chapter5 Support Vector Machines (支持向量机)
支持向量机(SVM)是个非常强大并且有多种功能的机器学习模型,能够做线性或者非线性的分类,回归,甚至异常值检测。机器学习领域中最为流行的模型之一,是任何学习机器学习的人必备的工具。SVM 特别适合应用于复杂但中小规模数据集的分类问题。
本章节将阐述支持向量机的核心概念,怎么使用这个强大的模型,以及它是如何工作的。
设置
from __future__ import division,print_function,unicode_literals
import numpy as np
np.random.seed(42)
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import os
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "svm"
def save_fig(figure_id,tight_layout = True):
path = os.path.join(PROJECT_ROOT_DIR,"images",CHAPTER_ID,figure_id + ".png")
print("Saving_figure",fig_id)
if tight_out:
plt.tight_layout()
plt.savefig(path,format = 'png',dpi = 300)
import warnings
warnings.filterwarnings(action = "ignore",module = "scipy",message = "^interal gelsd")线性支持向量机分类
最大间隔分类
SVM 的基本思想能够用一些图片来解释得很好,下图展示了我们在第4章结尾处介绍的鸢尾花数据集的一部分。这两个种类能够被非常清晰,非常容易的用一条直线分开(即线性可分的)。左边的图显示了三种可能的线性分类器的判定边界。其中用虚线表示的线性模型判定边界很差,甚至不能正确地划分类别。另外两个线性模型在这个数据集表现的很好,但是它们的判定边界很靠近样本点,在新的数据上可能不会表现的很好。相比之下,右边图中 SVM 分类器的判定边界实线,不仅分开了两种类别,而且还尽可能地远离了最靠近的训练数据点。你可以认为 SVM 分类器在两种类别之间保持了一条尽可能宽敞的街道(图中平行的虚线),其被称为最大间隔分类。

我们注意到添加更多的样本点在“街道”外并不会影响到判定边界,因为判定边界是由位于“街道”边缘的样本点确定的,这些样本点被称为“支持向量”(上图中被圆圈圈起来的点)。
from sklearn.svm import SVC
from sklearn import datasets
iris = datasets.load_iris()
X = iris["data"][:,(2,3)]
y = iris["target"]
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
svm_clf = SVC(kernel = "linear",C = float("inf"))
svm_clf.fit(X,y)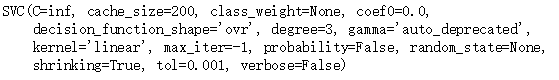
x0 = np.linspace(0, 5.5, 200)
pred_1 = 5*x0 - 20
pred_2 = x0 - 1.8
pred_3 = 0.1 * x0 + 0.5
def plot_svc_decision_boundary(svm_clf, xmin, xmax):
w = svm_clf.coef_[0]
b = svm_clf.intercept_[0]
x0 = np.linspace(xmin, xmax, 200)
decision_boundary = -w[0]/w[1] * x0 - b/w[1]
margin = 1/w[1]
gutter_up = decision_boundary + margin
gutter_down = decision_boundary - margin
svs = svm_clf.support_vectors_
plt.scatter(svs[:, 0], svs[:, 1], s=180, facecolors='#FFAAAA')
plt.plot(x0, decision_boundary, "k-", linewidth=2)
plt.plot(x0, gutter_up, "k--", linewidth=2)
plt.plot(x0, gutter_down, "k--", linewidth=2)
plt.figure(figsize=(12,2.7))
plt.subplot(121)
plt.plot(x0, pred_1, "g--", linewidth=2)
plt.plot(x0, pred_2, "m-", linewidth=2)
plt.plot(x0, pred_3, "r-", linewidth=2)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="upper left", fontsize=14)
plt.axis([0, 5.5, 0, 2])
plt.subplot(122)
plot_svc_decision_boundary(svm_clf, 0, 5.5)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.xlabel("Petal length", fontsize=14)
plt.axis([0, 5.5, 0, 2])
save_fig("large_margin_classification_plot")
plt.show() 
特征缩放的敏感度
警告
SVM 对特征缩放比较敏感,从下图可以看到:左边的图中,垂直的比例要更大于水平的比例,所以最宽的“街道”接近水平。但对特征缩放后(例如使用Scikit-Learn的StandardScaler),判定边界看起来要好得多,如右图。

Xs = np.array([1,50],[5,20],[3,80],[5,60]).astype(np.float64)
ys = np.array([0,0,1,1])
svm_clf = SVC(kernel = "linear",C = 100)
svm_clf.fit(Xs,ys)
plt.figure(figsize=(12,3.2))
plt.subplot(121)
plt.plot(Xs[:, 0][ys==1], Xs[:, 1][ys==1], "bo")
plt.plot(Xs[:, 0][ys==0], Xs[:, 1][ys==0], "ms")
plot_svc_decision_boundary(svm_clf, 0, 6)
plt.xlabel("$x_0$", fontsize=20)
plt.ylabel("$x_1$", fontsize=20,rotation = 0)
plt.title("Unscaled", fontsize=16)
plt.axis([0, 6, 0, 90])
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(Xs)
svm_clf.fit(X_scaled,ys)
plt.subplot(122)
plt.plot(Xs[:, 0][ys==1], Xs[:, 1][ys==1], "bo")
plt.plot(Xs[:, 0][ys==0], Xs[:, 1][ys==0], "ms")
plt.xlabel("$x_0$", fontsize=20)
plt.title("Scaled", fontsize=16)
plt.axis([-2, 2, -2, 2])
save_fig("sensitivity_to_feature_scales_plot")
软间隔分类(对异常值敏感)
如果我们严格地规定所有的数据都不在“街道”上,都在正确的两边,称为硬间隔分类,硬间隔分类有两个问题,第一,只对线性可分的数据起作用,第二,对异常点敏感。下图显示了只有一个异常点的鸢尾花数据集:左边的图中很难找到硬间隔,右边的图中判定边界和我们之前在图中没有异常点的判定边界非常不一样,它很难一般化。

对异常值的硬间隔敏感性
X_outliers = np.array([3.4,1.3],[3.2,0.8])
y_outliers = np.array([0,0])
Xo1 = np.concatanate([X,X_outliers[:1]],axis = 0)
yo1 = np.concatanate([y,y_outliers[:1]],axis = 0)
Xo2 = np.concatanate([X,X_outliers[1:]],axis = 0)
yo2 = np.concatanate([y,y_outliers[1:]],axis = 0)
svm_clf2 = SVC(kernel = "linear",C = 10 ** 9)
svm_clf2.fit(Xo2,yo2)
plt.figure(figsize = (12,2.7))
plt.subplot(121)
plt.plot(Xo1[:,0][yo1 == 1],Xo1[:,1][yo1 == 1], "bs")
plt.plot(Xo1[:,0][yo1 == 0],Xo1[:,1][yo1 == 0], "yo")
plt.text(0.3,1.0,"Impossible!",fontsize = 24,color = "red")
plt.xlabel("Petal length",fontsize = 14)
plt.ylabel("Pental width",fontsize = 14)
plt.annotate("Outlier",
xy = (X_outliers[0][0],X_outliers[0][1]),
xytext = (2.5,1.7),
ha = "center",
arrowprops = dict(facecolor = 'black',shrink = 0.1),
fontsize = 16,)
plt.axis([0,5.5,0,2])
plt.subplot(122)
plt.plot(Xo2[:,0][yo2 == 1],Xo2[:,1][yo2 == 1], "bs")
plt.plot(Xo2[:,0][yo2 == 0],Xo2[:,1][yo2 == 0], "yo")
plot_svc_decision_boundary(svm_clf2,0,5.5)
plt.xlabel("Petal length",fontsize = 14)
plt.annotate("Outlier",
xy = (X_outliers[1][0],X_outliers[1][1]),
xytext = (3.2,0.08),
ha = "center",
arrowprops = dict(facecolor = 'black',shrink = 0.1),
fontsize = 16,)
plt.axis([0,5.5,0,2])
save_fig("sensitivity_to_outliers_polt")
plt.show()
大的间隔 vs 间隔违规
为了避免上述的问题,我们更倾向于使用更加软性的模型。目的在保持“街道”尽可能大和避免间隔违规(例如:数据点出现在“街道”中央或者甚至在错误的一边)之间找到一个良好的平衡。这就是软间隔分类。
在 Scikit-Learn 库的 SVM 类,可以用C超参数(惩罚系数)来控制这种平衡:较小的C会导致更宽的“街道”,但更多的间隔违规。下图显示了在非线性可分隔的数据集上,两个软间隔SVM分类器的判定边界。左边图中,使用了较大的C值,导致更少的间隔违规,但是间隔较小。右边的图,使用了较小的C值,间隔变大了,但是许多数据点出现在了“街道”上。然而,第二个分类器似乎泛化地更好:事实上,在这个训练数据集上减少了预测错误,因为实际上大部分的间隔违规点出现在了判定边界正确的一侧。
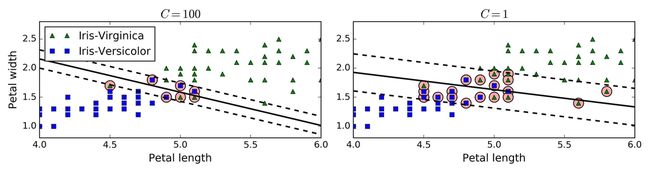
提示
如果你的 SVM 模型过拟合,你可以尝试通过减小超参数C去调整。
以下的 Scikit-Learn 代码加载了内置的鸢尾花(Iris)数据集,缩放特征,并训练一个线性 SVM 模型(使用LinearSVC类,超参数C=1,hinge 损失函数)来检测 Virginica 鸢尾花。
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:,(2,3)]
y = (iris["target"] == 2).astype(np.float64)
svm_clf = Pipeline([
("scaler",StandardScaler()),
("linear_svc",LinearSVC(C = 1,loss = "hinge",random_state = 42)),])
svm_clf.fit(X,y)

