LVS和Nginx
一.详细描述常见nginx常用模块和模块的使用示例
1.nginx 简介
Nignx(Engine X)是一款高度模块化的,轻量级的,高性能的HTTP和反向代理服务器,另外它也可以作为邮件代理服务器。
反向代理服务器:

正向代理:代理对象为客户端做代理,客户端无法直接访问服务端,需要通过配置代理对象才可以访问;而服务端只需要与代理对象打交道,不需要感知客户端的存在。例如通过代理访问国外网站。
反向代理:反向代理其实就是客户端去访问服务器时,他并不知道会访问哪一台,感觉就是客户端访问了Proxy一样,而实则就是当proxy关口拿到用户请求的时候会转发到代理服务器中的随机(算法)某一台。而在用户看来,他只是访问了Proxy服务器而已,典型的例子就是负载均衡了。
当客户端向服务端的反向代理发起请求时,反向代理以某种负载均衡机制将请求分发到各个目标服务器,并且将这些服务器所处理返回的内容返回给客户端。这个反向代理服务器没有保存任何网页的真实数据,所有的静态网页或者CGI程序,都保存在内部的Web服务器上。因此对反向代理服务器的攻击并不会使得网页信息遭到破坏,这样就增强了Web服务器的安全性,其中CDN就是一个比较常见的例子。
HTTP服务器:
Nginx和Apache一样都是HTTP服务器,但是两者处理用户的HTTP访问请求有所不同。
用户访问网页的基本过程(不包含缓存功能):
-
一个请求发到内核(通过socket套接字,到网卡,然后会被Linux的防火墙接收,如果请求的对象是自己,它会判断是不是本地进程的端口,如果是就直接提交到用户空间的相应进程,否则就丢弃)
-
内核交给用户空间的服务进程,服务进程发现用户请求的是一个页面文件,然后服务进程发起系统调用
-
内核通过磁盘IO获取响应内容
-
内核获取了数据之后交给服务进程
-
然后服务进程封装成响应报文,然后再送进内核
-
由内核向外响应
一次的用户请求涉及到了IO请求过程,而HTTP服务器就负责处理该过程并且将生成的报文返回给用户。
什么是IO模型:

Linux内核将所有外部设备都看做一个文件来操作。那么我们对与外部设备的操作都可以看做是对文件进行操作。我们对一个文件的读写,都通过调用内核提供的系统调用;内核给我们返回一个file descriptor(fd,文件描述符),对一个socket的读写也会有相应的描述符,称为socketfd(socket描述符)。描述符就是一个数字(可以理解为一个索引),指向内核中一个结构体(文件路径,数据区,等一些属性)。应用程序对文件的读写就通过对描述符的读写完成。
一个基本的IO,它会涉及到两个系统对象,一个是调用这个IO的进程对象(用户进程),另一个就是系统内核(kernel)。当一个read操作发生时,它会经历两个阶段:
1.通过read系统调用向内核发起读请求。
2.内核向硬件发送读指令,并等待读就绪。
3.DMA把将要读取的数据复制到描述符所指向的内核缓存区中。
4.内核将数据从内核缓存区拷贝到用户进程空间中。
IO的操作方式:
1)同步IO:当用户发出IO请求操作之后,内核会去查看要读取的数据是否就绪,如果数据没有就绪,就一直等待。需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户空间。
2)异步IO:只有IO请求操作的发出是由用户线程来进行的,IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成。也就是说在异步IO中,不会对用户线程产生任何阻塞。
3)阻塞IO:当用户线程发起一个IO请求操作(以读请求操作为例),内核查看要读取的数据还没就绪,当前线程被挂起,阻塞等待结果返回。
4)非阻塞IO:如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当前线程在拿到此次请求结果的过程中,可以做其它事情。
所以Linux系统下根据阻塞与非阻塞,同步与异步实现了五种IO模型:
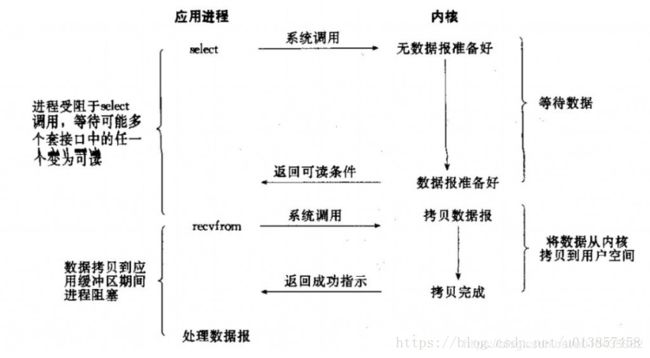
1.同步阻塞I/O模型:在内核将数据准备好之前,系统调用会一直等待所有的套接字,默认的是阻塞方式。
2.同步非阻塞I/O模型:每次客户询问内核是否有数据准备好,即文件描述符缓冲区是否就绪。当有数据报准备好时,就进行拷贝数据报的操作。当没有数据报准备好时,也不阻塞程序,内核直接返回未准备就绪的信号,等待用户程序的下一个轮寻。
3.I/O复用模型:IO多路转接是多了一个select函数,select函数有一个参数是文件描述符集合,对这些文件描述符进行循环监听,当某个文件描述符就绪时,就对这个文件描述符进行处理。
其中,select只负责等,recvfrom只负责拷贝。 IO多路转接是属于阻塞IO,但可以对多个文件描述符进行阻塞监听,所以效率较阻塞IO的高。
IO复用的实现方式目前主要有select、poll和epoll。
select和poll的原理基本相同:
-
注册待侦听的fd(这里的fd创建时最好使用非阻塞)
-
每次调用都去检查这些fd的状态,当有一个或者多个fd就绪的时候返回
-
返回结果中包括已就绪和未就绪的fd
相比select,poll解决了单个进程能够打开的文件描述符数量有限制这个问题:select受限于FD_SIZE的限制,如果修改则需要修改这个宏重新编译内核;而poll通过一个pollfd数组向内核传递需要关注的事件,避开了文件描述符数量限制。
此外,select和poll共同具有的一个很大的缺点就是包含大量fd的数组被整体复制于用户态和内核态地址空间之间,开销会随着fd数量增多而线性增大。
select和poll就类似于上面说的就餐方式。但当你每次都去询问时,老板会把所有你点的饭菜都轮询一遍再告诉你情况,当大量饭菜很长时间都不能准备好的情况下是很低效的。于是,老板有些不耐烦了,就让厨师每做好一个菜就通知他。这样每次你再去问的时候,他会直接把已经准备好的菜告诉你,你再去端。这就是事件驱动IO就绪通知的方式-epoll。
