爬虫新手实战——爬去男人团图片加神秘代码归类到指定目录
爬取单个演员页面加粗样式**
注:涉及到网址部分全部改成了神秘网址
headers={‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36’}
html=requests.get(‘神秘网址’,headers=headers)
soup=BeautifulSoup(html.content,‘lxml’)
soup_text=soup.find(‘div’,class_=‘zp_list’).find_all(‘a’)
actor=soup.find(‘div’,class_=‘infosay fr pos-r’).find(‘h1’) #演员名字标签
actor_name=actor.text
cur=datetime.datetime.now() #获取时间
year=cur.year
month=cur.month
day=cur.day
downloadtime=str(cur.year)+‘0’+str(cur.month)+‘0’+str(cur.day)
print(downloadtime)
path=‘E:\人间辞话\’+actor_name+downloadtime #文件夹路径
isExists = os.path.exists(path)
判断结果
if not isExists:
# 如果不存在则创建目录
os.makedirs(path)
imagesource = []
for links in soup_text:
a=‘神秘网址’+links.get(‘href’)
imagesource.append(a)
print(imagesource)
count=0
#在每个图片页面中下载图片
for i in imagesource:
time.sleep(random.random())
os.chdir(path)
html = requests.get(i)
soup = BeautifulSoup(html.content, ‘lxml’)
soup_fanhao = soup.find(‘div’, class_=‘artCon’).find(‘p’,text=re.compile(’.番号.’)) #获取番号标签
soup_date = soup.find(‘div’, class_=‘artCon’).find(‘p’, text=re.compile(’.日期.’)) #获取日期标签
soup_img = soup.find(‘div’, class_=‘artCon’).find(‘img’) #获取图片标签
soup_imgaddress=‘神秘网址’+soup_img.get(‘data-echo’) #获取图片地址
print(soup_fanhao.text,soup_date.text,soup_imgaddress)
data = requests.get( soup_imgaddress, headers=headers).content # 获取图片的二进制格式
print(path+’\’+soup_fanhao.text+’.jpg’)
with open(path+’\’+soup_fanhao.text+’.jpg’, ‘wb’) as f:
f.write(data)
count+=1
print("【正在下载】 %s 共%d 张" % (soup_fanhao.text,count))
with open(path+’\’+‘readme.txt’, ‘a’) as f:
f.write("【正在下载】 %s 共%d 张" % (soup_fanhao.text,count)+downloadtime+’\n’)
按页面爬取番号和图片
import os
from bs4 import BeautifulSoup
import requests
import re
import time
import random
import datetime
htmlpool=[] #构建演员页面url池
urlpool = [] # 构建url地址汇总池
for i in range(0,58):
html=‘神秘代码’+str(i)+’.html’
htmlpool.append(html)
print(htmlpool)
#按演员名字排序抓取番号信息
for linksfull in htmlpool:
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36’}
response = requests.get(linksfull, headers=headers)
soup = BeautifulSoup(response.content, ‘lxml’)
soup_text = soup.find(‘div’, class_=‘avps_ny’).find_all(‘a’)
for links in soup_text:
fulllink = ‘神秘网址’ + links.get(‘href’)
urlpool.append(fulllink)
for url in urlpool:
headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36’}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.content, ‘lxml’)
soup_text = soup.find(‘div’, class_=‘zp_list’).find_all(‘a’)
actor = soup.find(‘div’, class_=‘infosay fr pos-r’).find(‘h1’) # 演员名字标签
actor_name = actor.text
cur = datetime.datetime.now() # 获取时间
year = cur.year
month = cur.month
day = cur.day
downloadtime = str(cur.year) + ‘0’ + str(cur.month) + ‘0’ + str(cur.day)
print(downloadtime)
path = ‘E:\人间辞话\’ + actor_name + downloadtime # 文件夹路径
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
os.makedirs(path)
imagesource = []
for links in soup_text:
a = '神秘网址' + links.get('href')
imagesource.append(a)
print(imagesource)
count = 0
# 在每个图片页面中下载图片
for i in imagesource:
time.sleep(random.random())
os.chdir(path)
html = requests.get(i)
soup = BeautifulSoup(html.content, 'lxml')
#测试发现有极小部分番号网址是个空页面,是网站自身问题。所以做个判断跳过
if(soup.find('div', class_='artCon')!=None):
soup_fanhao = soup.find('div', class_='artCon').find('p', text=re.compile('.*番号.*')) # 获取番号标签
soup_date = soup.find('div', class_='artCon').find('p', text=re.compile('.*日期.*')) # 获取日期标签
soup_img = soup.find('div', class_='artCon').find('img') # 获取图片标签
soup_imgaddress = '神秘网址' + soup_img.get('data-echo') # 获取图片地址
print(soup_fanhao.text, soup_date.text, soup_imgaddress)
data = requests.get(soup_imgaddress, headers=headers).content # 获取图片的二进制格式
print(path + '\\' + soup_fanhao.text + '.jpg')
year = soup_date.text[-10:-6]
month = soup_date.text[-5:-3]
day = soup_date.text[-2:]
datanum = year + month + day
with open(path + '\\' + datanum + soup_fanhao.text + '.jpg', 'wb') as f:
f.write(data)
count += 1
print("【正在下载】 %s 共%d 张" % (soup_fanhao.text, count))
with open(path + '\\' + 'readme.txt', 'a') as f:
f.write("【正在下载】 %s %s 共%d 张" % (soup_fanhao.text, soup_date.text, count) + downloadtime + '\n')
运行结果:
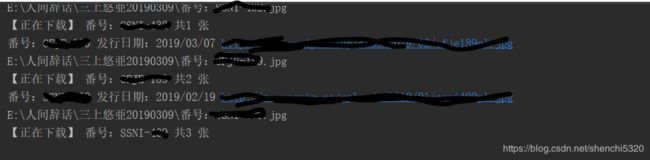
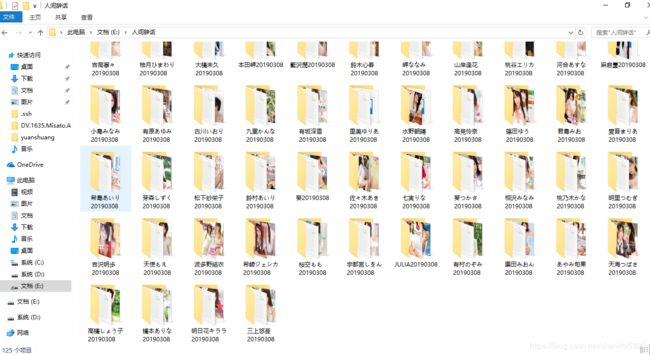
github源码:https://github.com/DemonsYuan/nanrenvip_fanhaoDownload
[email protected]:DemonsYuan/nanrenvip_fanhaoDownload.git