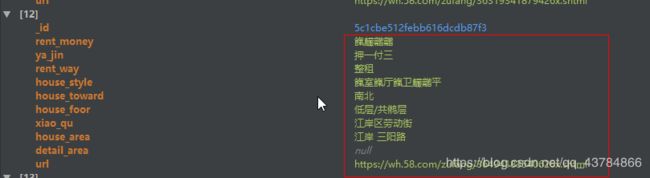
解密后爬取的内容,可以看到,数据都被解密

到这里整个项目就结束了,如有错误的地方欢迎指正