一文看懂 DDD(领域驱动设计)、CQRS和Event Souring与分层架构
我最近开始学习领域驱动设计,CQRS和事件溯源。 到目前为止,我主要参与了使用“经典”N层/层架构和关系数据库的项目。 随着项目变得越来越复杂,我注意到这个模型并不总是很好。 不久之前,我写了一篇关于N层神话的文章,它已经暴露了我觉得这种类型的架构所带来的一些问题。 我尝试的第一件事是在这样的架构中应用域驱动设计。
Domain driven design
那么,实际上领域驱动设计是什么? 在领域驱动设计中,语言是最重要的因素。 我们希望的是在代码中明确表达出领域业务。 从本质上讲,作为开发人员,是希望使用与业务相同的语言。
领域驱动设计可以非常简单或非常复杂。 以下是我能想到的最简单的例子:
var acc = new Account();
var acc2 = new Account();
acc.Balance+=10;acc2.Balance-=10;
//贫血模型
public class Account {
public decimal Balance
{
get;
set;
}
}
在这里,业务逻辑存在于我们的帐户类之外。 没有转移的概念,它只是简单地添加和减去。 这更像是一种程序编码风格,你只是在操纵数据。 下一个片段显示了一种非常简单的使用语言形式来使行为显式化(注意到setter现在是私有的):
var acc = new Account();
var acc2 = new Account();
acc.TransferMoneyTo(acc2,10);
//充血模型
public class Account {
public decimal Balance
{
get;
private set ;
}
public void TransferMoneyTo(Account other, decimal amount) {
Balance += amount;
other.Balance -= amount;
}
}
现在,显然域驱动设计还有更多,但实质上是关注语言并使隐晦的业务明确的表达出来。(原句: but the essence is the focus on language and making the implicit explicit.)
DDD应用于经典的N层架构的问题
在将DDD应用于经典的N层架构时,我遇到了一些问题,而我得出了在这样的架构中几乎不可能使用DDD的结论。
1.我感觉真正的DDD的第一个不可能的原因是,因为所有描述领域的语言都会因为处理数据持久化问题而被搞得十分混乱。当然,我们有ORM框架,比如Entity Framework和NHibernate,但是你仍然需要大量的映射和基础代码,这些会导致无法专注于领域建模。 ORM也不总是允许你将域模型映射到数据库模型(作为示例,我在Stack Overflow上看到这个问题:如何映射具有对实体的引用的值类型?。
因此,你需要在域模型中引入更改以适应数据库。这是一种有问题的抽象,在我看来更糟糕的是没有抽象。
拥有单一数据库模型不仅会强制你将领域模型映射到数据库模型,还会强制你将领域模型映射到视图。完成所有这种映射所需的代码会快速混淆你的域语言。
2.其次,由于我们正在处理关系数据库,我们倾向于自下而上设计。当我们考虑我们的领域模型时,我们会考虑数据模型(即:一对多,多对多)。我们知道约束,因此当我们建模时,我们会在不知不觉中用这些约束进行建模。虽然数据模型可以为你提供有关领域的一些有用的信息,但我觉得行为模型更有价值。
3.它使我们的设计更复杂的第三个原因是我们认为我们需要强一致性。这似乎是一个重要的问题,但我认为我们对强一致性给予了太多的重视。我们欺骗自己认为如果我们有一个单一的数据来源(数据库),我们总是能满足强一致性。实际情况是,我们其实已经处于最终一致的状态。想想一个简单的用例:用户编辑产品描述。在从数据库读取产品和保存新值的用户之间的时间内,已经有人可以更改该产品或甚至删除它的窗口。我们忽略了这些情况,因为它们很少见。我们认为强一致性是一个优先事项但是忽略它出错的情况,这不奇怪吗?也许它其实不是那么重要。
鉴于这些问题,我注意到越来越多的领域驱动设计无法通过经典的分层架构实现。即使使用诸如存储库repository,工作单元等众所周知的模式,我们也几乎总是使用超长的service层和贫血域模型(模型里是大量的getter和setter,没有业务方法)或是处理了太多事情的领域模型(想想你的实体内的数据访问代码)。
有更好的解决办法吗?