svm_clf.predict([5.5, 1.7])
![]()
笔记
不同于 Logistic 回归分类器,SVM 分类器不会输出每个类别的概率。
作为一种选择,可以在 SVC 类,使用SVC(kernel="linear", C=1),但是它比较慢,尤其在较大的训练集上,所以一般不被推荐。另一个选择是使用SGDClassifier类,即SGDClassifier(loss="hinge", alpha=1/(m*C))。它应用了随机梯度下降(SGD 见第四章)来训练一个线性 SVM 分类器。尽管它不会和LinearSVC一样快速收敛,但是对于处理那些不适合放在内存的大数据集是非常有用的,或者处理在线分类任务同样有用。
提示
LinearSVC要使偏置项规范化,首先应该集中训练集减去它的平均数。如果使用了StandardScaler,那么它会自动处理。此外,确保设置loss参数为hinge,因为它不是默认值。最后,为了得到更好的效果,你需要将dual参数设置为False,除非特征数比样本量多(我们将在本章后面讨论二元性)。
不同正则化设置生成的图
scaler = StandardScaler()
svm_clf1 = LinearSVC(C = 1,loss = "hinge",random = 42)
svm_clf2 = LinearSVC(C = 100,loss = "hinge",random = 42)
scaled_svm_clf1 = Pipeline([
("scaler",scaler),
("linear_svc",svm_clf1),])
scaled_svm_clf2 = Pipeline([
("scaler",scaler),
("linear_svc",svm_clf2),])
scaled_svm_clf1.fit(X,y)
scaled_svm_clf2.fit(X,y)
b1 = svm_clf1.decision_function([-scaler.mean_ / scaler.scale_])
w1 = svm_clf1.coef_[0] / scaler.scale_
svm_clf1.intercept_ = np.array([b1])
svm_clf1.coef_ = np.array([w1])
b2 = svm_clf2.decision_function([-scaler.mean_ / scaler.scale_])
w2 = svm_clf2.coef_[0] / scaler.scale_
svm_clf2.intercept_ = np.array([b2])
svm_clf2.coef_ = np.array([w2])
t = y * 2 - 1
support_vectors_idx1 = (t * (X.dot(w1) + b1) < 1).ravel()
svm_clf1.support_vectors_ = X[support_vectors_idx1]
support_vectors_idx2 = (t * (X.dot(w2) + b2) < 1).ravel()
svm_clf2.support_vectors_ = X[support_vectors_idx2]
plt.figure(figsize = (12,3.2))
plt.subplot(121)
plt.plot(X[:,0][y == 1],X[:,1][y == 1], "g^",label = "Iris-Virginica")
plt.plot(X[:,0][y == 0],X[:,1][y == 0], "bs",label = "Iris-Versicolor")
plot_svc_decision_boundary(svm_clf1,4,6)
plt.xlabel("Petal length",fontsize = 14)
plt.ylabel("Pental width",fontsize = 14)
plt.legend(loc = "upper left",fontsize = 14)
plt.title = ("$C = {}$".format(svm_clf1.C),fontsize = 16)
plt.axis([4,6,0.8,2.8])
plt.subplot(122)
plt.plot(X[:,0][y == 1],X[:,1][y == 1], "g^")
plt.plot(X[:,0][y == 0],X[:,1][y == 0], "bs")
plot_svc_decision_boundary(svm_clf2,4,6)
plt.xlabel("Petal length",fontsize = 14)
plt.title = ("$C = {}$".format(svm_clf2.C),fontsize = 16)
plt.axis([4,6,0.8,2.8])
save_fig("regularization_polt")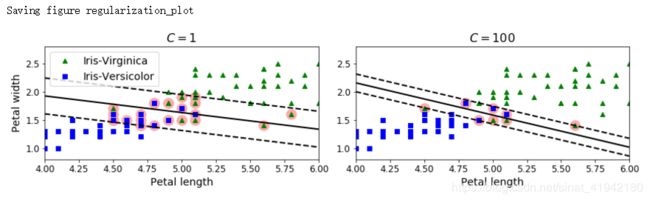
非线性SVM分类
尽管线性 SVM 分类器在许多案例上表现得出乎意料的好,但是很多数据集并不是线性可分的。一种处理非线性数据集方法是增加更多的特征,例如多项式特征(正如在第4章所做的那样);在某些情况下可以变成线性可分的数据。
增加特征使数据集线性可分
X1D = np.linspace(-4,4,9).reshape(-1,1)
X2D = np.c_[X1D,X1D ** 2]
y = np.array([0,0,1,1,1,1,1,0,0])
plt.figure(figsize = (11,4))
plt.subplot(121)
plt.grid(True,which = 'both')
plt.axhline(y = 0,color = 'k')
plt.plot(X1D[:,0][y == 0],np.zeros(4),"bs")
plt.plot(X1D[:,0][y == 1],np.zeros(5),"g^")
plt.gca().get_yaxis().set_ticks([])
plt.xlabel(r"$x_1$",fontsize = 20)
plt.axis([-4.5,4.5,-0.2,0.2])
plt.subplot(122)
plt.grid(True,which = 'both')
plt.axhline(y = 0,color = 'k')
plt.axvline(x = 0,color = 'k')
plt.plot(X2D[:,0][y == 0],X2D[:,1][y == 0],"bs")
plt.plot(X2D[:,0][y == 1],X2D[:,1][y == 1],"g^")
plt.gca().get_yaxis().set_ticks([0,4,8,12,16])
plt.xlabel(r"$x_1$",fontsize = 20)
plt.ylabel(r"$x_2$",fontsize = 20,rotation = 0)
plt.plot([-4.5,4.5],[6.5,6.5],"r--",lonewidth = 3)
plt.axis([-4.5,4.5,-1,17])
plt.subplots_adjust(right = 1)
save_fig("higher_dimensions_plot",tight_layout = False)
plt.show()

上图的左图中,它只有一个特征x1的简单的数据集,该数据集不是线性可分的。但是如果增加了第二个特征 x2=(x1)^2,产生的 2D 数据集就能很好的线性可分。
为了实施这个想法,通过 Scikit-Learn,创建一个管道(Pipeline)去包含多项式特征(PolynomialFeatures)变换,然后一个StandardScaler和LinearSVC。在卫星数据集(moons datasets)测试一下效果。
from sklearn.datasets import make_moons
X,y = make_moons(n_samples = 100,noise = 0.15,random_state = 42)
def plot_dataset(X,y,axes):
plt.plot(X[:,0][y == 0],X[:,1][y == 0],"bs")
plt.plot(X[:,0][y == 1],X[:,1][y == 1],"g^")
plt.axis(axes)
plt.grid(True,which = 'both')
plt.xlabel(r"$x_1$",fontsize = 20)
plt.ylabel(r"$x_2$",fontsize = 20,rotation = 0)
plot_dataset(X,y,[-1.5,2.5,-1,1.5])
plt.show()

使用多项式特征的线性SVM分类器
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.svm import LinearSVC
polynomial_svm_clf = Pipeline([
("poly_features",PolynomialFeatures(degree = 3)),
("scaler",StandardScaler()),
("svm_clf",LinearSVC(C = 10,loss = "hinge",random_state = 42)),])
polynomial_svm_clf.fit(X,y)

def plot_predictions(clf,axes):
x0s = np.linspace(axes[0],axes[1],100)
x1s = np.linspace(axes[2],axes[3],100)
x0,x1 = np.meshgrid(x0s,x1s)
X = np.c_[x0.ravel(),x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
y_decision = clf.decision_function(X).reshape(x0.shape)
plt.contourf(x0,x1,y_pred,cmap = plt.cm.brg,alpha = 0.2)
plt.contourf(x0,x1,y_decision,cmap = plt.cm.brg,alpha = 0.1)
plot_predictions(polynomial_svm_clf,[-1.5,2.5,-1,1.5])
plt_dataset(X,y,[-1.5,2.5,-1,1.5])
save_fig("moons_polynomial_svc_plot")
plt.show()
(1)多项式核
添加多项式特征很容易实现,不仅仅在 SVM,在各种机器学习算法都有不错的表现,但是低次数的多项式不能处理非常复杂的数据集,而高次数的多项式却产生了大量的特征,会使模型变慢。
幸运的是,当使用 SVM 时,可以运用一个被称为“核技巧”(kernel trick)的神奇数学技巧。它可以取得就像添加了许多多项式,甚至有高次数的多项式,一样好的结果。因为实际上并没有增加任何特征,所以不会导致大量特征的组合爆炸。这个技巧可以用 SVC 类来实现。在卫星数据集测试一下效果。
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline([
("scaler",StandardScaler()),
("svm_clf",SVC(kernel = "poly",degree = 3,coef0 = 1,C = 5))])
poly_kernel_svm_clf.fit(X,y)
poly100_kernel_svm_clf = Pipeline([
("scaler",StandardScaler()),
("svm_clf",SVC(kernel = "poly",degree = 10,coef0 = 100,C = 5))])
poly100_kernel_svm_clf.fit(X,y)
plt.figure(figsize = (11,4))
plt.subplot(121)
plot_predictions(poly_kernel_svm_clf,[-1.5,2.5,-1,1.5])
plot_dataset(X,y,[-1.5,2.5,-1,1.5])
plt.title(r"$d = 3,r = 1,C = 5$",fontsize = 18)
plt.subplot(122)
plot_predictions(poly100_kernel_svm_clf,[-1.5,2.5,-1,1.5])
plot_dataset(X,y,[-1.5,2.5,-1,1.5])
plt.title(r"$d = 10,r = 100,C = 5$",fontsize = 18)
save_fig("moons_kernelized_polynomial_svc_plot")
plt.show()

