论文阅读(【CVPR2018】Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision)
论文阅读(【CVPR2018】Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision)
目录
论文和作者
论文
作者
方法概述
网络结构
损失函数
网络参数
实验
图像去雾
实验结果
图像超分辨率重建
实验结果
图像去雨
实验结果
图像保边滤波
实验结果
总结
参考文献
论文和作者
论文
【CVPR2018】Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision
论文链接 论文主页 代码
作者
Jinshan Pan, Sifei Liu, Deqing Sun, Jiawei Zhang, Yang Liu, Jimmy Ren, Zechao Li, Jinhui Tang, Huchuan Lu, Yu-Wing Tai, Ming-Hsuan Yang
方法概述
本文针对低层视觉问题,提出了一般性的用于解决低层视觉问题的对偶卷积神经网络。作者认为,低层视觉问题,如常见的有超分辨率重建、保边滤波、图像去雾和图像去雨等,这些问题经常涉及到估计目标信号的两个成分:结构和细节。因此,文章提出DualCNN,它包含两个平行的分支来分别恢复结构和细节信息。

SRCNN只有3层,在恢复图像细节方面效果不好,于是VDSR用20层的CNN来恢复细节,但是,如果图像的结构没有被很好地恢复,超分结果就会出现许多artifacts(如上图)。
网络结构
作者提出,用两个并列的网络Net-D和Net-S来分别恢复图像的细节和结构信息,其中D表示detail,S表示structure.最后将两个输出以某种方式整合成最终的输出(视具体问题而定)。
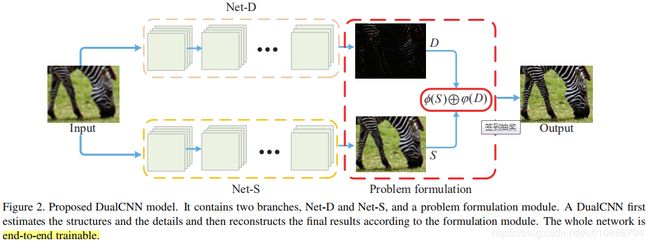
损失函数
令X,S和D分别表示ground truth,Net-S和Net-D的输出,两个网络恢复出的结构和细节需要能够恢复出原图X,于是损失函数如下:
![]()
![]()
另外,Net-S和Net-D各自的损失函数如下:
![]()
![]()
于是,DualCNN最终的损失函数如下:
![]()
网络参数
Net-S使用三层卷积神经网络,卷积核大小分别是9x9,1x1和5x5,卷积核个数分别是64,32,1,每一层后面接ReLU非线性激活层。Net-D使用20层卷积层,后面也是ReLU非线性激活层,每层卷积核个数64个。这两个网络结构和SRCNN与VDSR基本一样。作者使用批大小64,用SGD方式训练,学习率为10^(-4).训练时,用SRCNN和VDSR的预训练模型作为网络的初始参数。
实验
图像去雾
图像去雾模型可以表示为:![]() ,其中I表示有雾图像,J是无雾图像,D是透射率图,S是大气光。
,其中I表示有雾图像,J是无雾图像,D是透射率图,S是大气光。
令![]() ,那么图像去雾的损失函数就变成
,那么图像去雾的损失函数就变成![]() .
.
测试时,重建出的清晰图像![]() 表示为:
表示为:
![]() ,这里d0是为了防止分母为0,设置为0.1.
,这里d0是为了防止分母为0,设置为0.1.
![]() 分别设置为0.1,0.9,0.9
分别设置为0.1,0.9,0.9
实验结果

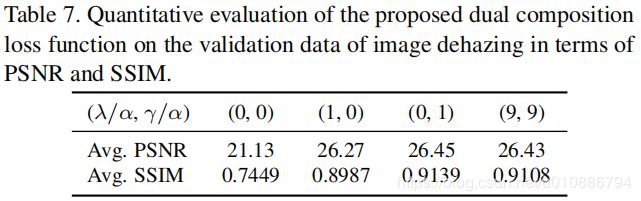
Tabel5 可能是数据集的原因,PSNR都比较低。

图像超分辨率重建
对于超分辨率重建,将ground truth X进行高斯滤波就可以得到![]() ,再用X与
,再用X与![]() 做差得到
做差得到![]() 。
。
![]()
![]() 分别设置为1,0.001和0.01.
分别设置为1,0.001和0.01.
实验结果

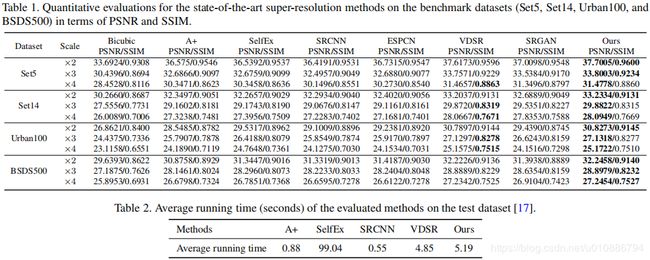
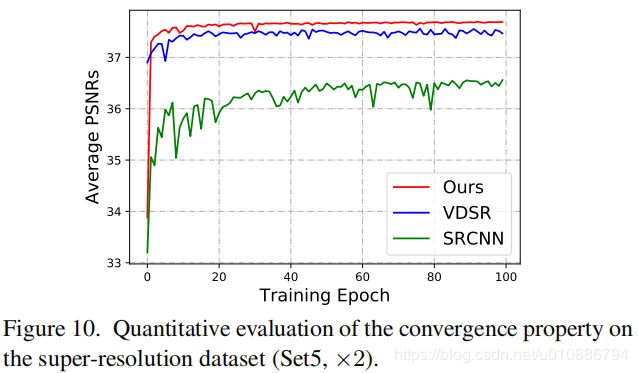
图像去雨
对于图像去雨,直接令![]() 为ground truth X,并且将
为ground truth X,并且将![]() 分别设置为1,0.001和0.
分别设置为1,0.001和0.
实验结果
下图可以看出效果还是不错的,并且如果只有S网络的话,去雨的效果不怎么好,但是加上D网络,效果明显改善。

下面这幅图是为了说明本文作者所提出的DualCNN不仅可以有效去雨,而且还可以得到比较好的图像细节。

作者对比了DualCNN与SRCNN、VDSR以及两个网络串连的实验结果,如下图:
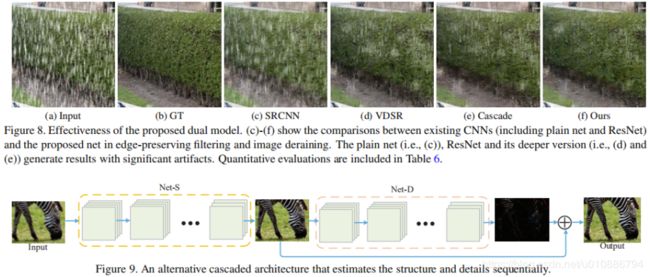
图像保边滤波
对于图像保边滤波,也是直接令![]() 为ground truth X,并且将
为ground truth X,并且将![]() 分别设置为1,0.0001和0.
分别设置为1,0.0001和0.
实验结果



总结
本文用一个框架解决了低层视觉的多个问题,并且从实验结果来看,与当前流行的针对特定问题的方法具有可比性。
参考文献
[1]C. Dong, C. C. Loy, K. He, and X. Tang. Learning a deep convolutional network for image super-resolution. In ECCV, pages 184–199, 2014. 1, 2, 3, 6, 8
[2]J. Kim, J. K. Lee, and K. M. Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, pages 1646–1654, 2016. 1, 2, 3, 4, 5, 6, 8