epoll的出现,解决了select、poll的缺点:
-
基于事件驱动的方式,避免了每次都要把所有fd都扫描一遍。
-
epoll_wait只返回就绪的fd。
-
epoll使用nmap内存映射技术避免了内存复制的开销。
-
epoll的fd数量上限是操作系统的最大文件句柄数目,这个数目一般和内存有关,通常远大于1024。
目前,epoll是Linux2.6下最高效的IO复用方式,也是Nginx、Node的IO实现方式。而在freeBSD下,kqueue是另一种类似于epoll的IO复用方式。
此外,对于IO复用还有一个水平触发和边缘触发的概念:
-
水平触发:当就绪的fd未被用户进程处理后,下一次查询依旧会返回,这是select和poll的触发方式。
-
边缘触发:无论就绪的fd是否被处理,下一次不再返回。理论上性能更高,但是实现相当复杂,并且任何意外的丢失事件都会造成请求处理错误。epoll默认使用水平触发,通过相应选项可以使用边缘触发。
4.异步IO:当应用程序调用异步IO读取时,内核一方面去取数据报内容返回,另一方面将程序控制权还给应用进程,应用进程继续处理其他事情,是一种非阻塞的状态。当内核中有数据报就绪时,由内核将数据报拷贝到应用程序中。
5。信号驱动:当数据报准备好的时候,给我发送一个信号,对SIGIO信号进行捕捉,并且调用我的信号处理函数来获取数据报。对比信号驱动IO,异步IO的主要区别在于:信号驱动由内核告诉我们何时可以开始一个IO操作(数据在内核缓冲区中),而异步IO则由内核通知IO操作何时已经完成(数据已经在用户空间中)。
所以Apache和Nginx最大的不同在于它们对连接的处理方式。Apache提供一系列多重处理模块(mpmprefork、mpmworker、mpm_envent),通过这些多重处理模块对进程和线程池进行管理,以多进程或多线程同步、阻塞的方式来使用操作系统的资源,当访问人数过多时容易造成访问过慢。与Apache不同,Nginx的工作是多进程单线程的,通过异步、非阻塞的事件驱动的方式来实现的,使用多进程模式,不仅能提高并发率,而且进程之间相互独立,一个 worker 进程挂了不会影响到其他 worker 进程。
参考:IO原理理解与IO模型 五种IO模型(详解+形象例子说明) IO多路复用
Nginx程序的架构:
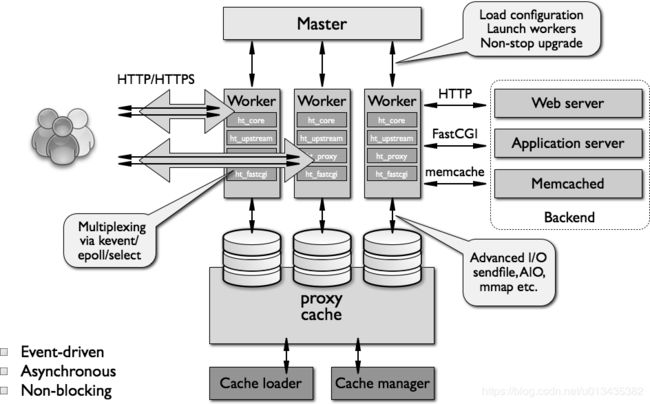
- 3.1master/worker
一个master进程:负责加载和分析配置文件,管理worker进程,平滑升价
一个或多个worker进程:处理并相应客户请求 - 3.2缓存相关的进程:
cache loader:载入缓存对象
cache manager:管理缓存对象 - 3.3特性:异步、事件驱动和非阻塞
并发请求处理:通过epoll/select
文件IO:高级IO sendfile,异步,mmap
nginx模块:高度模块化,但其模块早期不支持DSO机制;近期版本支持动态装载和卸载;
nginx的进程模型分为两级,一个master进程和多个工作进程。master进程用于负载加载和分析配置文件、管理worker进程、平滑升级。woker进程处理并响应用户请求,worker进程在响应用户请求可以通过异步、事件驱动和非阻塞多种方式;与缓存相关的进程用于加载,管理缓存对象。
所以一般会这样做,就是明确指定操作系统使用一个物理核心,然后手动的把其他核心的都绑定到Nginx的work进程上去。这就是Nginx优化之一。这么做就是为了避免切换次数。
Nginx常用模块:
1.核心模块
##查看nginx的主配置文件/etc/nginx/nginx.conf
[root@izwz95rptd09gfx867uwm6z ~]# vim /etc/nginx/nginx.conf
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user nginx; ##进程运行使用的用户和组
worker_processes auto; ##设置nginx的work process的数量,推荐设置为等于或略小
于CPU的核心数,因为若设置为大于CPU的核心数时会产生拥
挤,范围会影响性能,若设置成auto,默认数量为CPU的核心数
error_log /var/log/nginx/error.log;
##错误日志,错误记录等级,等级从低到高为debug, info,notice, warn, error, crit, alert, emerg
例:error_log /var/log/nginx/error.log;
pid /run/nginx.pid; #指定存储nginx主进程号的文件路径
# Load dynamic modules. See /usr/share/nginx/README.dynamic. #指明要装载的动态模块
include /usr/share/nginx/modules/*.conf; #指明包含进来的其他文件类型
#daemon on; #是否已守护进程方式运行Nginx
#master_process on; #是否已master-worker模型运行Nginx,默认on
events { #事件驱动相关配置, 用来指定nginx的工作模式及
连接数上限
use epoll; #指明并发连接请求的处理方式
worker_connections 1024; #每个worker进程能够打开的最大并发连接数
#accpet mutex on | off; #处理新连接的方式,on意味着由每个worker轮流处理新请
求,off意味着每个新请求到达都会通知所有worker进程.