上图中的左图用3阶的多项式核训练了一个 SVM 分类器。右图是使用了10阶的多项式核 SVM 分类器。很明显,如果模型过拟合,可以减小多项式核的阶数。相反的,如果是欠拟合,可以尝试增大它。超参数coef0控制了高阶多项式与低阶多项式对模型的影响。
通用的方法是用网格搜索(grid search 见第 2 章)去找到最优超参数。首先进行非常粗略的网格搜索,这一般会很快,然后在找到的最佳值进行更细的网格搜索。对每个超参数的作用有一个很好的理解可以帮助我们在正确的超参数空间找到合适的值。
(2)增加相似特征
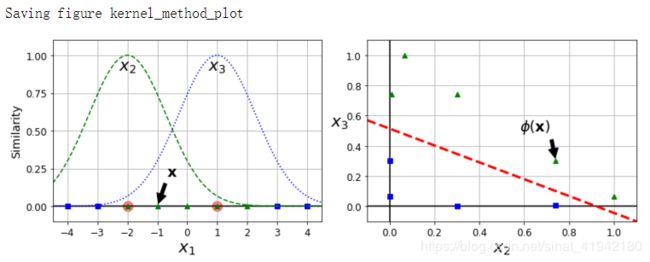
另一种解决非线性问题的方法是使用相似函数(similarity funtion)计算每个样本与特定地标(landmark)的相似度。

例如,看看前面讨论过的一维数据集,并在x1=-2和x1=1之间增加两个地标(上图的左图)。接下来,定义一个相似函数,即高斯径向基函数(Gaussian Radial Basis Function,RBF),设置γ = 0.3(见下面的公式)
公式 高斯RBF

它是一个从 0 到 1 的钟型函数,值为 0 的离地标很远,值为 1 的在地标上。现在我们准备计算新特征。例如,看一下样本x1=-1:它距离第一个地标距离是 1,距离第二个地标是 2。因此它的新特征为x2=exp(-0.3 × (1^2))≈0.74和x3=exp(-0.3 × (2^2))≈0.30。上图右边的图显示了特征转换后的数据集(删除了原始特征),可以看到,它现在是线性可分的。
使用高斯RBF的相似特征
def gaussian_rbf(x,landmark,gamma):
return np.exp(-gamma * np.linalg.norm(x - landmark,axis = 1) ** 2)
gamma = 0.3
x1s = np.linspace(-4.5,4.5,200).reshape(-1,1)
x2s = gaussian_rbf(x1s,-2,gamma)
x3s = gaussian_rbf(x1s,1,gamma)
XK = np.c_[gaussian_rbf(X1D,-2,gamma),gaussian_rbf(X1D,1,gamma)]
yk = np.array([0,0,1,1,1,1,1,0,0])
plt.figure(figsize = (11,4))
plt.subplot(121)
plt.grid(True,which = 'both')
plt.axhline(y = 0,color = 'k')
plt.scatter(x = [-2,1],y = [0,0],s = 150,alpha = 0.5,c = "red")
plt.plot(X1D[:,0][yk == 0],np.zeros(4),"bs")
plt.plot(X1D[:,0][yk == 1],np.zeros(5),"g^")
plt.plot(x1s,x2s,"g--")
plt.plot(x1s,x3s,"b:")
plt.gca().get_yaxis().set_ticks([0,0.25,0.5,0.75,1])
plt.xlabel(r"$x_1$",fontsize = 20)
plt.ylabel(r"$Similarity$",fontsize = 14)
plt.annotate(r'$\mathbf{x}$',
xy = (X1D[3,0],0),
xytext = (-0.5,0.20),
ha = "center",
arrowprops = dict(facecolor = 'black',shrink = 0.1),
fontsize = 18,)
plt.text(-2,0.9,"$x_2$",ha = "center",fontsize = 20)
plt.text(1,0.9,"$x_3$",ha = "center",fontsize = 20)
plt.axis([-4.5,4.5,-0.1,1.1])
plt.subplot(122)
plt.grid(True,which = 'both')
plt.axhline(y = 0,color = 'k')
plt.axvline(x = 0,color = 'k')
plt.plot(XK[:,0][yk == 0],XK[:,1][yk == 0],"bs")
plt.plot(XK[:,0][yk == 1],XK[:,1][yk == 1],"g^")
plt.xlabel(r"$x_2$",fontsize = 20)
plt.ylabel(r"$x_3$",fontsize = 20,rotation = 0)
plt.annotate(r'$\phi\left(\mathbf{x}\right)$',
xy = (XK[3,0],XK[3,1]),
xytext = (0.65,0.50),
ha = "center",
arrowprops = dict(facecolor = 'black',shrink = 0.1),
fontsize = 18,)
plt.plot([-0.1,1.1],[0.57,-0.1],"r--",lonewidth = 3)
plt.axis([-0.1,1.1,-0.1,1.1])
plt.subplots_adjust(right = 1)
save_fig("kernel_method_plot")
plt.show()
x1_example = X1D[3,0]
for landmark in (-2,1):
k = gaussian_rbf(np.array([[x1_example]]),np.array([landmark]),gamma)
print("Phi({},{}) = {}".format(x1_example,landmark,k))
如何选择地标。最简单的方法是在数据集中的每一个样本的位置创建地标。这将产生更多的维度,从而增加了转换后数据集是线性可分的可能性。但缺点是,m个样本,n个特征的训练集被转换成了m个实例,m个特征的训练集(假设你删除了原始特征)。这样一来,如果训练集非常大,最终会得到同样大的特征。
高斯RBF核
就像多项式特征法一样,相似特征法对各种机器学习算法同样也有不错的表现。但是在所有额外特征上的计算成本可能很高,特别是在大规模的训练集上。然而,“核” 技巧再一次显现了它在 SVM 上的神奇之处:高斯核可以获得同样好的结果,就像在相似特征法添加了许多相似特征一样,但事实上,并不需要在RBF添加它们。现在使用SVC类的高斯RBF核来检验一下。
rbf_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
))
rbf_kernel_svm_clf.fit(X, y)

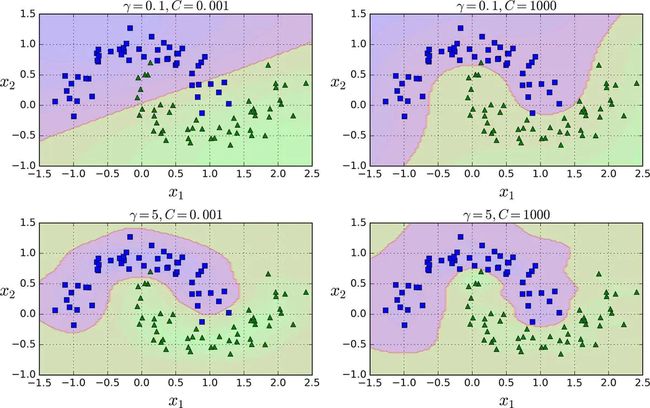
这个模型在上图的左下角表示。其他的图显示了用不同的超参数gamma (γ)和C训练的模型。
使用RBF核的SVM分类器
from sklearn.svm import SVC
gamma1,gamma2 = 0.1,5
C1,C2 = 0.001,1000
hyperparams = (gamma1,C1),(gamma1,C2),(gamma2,C1),(gamma2,C2)
svm_clfs = []
for gamma,C in hyperparams:
rbf_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=gamma, C=C))
))
rbf_kernel_svm_clf.fit(X, y)
svm_clfs.append(rbf_kernel_svm_clf)
plt.figure(figsize = (11,7))
for i,svm_clf in enumerate(svm_clfs):
plt.subplot(221 + i)
plot_predictions(svm_clf,[-1.5,2.5,-1,1.5])
plot_dataset(X,y,[-1.5,2.5,-1,1.5])
gamma,C = hyperparams[i]
plt.title(r"$\gamma = {},C = {}$".format(gamma,C),fontsize = 16)
save_fig("moons_rbf_svc_plot")
plt.show()