鉴于这些问题,我想知道是否有更好的方法,所以我开始研究CQRS和事件溯源。 我还处于学习过程的早期阶段,乍一看它看起来很复杂。 原因在于它与传统方法有很大的不同。 我想在这篇博文中完成的是描述这些方法,概述这样的架构是什么样的,并展示它所呈现的机会。
CQRS
CQRS代表“Command Query Responsibility Segregation”,也就是我们常说的读写隔离,这意味着你应该将读写分成应用程序的两个不同部分。
在分层体系结构中,我们的领域以一组(通常以数据为中心)类表示。 最重要的是,有一层服务将这些对象持久存储到数据库中并检索它们(通常通过repository和工作模式单元)。 一般来说,读和写的处理方式相同。 对象通过相同的层并在前往视图和向下到数据库的过程中进行转换。
下图显示了读取或写入时发生的 分层架构情况 示例:

所有对象都经过相同的层,在我们写和读时经历所有相同的 转换。 当我们写时,我们将从视图模型映射到领域实体,然后ORM将实体映射到数据库表。 在读时,我们做了相反的转变。 这是一种 数据驱动的 方法。 所有这些映射真的有必要吗?
使用CQRS,我们基本上以非常不同的方式对待读和写。
下图显示了 CQRS模型中的读取和写入侧的示例:

写的过程如下:
- 视图构造一个命令并将其传递给命令处理handler程序。
- 然后,命令处理程序将该命令应用于领域类。
- 领域类发送一个发生的事件
- 事件处理程序捕获这些事件并保存这些更改。
- 读取方面非常简单:每个视图都有一个专用的“源”(这可以是一个简单的表或视图)。
起初,这整个想法对我来说似乎很奇怪,我看到了一些问题:
- 我们是在写入方面引入更多层吗?
是的,但这些是非常轻量的层。 命令处理程序唯一做的就是接受命令并找到正确的实体(或者如果我们用DDD的术语叫做aggregate聚合)以应用命令。
事件处理程序仅负责将更改应用于数据库。 - 如何将逻辑应用于视图获取的数据?
这个概念背后的想法是领域层准备数据。 当事件处理程序收到数据中的更改时,它可以以不同的方式处理它。 一种方法是只保存数据库中的值。 但是,它还可以决定将相同数据的视图优化形式保存到辅助存储。 这样,当视图获得它时,它已经被处理。
在我意识到这些问题实际上并不难以克服之后,我看到了这个系统提供的优势:
- 命令处理程序消除了我们通常会在服务中放入的许多逻辑,并将其放回到它所属的领域模型中。
- 事件处理程序将所有持久性逻辑从域模型中删除。
- 因此,领域模型专注于一件事:领域本身的逻辑。
- 读取方可以更加高效,因为它可以直接进入数据库(使用优化的数据访问代码)并获得预处理数据。这是一个很大的好处,因为读比写多一个数量级(考虑你发送的推文数量与你阅读的数量相比)。
- 如果要将应用程序分成不同的tiers (而不是 layers),则可以单独扩展读取和写入侧。这是一个巨大的好处,因为通常你需要扩展,在其中一方变慢的时候(通常是读取方)。
- 除了将读写侧分成不同的层之外,还可以更容易地分离水平层。发送的命令和事件只是POCO,它们可以通过线路轻松序列化。
- 由于命令和事件很容易序列化,因此你也可以将它们存储起来。这为你提供了许多可能性,例如日志记录和审计。事件溯源也基于此功能。
POCO(Plain Old C#/CLR Object),意为:纯老式的 C#/CLR 对象,也可以称为简单的 C#/CLR 对象,POCO 的概念来自于 POJO(Plain Old Java Object),POJO 的内在含义是指那些没有从任何类继承、也没有实现任何接口,更没有被其它框架侵入的 C# 对象
Event sourcing
那么,什么是事件溯源?事件溯源是范式的另一个转变,一开始就让我感到震惊。使用常规数据库时,我们通常会在数据库中创建一条记录,然后对同一条记录执行一些更新,读取几次,直到最终被删除。基本上我们总是保存数据的最新快照。如果你退后一步,你会发现我们实际上一直在删除数据。无论何时在数据库中执行删除或更新,都将删除数据。想一想,你真的想删除数据吗?你怎么知道在几个月的时间内这些数据不重要?
有一些方法可以防止删除数据(例如进行逻辑删除),但所有这些方法都集中在实际的删除上。更新也是删除。此外,逻辑删除仍然只保留数据库中的最后一个可用快照。坦率地说,我已经看到这种技术被大量使用了。我几乎没有看到从这样的记录恢复,因为它可能不是你想要的快照。
如果我们保存所有快照,即我们的数据所处的每个状态,该怎么办?
更好的方法是保存每个版本之间的增量。当我们使用事件并查看为某个实体提交的所有事件时,我们能否以任何状态重现我们的实体?当然,我们可以,这正是溯源的所在。因此,我们的系统现在只进行插入,而不是插入数据,更新和删除数据。听起来不是那么容易吗?让我再说一遍,我们现在只做插入!!
