【Java】GC and GC Tuning
目录
1、什么是垃圾
2、如何定位垃圾
reference count
Root Searching
3、常见的垃圾回收算法
Mark-Sweep(标记清除)
Copying(拷贝算法)
Mark-Compact(标记压缩)
4、JVM内存分代模型(用于分代垃圾回收算法)
堆内存逻辑分区
5、垃圾回收器
Serial
Parallel Scavenge
ParNew
SerialOld
Parallel Old
CMS
6、JVM参数
7、思维导图
1、什么是垃圾
内存分配与回收方式:
-
C语言:malloc、free
-
C++:new、delete
-
Java:new 自动回收内存
自动回收内存系统不容易出错,手动回收内存,容易出现以下的错误:
-
忘记回收
-
多次回收
垃圾的定义:没有任何引用指向的一个对象或者多个对象(循环引用)。
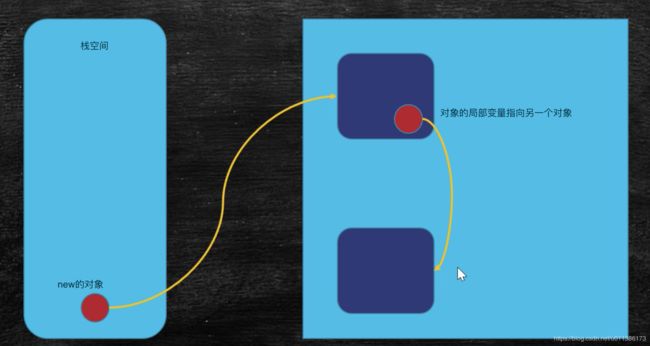
当把成员变量设置为空(null)之后,不再指向任何引用对象,那么该对象就被称作垃圾:
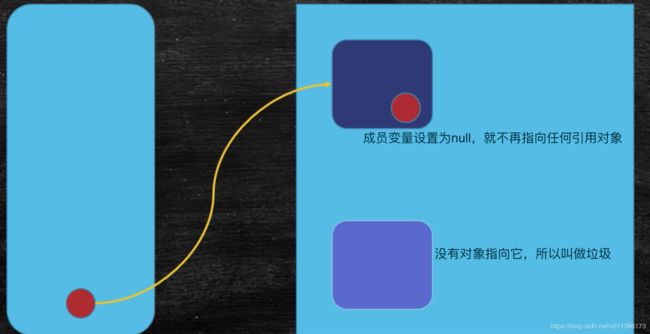
还有一种情况,多个对象之间互相引用,但是没有其他的引用指向这个循环的对象。
2、如何定位垃圾
-
reference count

当引用计数变为0的时候,这个对象就成为垃圾了。但是引用计数不能解决对象循环引用
如下:

每个引用计数都是1,但是它们全部是垃圾,所以用引用计数的方式的话,这些垃圾就找不到了,会发生内存泄漏。
-
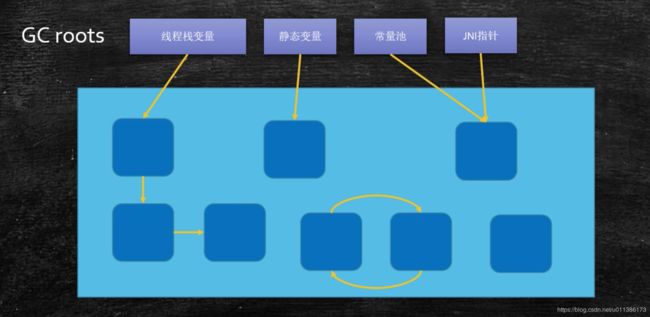
Root Searching
根可达或者根搜索算法。
通过程序找到一些根对象,通过根对象找到它所连接的那些对象不是垃圾,其他的都是垃圾。
Roots:线程栈变量、静态变量、常量池、JNI指针
3、常见的垃圾回收算法
-
Mark-Sweep(标记清除)
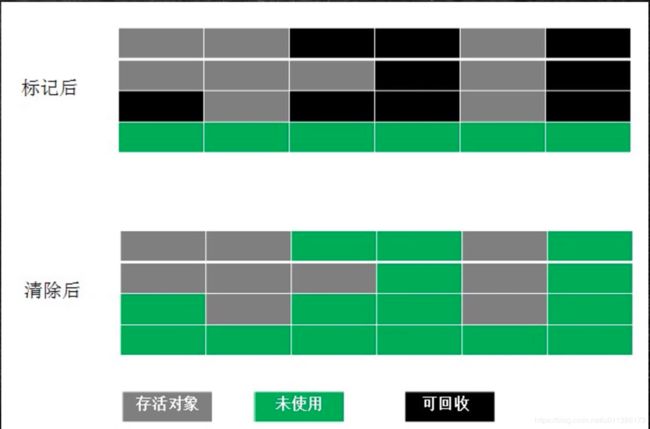
将可回收的对象标记为非垃圾。
缺点:位置不连续,产生内存碎片。
-
Copying(拷贝算法)
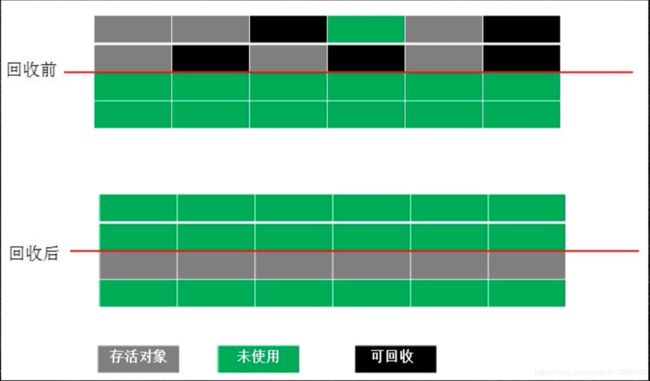
内存一分为二,将存活对象复制到未使用的内存中,原内存全部标记为可使用;新分配内存时先分配存活对象所在的那段内存,垃圾回收时,重复上述操作。
特点:没有碎片,但是内浪费空间。最大的问题:内存浪费。
-
Mark-Compact(标记压缩)
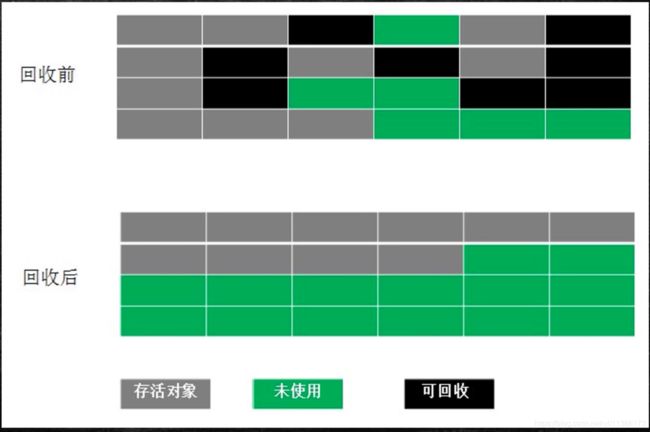
将存活对象依次复制到垃圾对象和未使用的区域中,结合了标记清除和拷贝的做法,但是效率比copy略低。
三种方法找垃圾的效率是一致的,区别在于找到垃圾后对其进行整理的方式。拷贝算法是内存拷贝,是线性地址的拷贝,速度很快的,效率很高。但是压缩算法却不这么简单,因为任意一个内存进行移动时,如果是多线程, 都要进行线程同步;如果是单线程,那单线程的效率本来就低。 所以任何一块内存挪动都要进行线程同步,所以效率肯定是很低的。
4、JVM内存分代模型(用于分代垃圾回收算法)
目前,生产环境中普遍使用的是JDK1.7或JDK1.8,根据JDK版本不同,分代也不同。
JVM中分代:新生代+老年代+永久代(JDK1.7)/元数据区(JDK1.8)Metaspace。
- 永久代和元数据区是装载Class的,将硬盘上的Class对象load到内存的时候,装载了永久代或者元数据区域,具体放在哪里区别于使用的JDK版本
- 永久代必须指定大小限制,而元数据可以设置,也可不设置,无上限(受限于物理内存)