从上图可以看出,增大γ使钟型曲线更窄(上图左图),导致每个样本的影响范围变得更小:即判定边界最终变得更不规则,在单个样本周围环绕。相反的,较小的γ值使钟型曲线更宽,样本有更大的影响范围,判定边界最终则更加平滑。所以γ是可调整的超参数:如果模型过拟合,应该减小γ值,若欠拟合,则增大γ(与超参数C相似)。
还有其他的核函数,但很少使用。例如,一些核函数是专门用于特定的数据结构。在对文本文档或者 DNA 序列进行分类时,有时会使用字符串核(String kernels)(例如,使用 SSK 核(string subsequence kernel)或者基于编辑距离(Levenshtein distance)的核函数)。
提示
这么多可供选择的核函数,如何决定使用哪一个?一般来说,应该先尝试线性核函数(记住LinearSVC比SVC(kernel="linear")要快得多),尤其是当训练集很大或者有大量的特征的情况下。如果训练集不太大,也可以尝试高斯RBF核,它在大多数情况下都很有效。如果有空闲的时间和计算能力,还可以使用交叉验证和网格搜索来试验其他的核函数,特别是有专门用于所用训练集数据结构的核函数。
计算复杂度
LinearSVC类基于liblinear库,它实现了线性 SVM 的优化算法。它并不支持核技巧,但是它的样本和特征的数量几乎是线性的:训练时间复杂度大约为O(m × n)。
如果要非常高的精度,这个算法需要花费更多时间。这是由容差值超参数ϵ(在 Scikit-learn 称为tol)控制的。在大多数分类任务中,使用默认容差值就行。
SVC 类基于libsvm库,它实现了支持核技巧的算法。训练时间复杂度通常介于O(m^2 × n)和O(m^3 × n)之间。不幸的是,这意味着当训练样本变大时,它将变得极其慢(例如,成千上万个样本)。这个算法对于复杂但小型或中等数量的数据集表现是完美的。然而,它能对特征数量很好的缩放,尤其对稀疏特征来说(sparse features)(即每个样本都有一些非零特征)。在这个情况下,算法对每个样本的非零特征的平均数量进行大概的缩放。下表是对 Scikit-learn 的 SVM 分类模型进行比较。

SVM回归
正如我们之前提到的,SVM 算法应用广泛:不仅仅支持线性和非线性的分类任务,还支持线性和非线性的回归任务。技巧在于逆转目标:限制间隔违规的情况下,不是试图在两个类别之间找到尽可能大的“街道”(即间隔)。SVM 回归任务是限制间隔违规情况下,尽量放置更多的样本在“街道”上。“街道”的宽度由超参数ϵ控制。
SVM回归
np.random.seed(42)
m = 50
X = 2 * np.random.rand(m,1)
y = (4 + 3 * X + np.random.randn(m,1)).ravel()
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon = 1.5,random_state = 42)
svm_reg.fit(X,y)
svm_reg1 = LinearSVR(epsilon = 1.5,random_state = 42)
svm_reg2 = LinearSVR(epsilon = 0.5,random_state = 42)
svm_reg1.fit(X,y)
svm_reg2.fit(X,y)
def find_support_vectors(svm_reg,X,y):
y_pred = svm_reg.predict(X)
off_margin = (np.abs(y - y_pred) >= svm_reg.epsilon)
return np.argwhere(off_margin)
svm_reg1.support = find_support_vectors(svm_reg1,X,y)
svm_reg2.support = find_support_vectors(svm_reg2,X,y)
eps_x1 = 1
eps_y_pred = svm_reg1.predict([[eps_x1]])
def plot_svm_regression(svm_reg, X,y,axes):
x1s = np.linspace(axes[0],axes[1],100).reshape(100,1)
y_pred = svm_reg.predict(x1s)
plt.plot(x1s,y_pred,"k-",linewidth = 2,label = r"$\hat{y}$")
plt.plot(x1s,y_pred + svm_reg.epsilon,"k--")
plt.plot(x1s,y_pred + svm_reg.epsilon,"k--")
plt.scatter(X[svm_reg.support_], y[svm_reg.support_], s=180, facecolors='#FFAAAA')
plt.plot(X, y, "bo")
plt.xlabel(r"$x_1$",fontsize = 18x0)
plt.legend(loc = "upper left", fontsize = 18)
plt.axis(axes)
plt.figure(figsize=(9,4))
plt.subplot(121)
plot_svm_regression(svm_reg1, X,y,[0,2,3,11])
plt.title(r"$\epsilon = {}$".format(svm_reg1.epsilon),fontsize = 18)
plt.ylabel("$y$", fontsize=18,rotation = 0)
plt.legend(loc="upper left", fontsize=14)
plt.annotate(
'',xy = (eps_x1,eps_y_pred),xycoords = 'data',
xytext = (eps_x1,eps_y_pred - svm_reg1.epsilon),
textcoords = 'data',arrowprops = {'arrowstyle': '<->','linewidth': 1.5})
plt.text(0.91,5.6,r"$\epsilon$",fontsize = 20)
plt.subplot(122)
plot_svm_regression(svm_reg2, X,y,[0,2,3,11])
plt.title(r"$\epsilon = {}$".format(svm_reg2.epsilon),fontsize = 18)
save_fig("svm_regression_plot")
plt.show()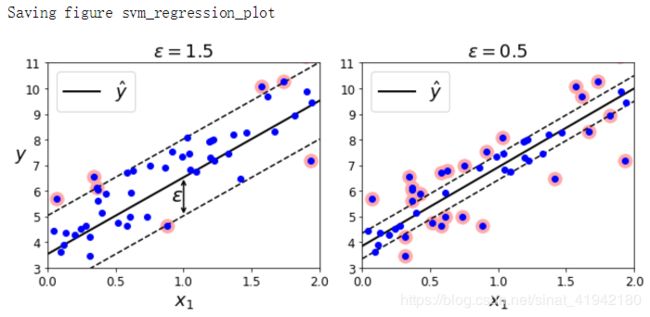
上图显示了在一些随机生成的线性数据上,两个线性 SVM 回归模型的训练情况。一个有较大的间隔(ϵ=1.5),另一个间隔较小(ϵ=0.5)。
添加更多的数据样本在间隔之内并不会影响模型的预测,因此,这个模型认为是ϵ不敏感的(ϵ-insensitive)。
使用二项多项式核的SVM回归
处理非线性回归任务,可以使用核化的 SVM 模型。下面使用了 Scikit-Learn 的SVR类(支持核技巧)。在回归任务上,SVR类和SVC类是一样的,并且LinearSVR是和LinearSVC等价。LinearSVR类和训练集的大小成线性(就像LinearSVC类),当训练集变大,SVR会变的很慢(就像SVC类)。
np.random.seed(42)
m = 100
X = 2 * np.random.rand(m,1)
y = (0.2 + 0.1 * X + 0.5 * X**2 + np.random.randn(m,1) / 10).ravel()
from sklearn.svm import SVR
svm_poly_reg1 = SVR(kernel = "poly",degree = 2,C = 100,epsilon = 0.1)
svm_poly_reg2 = SVR(kernel = "poly",degree = 2,C = 0.01,epsilon = 0.1)
svm_poly_reg1.fit(X,y)
svm_poly_reg2.fit(X,y)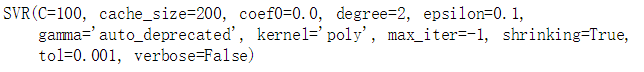
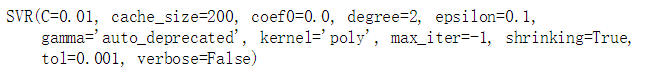
plt.figure(figsize=(9,4))
plt.subplot(121)
plot_svm_regression(svm_poly_reg1, X,y,[-1,1,0,1])
plt.title(r"$degree = {},C = {},\epsilon = {}$".format(svm_poly_reg1.degree,svm_poly_reg1.C,svm_poly_reg1.epsilon),fontsize = 18)
plt.ylabel("$y$", fontsize=18,rotation = 0)
plt.subplot(122)
plot_svm_regression(svm_poly_reg2, X,y,[-1,1,0,1])
plt.title(r"$degree = {},C = {},\epsilon = {}$".format(svm_poly_reg2.degree,svm_poly_reg2.C,svm_poly_reg2.epsilon),fontsize = 18)
save_fig("svm_with_polynomial_kernel_plot")
plt.show()
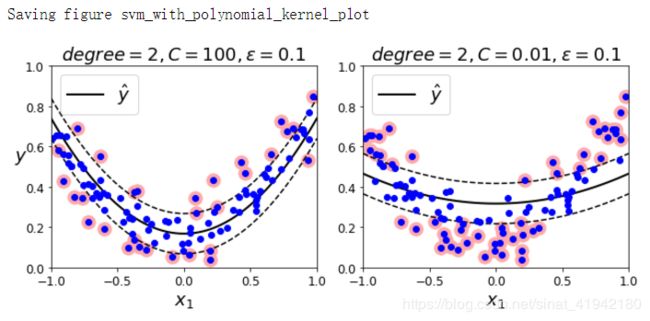
上图显示了随机二次方的训练集,使用二次方多项式核函数的 SVM 回归。左图是较小的正则化(即更大的C值),右图则是更大的正则化(即小的C值)
笔记
SVM 也可以用来做异常值检测,详情见 Scikit-Learn 文档。
背后机制
这个章节从线性 SVM 分类器开始,将解释 SVM 是如何做预测的并且算法是如何工作的。如果是刚接触机器学习,可以跳过这个章节,直接进入本章末尾的练习。等到想深入了解 SVM,再回头研究这部分内容。
首先,关于符号的约定:在第 4 章,将所有模型参数放在一个矢量θ里,包括偏置项θ0,θ1到θn的输入特征权重,和增加一个偏差输入x0 = 1到所有样本。在本章中,将使用一个不同的符号约定,在处理 SVM 上,这更方便,也更常见:偏置项被命名为b,特征权重向量被称为w,在输入特征向量中不再添加偏置特征。
决策函数和预测
线性 SVM 分类器通过简单地计算决策函数![]() 来预测新样本的类别:如果结果是正的,预测类别
来预测新样本的类别:如果结果是正的,预测类别ŷ是正类,为 1,否则他就是负类,为 0。见下面的公式
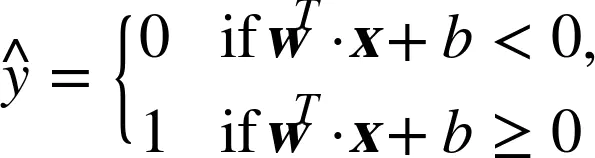
花瓣数据集的决策函数
iris = datasets.load_iris()
X = iris["data"][:,(2,3)]
y= (iris["target"] == 2).astype(np.float64)
from mpl_toolkits.mplot3d import Axes3D
def plot_3D_decision_function(ax,w,b,x1_lim = [4,6],x2_lim = [0.8,2.8]):
x1_in_bounds = (X[:,0] > x1_lim[0]) & (X[:,0] < x1_lim[1])
X_crop = X[x1_in_bounds]
y_crop = y[x1_in_bounds]
x1s = np.linspace(x1_lim[0], x1_lim[1], 20)
x2s = np.linspace(x2_lim[0], x2_lim[1], 20)
x1,x2 = np.meshgrid(x1s,x2s)
xs = np.c_[x1.ravel(),x2.ravel()]
df = (xs.dot(w + b)).reshape(x1.shape)
m = 1 / np.linalg.norm(w)
boundary_x2s = -x1s * (w[0] / w[1]) - b / w[1]
margin__x2s_1 = -x1s * (w[0] / w[1]) - (b - 1) / w[1]
margin__x2s_2 = -x1s * (w[0] / w[1]) - (b + 1) / w[1]
ax.plot_surface(x1s, x2, np.zeros_like(x1),
color="b", alpha=0.2, cstride=100, rstride=100)
ax.plot(x1s, boundary_x2s, 0, "k-", linewidth=2, label=r"$h=0$")
ax.plot(x1s, margin_x2s_1, 0, "k--", linewidth=2, label=r"$h=\pm 1$")
ax.plot(x1s, margin_x2s_2, 0, "k--", linewidth=2)
ax.plot(X_crop[:, 0][y_crop==1], X_crop[:, 1][y_crop==1], 0, "g^")
ax.plot_wireframe(x1, x2, df, alpha=0.3, color="k")
ax.plot(X_crop[:, 0][y_crop==0], X_crop[:, 1][y_crop==0], 0, "bs")
ax.axis(x1_lim + x2_lim)
ax.text(4.5, 2.5, 3.8, "Decision function $h$", fontsize=15)
ax.set_xlabel(r"Petal length", fontsize=15)
ax.set_ylabel(r"Petal width", fontsize=15)
ax.set_zlabel(r"$h = \mathbf{w}^T \mathbf{x} + b$", fontsize=18)
ax.legend(loc="upper left", fontsize=16)
fig = plt.figure(figsize=(11, 6))
ax1 = fig.add_subplot(111, projection='3d')
plot_3D_decision_function(ax1, w=svm_clf2.coef_[0], b=svm_clf2.intercept_[0])
save_fig("iris_3D_plot")
plt.show()
上图显示了和下图右边图模型相对应的决策函数:因为这个数据集有两个特征(花瓣的宽度和花瓣的长度),所以是个二维的平面。决策边界是决策函数等于 0 的点的集合,图中两个平面的交叉处,即一条直线(图中的实线)。
虚线表示的是那些决策函数等于 1 或 -1 的点:它们平行,且到决策边界的距离相等,形成一个间隔。训练线性 SVM 分类器意味着找到w值和b值使得这一个间隔尽可能大,同时避免间隔违规(硬间隔)或限制它们(软间隔)。