让我们看一个事件日志以及如何转换为对象状态的示例。
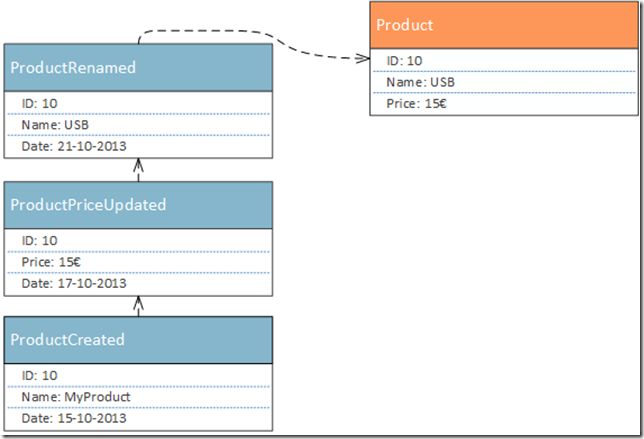
在此图中,你可以看到我们有三个事件:ProductCreated,ProductPriceUpdated 和 ProductRenamed。如果我们不是保存由这些事件产生的产品,而是自己存储事件,我们可以在任何给定时间 重新创建 产品,只需向上移动堆栈并应用每个 转换。这是事件溯源背后的基本概念。
虽然这看起来非常低效,但这意味着我们现在可以在历史的任何给定点获得实体的状态。不删除任何数据会打开非常有趣的场景。我们来看一个例子吧。
假设你的公司销售家具并且你拥有客户数据库。市场营销经常要求我们向去年改变地址的每个人发送促销活动,因为他们可能会购买新家具。
在典型的体系结构中,要解决此需求,可以在数据库中添加一个字段(“lastAddressModification”),向客户添加相同的字段,并在必要时修改持久性机制。在服务层中,添加一个检查以查看地址是否已更改,如果是,则更新该字段。一切都很好,从现在开始,每当有人改变他们的地址,他们都会得到晋升。从现在开始!为了让这个工作,你需要做些什么?你必须修改数据库,更改持久性机制(映射或SQL查询),修改域对象和服务层。
考虑通过事件溯源实现这一点。由于你拥有所有事件,因此你只需要执行以下操作:当你向上查看事件堆栈时,可以检查上个月是否发生了涉及地址更改的事件。一旦你实现此功能,它将开始工作,它将开始追溯性地执行此功能之前发生的事件。
这种方法对于我们认为不可能的各种功能非常有用。我经常听到的答案是,没有必要这样做,而且业务部门也没有要求这样做。我认为原因是我们习惯于告诉他们不要求这样,因为我们认为这是不可能的。
性能
正如我所说,这似乎非常低效。当某个实体有很多事件时,可能需要一段时间才能完成堆栈。需要考虑的一件事是,只有在收到命令时才需要这样做。在所有其他情况下,数据将以非规范化形式提供,并针对读取进行了优化(快照)。但是,如果你碰巧有数百个事件(这不太可能),它仍然可能很慢。解决这个问题的方法将我们带回到我们开始的地方,尽管区别不大。我们可以存储快照。
现在我们不是从下往上移动堆栈,而是从顶部开始直到找到快照。然后我们应用该快照之后发生的所有事件以进入当前状态。如果你需要访问其他历史数据(例如在前面的示例中),你仍然可以执行自下而上的方法。
这个解决方案有效,但如果可能,我认为应该避免。原因是你正在创建对快照的依赖关系。如果你没有快照,则你的域模型可以根据需要变化。只要你仍然知道如何将过去的事件应用于它,你就可以修改你想要的任何内容。如果使用快照,则会对该快照创建依赖关系,并且在修改域模型时必须将其考虑在内。一个可能的解决方案是在域更改时重新计算快照,但这又会增加开销,这是应该尽可能避免的情况。
结论
领域驱动设计,CQRS和事件溯源是非常有趣和强大的技术。对于复杂的问题,它们是从不同的角度处理它们,以便它们成为简单的问题。
我会在任何应用程序中使用它吗? 不,我认为领域需要足够复杂才能从中获益。 话虽如此,我认为自己没有足够的经验来推荐它在哪一点上变得有益。 我想时间会证明这一点。
我希望在这篇文章中我能够给你一些关于DDD,CQRS和事件溯源的概述。
Note: 注意:鉴于这些主题对我来说相对较新,为什么我会写一篇关于它的博客文章?
第一个原因是我想分享到目前为止我学到的东西,这有助于我更好地理解事物。 其次,在寻找信息时,花了我一段时间才能了解全局,我想我现在已经明白了,所以我想把它写下来和那些和我一样处于同样情况的人。
最后但并非最不重要的是,对于该领域的专家来说,这是一个开放性的问题,看看我是否做出了任何不正确的结论。 所以任何评论,批评和建议都会受到欢迎。
原文翻译自:Introduction to Domain Driven Design, CQRS and Event Sourcing