机器学习笔记2——分类
分类
笔记整理配套教程:coursera,欢迎转载分享!
1.背景
你想要在西雅图选一个寿司很好的餐馆,所以你需要找到这样的餐馆。我们可以获得餐馆的评价比如“the sushi of this restaurant is best in the city”,我们可以把这句话输入一个情感分类器,我们可以知道这句话是对这个餐馆寿司的正面评价。(可能有些评价里面包含很多内容,比方说这里的拉面很一般,但是我们不关心拉面,所以我们需要忽略这些无关的内容。)
Tips:分类有很多用途,比如 垃圾邮件分类,图片分类等。
2.分类边界
以餐馆评价为例,我们需要根据评价内容将这条评论分为“积极评价”或者“消极评价”,最简单的思路是我们可以挑选句子中的词汇,把这些词汇分为积极或者消极,事先约定每个特定词汇的权重,统计总权重来识别句子是积极评价还是消极评价:

那么我们是如何分类帮助我们做决策的呢?举个例子,比方对两个单词我们给予如下权重:
| Word | Weight |
|---|---|
| awesome | 1.0 |
| awful | -1.5 |
那么,Score(x) = 1.0-1.5=-0.5,所以这是负面评价。我们可以计算积极与消极的分界线是Score(x)=0的直线,如果有三个指标我们可以得到一个分界面,如果是多个指标我们可以得到一个高维曲面作为分界。
我们怎么确定这些权重呢?我们需要吧数据分为测试集和训练集,我们使用训练集训练权重,然后使用这些权重对测试集进行测试,计算错误率和正确率,我们可以用错误率或者正确率来评判一个分类器的好坏。

3.如何评价分类器的好坏
那么问题来了,正确率达到多少才算好呢?首先,分类器的正确率必须比随机猜测的正确率高。好比分成四类,你至少需要高于25%的正确率才算是一个合格的分类器,否则你的分类其是毫无意义的。其次,你的分类器必须有意义,好比你有一个你有个垃圾邮件预测器 它的正确率有90% 你能拿它出去吹牛吗? 它够棒了吗? 这个 还得看情况 如果是垃圾邮件分类器 这个正确率不行 因为2010年数据显示 世界上所有发送的电子邮件中 有90%都是垃圾邮件 所以我只要猜说每封邮件都是垃圾邮件 那么我的正确率是多少? 90% 。
既然分类器是会犯错误的,那么我们该怎么对待这些错误呢?我们使用confusion matrix来表示:
我们要从TP、FP、TN、FN讲起。
考虑一个二分类问题:一个item,它实际值有0、1两种取值,即负例、正例;而二分类算法预测出来的结果,也只有0、1两种取值,即负例、正例。我们不考虑二分类算法细节,当作黑箱子就好;我们关心的是,预测的结果和实际情况匹配、偏差的情况。
TP:true positive,实际是正例,预测为正例
FP:false positive,实际为负例,预测为正例
TN:true negative,实际为负例,预测为负例
FN:false negative,实际为正例,预测为负例
也就是说:我们不仅考虑算法的预测结果对不对,还要考虑是“哪一种对”;我们还考虑算法预测错的情况,并且我们深究“是哪一种错”:
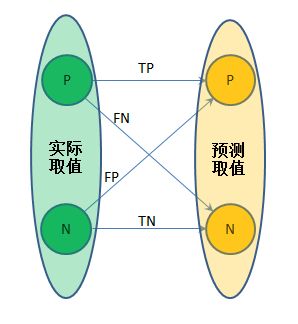
OK,既然把TP、FP、TN、FN搞清楚了,那么看几个rate的定义。
TPR:true positive rate, 等于 TPR=TPTP+FN ,又叫precision rate
FPR:false positive rate,等于 FPR=FPFP+TN
TNR:true negative rate,等于 TNR=TNFP+TN
FNR:false negative rate,等于 FNR=FNTP+FN ,又叫miss rate
- fnr+tpr=1 , fpr+tnr=1
3.1理解阈值
3.1原文参见http://www.cnblogs.com/zjutzz/p/5182559.html
再次考虑二分类问题。你说,真实世界会存在严格的二分类吗?就说人的性取向,有的人也是“徘徊不定”的,这样的人真是让人头疼但是必须想办法处理掉。因此设定一个阈值:根据这个人的一系列举动,给ta的性别累计打分并最终映射到[0,1]区间(得到score),然后比如设定阈值t为0.5,若score>t=0.5,那么ta是男的;否则是女的。
回到理论上,每一个需要预测的变量,其取值都可以根据阈值进行划分。对于二分类,我设定阈值t,当某个item取值大于t,就判定为正例(positive),否则判定为负例(negative)。
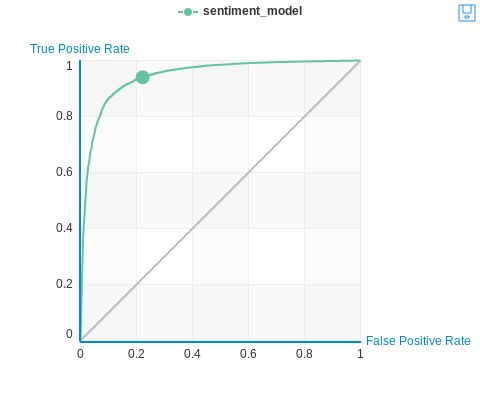
也就是说,我手头有一堆预测得到的数据,我通过设定不同的阈值,能得到不同的TP、FP、TN、FN取值,相应的TPR、FPR、TNR、FNR取值也产生变化。那么这种变化我就可以通过图像显示出来:对于一个确定的阈值t,FPR和TPR是确定的,得到一个(fpr,tpr)元组;将阈值从0到1变化,当t=0时所有预测结果都大于0都是Positive所以FP=TP=1,FN=TN=0,fpr=tpr=1,得到(1,1)点,当t=1时所有预测结果都小于0都是Negative所以FP=TP=0,FN=TN=1,fpr=tpr=0,得到(0,0)点,t取(0,1)上的值时则fpr和tpr都在0到1之间变化,且不难发现:当t增加,#FP也减小,#TN增加,则fpr减小;当t增加,#TP减小,#FN增加,则tpr减小。也就是说,当阈值t从0变化到1,fpr和tpr也单调减小,从(1,1)减小到(0,0)
得到如下的ROC曲线:
4. FP & FN的理解
FP FN的代价视情况而定,比如垃圾邮件分类,一封垃圾邮件被误认为不是垃圾邮件(FN),我们会受到打扰。如果反过来,一封邮件不是垃圾邮件但是却被当作垃圾邮件过滤掉了,我们可能会蒙受很大的损失。
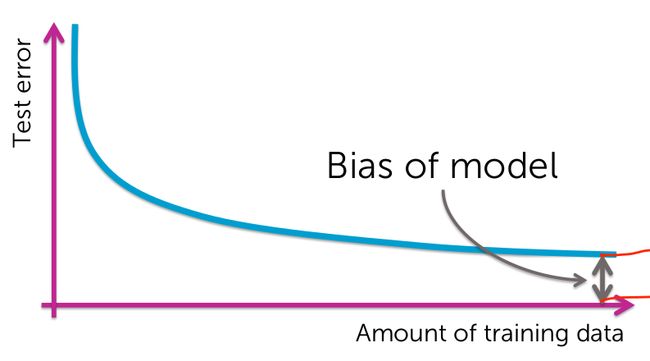
还有一个问题是我们需要多少训练数据呢?事实是越复杂的模型需要越多的数据,但是无论多少数据我们最终的错误率都不可能达到0%。
6.graphlab-python构建模型
