1. 项目背景
传统数仓的组织架构是针对离线数据的OLAP(联机事务分析)需求设计的,常用的导入数据方式为采用sqoop或spark定时作业逐批将业务库数据导入数仓。随着数据分析对实时性要求的不断提高,按小时、甚至分钟级的数据同步越来越普遍。由此展开了基于spark/flink流处理机制的(准)实时同步系统的开发。
然而实时同步数仓从一开始就面临如下几个挑战:
- 小文件问题。不论是spark的microbatch模式,还是flink的逐条处理模式,每次写入HDFS时都是几M甚至几十KB的文件。长时间下来产生的大量小文件,会对HDFS namenode产生巨大的压力。
- 对update操作的支持。HDFS系统本身不支持数据的修改,无法实现同步过程中对记录进行修改。
- 事务性。不论是追加数据还是修改数据,如何保证事务性。即数据只在流处理程序commit操作时一次性写入HDFS,当程序rollback时,已写入或部分写入的数据能随之删除。
Hudi是针对以上问题的解决方案之一。以下是对Hudi的简单介绍,主要内容翻译自官网。
2. Hudi简介
2.1 时间线(Timeline)
Hudi内部按照操作时刻(instant)对表的所有操作维护了一条时间线,由此可以提供表在某一时刻的视图,还能够高效的提取出延后到达的数据。每一个时刻包含:
- 时刻行为:对表操作的类型,包含:
commit:提交,将批次的数据原子性的写入表;
clean: 清除,后台作业,不断清除不需要的旧得版本的数据;
delta_commit:delta 提交是将批次记录原子性的写入MergeOnRead表中,数据写入的目的地是delta日志文件;
compacttion:压缩,后台作业,将不同结构的数据,例如记录更新操作的行式存储的日志文件合并到列式存储的文件中。压缩本身是一个特殊的commit操作;
rollback:回滚,一些不成功时,删除所有部分写入的文件;
savepoint:保存点,标志某些文件组为“保存的“,这样cleaner就不会删除这些文件;
- 时刻时间:操作开始的时间戳;
- 状态:时刻的当前状态,包含:
requested 某个操作被安排执行,但尚未初始化
inflight 某个操作正在执行
completed 某一个操作在时间线上已经完成
Hudi保证按照时间线执行的操作按照时刻时间具有原子性及时间线一致性。
2.2 文件管理
Hudi表存在在DFS系统的 base path(用户写入Hudi时自定义) 目录下,在该目录下被分成不同的分区。每一个分区以 partition path 作为唯一的标识,组织形式与Hive相同。
每一个分区内,文件通过唯一的 FileId 文件id 划分到 FileGroup 文件组。每一个FileGroup包含多个 FileSlice 文件切片,每一个切片包含一个由commit或compaction操作形成的base file 基础文件(parquet文件),以及包含对基础文件进行inserts/update操作的log files 日志文件(log文件)。Hudi采用了MVCC设计,compaction操作会将日志文件和对应的基础文件合并成新的文件切片,clean操作则删除无效的或老版本的文件。
2.3 索引
Hudi通过映射Hoodie键(记录键+ 分区路径)到文件id,提供了高效的upsert操作。当第一个版本的记录写入文件时,这个记录键值和文件的映射关系就不会发生任何改变。换言之,映射的文件组始终包含一组记录的所有版本。
2.4 表类型&查询
Hudi表类型定义了数据是如何被索引、分布到DFS系统,以及以上基本属性和时间线事件如何施加在这个组织上。查询类型定义了底层数据如何暴露给查询。
| 表类型 | 支持的查询类型 |
|---|---|
| Copy On Write写时复制 | 快照查询 + 增量查询 |
| Merge On Read读时合并 | 快照查询 + 增量查询 + 读取优化 |
2.4.1 表类型
Copy On Write:仅采用列式存储文件(parquet)存储文件。更新数据时,在写入的同时同步合并文件,仅仅修改文件的版次并重写。
Merge On Read:采用列式存储文件(parquet)+行式存储文件(avro)存储数据。更新数据时,新数据被写入delta文件并随后以异步或同步的方式合并成新版本的列式存储文件。
| 取舍 | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | 高 | 低 |
| Update cost (I/O)更新操作开销(I/O) | 高(重写整个parquet) | 低(追加到delta记录) |
| Parquet文件大小 | 小(高更新(I/O)开销) | 大(低更新开销) |
| 写入频率 | 高 | 低(取决于合并策略) |
2.4.2 查询类型
- 快照查询:查询会看到以后的提交操作和合并操作的最新的表快照。对于merge on read表,会将最新的基础文件和delta文件进行合并,从而会看到近实时的数据(几分钟的延迟)。对于copy on write表,当存在更新/删除操作时或其他写操作时,会直接代替已有的parquet表。
- 增量查询:查询只会看到给定提交/合并操作之后新写入的数据。由此有效的提供了变更流,从而实现了增量数据管道。
- 读优化查询:查询会看到给定提交/合并操作之后表的最新快照。只会查看到最新的文件切片中的基础/列式存储文件,并且保证和非hudi列式存储表相同的查询效率。
| 取舍 | 快照 | 读取优化 |
|---|---|---|
| 数据延迟 | 低 | 高 |
| 查询延迟 | 高(合并基础/列式存储文件 + 行式存储delta / 日志 文件) | 低(原有的基础/列式存储文件查询性能) |
3. Spark结构化流写入Hudi
以下是整合spark结构化流+hudi的示意代码,由于Hudi OutputFormat目前只支持在spark rdd对象中调用,因此写入HDFS操作采用了spark structured streaming的forEachBatch算子。具体说明见注释。