训练目标
小权重向量导致大间隔
def plot_2D_decision_function(w,b,x1_lim = [-3,3],ylabel = True):
x1= np.linspace(x1_lim[0], x1_lim[1], 200)
y = w * x1 + b
m = 1 / w
plt.plot(x1,y)
plt.plot(x1_lim,[1,1],"k:")
plt.plot(x1_lim,[-1,-1],"k:")
plt.axhline(y = 0,color = 'k')
plt.axvline(x = 0,color = 'k')
plt.plot([m,m],[0,1],"k--")
plt.plot([-m,-m],[0,-1],"k--")
plt.plot([-m,m],[0,0],"k-o",linewidth = 3)
plt.axis(x1_lim + [-2,2])
plt.xlabel(r"$x_1$",fontsize = 16)
if ylabel:
plt.ylabel(r"$w_1 x_1$",fontsize = 16,rotation = 0)
plt.title(r"$w_1 = {}$".format(w),fontsize = 16)
plt.figure(figsize=(12, 3.2))
plt.subplot(121)
plot_2D_decision_function(1,0)
plt.subplot(122)
plot_2D_decision_function(0.5,0,ylabel = False)
save_fig("small_w_large_margin_plot")
plt.show()
看下决策函数的斜率:它等于权重向量的范数![]() 。如果把这个斜率除于 2,决策函数等于 ±1 的点将会离决策边界原来的两倍大。换句话,即斜率除以 2,那么间隔将增加两倍。上图中,2D 形式比较容易可视化。权重向量
。如果把这个斜率除于 2,决策函数等于 ±1 的点将会离决策边界原来的两倍大。换句话,即斜率除以 2,那么间隔将增加两倍。上图中,2D 形式比较容易可视化。权重向量w越小,间隔越大。
故目标是最小化![]() ,从而获得大的间隔。然而,如果想要避免间隔违规(硬间隔),对于正的训练样本,需要决策函数大于 1,对于负训练样本,小于 -1。若对负样本(即
,从而获得大的间隔。然而,如果想要避免间隔违规(硬间隔),对于正的训练样本,需要决策函数大于 1,对于负训练样本,小于 -1。若对负样本(即![]() 定义
定义![]() ,对正样本(即
,对正样本(即![]() 定义
定义![]() ,那么可以对所有的样本表示为
,那么可以对所有的样本表示为![]() 。
。
因此,可以将硬间隔线性 SVM 分类器表示为下面公式中的约束优化问题。
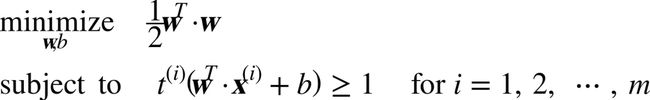
公式3 硬间隔线性SVM分类器目标

为了获得软间隔的目标,需要对每个样本应用一个松弛变量(slack variable)![]() 。
。![]() 表示了第
表示了第i个样本允许违规间隔的程度。现在有两个不一致的目标:一个是使松弛变量尽可能的小,从而减小间隔违规,另一个是使1/2 w·w尽量小,从而增大间隔。这时C超参数发挥作用:它允许在两个目标之间权衡。于是得到了下面公式的约束优化问题。
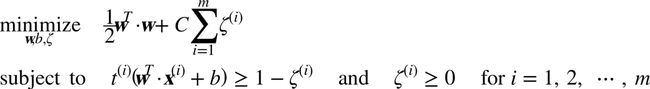
公式4 软间隔线性SVM分类器目标
二次规划
硬间隔和软间隔都是线性约束的凸二次规划优化问题。这些问题被称之为二次规划(QP)问题。现在有许多解决方案可以使用各种技术来处理 QP 问题,但这超出了本书的范围。一般问题的下面的公式在公式给出。

