Word和Excel大概是我们最常碰到的两种文件了,我前面写过pandas的基本操作,利用它可以轻松完成Excel文件的批量处理,那么对于word文件的处理是否也有同样简单的方式,答案是肯定的,这涉及到python的另一个库docx,这篇文章的主要内容是:
如何批量处理word中的表格
我随便找了一个Word文件,它的部分内容如下:
这个文件中有多个这样表格,我们要将它们处理成一个简单表——属性一行,值 一行
下面正式开始,docx之外的内容我将不做详细说明,有问题请留言。
1.安装docx:
pip install python-docx
2.导入docx库
from docx import Document
import pandas as pd
3.读Word文件
doc=Document('2007年三江源生态监测森林数据集.docx')
ps:docx不支持dox格式的word文件。
4.读表格
tb=doc.tables
5.读行
rows=tb[0].rows
6.读列
cols=rows[0].cells
7.单元格
cell=cols[0]
text=cell.text
有了上面的基础知识,读取word中的表格应该没什么问题了,下面是是完整代码:
doc=Document('2007年三江源生态监测森林数据集.docx')
index,key,value=[],[],[]
table_index=0
for tb in doc.tables:
table_index+=1
row_index=0
for row in tb.rows:
row_index+=1
for cell in row.cells:
text=""
for p in cell.paragraphs:##如果cell中有多段,即有回车符
text+=p.text
if row_index%2==0:
value.append(text)#偶数行为值
index.append(table_index)#这行也可以放在else中
else:
key.append(text)#奇数行为属性
现在word中所有表格的内容已经读出来了,不过是在两个列表中,将它们重新构造成一个表格。
8.重建表格
df=pd.DataFrame({'table_index':index,'key':key,'value':value})
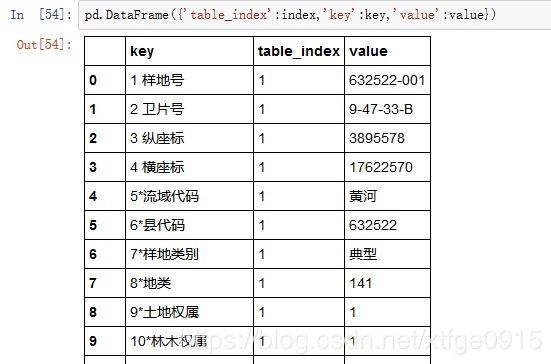
但是这个表格并不是我们想要的结果,我们想要的是key为表头,value为值,table_index为索引,所以我们还需要进一步的操作。
8.pviot
#删除重复行,否则会报错:Index contains duplicate entries, cannot reshape
df=df.drop_duplicates(['table_index','key'])
df1=df.pivot(index='table_index',columns='key',values='value')
#下面两行用于去除列名和索引名,可有可无,加上只因为我有强迫症,为了美观,感兴趣的朋友可以对比加上这现行前后的差异
df1.columns=list(df1.columns)
df1.index=list(df1.index)
最终得到的表格是这样的: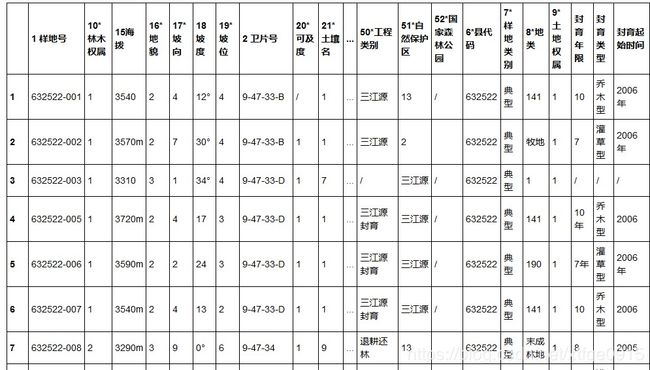
9.如何把表格写入word文件
上面的表格内容太多,我们取一部分写入word中
from docx.enum.table import WD_TABLE_ALIGNMENT
from docx.shared import Cm
df2=df1.iloc[:10,:6]
d=Document()
tb=d.add_table(rows=len(df2.index),cols=len(df2.columns))
tb.add_row()
for i in range(len(df2.columns)):
tb.cell(0,i).text=df2.columns[i]#添加表头
for row in range(1,len(df2.index)+1):
for col in range(len(df2.columns)):
tb.cell(row,col).width=1
tb.cell(row,col).text=df2.iloc[row,col]
tb.cell(row,col).width=Cm(6)
tb.cell(row,col).ipynb
tb.style='Medium Grid 1 Accent 1'
tb.autofit=True
d.save('tb.docx')
最后生成的word表格是这样的: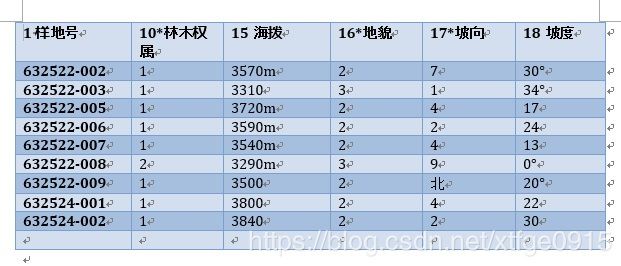
关于表格的样式控制将在另一篇博客中展开讨论:利用python批量处理Word文件——表格(二)样式控制
关于word表格的处理就到这里了,现实中我们要处理的文件内容千变万化,不过只要熟练这些基础操作,就可以以不变应万变,后面我会继续写word中其它内容的处理,感兴趣的朋友可以多多关注。