利用Python爬取《囧妈》豆瓣短评数据,并进行snownlp情感分析
利用Python爬取《囧妈》豆瓣短评数据,并进行snownlp情感分析
一、电影评论爬取
今年的贺岁片《囧妈》上映前后,在豆瓣评论上就有不少网友发表了自己的观点,到底是好评的声音多还是差评的声音多,评价的情感又是怎样的呢,我们通过Python进行数据爬取,然后用snownlp进行情感分析。
使用游客身份进行数据爬取时,只能爬取11页共220条。这数据量太少了,玩起来没什么代表性,还得想办法爬更多的数据,办法就是注册账号,用cookie进行登录,把cookie添加到headers里面去,具体操作看程序
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from lxml import etree
import time
import pandas as pd
ua = UserAgent()
""" #headers模板
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Mobile Safari/537.36',
'cookie': '将复制的cookie信息贴在此处'}
"""
cookie='XXXXX '
headers = {'User-Agent': ua.chrome,'cookie':cookie}
start=time.clock()
comment_word=[]
for ii in range(820):
ss=ii*20
url='https://movie.douban.com/subject/30306570/comments?start=%s'%ss+'&limit=20&sort=new_score&status=P'
req= requests.get(url,headers=headers)
soup=BeautifulSoup(req.text,'lxml')#生成一个BeautifulSoup 对象,用以后面的查找工作,lxml 字典
xml_word=soup.find_all('span',class_='short') #评论内容位置
xml_zan=soup.find_all('span',class_='votes') #点赞数位置
xml_time=soup.find_all('span',class_='comment-time') #点赞数位置
time.sleep(1)
for i in range(len(xml_word)):
msg__word=xml_word[i].text
msg_zan=int(xml_zan[i].text)
msg_time=xml_time[i].text.split('\n')[1].split(' ')[-1]
comment_word.append([msg_time, msg_zan,msg__word])
comentv=pd.DataFrame(comment_word,columns=['评论时间','点赞数量','评论内容'])
comentv.to_csv('C:/Users/lenovo/Desktop/muvieos.csv',encoding='utf_8_sig', index=False)
end=time.clock()
print('time is:',end-start)
我的程序中抓取了评论时间、评论内容、觉得有用的数量,同时记录一下程序运行时耗费的时间。经过漫长的等待,结果发现一次只能爬500条数据,然后IP就被限制了,需要输入验证码,网上有破解的办法,具体也不想去研究了,就先拿500条数据来玩吧。

电影是在2020/1/25上映,看一看评论在电影上映前后的热度,显然上映前讨论得比较热闹,点击有用的个数还是比较高的,随着时间的推移,受关注度就越来越低。
import matplotlib.pyplot as plt
plt.figure(figsize=[40,12])
plt.plot(DATAS.评论时间,DATAS.点赞数量,'*')
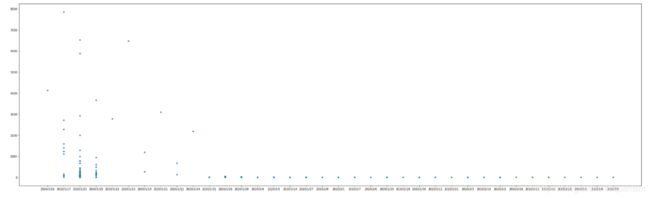
二、情分分析
接下来就是利用snownlp来做情感分析了,但是这个包原来是用来做购物评价分析的,直接用来做电影情感分析,得到的答案不是很准确,打开snownlp安装所在目录,可以看到中文本积极评论pos.txt和消极评论neg.txt所在的位置,打开这两个文件夹可以看到里面很多中文

例如neg.txt里面的内容是:

训练是更好地完善现有的语料库,官方提供的教程提供训练的包括分词,词性标注,情感分析。以分词为例 ,在snownlp/seg目录下:
# 分词训练
from snownlp import seg
seg.train('data.txt')
seg.save('seg.marshal')
# 词性标注训练
# from snownlp import tag
# tag.train('199801.txt')
# tag.save('tag.marshal')
# 情感分析训练
# from snownlp import sentiment
# sentiment.train('neg.txt', 'pos.txt')
# sentiment.save('sentiment.marshal')
这样训练好的文件就存储为seg.marshal了,之后修改snownlp/seg/init.py里的data_path指向刚训练好的文件即可
为了建立训练素材,我打开已经爬取并保存好的CSV文件夹,根据自己的主观判断进行正反面分类,把标记好的两个素材文件pos.txt,neg.txt放到原包的位置。
我直接运行情感分析训练程序的时候出现两个地方报错:
1、FileNotFoundError: [Errno 2] No such file or directory: ‘pos.txt’
解决办法:建立绝对路径,‘C:/Users/lenovo/Desktop/orial/pos.txt’,pos.txt 和neg.txt同样建立绝对路径
2、建立绝对路径后,报错:‘utf-8’ codec can’t decode byte 0xc6 in position 0: invalid continuation byte,
解决办法:我们在新建并保存txt文件的时候默认是ANSI格式,再另存为utf-8并覆盖源文件就行了

from snownlp import sentiment
sentiment.train('C:/Users/lenovo/Desktop/orial/neg.txt','C:/Users/lenovo/Desktop/orial/pos.txt')
sentiment.save('sentiment.marshal')
训练完后,就可以拿来检验训练效果了
from snownlp import SnowNLP
s='我讨厌这部电影,甚至作呕,强行灌鸡汤,强行要把所谓的黑暗面撕出来,然后结尾强行煽情和解。没有人没和解,只是徐峥自己没和解吧!'
ss=SnowNLP(s)
ss.sentiments
在我没训练之前,直接运用原生态的包,得到的分数是0.6+,这个分数虽然不是很高,但是明显跟我们主观判断相差太远,训练后得到的分数数1.0683347495765716e-05,效果还不错。
如果还想恢复原生态安装包的pos.txt,neg.txt,sentiment.marshal这三个文件,可以通过先关闭程序运行,卸载这个包再安装
pip uninstall snownlp
pip install snownlp
由于我差不多使用了前200+的评论作为训练样本了,为了不混淆,我从300开始检测评论结果
from snownlp import SnowNLP
taidu=[]
taidutime=[]
for i in range(300,len(DATAS)):
ss=SnowNLP(DATAS.评论内容[i])
taidu.append(ss.sentiments)
taidutime.append(DATAS.评论时间[i])
plt.figure(figsize=[40,12])
plt.plot(taidutime,taidu,'*')

如果以0.5作为分界点,统计一下图中点的个数,具体数好评的多还是差评的多,我想数据已经说明了一切。
三、用jieba进行分析,做词频统计
通过词频统计,想知道评论中出现次数最多的词有哪些,是褒义词还是贬义词
import re
import jieba #分词包
import pandas as pd
import numpy #numpy计算包
#提取评论内容
comments = ' '
for k in range(len(DATAS)):
comments = comments + (str(DATAS.评论内容[k])).strip()
#进行正则化处理,去除标点符号等
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filterdata = re.findall(pattern,comments)
cleaned_comments = ''.join(filterdata)
#分词
segment = jieba.lcut(cleaned_comments)
words_df=pd.DataFrame({'segment':segment})
#去除停用词
stopwords=pd.read_csv("C:/Users/lenovo/Desktop/chineseStopWords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='gb18030')#quoting=3全不引用
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
#统计词出现的次数
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
words_stat
分词后得到的结果如下:
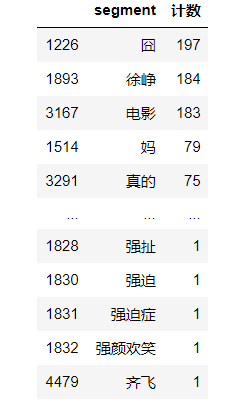
得到这个词频统计后,可以进行词云制作,这部分就不打算做了,网上很多教程,随便找一个贴上来就可以画了,这里就不想画了。
这个项目的目的是针对网络爬虫练习,至此项目基本完成了。