前言
Elastic Stack 提供 Beats 和 Logstash 套件来采集任何来源、任何格式的数据。其实Beats 和 Logstash的功能差不多,都能够与 Elasticsearch 产生协同作用,而且
logstash比filebeat功能更强大一点,2个都使用是因为:Beats 是一个轻量级的采集器,支持从边缘机器向 Logstash 和 Elasticsearch 发送数据。考虑到 Logstash 占用系
统资源较多,我们采用 Filebeat 来作为我们的日志采集器。并且这里采用kafka作为传输方式是为了避免堵塞和丢失,以实现日志的实时更新。
介绍
1.Filebeat:filebat是一个用于转发和集中日志数据的轻量级shipper。作为代理安装在服务器上,filebeat监视指定的日志文件或位置,收集日志事件,并将它们转发给ElasticSearch或logstash进行索引。
2.Logstash:Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到存储库。
3.ElasticSearch:Elasticsearch 是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可靠性和管理便捷性而设计。
4.Kibana:Kibana 能够以图表的形式呈现数据,并且具有可扩展的用户界面,供您全方位配置和管理 Elastic Stack。
Elastic Stack架构

软件环境
Ubuntu 18.04.1
Elastic Stack官网:https://www.elastic.co/
kafka、Zookeeper安装
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用
提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
注:安装kafka时会发现它需要安装Zookeeper的。kafka的官方文档有说明。zookeeper是为了解决分布式一致性问题的工具,kafka使用ZooKeeper用于管理、协调代理。当Kafka系统中新增了代理或某个代理失效时,Zookeeper服务将通知生产者和消费者。生产者与消费者据此开始与其他代理协调工作。
Zookeeper单机安装配置:
Step 1:下载压缩包并解压
1 >wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz 2 >tar -zxvf zookeeper-3.4.13.tar.gz 3 >cd zookeeper-3.4.13
Step 2:修改配置文件
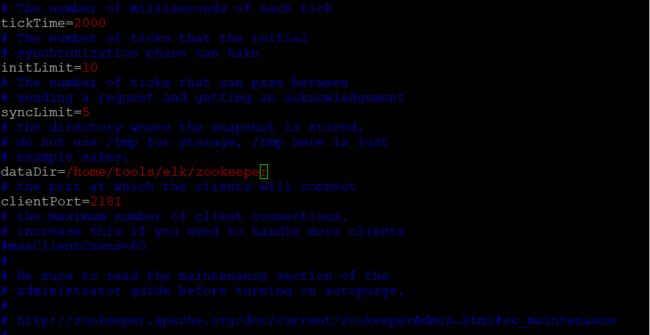
先复制模板配置文件,并重命名,然后里面存放数据的路径dataDir可以自己定义
1 >cp -rf conf/zoo_sample.cfg conf/zoo.cfg 2 >vim zoo.cfg
Step 3:启动服务
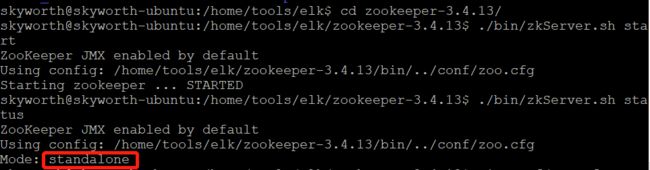
1 >./bin/zkServer.sh start 2 3 >./bin/zkServer.sh status
先启动,系统会默认加载zoo.cfg配置,然后使用 zkServer.sh status 查看服务状态
kafka安装配置:
根据官网教程开始安装(复制的官网教程):
Step 1: Download the code
1 > wget http://mirror.apache-kr.org/kafka/2.1.0/kafka_2.11-2.1.0.tgz 2 > tar -xzf kafka_2.11-2.1.0.tgz 3 > cd kafka_2.11-2.1.0/
Step 2: Start the server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don't already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.(由于我自己安装的Zookeeper,所以这一步可以省略)
1 > ./bin/zookeeper-server-start.sh config/zookeeper.properties 2 [2019-01-23 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) 3 ...
