sklearn中的交叉验证与参数选择
大家可能看到交叉验证想到最多的就是sklearn里面数据集的划分方法train_test_split,实际上这只是数据交叉验证的数据方法,对模型的进行评分。这里我们将对仔细讲解sklearn中交叉验证如何判断模型是否过拟合,并进行参数选择。主要涉及一下方法:

其中方法中的得分参数如下,部分下面会解释:
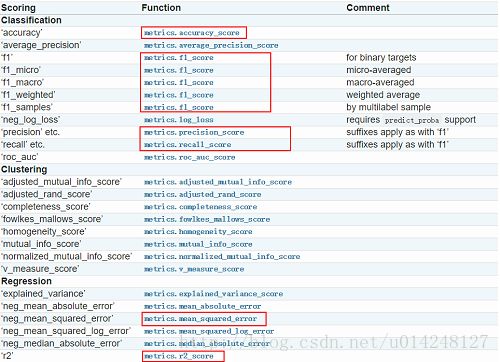
一、cross_validate评估模型的表现:
1,对模型训练一次,然后评估:这样还是会存在过拟合的问题。具体如下:
#直接训练
X_train,X_test,y_train,y_test=train_test_split(iris_X,iris_y,random_state=4) #把数据集分为训练集和测试集两个部分一部分是训练集,一部分是测试集,其中测试集占了30%
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
print(knn.score(X_test,y_test)) 解决办法就是把数据分成(训练,验证,测试),但是这样的问题就是会导致数据的浪费。接下来我们用交叉验证的方法评估。
2,cross_val_score方法:
(1)这个方法是对数据进行多次分割,然后训练多个模型并评分,每次分割不一样。之后我们用评分的均值来代表这个模型的得分。方法重要参数是:cv代表计算多少次,分割次数;scoring代表方法。
#交叉验证
from sklearn.model_selection import cross_val_score
knn = KNeighborsClassifier(n_neighbors=5)
score = cross_val_score(knn,iris_X,iris_y,cv=5,scoring='accuracy')
print(score)
print(score.mean())(2)我们可以用这个方法,改变超参数n_neighbors的值,对不同模型进行准确评分,进行参数选择。(代码比较简单,看注释应该可以理解)
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
iris=load_iris()
iris_X=iris.data
iris_y=iris.target
#交叉验证
from sklearn.model_selection import cross_val_score
knn = KNeighborsClassifier(n_neighbors=5)
score = cross_val_score(knn,iris_X,iris_y,cv=5,scoring='accuracy')
print(score)
print(score.mean())
#交叉验证对参数进行选择
import matplotlib.pyplot as plt
k_range = range(1,31)
k_loss = []
k_accuracy = []
for k in k_range:#对参数进行控制,选择参数表现好的,可视化展示
knn = KNeighborsClassifier(n_neighbors=k)
accuracy = cross_val_score(knn,iris_X,iris_y,cv=10,scoring='accuracy')#for classification 精度
loss = -cross_val_score(knn,iris_X,iris_y,cv=10,scoring='neg_mean_squared_error')#for regression 损失函数
k_accuracy.append(accuracy.mean())#计算均值得分
k_loss.append(loss.mean())
#绘图
plt.subplot(1,2,1)
plt.plot(k_range,k_accuracy)
plt.xlabel("Value of K for KNN")
plt.ylabel("Cross-validates Accuracy")
plt.subplot(1,2,2)
plt.plot(k_range,k_loss)
plt.xlabel("Value of K for KNN")
plt.ylabel("Cross-validates Loss")
plt.show()(3)cv可以传入数据的分割方法:分割方法用ShuffleSplit(还有其他的类)类来定义
from sklearn.model_selection import ShuffleSplit
n_samples = iris.data.shape[0]
cv = ShuffleSplit(n_splits=3, test_size=0.3, random_state=0)
cross_val_score(clf, iris.data, iris.target, cv=cv)3,cross_validate方法:这个就是可以设置多个评分输出,其他一样
from sklearn.model_selection import cross_validate
from sklearn.metrics import recall_score
scoring = ['precision_macro', 'recall_macro']#设置评分项
clf = svm.SVC(kernel='linear', C=1, random_state=0)
scores = cross_validate(clf, iris.data, iris.target, scoring=scoring, cv=5, return_train_score=False)
sorted(scores.keys())
scores['test_recall_macro'] 4,cross_val_predict方法:这个是对计算预测值,然后我们可以根据预测值计算得分。
from sklearn import metrics
