#写在前面#大学毕业生面对最紧迫的问题:找工作。企业提供工作机会,学生找寻就业方向。这一双向选择的过程,企业和个人都有可能成为主导者。事实上,毕业生始终处在较为弱势的处境,因此需要有效的手段助力毕业生做出更加科学、合理、客观的职业选择,毕竟这是迈向社会的第一步——人生的第一份工作。

大学毕业生面对以下两个困境(需求痛点):
1、大学生缺乏社会工作经验、阅历不足,对招聘企业信息都局限于互联网提供的基础信息,再加上一些自我的感性判断,无法了解一家企业/公司的实际情况和未来潜力;
2、企业招聘过程中,面向学生未能提供客观、真实的公司信息,大学毕业生难免存在理解上的偏差,做出不明智的抉择和判断;
征信——一种高效、科学的技术手段,可以帮助毕业生了解社会对招聘企业的客观评价,从而在就业路上少走弯路。
问题分析
大学毕业生择业过程中显得很谨慎甚至说有些许的胆怯,但流露出来更多是迷惘:应该去一家什么样的公司?或者说我去的这家公司到底怎样?
因为不了解,所以胆怯;因为不了解,所以迷惘。
1、用户故事
一名应届毕业生,找工作时,最关心/在意一家公司的那些方面?
a. 薪酬水平:最主要的考虑因素,占57.69%;
b. 专业对口/兴趣相关:占52.94%;
c. 发展前景:职业发展和个人发展前景占41. 63%;
d. 公司性质:国企/私企/公务员/事业单位等占40.05%;[数据来源:中国青年报]
很显然,工资是毕业生最看重的找工作要素,但并未将薪酬视为唯一标准。毕业生的视角很狭隘,大多看到的只是眼前的表象,而无法以更加多维的视角评价公司。以上毕业生的关注要素,是毕业生视角给出的一些个性化参考维度,那么下面将进一步补充一个命题:应该从哪些维度评价一家公司?
解决问题
概括起来讲,大学毕业生择业时最关注有三个要点:
a. 薪资福利
b. 专业对口/兴趣
c. 公司现状/前景
那么,公司的哪些信息维度可以解释以上四个要点的呢?公司的一面之词的推销宣传和个人的分析判断恐怕很难保证结论的准确性,而建立科学的征信评价模型对毕业生择业过程中认识公司大有裨益。以下针对以上的三个要点,尝试做一个信用建模:
1、数据来源
a. 薪资福利:一个岗位的薪资水平取取决于一家公司的综合实力。薪资的决定要素有很多,职业类型、行业薪资、公司薪资实力等等综合所得,可能单纯地评判一个数字显得并不那么写实。
评价维度
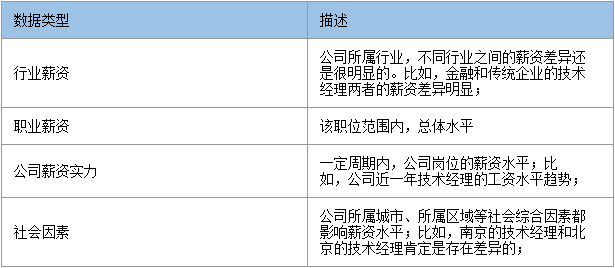
b. 专业/兴趣:提供职位是否与自己的专业相吻合和兴趣相关。很多人还是愿意从事与自己所学相关的工作的,本质上是个人信息与企业属性相匹配的过程。
评价维度

c. 企业特性:包括,现状和未来。企业现状是应聘者选择公司的基本面,而企业的未来又是个人发展的保障。对于一名应聘者来讲,其关注的是企业的现在与未来是好/是坏的结论,那么从哪些角度评价一家企业的好/坏呢?行业趋势、股权架构、组织结构、财务状况、核心产品、商业/经营模式等等要素共同决定了一家公司的好坏。
评价维度
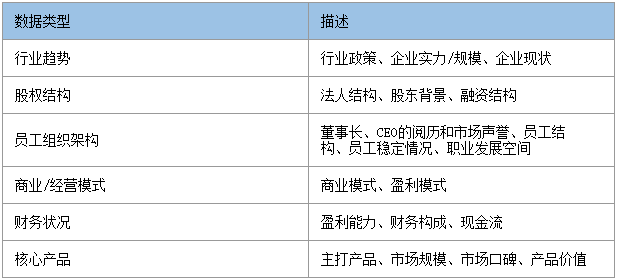
其实,除了以上的数据维度评价一个企业的综合实力外,社会化员工评价也很关键。现有及前员工的评价对以上任何评价维度都极具价值。
2、模型构建
如何设计征信评价标准?传统的征信商业模式均采用——信用报告的模式,说白了就是将个人/企业信息进行整理输出,论技术含量和信息价值量都不是那么可观的。普通用户或许更加愿意接受简单、直观的征信产品形态,不需要洋洋洒洒的一纸文书,更不需要那些看不懂的专业评价内容。一个分数等级、一个评价体系简化面向用户的信用评分模型,其实并未减少评价模型背后的任何可能。蚂蚁金服的芝麻信用就是典型的信用分模型,而腾讯征信采用了信用评级的形式。信用分、信用评级概念上都简化了用户的理解和获取成本,这一点上可谓异曲同工;同时,直观的征信模型对信用场景也更加友好,应用场景更加宽泛。那么如何将背后无数信用数据变量整合成一个显性衍生变量呢?