- 字符串常量在JDK1.7中,是放在永久代区域;而JDK1.8中,是放在堆里
- MethodArea是一个逻辑概念,并不是指的一个区域,在JDK1.7中对应的就是永久代,JDK1.8中对应的是元数据
堆内存逻辑分区
- 新生代中分了两类区域,eden和survivor,而survivor有两块。默认的比例,新生代:老年代=1:3,新生代中eden: survivor:survivor = 8:1:1。
之所以新生代中按照这个比例分配,是因为eden区在GC的时候,90%的对象都会被回收,剩下的存活对象在survivor区是可以放下的。
当创建一个对象时,默认会去找eden区, 如果对象特别大,eden区装不下则直接进入老年代。
新生代 = Eden + 2个survivor区(survivor0、survivor1):
- YGC(Young GC)回收后,大多数的对象会被回收,活着的对象进入survivor0
- 再次YGC,活着的对象eden+s0拷贝到s1,将eden和s0清空
- 再次YGC,活着的对象eden+s1拷贝到s0,将eden和s1清空
- 年龄足够->老年代(年龄足够:15,CMS 6)
- survivor区装不下的时候,装不下的部分直接进入老年代
老年代:
- 顽固份子
- 老年代区域满了,就进行Full GC(简称FGC, FGC包括新生代和老年代同时GC)
GC Tuning:尽量减少FGC。
5、垃圾回收器
- Serial、ParNew、Parallel Scavenge是用于回收Young Generation
- CMS、Serial Old、Parallel Old是用于回收Old Generation
- G1、ZGC、Shenandoah不区分老年代和新生代。
- Epsilon是一个空的GC,仅仅用于调试JDK。
- 图中的红色虚线表示可以配合使用。
Serial
垃圾回收的时候,程序是无法执行的。stop-the-world(STW)是停止程序运行,回收线程开始运行,回收结束后程序再接着运行。
Parallel Scavenge
并行回收,多个线程同时进行垃圾回收。
ParNew
配合CMS的年轻代并行回收。
SerialOld
单线程回收算法用于old区域
Parallel Old
多线程回收算法用于old区域
CMS
ConcurrentMarkSweep,用于回收老年代,在垃圾回收的同时程序也能运行。(黄色的表示垃圾回收线程,蓝色表示程序执行线程)
调优针对的是Serial、Parallel Scavenge和Serial Old、Parallel New,因为JDK1.8默认的垃圾回收:Parallel Scavenge + Parallel Old。
6、JVM参数
JVM的命令行参数参考:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
JVM参数分类:
- 标准:-开头,所有的HotSpot都支持。 如:java -version
- 非标准:-X开头,特定版本HotSpot支持特定命令
- 不稳定:-XX开头,下个版本可能取消
- -XX: +PrintFlagsFinal --- 设置值(最终生效值)
- -XX:+PrintFlagsInitial --- 默认值
- -XX:+PrintCommandLineFlags ---命令行参数
7、思维导图
参考文档:
https://blogs.oracle.com/jonthecollector/our-collectors
https://blogs.oracle.com/jonthecollector/why-not-a-grand-unified-garbage-collector