Now start the Kafka server:
首先可以先修改一下配置文件server.propertise
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样 port=9092 #当前kafka对外提供服务的端口默认是9092 num.network.threads=3 #这个是borker进行网络处理的线程数 num.io.threads=8 #这个是borker进行I/O处理的线程数 log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个 socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能 socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘 socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小 num.partitions=1 #默认的分区数,一个topic默认1个分区数 log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天 message.max.byte=5242880 #消息保存的最大值5M default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务 replica.fetch.max.bytes=5242880 #取消息的最大直接数 log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件 log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除 log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能 zookeeper.connect=localhost:12181#设置zookeeper的连接端口
1 > ./bin/kafka-server-start.sh config/server.properties 2 [2019-01-23 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) 3 [2019-01-23 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) 4 ...
后台启动的命令(蓝色部分为控制台输出地址):
>nohup bin/kafka-server-start.sh config/server.properties 1>/home/ec2-user/tools/kafka_2.11-2.1.0/logs/kafka.log 2>&1 &
到这里服务就启动成功了。
查看java进程pid也可以发现kafka

Step 3: Create a topic
Let's create a topic named "test" with a single partition and only one replica:
1 > ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
if you want delete a topic:
1 >./bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test
We can now see that topic if we run the list topic command:
1 > ./bin/kafka-topics.sh --list --zookeeper localhost:2181 2 test
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
在上一次配置的日子目录(server.properties里配置的log.dirs)上可以看到,已经存在了该主题的日志信息文件了,由于server.properties里面配置的num.partitions=1(默认的分区数,一个topic默认1个分区数)。所以只有一个文件夹
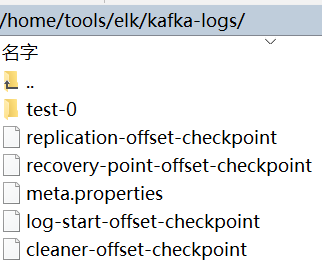
要查看topic详细信息的话:
1 >bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Step 4: Star a producer(创建发布者)
1 > ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Step 5: Start a consumer(创建订阅者)
1 > ./bin/kafka-console-consumer.sh --bootstrap-server localhost:2181 --topic test --from-beginning
创建好后,可以在发布者端发送消息进行测试,我们这里的发布者是filebeat,订阅者是logstash,可以不用配置。
Filebeat安装配置
beat是一个轻量级的数据传输者,它有好几种分类,这里暂时只用到Filebeat。

Filebeat的处理流程基本分为3部分:Input、Filter、Output。