以上三大类数据来源可以实验性地综合出三个信用分评估维度:薪资能力、个人实现、企业特性;
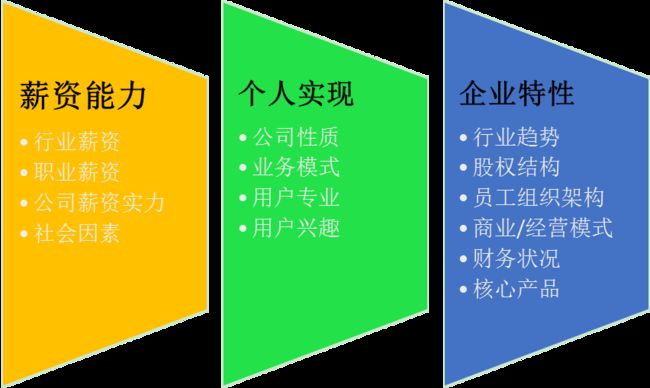
通过以上数据类型可以提炼出更多的数据分析维度,下面仅以上述三个征信评价维度为例。
3、数据经营
以[薪资能力]为分析对象,将[行业薪资]作为衡量企业[薪资能力]的维度,应该做哪些方面的思考。
从事什么职业?什么级别?在哪个行业?
什么职业类型,初步决定该用户的获薪水平;具体的职位类别最终关联到用户实现价值,用户做什么,明确不同工作之间的差异,一定程度上可以区分不同职业之间的薪资水平。
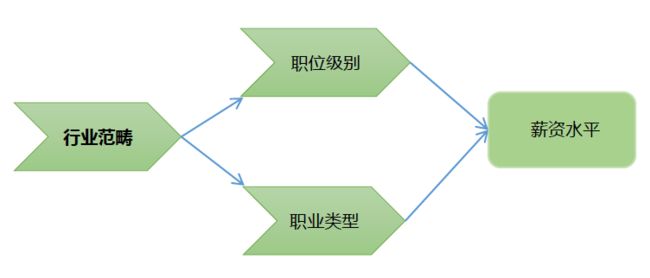
什么职位级别,强化用户的获得薪资的能力;用户所在职位级别直接决定该用户的价值实现程度及获取价值的能力,以及该职位在公司实际所处的战略位置和重视程度。
什么行业范畴,预判用户持续获得薪资能力;尝试对该用户所处行业的发展现状及前景进行调研,给出该用户公司在该行业的综合水平。实际上,行业范畴给职业类型和职位级别都加上了相应的权重。
综上所述,职位、级别、行业基本决定公司现在及未来的“薪资能力”,即用户获得可期望的薪资水平。
想要将上述假设性择业征信模型实践到现实的用户群体中,必须面对两个客观难题:
1、数据来务必可靠,一切征信产品皆数据,全面、准确、客观的数据才是征信应用场景的根本;
2、用户缺乏征信意识,大学毕业生普遍未接触过征信,尚未形成个人征信的概念,更谈不上借助征信解决实际问题;
行文小结
征信在商业(B端)领域的应用较为广泛,大多都是企业单向约束普通用户,对普通用户进行信用身份校验的媒介。然而,大学毕业生面对或者说考量企业时表现出来的更多是无奈、无知,不知道究竟该从何入手对企业做出一个清晰的认识和正确的评判。正如我之前所说,征信的未来在于应用场景,而征信场景的核心却在于普通用户(C端),因为企业(B端)应用场景相对狭隘。
原创声明:本文章的最终解释权归产品小王所有,如需转载,请注明文章出处!谢谢...