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_predict
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
clf = KNeighborsClassifier(n_neighbors=5)
predicted = cross_val_predict(clf, iris.data, iris.target, cv=10)
score = metrics.accuracy_score(iris.target, predicted)#计算得分
print(score)二、Validation curves验证曲线:前面主要讲的是模型的评估,主要思想就是采用多次数据分割的思想进行交叉验证,用每次分割的得分均值评估模型。这里主要讲通过可视化了解模型的训练过程,判断模型是否过拟合,并进行参数选择。
1,validation_curve验证曲线方法:这个方法是用来测试模型不同参数(不同模型)的得分情况。重要参数为:param_name代表要控制的参数;param_range代表参数的取值列表。其他参数都一样。返回训练和测试集上的得分。
(根据模型在训练集合测试集上,不同参数取值的结果,判断模型是否过拟合,并进行参数选择;每次针对一个参数)
from sklearn.model_selection import validation_curve #可视化学习的整个过程
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits=load_digits()
X=digits.data
y=digits.target
gamma_range=np.logspace(-6,-2.3,5)#从-6到-2.3取5个点
train_loss,test_loss=validation_curve(
SVC(),X,y,param_name="gamma",param_range=gamma_range,cv=10,scoring="neg_mean_squared_error")
train_loss_mean= (-1)*np.mean(train_loss,axis=1)
test_loss_mean= (-1)*np.mean(test_loss,axis=1)
plt.plot(gamma_range,train_loss_mean,"o-",color="r",label="Training")
plt.plot(gamma_range,test_loss_mean,"o-",color="g",label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()2,learning_curve学习曲线方法:这个方法显示了对于不同数量的训练样本的模型的验证和训练评分。 这是一个工具,可以找出我们从添加更多的训练数据中受益多少,以及估计器是否因方差错误或偏差错误而受到更多的影响。 如果验证分数和训练分数都随着训练集规模的增加而收敛到一个太低的值,那么我们就不会从更多的训练数据中受益。 在下面的情节中,你可以看到一个例子:朴素贝叶斯大致收敛到一个低分。
方法重要参数:train_sizes代表每次选择进行训练的数据大小。
方法返回:训练数据大小列表,训练集,测试集上的得分列表
from sklearn.model_selection import learning_curve #可视化学习的整个过程
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits=load_digits()
X=digits.data
y=digits.target
#交叉验证测试
train_sizes,train_loss,test_loss = learning_curve(SVC(gamma=0.1),X,y,cv=10,scoring='neg_mean_squared_error',train_sizes=[0.1,0.25,0.5,0.75,1]) #记录的点是学习过程中的10%,25%等等的点
train_loss_mean = -1 * np.mean(train_loss,axis=1)
test_loss_mean = -1 * np.mean(test_loss,axis=1)
#可视化展示
plt.subplot(1,2,1)
plt.plot(train_sizes,train_loss_mean,'o-',color='r',label='train')
plt.plot(train_sizes,test_loss_mean,'o-',color='g',label='cross_validation')
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
#交叉验证测试
train_sizes,train_loss,test_loss = learning_curve(SVC(gamma=0.001),X,y,cv=10,scoring='neg_mean_squared_error',train_sizes=[0.1,0.25,0.5,0.75,1]) #记录的点是学习过程中的10%,25%等等的点
train_loss_mean = 1 * np.mean(train_loss,axis=1)
test_loss_mean = 1 * np.mean(test_loss,axis=1)
#可视化展示
plt.subplot(1,2,2)
plt.plot(train_sizes,train_loss_mean,'o-',color='r',label='train')
plt.plot(train_sizes,test_loss_mean,'o-',color='g',label='cross_validation')
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()