开始安装
1.官网下载 :filebeat-6.5.4-linux-x86_64.tar.gz,复制到LINUX服务器,然后解压( tar -xzvf filebeat-6.5.4-linux-x86_64.tar.gz)

2.进入filebeat-6.5.4-linux-x86_64文件夹,修改filebeat.yml,filebeat默认是将数据传输到elasticsearch,需要修改为kafka
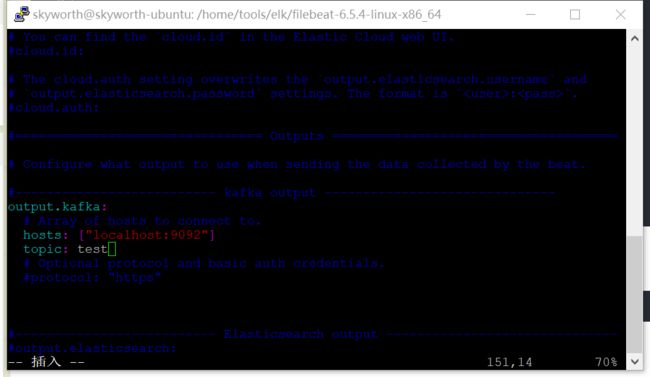
这里放一个filebeat详细配置参考:https://www.cnblogs.com/kuku0223/p/8316922.html
配置完成后启动filebeat:
1 > sudo ./filebeat -e -c filebeat.yml
ELK(elasticsearch+logstash+kibana 6.5.4)配置
elasticsearch安装配置
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
顺带提一下Elasticsearch的数据结构:FST(Finite StateTransducers),其特点高度重复利用数据前缀和后缀存储数据,能很大层度上压缩数据。
elasticsearch安装配置:
从官网上下载软件:https://www.elastic.co/cn/downloads/elasticsearch
解压之后,修改config/elasticsearch.yml配置文件,配置一下ip和端口号:
1 skyworth@skyworth-ubuntu:~$ cd /home/tools/elk/elasticsearch-6.5.4/ 2 skyworth@skyworth-ubuntu:/home/tools/elk/elasticsearch-6.5.4$ vim config/elasticsearch.yml
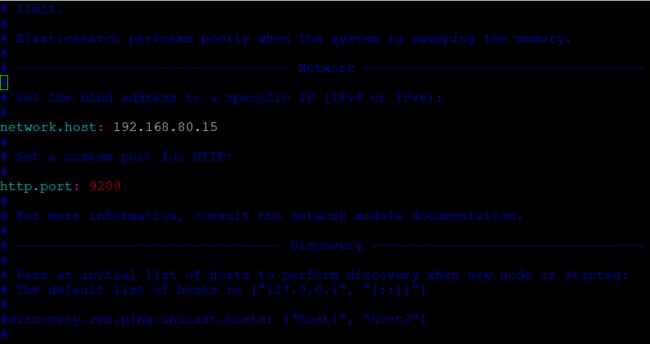
然后启动命令:
1 skyworth@skyworth-ubuntu:/home/tools/elk/elasticsearch-6.5.4$ ./bin/elasticsearch
后台运行命令:
>./bin/elasticsearch -d
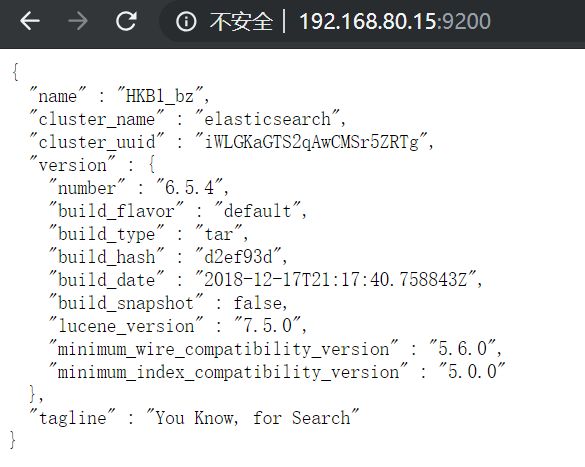
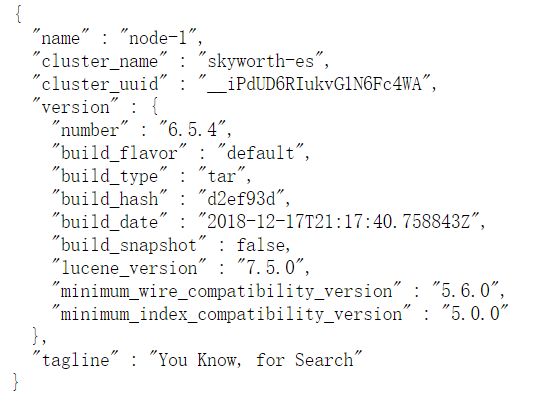
然后浏览器打开端口(http://192.168.80.15:9200/),出现如下信息说明启动成功
elasticsearch启动常见错误参考:https://www.cnblogs.com/zhi-leaf/p/8484337.html
elastucsearch安全框架(Search Guard ,x-pack收费)
官方参考文档:https://docs.search-guard.com/latest/demo-installer.html#install-search-guard-on-elasticsearch
配置参考:http://xiaoqiangge.com/aritcle/1536058241842.html
Install Search Guard on Elasticsearch:
>bin/elasticsearch-plugin install -b com.floragunn:search-guard-6:6.5.4-24.0
接着,配置ssl,由于ElasticSearch节点之间通讯默值非加密,造成数据不安全,Search Guard强制ElasticSearch节点之间通讯为加密方式。
可以在 https://search-guard.com/tls-certificate-generator 上申请密匙。
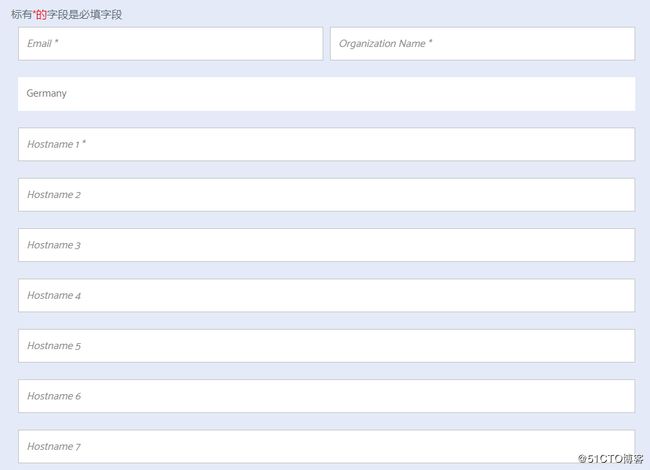
Email用来接收密钥,
Organization Name可以随便填写,
Hostname填写ElasticSearch集群中每个节点的node name,这是一一对应的,这里我只有一个节点,node name为node-1。
填写好之后,邮箱会收到一个压缩包,将这个压缩包解压到Elastucsearch的config目录下,并在elasticsearch.yml追加配置,如下:
http.compression: true xpack.security.enabled: false searchguard.ssl.transport.pemcert_filepath: CN=node-1.crtfull.pem searchguard.ssl.transport.pemkey_filepath: CN=node-1.key.pem searchguard.ssl.transport.pemkey_password: 3816b97cbd40d1a97402 searchguard.ssl.transport.pemtrustedcas_filepath: chain-ca.pem searchguard.ssl.transport.enforce_hostname_verification: false searchguard.ssl.http.enabled: true searchguard.ssl.http.pemcert_filepath: CN=node-1.crtfull.pem searchguard.ssl.http.pemkey_filepath: CN=node-1.key.pem searchguard.ssl.http.pemkey_password: 3816b97cbd40d1a97402 searchguard.ssl.http.pemtrustedcas_filepath: chain-ca.pem searchguard.authcz.admin_dn: - CN=sgadmin searchguard.audit.type: internal_elasticsearch searchguard.enable_snapshot_restore_privilege: true searchguard.check_snapshot_restore_write_privileges: true searchguard.restapi.roles_enabled: ["sg_all_access"] cluster.routing.allocation.disk.threshold_enabled: false
注:有关配置属性以及pemkey_password属性可以在下载的密钥包中README.txt文件中查看到,如下:
## Passwords ### Common passwords Root CA password: 9c5eeb48cee19d1ae6ce0315154f7271ff6f8b8c Truststore password: 1d6df567841c5e8a7663 Admin keystore and private key password: 83f5fdded6c38208a9ad Demouser keystore and private key password: e598a7e1684295923d36 ## Host/Node specific passwords Host: node-1 node-1 keystore and private key password: 3816b97cbd40d1a97402 node-1 keystore: node-certificates/CN=node-1-keystore.jks node-1 PEM certificate: node-certificates/CN=node-1.crtfull.pem node-1 PEM private key: node-certificates/CN=node-1.key.pem
这时还无法启动ES,需要对节点密钥文件进行授权,权限打小为0644(rw-r--r--),否则会出现对密钥文件没有读取权限,如下:
>chmod 644 root-ca.pem chain-ca.pem node-certificates/CN\=node-1.key.pem node-certificates/CN\=node-1.crtfull.pem /home/ec2-user/tools/elasticsearch-6.5.4/config/
把节点授权的4个文件复制到ES的config文件夹下
cp root-ca.pem chain-ca.pem node-certificates/CN\=node-1.key.pem node-certificates/CN\=node-1.crtfull.pem /home/ec2-user/tools/elasticsearch-6.5.4/config/
接着对sgadmin客户端密钥进行授权:
>chmod 644 root-ca.pem chain-ca.pem client-certificates/CN\=sgadmin.key.pem client-certificates/CN\=sgadmin.crtfull.pem
然后把客户端密匙的4个文件复制到插件的tools目录下
cp root-ca.pem chain-ca.pem client-certificates/CN\=sgadmin.key.pem client-certificates/CN\=sgadmin.crtfull.pem /home/ec2-user/tools/elasticsearch-6.5.4/plugins/search-guard-6/tools
注:这里都没有去使用root用户权限,自己创建用户
然后再启动ES,分别检查状态和日志是否存在错误,如果没有存在错误开始执行最后一步,初始化sgadmin配置,如下:
进入目录 /home/ec2-user/tools/elasticsearch-6.5.4/plugins/search-guard-6/tools 对sgadmin.sh进行授权 chmod 744 sgadmin.sh 执行初始化语句 sh sgadmin.sh -cd ../sgconfig/ -icl -nhnv -cacert root-ca.pem -cert CN=sgadmin.crtfull.pem -key CN=sgadmin.key.pem -h localhost -keypass 83f5fdded6c38208a9ad
执行完之后会出现如下效果:

最后在浏览器书如https://admin:admin@localhost:9200可以查看结果:
kibana安装配置
通过 Kibana,能够对 Elasticsearch 中的数据进行可视化并在 Elastic Stack 进行操作.