}
性能调优
worker_processes number | auto;
##worker进程的数量;通常应该为当前主机的cpu的物理核心数
worker_cpu_affinity auto [cpumask] ##将work进程绑定在固定cpu上提高缓存命中率
例:
worker_cpu_affinity 0001 0010 0100 1000; # 将worker进程固定在指定的CPU(或核心)中,因为 nginx
默认是随机分配cpu(或核心)的,此设置可将 nginx进程固
定在指定的CPU(或核心)上,以加快处理速度降低出错率。
worker_priority number
##指定worker进程的nice值,设定worker进程优先级: [-20,20], nginx默认状态下的nice值为0
worker_rlimit_nofile number
##worker进程所能够打开的文件数量上限,默认较小,生产中需要调大如65535
master_process on | off; ##确认master process的开启状态。
multi_accept on | off; #Context:events
当multi_accept为on时,所有的新连接情求将同时被worker process同时接收处理,当multi_accept为off时,worker process一次只接收处理一个新连接默认为off
pid ##设置nginx主进程ID文件位置
例:pid log/nginx.pid;
2.http核心模块相关配置ngx_http_core_module
web服务模板
server { ... }
配置一个虚拟主机
server {
listen address[:PORT]|PORT; #设置监听IP的地址和端口,一般只需设置ip和端口
server_name SERVER_NAME; 设置虚拟主机的主机名,可使用正则表达式进行匹配
root /PATH/TO/DOCUMENT_ROOT;
}
##配置虚拟机有三种方式
(1) 基于port;
listen PORT; 指令监听在不同的端口
(2) 基于ip的虚拟主机
listen IP:PORT; IP 地址不同
(3) 基于hostname
server_name fqdn; 指令指向不同的主机名
套接字相关配置
##listen address[:port] 的扩展设置
listen address[:port] [default_server] [ssl] [http2 | spdy] [backlog=number] [rcvbuf=size] [sndbuf=size]
default_server 设定为默认虚拟主机
ssl 限制仅能够通过ssl连接提供服务
backlog=number 超过并发连接数后,新请求进入后援队列的长度
rcvbuf=size 接收缓冲区大小
sndbuf=size 发送缓冲区大小
例:
listen 127.0.0.1:8000;
listen 127.0.0.1;
listen 8000;
listen *:8000;
listen localhost:8000;server_name
server_name name ...;
支持*通配任意长度的任意字符
server_name *.magedu.com www.magedu.*
支持~起始的字符做正则表达式模式匹配,性能原因慎用
server_name ~^www\d+\.magedu\.com$ #\d 表示 [0-9]
匹配优先级机制从高到低:
(1) 首先是字符串精确匹配 如: www.magedu.com
(2) 左侧*通配符 如: *.magedu.com
(3) 右侧*通配符 如: www.magedu.*
(4) 正则表达式 如: ~^.*\.magedu\.com$
(5) default_server
设置虚拟主机的主机名,可使用正则表达式进行匹配
例:server {
server_name ~^(www\.)?(.+)$;
index index.php index.html;
root /nginx/$2;
}
这里用到了正则表达式后向引用的知识,可以实现在一个server中配置多个站点,
当输入站点www.fff.com时对应站点的主目录为/nginx/fff.com目录
当输入站点www.ddd.org时对应站点的主目录为/nginx/ddd.com目录
目录必须存在性能选项:
tcp_nodelay on | off;
tcp_nopush on | off;
在keepalived模式下的连接是否启用TCP_NODELAY选项
当为off时,延迟发送,合并多个请求后再发送
默认On时,不延迟发送
可用于: http, server, location
sendfile on | off;
是否启用sendfile功能,在内核中封装报文直接发送
默认Off
server_tokens on | off | build | string
是否在响应报文的Server首部显示nginx版本
location匹配
location [ = | ~ | ~* | ^~ ] uri { ... }
location @name { ... }
在一个server中location配置段可存在多个,用于实现从uri到文件系统的路径映射; ngnix会根据
用户请求的URI来检查定义的所有location,并找出一个最佳匹配,而后应用其配置
示例:
server {...
server_name www.magedu.com;
location /images/ {
root /data/imgs/;
}
}
http://www.magedu.com/images/logo.jpg --> /data/imgs/images/logo.jpg
=:对URI做精确匹配;
^~:对URI的最左边部分做匹配检查,不区分字符大小写
~:对URI做正则表达式模式匹配,区分字符大小写
~*:对URI做正则表达式模式匹配,不区分字符大小写
不带符号:匹配起始于此uri的所有的uri
匹配优先级从高到低:
=, ^~, ~/~*, 不带符号路径别名alias path
alias #Context:location
alias表示路径别名,alias后面接路径,也就是用户访问的真正路径,一般用在location环境下
例:location /i/ {
alias /data/w3/images/; #一定要记得结尾加/
}
当用户请求为路径URI/i/时,实际访问的是URI/data/w3/images/
示例:
http://www.magedu.com/bbs/index.php
location /bbs/ {
alias /web/forum/;
} --> /web/forum/index.html
location /bbs/ {
root /web/forum/;
} --> /web/forum/bbs/index.html
注意: location中使用root指令和alias指令的意义不同
(a) root,相当于追加在root目录后面
(b) alias,相当于对location中的url进行替换
此处可深入对比root与alias的区别:
1.root指定的是location匹配访问的path目录的上一级目录,也可以理解为location匹配访问的起始根目录
2.alias指定的是location匹配访问的path目录的真正目录路径,而location后是path目录别名
3.对于root来说,location后的path目录必须真实存在
4.对于alias来说,location后的path目录可以不存在
5.alias只能用在location中,而root可用在 http,server,location,if in location中
6.有网友建议错误页面设置:
error_page code ... [=[response]] uri;
模块: ngx_http_core_module
定义错误页, 以指定的响应状态码进行响应
可用位置: http, server, location, if in location
error_page 404 /404.html
error_page 404 =200 /404.html #防止404页面被劫持长连接相关设置:
keepalive_timeout timeout [header_timeout]
设定保持链接超时时长,0表示禁止长连接,默认为75s
keepalive_requests number ##再一次长连接上所允许请求的最大资源数量,默认为100
keepalive_diasble none | browser ##对那种浏览器禁止使用长连接
send_timeout time ##向客户端发送响应报文的超时时长,指两次报文之间的间隔,而非整个相应过程时间
请求报文缓存:
client_body_buffer_size size;
用于接收每个客户端请求报文的body部分的缓冲区大小;默认为16k;超出此大小时,
其将被暂存到磁盘上的由client_body_temp_path指令所定义的位置
client_body_temp_path path [level1 [level2 [level3]]];
设定用于存储客户端请求报文的body部分的临时存储路径及子目录结构和数量
目录名为16进制的数字;
client_body_temp_path /var/tmp/client_body 1 2 2
1 1级目录占1位16进制,即2^4=16个目录 0-f
2 2级目录占2位16进制,即2^8=256个目录 00-ff
2 3级目录占2位16进制, 即2^8=256个目录 00-ff
aio on|off ##aio是指异步非阻塞IO模型客户端访问限制相关配置:
limit_rate rate;
限制响应给客户端的传输速率,单位是bytes/second 默认值0表示无限制
limit_except method ... { ... },仅用于location
限制客户端使用除了指定的请求方法之外的其它方法
method:GET, HEAD, POST, PUT, DELETE,MKCOL, COPY, MOVE, OPTIONS, PROPFIND,
PROPPATCH, LOCK, UNLOCK, PATCH
例:
limit_except GET {
allow 192.168.1.0/24;
deny all;
}
除了GET和HEAD 之外其它方法仅允许192.168.1.0/24网段主机使用3. 访问控制模块ngx_http_access_module
基于ip的访问控制功能
allow address | CIDR | UNIX: | all;
deny address | CIDR | unix: | all;
http, server, location, limit_except
自上而下检查,一旦匹配,将生效,条件严格的置前
示例:
location / {
deny 192.168.1.1;
allow 192.168.1.0/24;
allow 2001:0db8::/32
deny all;
}4.用户认证模块ngx_http_auth_basic_module
实现基于用户的访问控制,使用basic机制进行用户认证
auth_basic #Context:http, server, location, limit_except
##反馈给用户的服务器认证信息,必须与auth_basic_user_file配合使用
auth_basic_string | off;
auth_basic_user_file file;
设置用户认证文件的路径,配置用户认证的用户名与密码可用httpd-tools来实现
1.yum -y install httpd-tools #安装httpd-tools
2.htpasswd -c -m /etc/nginx/.ngxpwd ready #指定密码文件路径与文件名,用户名为ready
server {
server_name www.hhh.com;
root /nginx/test2/;
location ~* ^/(login|admin) {
#alias /admin/; #为何加此项会访问不成功,改为location /login/却会访问成功?