一下代码资源可以到我的资源下载,不需要积分http://download.csdn.net/detail/u014303046/9660376
import graphlab
#导入数据
products = graphlab.SFrame('amazon_baby.gl/')
#计数每条评论李每个单词出现的次数,以字典存储,添加一列word_count
products['word_count'] = graphlab.text_analytics.count_words(products['review'])
#找到某个特定产品能的数据
giraffe_reviews = products[products['name']=='Vulli Sophie the Giraffe Teether']
#看一下这个产品的评级总体状况
giraffe_reviews['rating'].show(view='Categorical')
#除去那些难以判断的评分
products = products[products['rating'] != 3]
#把评分4或5的设为1,用来作为后面的目标来训练
products['sentiment'] = products['rating'] >= 4
#train_data test_data
train_data,test_data = products.random_split(0.8,seed=0)
#建立模型
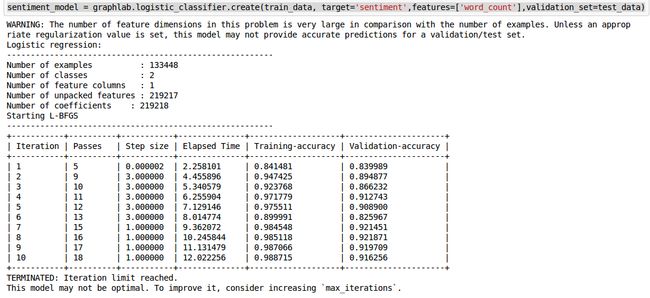
sentiment_model = graphlab.logistic_classifier.create(train_data, target='sentiment',features=['word_count'],validation_set=test_data) 此时可以看到输出:
#使用测试集检验模型
sentiment_model.evaluate(test_data, metric='roc_curve')得到:
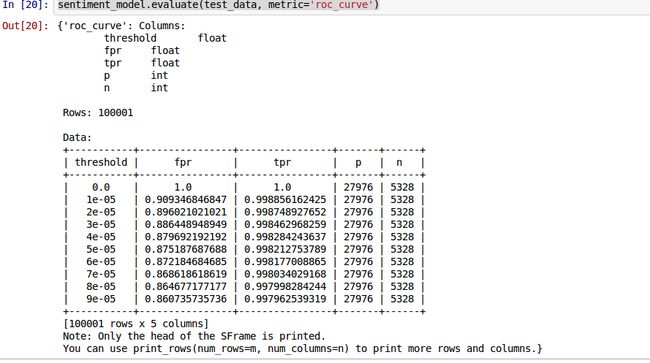
#ROC曲线
sentiment_model.show(view='Evaluation')得到:
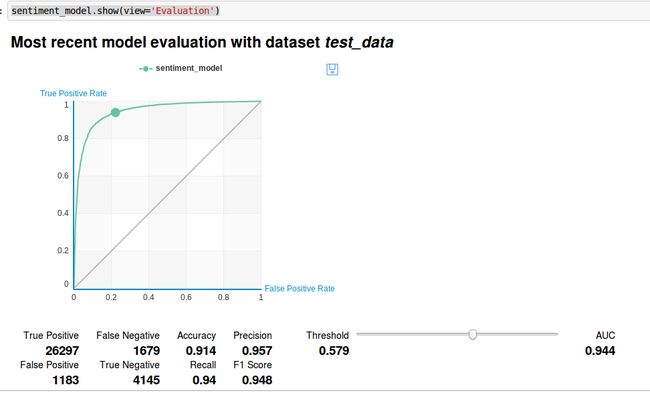
#用我们之前选出来的产品看一看模型效果
giraffe_reviews['predicted_sentiment'] = sentiment_model.predict(giraffe_reviews, output_type='probability')
#排个序
giraffe_reviews = giraffe_reviews.sort('predicted_sentiment', ascending=False)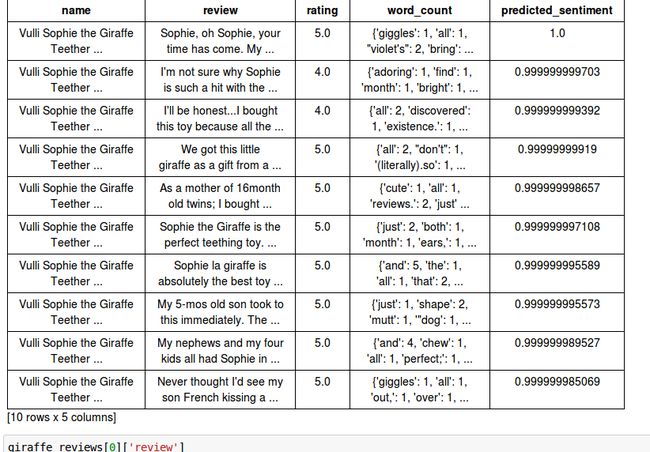
写道这里差不多该结束了,我们可以用一些特定的词汇来建立模型,而非所有单词。可以试试效果。