kibana安装配置:
首先下载软件,然后解压,修改配置文件config/kibana.yml,再启动就行,与elasticsearch类似。
1 skyworth@skyworth-ubuntu:/home/tools/elk/kibana-6.5.4-linux-x86_64$ vim config/kibana.yml
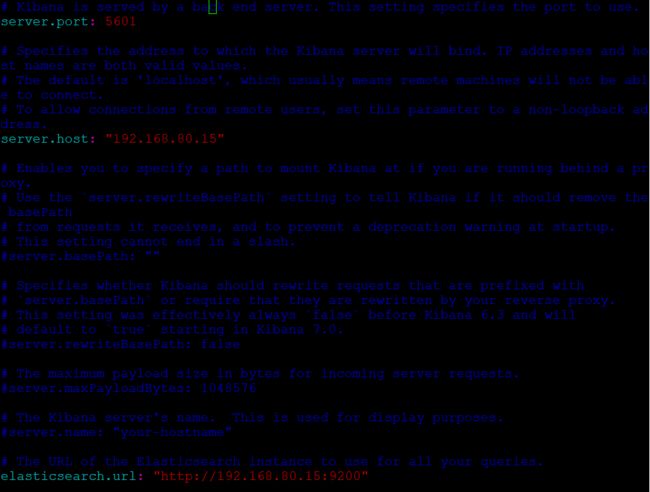
1 skyworth@skyworth-ubuntu:/home/tools/elk/kibana-6.5.4-linux-x86_64$ ./bin/kibana
kibana后台启动
>nohup bin/kibana 1>/home/ec2-user/tools/kibana-6.5.4-linux-x86_64/logs/kibana.log 2>&1 &
Install Search Guard on Kibana
这里只需要修改一下 kibana.yml,增加如下配置就好:
# Use HTTPS instead of HTTP elasticsearch.url: "https://localhost:9200" # Configure the Kibana internal server user elasticsearch.username: "kibanaserver" elasticsearch.password: "kibanaserver" # Disable SSL verification because we use self-signed demo certificates elasticsearch.ssl.verificationMode: none # Whitelist the Search Guard Multi Tenancy Header elasticsearch.requestHeadersWhitelist: [ "Authorization", "sgtenant" ]
logstash安装配置
filebeat中message要么是一段字符串,要么在日志生成的时候拼接成json然后在filebeat中指定为json。但是大部分系统日志无法去修改日志格式,filebeat则无法通过正则去匹配出对应的field,这时需要结合logstash的grok来过滤。
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到存储库中。
安装过程依然是下载压缩包,解压后修改配置文件,再启动。
进入config文件夹,我们可以修改原有的logstash-sample.conf,或者自己新建一个(这里选择自己新建一个logstash-skyworth.conf)。

修改配置文件:
input{ kafka{ bootstrap_servers => ["192.168.80.15:9092"] client_id => "test" group_id => "test" auto_offset_reset => "latest" //从最新的偏移量开始消费 consumer_threads => 5 decorate_events => true //此属性会将当前topic、offset、group、partition等信息也带到message中 topics => ["test"] type => "skyworth" } } filter { if ([message]== "") { drop {} } } output { if [type] == "skyworth"{ elasticsearch { hosts => ["192.168.80.15:9200"] # ElasticSearch的地址加端口 index => "skyworth-log-%{+YYYYMMdd}" # ElasticSearch的保存文档的index名称, } } }
启动命令:
1 >./bin/logstash -f config/logstash-skyworth.conf
注:elastic stack 安全框架X-Pack 安装配置请参考:https://www.cnblogs.com/cjsblog/p/9501858.html
总结
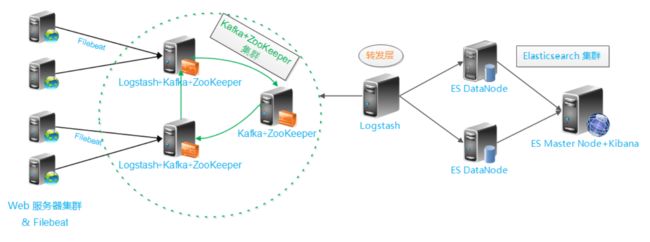
业务流程偷了张图如下:
注:有的人会在filebeat和kafka之间再加一层前置的logstash用于格式化日志,目前我也没明白为什么要那样做。