auth_basic "why?";
auth_basic_user_file /etc/nginx/.ngxpwd;
} #root路径下用户请求以admin或login开头时,都会出现用户认证
用户口令:
1、明文文本:格式name:password:comment
2、加密文本:由htpasswd命令实现 httpd-tools所提供
htpasswd [-c第一次创建时使用] [-D删除用户] passwdfile username5. 状态查看模块ngx_http_stub_status_module
用于输出nginx的基本状态信息
Active connections:当前状态,活动状态的连接数
accepts:统计总值,已经接受的客户端请求的总数
handled:统计总值,已经处理完成的客户端请求的总数
requests:统计总值,客户端发来的总的请求数
Reading:当前状态,正在读取客户端请求报文首部的连接的连接数
Writing:当前状态,正在向客户端发送响应报文过程中的连接数
Waiting:当前状态,正在等待客户端发出请求的空闲连接数
示例:
location /abc {
stub_status;
auth_basic "why?";
auth_basic_user_file /etc/nginx/.ngxpwd;
}
输出示例:
Active connections: 3 #当前的活动链接数
server accepts handled requests #accept已经接受的用户请求数,handled已经处理完成的用户请求数,requests总请求数 303 303 2533
Reading: 0 Writing: 1 Waiting: 2 #Reading:处于读取客户端请求报文首部的连接的连接数;
#Writing:处于向客户端发送响应报文过程中的连接数;
#Waiting:处于等待客户端发出请求的空闲连接数6. 日志记录模块ngx_http_log_module
log_format name string ... ##string可以使用nginx核心模块及其它模块内嵌的变量
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]];
##访问日志文件路径,格式及相关的缓冲的配置
access_log off;
列如:
log_format compression 'remote_addr-$remote_user [$time_local]'
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" "$gzip_ratio"';
access_log /spool/logs/nginx-access.log compression buffer=32k;
json格式日志示例;log_format json '{"@timestamp":"$time_iso8601",'
'"client_ip":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"method":"$request_method",'
'"request_uri":"$request_uri",'
'"xff":"$http_x_forwarded_for",'
'"referrer":"$http_referer",'
'"agent":"$http_user_agent",'
'"status":"$status"}';
open_log_file_cache max=N [inactive=time] [min_uses=N] [valid=time];
##缓存各日志文件相关的元数据信息
open_log_file_cache off;
max:缓存的最大文件描述符数量
min_uses:在inactive指定的时长内访问大于等于此值方可被当作活动项
inactive:非活动时长
valid:验正缓存中各缓存项是否为活动项的时间间隔
例: open_log_file_cache max=1000 inactive=20s valid=1m;7. 压缩相关选项ngx_http_gzip_module
gzip on | off; #启用或禁用gzip压缩
gzip_comp_level level; #压缩比由低到高: 1 到 9 默认: 1
gzip_disable regex ...; #匹配到客户端浏览器不执行压缩
gzip_min_length length; #启用压缩功能的响应报文大小阈值
gzip_http_version 1.0 | 1.1; #设定启用压缩功能时,协议的最小版本 默认: 1.1
gzip_buffers number size; #支持实现压缩功能时缓冲区数量及每个缓存区的大小 默认: 32 4k 或 16 8k
gzip_types mime-type ...; #指明仅对哪些类型的资源执行压缩操作;即压缩过滤器
gzip_vary on | off; #如果启用压缩,是否在响应报文首部插入“Vary: AcceptEncoding
gzip_proxied off | expired | no-cache | no-store |
private | no_last_modified | no_etag | auth | any ...;
##nginx对于代理服务器请求的响应报文,在何种条件下启
##用压缩功能
##off:对被代理的请求不启用压缩
##expired,no-cache, no-store, private:对代理服务器请求的响应报文首部Cache-Control值任何一个,启用压缩功能
8. https模块ngx_http_ssl_module模块:
ssl on | off; ##为指定虚拟机启用HTTPS protocol, 建议用listen指令代替
ssl_certificate file; ##当前虚拟主机使用PEM格式的证书文件
ssl_certificate_key file; #当前虚拟主机上与其证书匹配的私钥文件
ssl_protocols [SSLv2] [SSLv3] [TLSv1] [TLSv1.1] [TLSv1.2]; #支持ssl协议版本,默认为后三个
ssl_session_cache off | none | [builtin[:size]] [shared:name:size];
builtin[:size]: #使用OpenSSL内建缓存,为每worker进程私有
[shared:name:size]:#在各worker之间使用一个共享的缓存
ssl_session_timeout time; #客户端连接可以复用ssl session cache中缓存的ssl参数的有效时长,默认5m
示例:
server{
listen 443 ssl;
server_name www.baidu.com;
root /vhosts/ssl/htdocs;
ssl on;
ssl_certificate /etc/nginx/ssl/nginx.crt;
ssl_certificate_key /etc/nginx/ssl/nginx.key;
ssl_session_cache shared:sslcache:20m;
ssl_session_timeout 10m;
}9.重定向模块ngx_http_rewrite_module:
根据用户请求的URL按一定规则进行重新替换或定向,使用户请求跳转至规则定制的URLrewrite regex replacement [flag] #将用户请求的URI基于regex所描述的模式进行检查,匹配到时将其替 换为replacement指定的新的URI,其中加入在同一级配置块中存在多个rewrite规则,那么会自上而下逐个检查;被某条件规则替换完成后,会重新一轮的替换检查。隐含有循环机制,但不超过10次;如果超过,提示500响应码
[flag]所表示的标志位用于控制此循环机制
##如果replacement是以http://或https://开头,则替换结果会直接以重向返回给客户端