package pers.machi.sparkhudi
import org.apache.log4j.Logger
import org.apache.spark.sql.catalyst.encoders.RowEncoder
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
object SparkHudi {
val logger = Logger.getLogger(SparkHudi.getClass)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("SparkHudi")
//.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.default.parallelism", 9)
.config("spark.sql.shuffle.partitions", 9)
.enableHiveSupport()
.getOrCreate()
// 添加监听器,每一批次处理完成,将该批次的相关信息,如起始offset,抓取记录数量,处理时间打印到控制台
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})
// 定义kafka流
val dataStreamReader = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "testTopic")
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", false)
// 加载流数据,这里因为只是测试使用,直接读取kafka消息而不做其他处理,是spark结构化流会自动生成每一套消息对应的kafka元数据,如消息所在主题,分区,消息对应offset等。
val df = dataStreamReader.load()
.selectExpr(
"topic as kafka_topic"
"CAST(partition AS STRING) kafka_partition",
"cast(timestamp as String) kafka_timestamp",
"CAST(offset AS STRING) kafka_offset",
"CAST(key AS STRING) kafka_key",
"CAST(value AS STRING) kafka_value",
"current_timestamp() current_time",
)
.selectExpr(
"kafka_topic"
"concat(kafka_partition,'-',kafka_offset) kafka_partition_offset",
"kafka_offset",
"kafka_timestamp",
"kafka_key",
"kafka_value",
"substr(current_time,1,10) partition_date")
// 创建并启动query
val query = df
.writeStream
.queryName("demo").
.foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.persist()
println(LocalDateTime.now() + "start writing cow table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
// 以kafka分区和偏移量作为组合主键
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
// 以当前日期作为分区
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "copy_on_write_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/COPY_ON_WRITE")
println(LocalDateTime.now() + "start writing mor table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "MERGE_ON_READ")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "merge_on_read_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/MERGE_ON_READ")
println(LocalDateTime.now() + "finish")
batchDF.unpersist()
}
}
.option("checkpointLocation", "/tmp/sparkHudi/checkpoint/")
.start()
query.awaitTermination()
}
}
4. 测试结果
受限于测试条件,这次测试没有考虑update操作,而仅仅是测试hudi对追加新数据的性能。
数据程序一共运行5天,期间未发生报错导致程序退出。
kafka每天读取数据约1500万条,被消费的topic共有9个分区。
几点说明如下
1 是否有数据丢失及重复
由于每条记录的分区+偏移量具有唯一性,通过检查同一分区下是否有偏移量重复及不连续的情况,可以断定数据不存丢失及重复消费的情况。
2 最小可支持的单日写入数据条数
数据写入效率,对于cow及mor表,不存在更新操作时,写入速率接近。这本次测试中,spark每秒处理约170条记录。单日可处理1500万条记录。
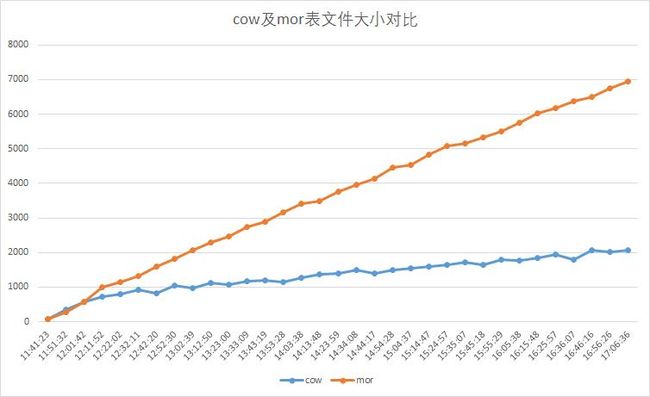
3 cow和mor表文件大小对比
每十分钟读取两种表同一分区小文件大小,单位M。结果如下图,mor表文件大小增加较大,占用磁盘资源较多。不存在更新操作时,尽可能使用cow表。