公式5 二次规划问题
注意到表达式Ap ≤ b实际上定义了 约束:![]() , 是个包含了
, 是个包含了A的第i行元素的向量,![]() 是
是b的第i个元素。
可以很容易地看到,如果用以下的方式设置 QP 的参数,将获得硬间隔线性 SVM 分类器的目标:
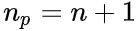 ,
,n表示特征的数量(+1 是偏置项)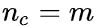 ,
,m表示训练样本数量H是 单位矩阵,除了左上角为 0(忽略偏置项)
单位矩阵,除了左上角为 0(忽略偏置项)f = 0,一个全为 0 的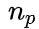 维向量
维向量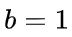 ,一个全为 1 的
,一个全为 1 的 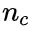 维向量
维向量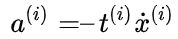 ,
, 等于
等于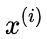 带一个额外的偏置特征
带一个额外的偏置特征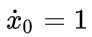
所以训练硬间隔线性 SVM 分类器的一种方式是使用现有的 QP 解决方案,即上述的参数。由此产生的向量p将包含偏置项 ![]() 和特征权重
和特征权重![]() 。同样的,可以使用 QP 解决方案来解决软间隔问题(见本章最后的练习)
。同样的,可以使用 QP 解决方案来解决软间隔问题(见本章最后的练习)
然而,使用核技巧将会看到一个不同的约束优化问题。
对偶问题
给出一个约束优化问题,即原始问题(primal problem),它可能表示不同但是和另一个问题紧密相连,称为对偶问题(Dual Problem)。对偶问题的解通常是对原始问题的解给出一个下界约束,但在某些条件下,它们可以获得相同解。幸运的是,SVM 问题恰好满足这些条件,所以可以选择解决原始问题或者对偶问题,两者将会有相同解。下面的公式表示了线性 SVM 的对偶形式
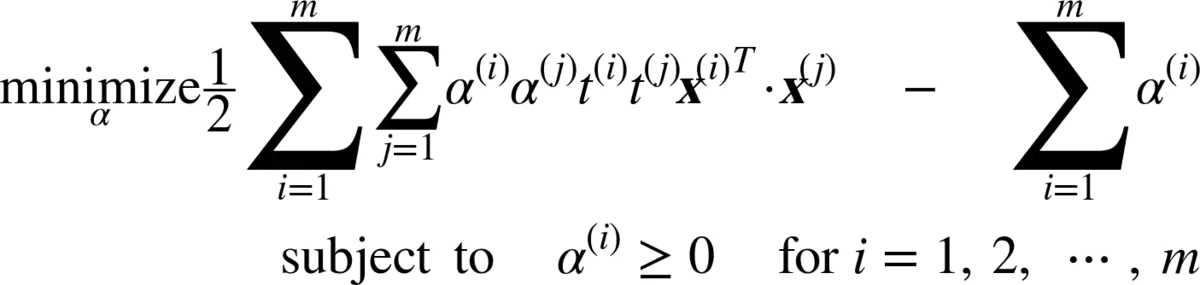
公式6 线性SVM目标的对偶形式
一旦找到最小化公式的向量α(使用 QP 解决方案),可以通过使用下面的公式的方法计算w和b,从而使原始问题最小化。
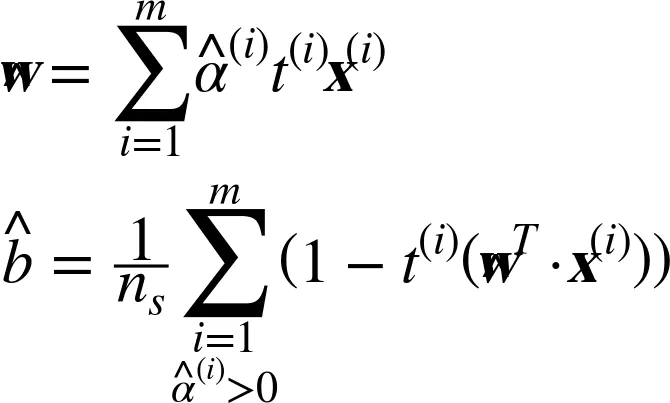
公式7 从对偶解到原始解
当训练样本的数量比特征数量小的时候,对偶问题比原始问题要快得多。更重要的是,它让核技巧成为可能,而原始问题则不然。那么这个核技巧是怎么样的呢?
核化支持向量机
假设我们想把一个 2 次多项式变换应用到二维空间的训练集(例如卫星数据集),然后在变换后的训练集上训练一个线性SVM分类器。下面的公式显示了想应用的 2 次多项式映射函数ϕ。
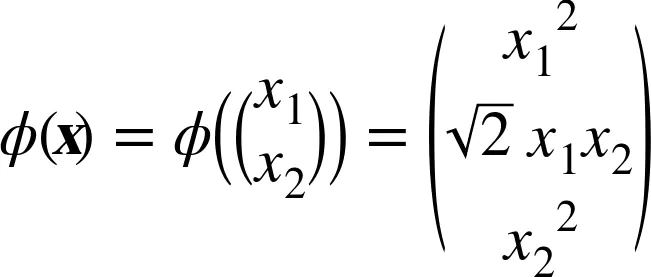
公式8二次多项式映射
注意到转换后的向量是 3 维的而不是 2 维。如果我们应用这个 2 次多项式映射,然后计算转换后向量的点积(见下面的公式),让我们看下两个 2 维向量a和b会发生什么。

公式9 二次多项式映射的核方法
转换后向量的点积等于原始向量点积的平方:![]()
关键点是:如果应用转换ϕ到所有训练样本,那么对偶问题将会包含点积 ![]() 。但如果
。但如果ϕ像在公式 8 定义的 2 次多项式转换,那么可以将这个转换后的向量点积替换成 ![]() 。所以实际上根本不需要对训练样本进行转换:仅仅需要在公式 6 中,将点积替换成它点积的平方。结果将会和经过麻烦的训练集转换并拟合出线性 SVM 算法得出的结果一样,但是这个技巧使得整个过程在计算上面更有效率。这就是核技巧的精髓。
。所以实际上根本不需要对训练样本进行转换:仅仅需要在公式 6 中,将点积替换成它点积的平方。结果将会和经过麻烦的训练集转换并拟合出线性 SVM 算法得出的结果一样,但是这个技巧使得整个过程在计算上面更有效率。这就是核技巧的精髓。
函数 ![]() 被称为二次多项式核(polynomial kernel)。在机器学习中,核函数是一个能计算点积的函数,并只基于原始向量
被称为二次多项式核(polynomial kernel)。在机器学习中,核函数是一个能计算点积的函数,并只基于原始向量a和b,不需要计算(甚至知道)转换ϕ。下面的公式列举了一些最常用的核函数。
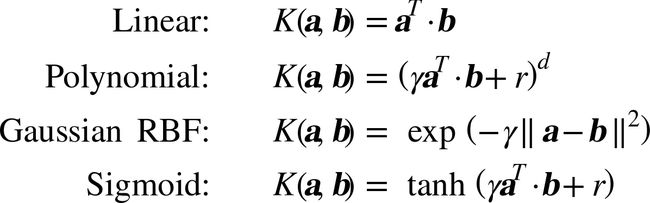
公式10 常见的核函数
Mercer 定理
根据 Mercer 定理,如果函数K(a, b)满足一些 Mercer 条件的数学条件(K函数在参数内必须是连续,对称,即K(a, b)=K(b, a),等),那么存在函数ϕ,将a和b映射到另一个空间(可能有更高的维度),有。所以你可以用
K作为核函数,即使你不知道ϕ是什么。使用高斯核(Gaussian RBF kernel)情况下,它实际是将每个训练样本映射到无限维空间,所以你不需要知道是怎么执行映射的也是一件好事。
注意一些常用核函数(例如 Sigmoid 核函数)并不满足所有的 Mercer 条件,然而在实践中通常表现得很好。
我们还有一个问题要解决。公式 7 展示了线性 SVM 分类器如何从对偶解到原始解,如果应用了核技巧那么得到的公式会包含![]() 。事实上,
。事实上,w必须和![]() 有同样的维度,可能是巨大的维度或者无限的维度,所以你很难计算它。但怎么在不知道
有同样的维度,可能是巨大的维度或者无限的维度,所以你很难计算它。但怎么在不知道w的情况下做出预测?好消息是你可以将公式 5-7 的w代入到新的样本![]() 的决策函数中,你会得到一个在输入向量之间只有点积的方程式。这时,核技巧将派上用场,见下面的公式
的决策函数中,你会得到一个在输入向量之间只有点积的方程式。这时,核技巧将派上用场,见下面的公式

公式11 用核化SVM做预测
注意到支持向量才满足α(i)≠0,做出预测只涉及计算为支持向量部分的输入样本![]() 的点积,而不是全部的训练样本。当然,你同样也需要使用同样的技巧来计算偏置项
的点积,而不是全部的训练样本。当然,你同样也需要使用同样的技巧来计算偏置项b,见下面的公式

公式12 使用核方法计算偏差项
如果开始感到头痛,这很正常:因为这是核技巧一个不幸的副作用
在线支持向量机
在结束这一章之前,快速地了解一下在线 SVM 分类器(回想一下,在线学习意味着增量地学习,不断有新实例)。对于线性SVM分类器,一种方式是使用梯度下降(例如使用SGDClassifire)最小化代价函数,如从原始问题推导出的公式 13。不幸的是,它比基于 QP 方式收敛慢得多。