当flag为 last时 ##重写完成后停止对当前URI在当前location中后续的其它重写操作,而后对新的URI启动新一轮重写检查;提前重启新一轮循环
break:重写完成后停止对当前URI在当前location中后续的其它重写操作,而后直接跳转至重写规则配置块之后的其它配置;结束循环,建议在location中使用
redirect:临时重定向,重写完成后以临时重定向方式直接返回重写后生成的新URI给客户端,由客户端重新发起请求;不能以http://或https://开头,使用相对路径,状态码: 302
permanent:重写完成后以永久重定向方式直接返回重写后生成的新URI给客户端,由客户端重新发起请求,状态
码:301
例:
rewrite ^/xcx/(.*\.html)$ /mageedu/$1 break;
rewrite ^/xcx/(.*\.html)$ https://www.dianping/mageedu/$1 permanent;
return ##停止处理,并返回给客户端指定的响应码
return code [text];
return code URL;
return URL;
rewrite_log on | off; #是否开启重写日志, 发送至error_log(notice level)
set $variable value; #用户自定义变量
if (condition) {...}
引入新的上下文,条件满足时,执行配置块中的配置指令; server, location
condition #比较操作符
== 相同
!= 不同
~:模式匹配,区分字符大小写
~*:模式匹配,不区分字符大小写
!~:模式不匹配,区分字符大小写
!~*:模式不匹配,不区分字符大小写
文件及目录存在性判断:
-e, !-e 存在(包括文件,目录,软链接)
-f, !-f 文件
-d, !-d 目录
-x, !-x 执行
例子
if ($http_user_agent ~ Chrom){
rewrite ^(.*)$ /chrome/$1 break;
}
if ($http_user_agent ~ MSIE) {
rewrite ^(.*)$ /IE/$1 break;
}
##根据浏览器类型进行访问地址的分流
10. 引用模块ngx_http_referer_module
#再打开某些网站时,会出现类似"此图片仅允许xx网内部使用"的图片提示,这就是基于此模块来实现防盗链的一种方法valid_referers none|blocked|server_names|string ...;
##定义referer首部的合法可用值,不能匹配的将是非法值
none:请求报文首部没有referer首部
blocked:请求报文有referer首部,但无有效值
server_names:参数,其可以有值作为主机名或主机名模式
arbitrary_string:任意字符串,但可使用*作通配符
regular expression:被指定的正则表达式模式匹配到的字符
串,要使用~开头,例如: ~.*\.magedu\.com
例:
valid_referers none block server_names *.magedu.com
*.mageedu.com magedu.* mageedu.* ~\.magedu\.;
if ($invalid_referer) {
return 403;
}11.反向代理模块ngx_http_proxy_module
proxy_pass URL; ##proxy_pass后面的路径不带uri时,其会将location的uri传递给后端主机
例如:
server {
...
server_name HOSTNAME;
location /uri/ {
proxy_pass http://host[:port];
}
...
}
##反代结果 http://HOSTNAME/uri --> http://host/uri 其中当http://host[:port]/ 意味着: http://HOSTNAME/uri --> http://host/
如果location定义其uri时使用了正则表达式的模式,则proxy_pass之后必须不能使用uri; 用户请求时传递的uri将直接附加代理到的服务的之后
例如:
server {
...
server_name HOSTNAME;
location ~|~* /uri/ {
proxy_pass http://host; 不能加/
}
...
}
反代结果:http://HOSTNAME/uri/ --> http://host/uri/
proxy_set_header field value; ##设定发往后端主机的请求报文的请求首部的值
后端记录日志记录真实请求服务器IP
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
标准格式如下:
X-Forwarded-For: client1, proxy1, proxy2
如后端是Apache服务器应更改日志格式:
%h -----> %{X-Real-IP}i
proxy_cache_path; ##定义可用于proxy功能的缓存;
proxy_cache_path path [levels=levels] [use_temp_path=on|off]
keys_zone=name:size [inactive=time] [max_size=size]
[manager_files=number] [manager_sleep=time]
[manager_threshold=time] [loader_files=number] [loader_sleep=time]
[loader_threshold=time] [purger=on|off] [purger_files=number]
[purger_sleep=time] [purger_threshold=time];
例:
proxy_cache_path /data/nginx/cache(属主要为nginx)
levels=1:2keys_zone=nginxcache:20m inactive=2m
proxy_cache zone | off; ##调用缓存,默认off;
指明调用的缓存,或关闭缓存机制; Context: http,server, location
proxy_cache_key string; ##缓存中用于“键”的内容,默认值: proxy_cache_key
$scheme$proxy_host$request_uri;
proxy_cache_valid [code ...] time; ##定义对特定响应码的响应内容的缓存时长定义在http{...}中
例如:
proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
在http配置定义缓存信
proxy_cache_path /var/cache/nginx/proxy_cache
levels=1:1:1 keys_zone=proxycache:20m
inactive=120s max_size=1g;
调用缓存功能,需要定义在相应的配置段,如server{...};
proxy_cache proxycache;
proxy_cache_key $request_uri;
proxy_cache_valid 200 302 301 1h;
proxy_cache_valid any 1m;
proxy_cache_use_stale; ##指令开启容错能力,即使用缓存内容来响应客户端的请求
proxy_cache_use_stale error | timeout |
invalid_header | updating | http_500 | http_502 |
http_503 | http_504 | http_403 | http_404 | off ...