公式13 线性SVM分类器损失函数
代价函数第一个和会使模型有一个小的权重向量w,从而获得一个更大的间隔。第二个和计算所有间隔违规的总数。如果样本位于“街道”上和正确的一边,或它与“街道”正确一边的距离成比例,则间隔违规等于 0。最小化保证了模型的间隔违规尽可能小并且少。
也可以实现在线核化的 SVM。例如使用“增量和递减 SVM 学习”或者“在线和主动的快速核分类器”。但是,这些都是用 Matlab 和 C++ 实现的。对于大规模的非线性问题,可能需要考虑使用神经网络(见第二部分)。
Hinge 损失
Hinge 损失
函数
max(0, 1–t)被称为 Hinge 损失函数(如下)。当t≥1时,Hinge 值为 0。如果t<1,它的导数(斜率)为 -1,若t>1,则等于0。在t=1处,它是不可微的,但就像套索回归(Lasso Regression)一样,仍然可以在t=0时使用梯度下降法(即 -1 到 0 之间任何值)
t = np.linspace(-2, 4, 200)
h = np.where(1 - t < 0, 0, 1 - t)
plt.figure(figsize=(5,2.8))
plt.plot(t, h, "b-", linewidth=2, label="$max(0, 1 - t)$")
plt.grid(True, which='both')
plt.axhline(y=0, color='k')
plt.axvline(x=0, color='k')
plt.yticks(np.arange(-1, 2.5, 1))
plt.xlabel("$t$", fontsize=16)
plt.axis([-2, 4, -1, 2.5])
plt.legend(loc="upper right", fontsize=16)
save_fig("hinge_plot")
plt.show() 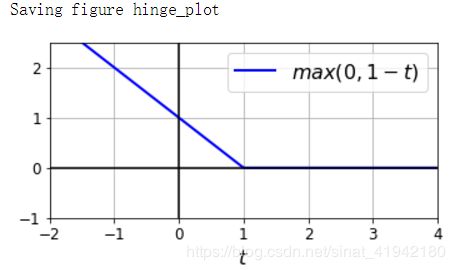
额外材料
训练时间
X,y = make_moons(n_samples = 1000,noise = 0.4,random_state = 42)
plt.plot(X[:,0][y == 0],X[:,1][y == 0],"bs")
plt.plot(X[:,0][y == 1],X[:,1][y == 1],"g^")
import time
tol = 0.1
tols = []
times = []
for i in range(10):
svm_clf = SVC(kernel="poly", gamma=3, C=10, tol=tol, verbose=1)
t1 = time.time()
svm_clf.fit(X, y)
t2 = time.time()
times.append(t2-t1)
tols.append(tol)
print(i, tol, t2-t1)
tol /= 10
plt.semilogx(tols, times)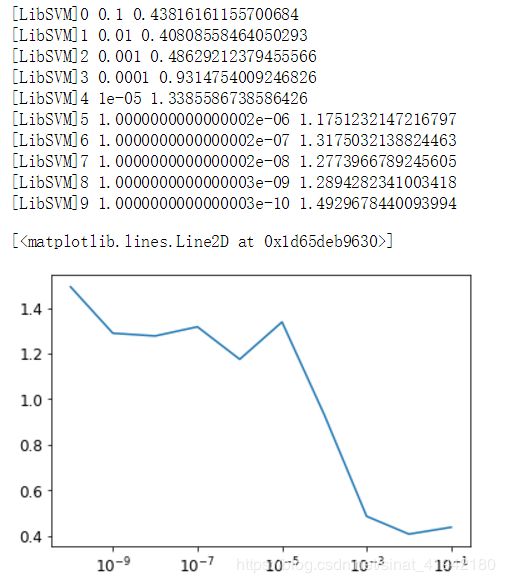
用BGD训练线性分类器
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.float64).reshape(-1, 1)
from sklearn.base import BaseEstimator
class MyLinearSVC(BaseEstimator):
def __init__(self, C=1, eta0=1, eta_d=10000, n_epochs=1000, random_state=None):
self.C = C
self.eta0 = eta0
self.n_epochs = n_epochs
self.random_state = random_state
self.eta_d = eta_d
def eta(self, epoch):
return self.eta0 / (epoch + self.eta_d)
def fit(self, X, y):
if self.random_state:
np.random.seed(self.random_state)
w = np.random.randn(X.shape[1], 1)
b = 0
m = len(X)
t = y * 2 - 1
X_t = X * t
self.Js=[]
# Training
for epoch in range(self.n_epochs):
support_vectors_idx = (X_t.dot(w) + t * b < 1).ravel()
X_t_sv = X_t[support_vectors_idx]
t_sv = t[support_vectors_idx]
J = 1/2 * np.sum(w * w) + self.C * (np.sum(1 - X_t_sv.dot(w)) - b * np.sum(t_sv))
self.Js.append(J)
w_gradient_vector = w - self.C * np.sum(X_t_sv, axis=0).reshape(-1, 1)
b_derivative = -C * np.sum(t_sv)
w = w - self.eta(epoch) * w_gradient_vector
b = b - self.eta(epoch) * b_derivative
self.intercept_ = np.array([b])
self.coef_ = np.array([w])
support_vectors_idx = (X_t.dot(w) + t * b < 1).ravel()
self.support_vectors_ = X[support_vectors_idx]
return self
def decision_function(self, X):
return X.dot(self.coef_[0]) + self.intercept_[0]
def predict(self, X):
return (self.decision_function(X) >= 0).astype(np.float64)
C=2
svm_clf = MyLinearSVC(C=C, eta0 = 10, eta_d = 1000, n_epochs=60000, random_state=2)
svm_clf.fit(X, y)
svm_clf.predict(np.array([[5, 2], [4, 1]]))![]()
plt.plot(range(svm_clf.n_epochs), svm_clf.Js)
plt.axis([0, svm_clf.n_epochs, 0, 100])
print(svm_clf.intercept_, svm_clf.coef_)![]()
svm_clf2 = SVC(kernel="linear", C=C)
svm_clf2.fit(X, y.ravel())
print(svm_clf2.intercept_, svm_clf2.coef_)
yr = y.ravel()
plt.figure(figsize=(12,3.2))
plt.subplot(121)
plt.plot(X[:, 0][yr==1], X[:, 1][yr==1], "g^", label="Iris-Virginica")
plt.plot(X[:, 0][yr==0], X[:, 1][yr==0], "bs", label="Not Iris-Virginica")
plot_svc_decision_boundary(svm_clf, 4, 6)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.title("MyLinearSVC", fontsize=14)
plt.axis([4, 6, 0.8, 2.8])
plt.subplot(122)
plt.plot(X[:, 0][yr==1], X[:, 1][yr==1], "g^")
plt.plot(X[:, 0][yr==0], X[:, 1][yr==0], "bs")
plot_svc_decision_boundary(svm_clf2, 4, 6)
plt.xlabel("Petal length", fontsize=14)
plt.title("SVC", fontsize=14)
plt.axis([4, 6, 0.8, 2.8])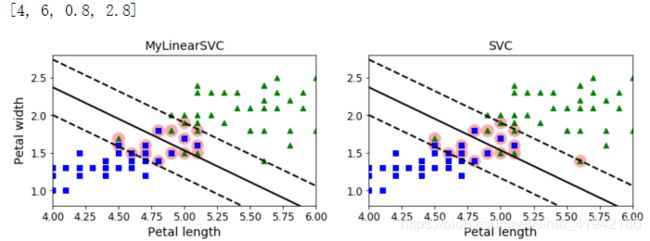
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(loss="hinge", alpha = 0.017, max_iter = 50, random_state=42)
sgd_clf.fit(X, y.ravel())
m = len(X)
t = y * 2 - 1
X_b = np.c_[np.ones((m, 1)), X]
X_b_t = X_b * t
sgd_theta = np.r_[sgd_clf.intercept_[0], sgd_clf.coef_[0]]
print(sgd_theta)
support_vectors_idx = (X_b_t.dot(sgd_theta) < 1).ravel()
sgd_clf.support_vectors_ = X[support_vectors_idx]
sgd_clf.C = C
plt.figure(figsize=(5.5,3.2))
plt.plot(X[:, 0][yr==1], X[:, 1][yr==1], "g^")
plt.plot(X[:, 0][yr==0], X[:, 1][yr==0], "bs")
plot_svc_decision_boundary(sgd_clf, 4, 6)
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.title("SGDClassifier", fontsize=14)
plt.axis([4, 6, 0.8, 2.8])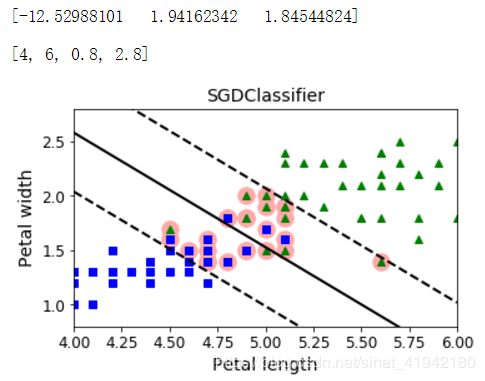
练习
8.在一个线性可分的数据集训练LinearSVC,并在同一个数据集上用SVC和SGDClassifier训练,看它们是否产生了大致相同效果的模型。
使用Iris数据集:Setosa和Versicolor类的Iris是线性可分的。
from sklearn import datasets
iris = datasets.load_iris()
X = iris["data"][:,(2,3)]
y = iris["target"]
setosa_or_versicolor = (y == 0) | (y == 1)
X = X[setosa_or_versicolor]
y = y[setosa_or_versicolor]
from sklearn.svm import SVC, LinearSVC
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import StandardScaler
C = 5
alpha = 1 / (C * len(X))
lin_clf = LinearSVC(loss="hinge", C=C, random_state=42)
svm_clf = SVC(kernel="linear", C=C)
sgd_clf = SGDClassifier(loss="hinge", learning_rate="constant", eta0=0.001, alpha=alpha,
max_iter=100000, random_state=42)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
lin_clf.fit(X_scaled, y)
svm_clf.fit(X_scaled, y)
sgd_clf.fit(X_scaled, y)
print("LinearSVC: ", lin_clf.intercept_, lin_clf.coef_)
print("SVC: ", svm_clf.intercept_, svm_clf.coef_)
print("SGDClassifier(alpha={:.5f}):".format(sgd_clf.alpha), sgd_clf.intercept_, sgd_clf.coef_)
接下来绘制这三个模型的决策边界
w1 = -lin_clf.coef_[0, 0]/lin_clf.coef_[0, 1]
b1 = -lin_clf.intercept_[0]/lin_clf.coef_[0, 1]
w2 = -svm_clf.coef_[0, 0]/svm_clf.coef_[0, 1]
b2 = -svm_clf.intercept_[0]/svm_clf.coef_[0, 1]
w3 = -sgd_clf.coef_[0, 0]/sgd_clf.coef_[0, 1]
b3 = -sgd_clf.intercept_[0]/sgd_clf.coef_[0, 1]
line1 = scaler.inverse_transform([[-10, -10 * w1 + b1], [10, 10 * w1 + b1]])
line2 = scaler.inverse_transform([[-10, -10 * w2 + b2], [10, 10 * w2 + b2]])
line3 = scaler.inverse_transform([[-10, -10 * w3 + b3], [10, 10 * w3 + b3]])
plt.figure(figsize=(11, 4))
plt.plot(line1[:, 0], line1[:, 1], "k:", label="LinearSVC")
plt.plot(line2[:, 0], line2[:, 1], "b--", linewidth=2, label="SVC")
plt.plot(line3[:, 0], line3[:, 1], "r-", label="SGDClassifier")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo")
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
plt.legend(loc="upper center", fontsize=14)
plt.axis([0, 5.5, 0, 2])
plt.show()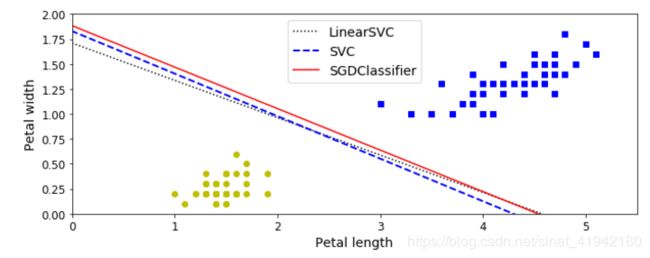
9. 在 MNIST 数据集上训练一个 SVM 分类器。因为 SVM 分类器是二元分类,你需要使用一对多(one-versus-all)来对 10 个数字进行分类。你可能需要使用小的验证集来调整超参数以加快进程。最后能达到多少准确度?
首先,加载数据集并分割成一个训练集和测试集。
def sort_by_target(mnist):
reorder_train = np.array(sorted([(target,i) for i,target in enumerate(mnist.target[:60000])]))[:,1]
reorder_test = np.array(sorted([(target,i) for i,target in enumerate(mnist.target[60000:])]))[:,1]
mnist.data[:60000] = mnist.data[reorder_train]
mnist.target[:60000] = mnist.target[reorder_train]
mnist.data[60000:] = mnist.data[reorder_test + 60000]
mnist.target[60000:] = mnist.target[reorder_test + 60000]
try:
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784',version = 1,cache = True)
mnist.target = mnist.target.astype(np.int8)
sort_by_target(mnist)
except ImportError:
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
X, y = mnist["data"], mnist["target"]
X_train = X[:60000]
y_train = y[:60000]
X_test = X[60000:]
y_test = y[60000:]许多训练算法对训练实例的顺序很敏感,所以通常最好先洗牌。
np.random.seed(42)
rnd_idx = np.random.permutation(60000)
X_train = X_train[rnd_idx]
y_train = y_train[rnd_idx]让我们从简单的线性SVM分类器开始。它将自动使用One-vs-All(也称为One-vs-the-Rest, OvR)策略,因此不需要做任何特殊的事情。
lin_clf = LinearSVC(random_state=42)
lin_clf.fit(X_train, y_train)
对训练集进行预测,查看准确分数。
from sklearn.metrics import accuracy_score
y_pred = lin_clf.predict(X_train)
accuracy_score(y_train, y_pred)![]()
在MNIST上85%的正确率真是糟糕。这个线性模型对于MNIST来说当然是太简单了,但也许只是需要对数据进行缩放。
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float32))
X_test_scaled = scaler.transform(X_test.astype(np.float32))
lin_clf = LinearSVC(random_state=42)
lin_clf.fit(X_train_scaled, y_train)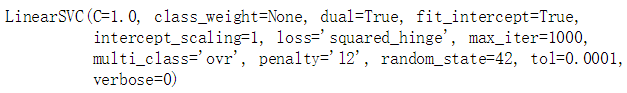
y_pred = lin_clf.predict(X_train_scaled)
accuracy_score(y_train, y_pred)![]()
这样就好多了,但是对于MNIST来说仍然不是很好。如果我们想使用SVM,就必须使用核函数。让我们尝试一个带有RBF内核(默认)的SVC。
警告:如果使用的是Scikit-Learn≤0.19,SVC类将默认使用One-vs-One (OvO)策略,因此如果想使用ovr策略,则必须显式地设置decision_function_shape="ovr" (ovr是0.19以来的默认值)。
svm_clf = SVC(decision_function_shape="ovr")
svm_clf.fit(X_train_scaled[:10000], y_train[:10000])
y_pred = svm_clf.predict(X_train_scaled)
accuracy_score(y_train, y_pred)![]()
这是有希望的,得到了更好的性能,即使在6倍少的数据上训练模型。
接下来通过交叉验证进行随机搜索来调整超参数。将在一个小的数据集上这样做,只是为了加快这个过程。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import reciprocal, uniform
param_distributions = {"gamma": reciprocal(0.001, 0.1), "C": uniform(1, 10)}
rnd_search_cv = RandomizedSearchCV(svm_clf, param_distributions, n_iter=10, verbose=2)
rnd_search_cv.fit(X_train_scaled[:1000], y_train[:1000])