##在被代理的后端服务器出现哪种情况下,可以直接使用过期的缓存响应客户端
proxy_cache_methods GET | HEAD | POST ...;##对哪些客户端请求方法对应的响应进行缓存
proxy_hide_header field;##用于隐藏后端服务器特定的响应首部
proxy_connect_timeout time; ##定义与后端服务器建立连接的超时时长,如超时会出现502错误,默认为60s,一般不建议超出75s
proxy_send_timeout time; ##把请求发送给后端服务器的超时时长;默认为60s
proxy_read_timeout time; ##等待后端服务器发送响应报文的超时时长, 默认为60s
add_header name value [always]; ##添加自定义首部
add_header X-Via $server_addr;
add_header X-Cache $upstream_cache_status;
add_header X-Accel $server_name;
add_trailer name value [always];
添加自定义响应信息的尾部
13. hph 相关模块ngx_http_fastcgi_module
nginx代理通过ngx_http_fastcgi_module这个模块,将收到php程序的请求后就转发到后台FastCGI服务器处理,这里nginx可以把php-fpm服务运行在同一机器上,也可以将nginx和php-fpm分离在两台机器上。但是,nginx不支持php模块方式,只能是php-fpm模式。
fastcgi_pass address; ##address为后端的fastcgi server的地址,可用位置:location,if in location
fastcgi_index name; ##fastcgi默认的主页资源
示例: fastcgi_index index.php;
fastcgi_index name; ##fastcgi默认的主页资源
示例: fastcgi_index index.php;
fastcgi_param parameter value [if_not_empty];##设置传递给 FastCGI服务器的参数值,可以是文本,变
量或组合
示例1:
location ~* \.php$ {
fastcgi_pass 后端fpm服务器IP:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /usr/share/nginx/html$fastcgi_script_name;
include fastcgi.conf;
…
}
##在后端服务器先配置fpm server和mariadb-server,在前端nginx服务上做配置
示例2:
location ~* ^/(status|ping)$ {
include fastcgi_params;
fastcgi_pass 后端fpm服务器IP:9000;
fastcgi_param SCRIPT_FILENAME $fastcgi_script_name;
include fastcgi.conf;
}
#通过/pm_status和/ping来获取fpm server状态信息(真实服务器端php-fpm配置文件中将这两项
#注释掉)
fastcgi 缓存相关:
fastcgi_cache_path path [levels=levels] [use_temp_path=on|off]
keys_zone=name:size [inactive=time] [max_size=size]
[manager_files=number] [manager_sleep=time] [manager_threshold=time]
[loader_files=number] [loader_sleep=time] [loader_threshold=time]
[purger=on|off] [purger_files=number] [purger_sleep=time]
[purger_threshold=time];
定义fastcgi的缓存;
path 缓存位置为磁盘上的文件系统
max_size=size ##磁盘path路径中用于缓存数据的缓存空间上限
levels=levels:##缓存目录的层级数量,以及每一级的目录数量
levels=ONE:TWO:THREE
示例: leves=1:2:2
keys_zone=name:size ## k/v映射的内存空间的名称及大小
inactive=time ##非活动时长
fastcgi_cache zone | off; ##调用指定的缓存空间来缓存数据,可用位置: http, server, location
fastcgi_cache_key string; ##定义用作缓存项的key的字符串
fastcgi_cache_methods GET | HEAD | POST ...; ##为哪些请求方法使用缓存
fastcgi_cache_min_uses number; ##缓存空间中的缓存项在inactive定义的非活动时间内至少要被访问到
fastcgi_keep_conn on | off; ##收到后端服务器响应后, fastcgi服务器是否关闭连接,建议启用长连接
fastcgi_cache_valid [code ...] time;##不同的响应码各自的缓存时长
14.代理模块ngx_http_upstream_module模块
用于将多个服务器定义成服务器组,而由proxy_pass,fastcgi_pass等指令进行引用
upstream name { ... } ##定义后端服务器组,会引入一个新的上下文
默认调度算法是wrr
upstream httpdsrvs {
server ...
server...
...
}
例如:
upstream upservers{
server 192.168.1.1;
server 192.168.1.2;
}##因为如果后端主机与nginx主机监听端口相同可以不写端口,否则需要指明后端主机的监听端口。
##在location的proxy_pass部分调用
location /{
proxy_pass http://upservers/;
...
}
server address [parameters];
在upstream上下文中server成员,以及相关的参数; Context:upstreamaddress的表示格式:
unix:/PATH/TO/SOME_SOCK_FILE
IP[:PORT]
HOSTNAME[:PORT]
parameters:
weight=number 权重,默认为1
max_conns 连接后端报务器最大并发活动连接数, 1.11.5后支持
max_fails=number 失败尝试最大次数;超出此处指定的次数时
server将被标记为不可用,默认为1
fail_timeout=time 后端服务器标记为不可用状态的连接超时时
长,默认10s
backup 将服务器标记为“备用”,即所有服务器均不可用时才启用
down 标记为“不可用”,配合ip_hash使用,实现灰度发布
ip_hash ##源地址hash调度方法
least_conn ##最少连接调度算法,当server拥有不同的权重时其为wlc,当所有后端主机连接数相同时,
则使用wrr,适用于长连接
hash key [consistent] #基于指定的key的hash表来实现对请求的调度,此处的key可以直接文本、变量或二者组合
作用:将请求分类,同一类请求将发往同一个upstream
server,使用consistent参数, 将使用ketama一致性hash算法,
适用于后端是Cache服务器(如varnish)时使用
hash $request_uri consistent;
hash $remote_addr;
keepalive 连接数N;为每个worker进程保留的空闲的长连接数量,可节约nginx端口,并减少连接管理的消耗
health_check [parameters]; ##健康状态检测机制;只能用于location上下文
常用参数:
interval=time检测的频率,默认为5秒
fails=number:判定服务器不可用的失败检测次数;默认为1次
passes=number:判定服务器可用的失败检测次数;默认为1次
uri=uri:做健康状态检测测试的目标uri;默认为/