rnd_search_cv.best_estimator_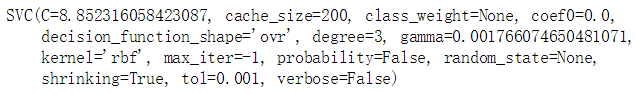
rnd_search_cv.best_score_![]()
这看起来很低,但只在1000个实例上训练模型。
接下来重新在整个训练集训练最好的评估器。
rnd_search_cv.best_estimator_.fit(X_train_scaled, y_train)
看起来不错!选择这个模型,在测试集上测试它。
y_pred = rnd_search_cv.best_estimator_.predict(X_test_scaled)
accuracy_score(y_test, y_pred)![]()
不算太糟,但显然模型有点过拟合。对超参数进行更多的调整(例如降低C和/或gamma),但是会冒测试集过拟合的风险。其他人已经发现超参数C=5和gamma=0.005会产生更好的性能(超过98%的准确率)。通过对训练集的更大一部分进行更长时间的随机搜索您可能也会发现这一点。
10. 在加利福尼亚住宅(California housing)数据集上训练一个 SVM 回归模型?
首先使用Scikit-Learn的fetch_california_housing()函数加载数据集。
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X = housing["data"]
y = housing["target"]切分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)对数据进行缩放
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)定义一简单的LinearSVR,并看在训练集上的表现。
from sklearn.svm import LinearSVR
lin_svr = LinearSVR(random_state=42)
lin_svr.fit(X_train_scaled, y_train)
from sklearn.metrics import mean_squared_error
y_pred = lin_svr.predict(X_train_scaled)
mse = mean_squared_error(y_train, y_pred)
mse![]()
np.sqrt(mse)![]()
在这个训练集中,目标是数万美元。RMSE给出了应该期望的错误类型的大致概念(对于较大的错误有更高的权重):因此,在这个模型中,可以期望大约10,000美元的错误。不是很好。
接下来看看是否可以用RBF核做得更好。将使用交叉验证的随机搜索来找到C和gamma的适当超参数值。
from sklearn.svm import SVR
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import reciprocal, uniform
param_distributions = {"gamma": reciprocal(0.001, 0.1), "C": uniform(1, 10)}
rnd_search_cv = RandomizedSearchCV(SVR(), param_distributions, n_iter=10, verbose=2, random_state=42)
rnd_search_cv.fit(X_train_scaled, y_train)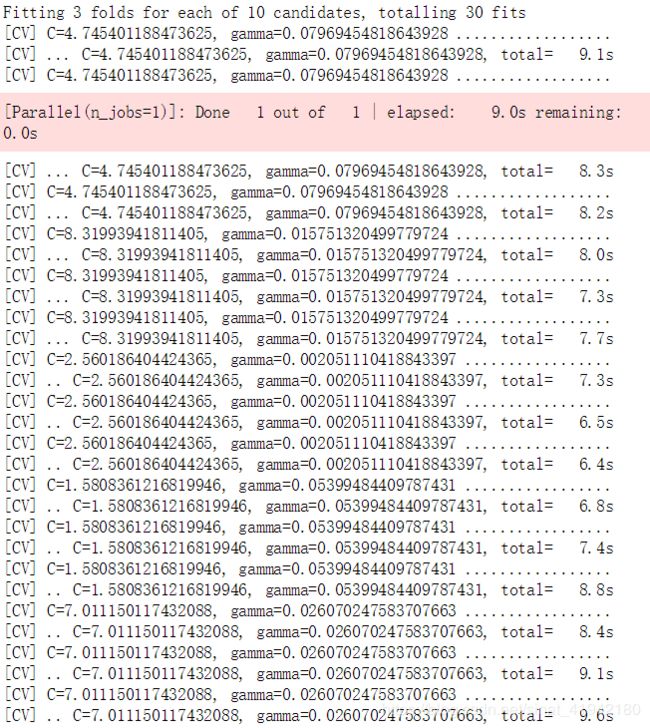
rnd_search_cv.best_estimator_
y_pred = rnd_search_cv.best_estimator_.predict(X_train_scaled)
mse = mean_squared_error(y_train, y_pred)
np.sqrt(mse)![]()
看起来比线性模型好多了。选择这个模型,并在测试集上进行评估。
y_pred = rnd_search_cv.best_estimator_.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
np.sqrt(mse)![]()