match=NAME:健康状态检测的结果评估调用此处指定的match配置块
注意:仅对nginx plus有效
match name { ... } ##对backend server做健康状态检测时,定义其结果判断机制;
只能用于http上下文常用的参数:
status code[ code ...]: 期望的响应状态码
header HEADER[operator value]:期望存在响应首
部,也可对期望的响应首部的值基于比较操作符和值进行比较
body:期望响应报文的主体部分应该有的内容
注意:仅对nginx plus有效
15.模拟反代基于tcp或udp的服务连接,即工作于传输层的反代或调度器
模拟反代基于tcp或udp的服务连接,即工作于传输层的反代或调度器
stream { ... }
定义stream相关的服务; Context:main
stream {
upstream telnetsrvs {
server 192.168.22.2:23;
server 192.168.22.3:23;
least_conn;
}
server {
listen 10.1.0.6:23;
proxy_pass telnetsrvs;
}
}
listen address:port [ssl] [udp] [proxy_protocol]
[backlog=number] [bind] [ipv6only=on|off] [reuseport]
[so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]];
16. ngx_stream_proxy_module模块
可实现代理基于TCP, UDP (1.9.13), UNIX-domain
sockets的数据流
1 proxy_pass address;
指定后端服务器地址
2 proxy_timeout timeout;
无数据传输时,保持连接状态的超时时长
默认为10m
3 proxy_connect_timeout time;
设置nginx与被代理的服务器尝试建立连接的超时时长
默认为60s
例如:
stream {
upstream telnetsrvs {
server 192.168.10.130:23;
server 192.168.10.131:23;
hash $remote_addr consistent;
}
server {
listen 172.16.100.10:2323;
proxy_pass telnetsrvs;
proxy_timeout 60s;
proxy_connect_timeout 10s;
}
参考:深入NGINX:nginx高性能的实现原理 Nginx 架构 Nginx 架构——【核心流程+模块介绍】
二.简述Linux集群类型、系统扩展方式及调度方法
什么是Linux集群
Linux cluster,Linux集群系统是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。一个集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算机系统就是集群的节点(node)。一个理想的集群,用户是不会意识到集群系统底层的节点的。在他们看来,集群是一个系统,而非多个计算机系统。并且集群系统的管理员可以随意增加和删改集群系统的节点。
Linux集群的类型
LB负载均衡集群(LoadBalance):
当我们把业务中一些关键服务分离出来放入一台主机时,这台主机如果在高负载的情况下发生了故障会导致整个业务不可用,对这些单点服务器我们需要做冗余,需要把用户的请求分散到多台相同业务的主机上。而用来分散用户请求的设备称之为负载均衡器,也称分发器、调度器。当集群中存在负载均衡器就叫做LB集群。
LB的分类:
(1).硬件LB
F5 公司的 BIG-IP系列
Citrix 公司的 NetScaler系列
A10 公司的 AX系列(2).软件LB
四层:LVS(Linux Virtual Server)
七层:Nginx,HAProxyHA高可用集群(High Availiablity,高可用):一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上。还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行。既思想就是要最大限度地减少服务中断时间。这类集群中比较著名的有Turbolinux TurboHA、Heartbeat、keepalived等。
HA三种工作方式:
(1)主从方式 (非对称方式)
工作原理:主机工作,备机处于监控准备状况;当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动或手动方式将服务切换到主机上运行,数据的一致性通过共享存储系统解决。
(2)双机双工方式(互备互援)
工作原理:两台主机同时运行各自的服务工作且相互监测情况,当任一台主机宕机时,另一台主机立即接管它的一切工作,保证工作实时,应用服务系统的关键数据存放在共享存储系统中。
(3)集群工作方式(多服务器互备方式)
工作原理:多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管。
HP集群(:High-PerformanceComputingCluster,高性能计算集群):是指以提高科学计算能力为目的计算机集群技术。HPC Cluster是一种并行计算(Parallel Processing)集群的实现方法。
分布式集群
分布式集群分为两种
- 分布式存储
当存储一个较大数据集,单台主机的网络IO和磁盘IO都无法承载,找一台主机实现分发调度,再把数据分发到一堆服务器上来实现存储。当一堆人要存储很多数据时,这台分发器把不同的人分散到不同的服务器上去进行存储。这台分发服务器存储了所有数据的索引,叫做元数据服务器namenode,存储数据的服务器叫做数据节点datanode,这些称之为分布式存储集群,如HDFS、Ceph、GFS、Switf等。 - 分布式计算
当我们需要做一个大量的计算任务时,对一个社交网站来说,日志访问有300亿条,想要查出300亿条中排名前100的有哪些。把大任务切成小任务,把300亿条数据分成每3亿个一份,时间就可以缩短到1/100。第一台服务器的结果,和所有其他服务器的结果在做第二次计算。如果还没有解决问题,就把大文件继续分割下去,把一个大问题分成中问题,把一个中问题分成小问题。把大问题分割成很多小问题叫做分布式计算集群。
参考:Linux 高可用(HA)集群基本概念详解 主流分布式存储技术的对比分析与应用
三.简述lvs四种集群有点及使用场景
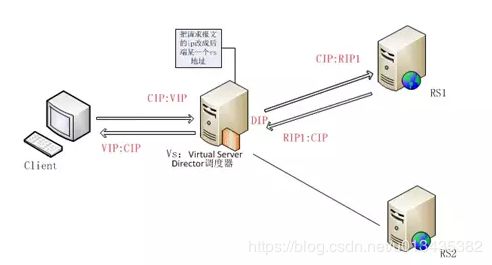
LVS:Linux virtual server,是工作在四层的负载均衡程序,由于在四层无需进入用户空间,所以也就无需监听套接字,不受端口数量的限制,对于用不起F5,但并发数又很大的企业可以使用。
VS:Virtual Server调度器,VS有两个地址:面向客户端的地址叫VIP,面向后端主机的地址叫DIP,RS的地址叫RIP,客户端的地址叫CIP。
RS: Real Server后端服务器
l4:四层交换机,四层路由器。
VS:根据请求报文的目标IP和目标协议及端口将其调度转发至某RealServer,根据调度算法来挑选RS。
iptables/netfilter:
iptables:用户控件的管理工具
netfilter:内核空间上的框架
流入:PREROUTING---> INPUT
流出:OUTPUT---> POSTROUTING;
转发:PREOUTING---> FORWARD---> POSTROUTING
DNAT:目标地址转换;PREROUTING;
SNAT:源地址转换;POSTROUTING;
lvs:ipvsadm/ipvs
ipvsadm:用户空间的命令行工具,规则管理器,用于管理集群服务及相关的RealServer;
ipvs:工作与内核空间的netfilter的INPUT钩子之上的框架。
lvs集群的类型:
- lvs-nat:修改请求报文的目标IP;多目标IP的DNAT;多目标IP的DNAT,通过将请求报文中的目标地址和目标端口修改为所选的RS的RIP和PORT实现转发; 根据iptables中提到过的架构netfilter,用户报文到达INPUT链,查看是否匹配得到ipvs中的规则,匹配到的话转换其目标IP地址并发送给后端服务器,后端服务器处理完毕后必须将报文发回给调度器,所以调度器的DIP必须为后端主机的网关,调度器会再次改变源IP地址并发给用户,整个过程中用户默认是不知道任何关于后端服务器的信息的,其中VIP一般为公网地址,而DIP和RIP是位于同一网段的私网地址。
(1)RIP和DIP必须在同一个IP网络,且应该使用私网地址;RS的网关要指向DIP;
(2)请求报文和响应报文都必须经由Director转发;Director易于成为系统瓶颈;
(3)支持端口映射,可修改请求报文的目标PORT;
(4)vs必须是Linux系统,rs可以是任意系统;
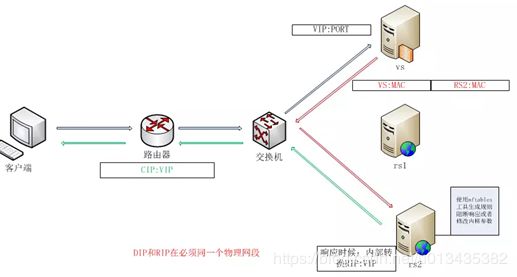
- lvs-dr:操纵封装新的MAC地址;通过为请求报文重新封装一个MAC首部进行转发,源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS的RIP所在接口的MAC地址;源IP/PORT,以及目标IP/PORT均保持不变;Director和各RS都得配置使用VIP。在前一种工作类型中,调度器的压力极大,因为所有的报文都要通过其Director,lvs-dr类型通过特殊结构,让后端服务器在回包时可以直接找到客户。首先RS与VS在同一交换机上,RIP与DIP位于同一网段且都是公网地址,然后将VIP设置于各台主机的虚拟接口上,如lo0、物理接口:0等,再关闭RS的ARP通告和ARP响应,这样当客户把报文发给VIP并到交换机时,自然会找到VS了,因为只有VS响应此ARP请求。VS查看ipvs规则,不会去修改目的IP地址,而是修改源目MAC地址将其转发给后端服务器,由于后端服务的虚拟接口上有VIP,所以其也会接受报文并做出响应,此响应报文是要直接发给客户的,所以一定要让回包的源地址为RS的VIP,这样就有效减轻了调度器的负担了。
(1) 确保前端路由器将目标IP为VIP的请求报文发往Director:
(a) 在前端网关做静态绑定; (b) 在RS上使用arptables; (c) 在RS上修改内核参数以限制arp通告及应答级别; arp_announce arp_ignore
(2) RS的RIP可以使用私网地址,也可以是公网地址;RIP与DIP在同一IP网络;RIP的网关不能指向DIP,以确保响应报文不会经由Director;
(3) RS跟Director要在同一个物理网络;
(4) 请求报文要经由Director,但响应不能经由Director,而是由RS直接发往Client;
(5) 不支持端口映射;
- lvs-tun:在原请求IP报文之外新加一个IP首部;转发方式:不修改请求报文的IP首部(源IP为CIP,目标IP为VIP),而是在原IP报文之外再封装一个IP首部(源IP是DIP,目标IP是RIP),将报文发往挑选出的目标RS;RS直接响应给客户端(源IP是VIP,目标IP是CIP); lvs-tun类型是通过隧道技术,让分隔两地的主机也能作为集群工作。和lvs-dr类型相似,也是请求报文经过vs,响应报文有后端服务器直接发给用户,但不用限制ARP了。在用户报文到达VS后,VS会在二层帧头和三层报头之间添加一个IP报头,将源目地址设为DIP与RIP并发给RS,RS收到后先拆开第一层IP报头,知道是lvs-tun模型,再拆第二层,也就是真正的IP报头,获得客户CIP,做出响应时就以源VIP,目CIP发送报文,此模型在生产环境中不多见。
(1) DIP, VIP, RIP都应该是公网地址;
(2) RS的网关不能,也不可能指向DIP;
(3) 请求报文要经由Director,但响应不能经由Director;
(4) 不支持端口映射;
(5) RS的OS得支持隧道功能;
- lvs-fullnat:通过同时修改请求报文的源IP地址和目标IP地址进行转发;在无需大费周章的使用隧道技术的情况下,跨越网段部署lvs。其不是标准类型,需要编译安装。工作原理和nat一样,只是vs在转换时,不仅能改变目标地址,也能改变源地址,把源地址改为DIP,这样RS在回包时会按图索骥找到DIP,VS再将其转换回CIP并发送给客户,这样就可以在客户和RS都不知道对方的情况下,在VS的掌控下进行通信了。但VS的压力依然巨大,而且安装起来不是很方便,所以使用的也不多。
(1) VIP是公网地址,RIP和DIP是私网地址,且通常不在同一IP网络;因此,RIP的网关一般不会指向DIP;
(2) RS收到的请求报文源地址是DIP,因此,只能响应给DIP;但Director还要将其发往Client;
(3) 请求和响应报文都经由Director;
(4) 支持端口映射; 注意:此类型默认不支持;
总结
lvs-nat, lvs-fullnat:请求和响应报文都经由Director; lvs-nat:RIP的网关要指向DIP; lvs-fullnat:RIP和DIP未必在同一IP网络,但要能通信; lvs-dr, lvs-tun:请求报文要经由Director,但响应报文由RS直接发往Client; lvs-dr:通过封装新的MAC首部实现,通过MAC网络转发; lvs-tun:通过在原IP报文之外封装新的IP首部实现转发,支持远距离通信。
四.描述LVS-NAT、LVS-DR的工作原理并实现配置
先安装ipvsadm工具,这个工具能帮我们把生成的规则送给内核yum install -y ipvsadm
ipvsadm:
- 主程序:/usr/sbin/ipvsadm
- 规则保存工具:/usr/sbin/ipvsadm-save
- 规则重载工具:/usr/sbin/ipvsadm-restore
- 配置文件:/etc/sysconfig/ipvsadm-config
grep -i "ipvs" -C 10 /boot/config-3.10.0-229.el7.x86_64
查看内核是否支持ipvs功能
环境准备:
lvs-nat:准备三台主机,一台作为调度器,拥有两块网卡,一块配置vip,一块配置dip;两台作为后端服务器,配置rip,与dip在同一网段,但与vip不在同一网段,并且两台服务器上都准备好相同的web服务,为了测试,准备两张名字相同,内容不同的页面。
主机1:vip:10.0.0.1/dip:192.168.10.1
主机2:rip:192.168.10.2
主机3:rip:192.168.10.3
然后我们就可以在lvs负载均衡的主机1上做规则了
ipvsadm -A -t 10.0.0.1.200:80 -s rr #添加VIP并且设置调度算法为rr
ipvsadm -a -t 10.0.0.1:80 -r 192.168.10.2 -m
ipvsadm -a -t 10.0.0.1:80 -r 192.168.10.3 -m
#-m表示地址伪装,-w表示权重
ipvsadm -Ln #查看规则
ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.0.1:80 rr
-> 192.168.10.2:80 Masq 1 0 0
->192.168.10.3:80 Masq 1 0 0
lvs-dr:准备三台主机,一台vs,两台rs,vip都配置在虚拟接口上,rip和dip都配置在物理接口上,且都位于同一网段。
主机1:vip:10.0.0.100/dip:10.0.0.9
主机2:vip:10.0.0.100/rip:10.0.0.8
主机3:vip:10.0.0.100/rip:10.0.0.10
##为主机一配置vip
ifconfig ens33:0 10.0.0.100 netmask 255.255.255.255 broadcast 10.0.0.100 up
##主机二主机三配置环回口并且设置路由所有访问10.0.0.100 的报文从lo:0方向走
ifconfig lo:0 10.0.0.100 netmask 255.255.255.255 broadcast 10.0.0.100 up
route add -host 10.0.0.100 dev lo:0
##主机二,三上关闭arp请求和arp响应
echo 1>/proc/sys/net/ipv4/conf/all/arp_ignore
echo 2>/proc/sys/net/ipv4/conf/all/arp_announce
主机一上配置ipvs
ipvsadm -A -t 10,0,0.100:80 -s rr
ipvsadm -a -t 10.0.0.100:80 -r 10.0.0.9 -g
ipvsadm -a -t 10.0.0.100:80 -r 10.0.0.10 -g