第一篇:从决策树学习谈到贝叶斯分类算法、EM、HMM
引言
最近在面试中(点击查看,我的个人简历),除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法,而我向来恨对一个东西只知其皮毛而不得深入,故写一个有关聚类 & 分类算法的系列文章以作为自己备试之用,甚至以备将来常常回顾思考。行文杂乱,但侥幸若能对读者起到一点帮助,则幸甚至哉。
本分类 & 聚类算法系列借鉴和参考了两本书,一本是Tom M.Mitchhell所著的机器学习,一本是数据挖掘导论,这两本书皆分别是机器学习 & 数据挖掘领域的开山 or 杠鼎之作,读者有继续深入下去的兴趣的话,不妨在阅读本文之后,课后细细研读这两本书。除此之外,还参考了网上不少牛人的作品(文末已注明参考文献或链接),在此,皆一一表示感谢(从本质上来讲,本文更像是一篇读书 & 备忘笔记)。
本分类 & 聚类算法系列暂称之为Top 10 Algorithms in Data Mining,其中,各篇分别有以下具体内容:
- 开篇:决策树学习Decision Tree,与贝叶斯分类算法(含隐马可夫模型HMM);
- 第二篇:支持向量机SVM(support vector machine),与神经网络ANN;
- 第三篇:待定...
OK,全系列任何一篇文章若有任何错误,漏洞,或不妥之处,还请读者们一定要随时不吝赐教 & 指正,谢谢各位。
分类与聚类,监督学习与无监督学习
在讲具体的分类和聚类算法之前,有必要讲一下什么是分类,什么是聚类,以及都包含哪些具体算法或问题。
常见的分类与聚类算法
简单来说,自然语言处理NLP中,我们经常提到的文本分类便就是一个分类问题,一般的模式分类方法都可用于文本分类研究。常用的分类算法包括:决策树分类法,朴素的贝叶斯分类算法(native Bayesian classifier)、基于支持向量机(SVM)的分类器,神经网络法,k-最近邻法(k-nearest neighbor,kNN),模糊分类法等等(本篇稍后会讲决策树分类与贝叶斯分类算法,当然,所有这些分类算法日后在本blog内都会一一陆续阐述)。
分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。但是很多时候上述条件得不到满足,尤其是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,这时候可以考虑使用聚类算法。
而K均值(K-means clustering)聚类则是最典型的聚类算法(当然,除此之外,还有很多诸如属于划分法K-MEDOIDS算法、CLARANS算法;属于层次法的BIRCH算法、CURE算法、CHAMELEON算法等;基于密度的方法:DBSCAN算法、OPTICS算法、DENCLUE算法等;基于网格的方法:STING算法、CLIQUE算法、WAVE-CLUSTER算法;基于模型的方法,本系列后续会介绍其中几种)。
监督学习与无监督学习
机器学习发展到现在,一般划分为 监督学习(supervised learning),半监督学习(semi-supervised learning)以及无监督学习(unsupervised learning)三类。举个具体的对应例子,则是比如说,在NLP词义消岐中,也分为监督的消岐方法,和无监督的消岐方法。在有监督的消岐方法中,训练数据是已知的,即每个词的语义分类是被标注了的;而在无监督的消岐方法中,训练数据是未经标注的。
上面所介绍的常见的分类算法属于监督学习,聚类则属于无监督学习(反过来说,监督学习属于分类算法则不准确,因为监督学习只是说我们给样本sample同时打上了标签(label),然后同时利用样本和标签进行相应的学习任务,而不是仅仅局限于分类任务。常见的其他监督问题,比如相似性学习,特征学习等等也是监督的,但是不是分类)。
SO,说的再具体点,则是:
- 监督学习的任务是学习带标签的训练数据的功能,以便预测任何有效输入的值。监督学习的常见例子包括将电子邮件消息分类为垃圾邮件,根据类别标记网页,以及识别手写输入。创建监督学习程序需要使用许多算法,最常见的包括神经网络、Support Vector Machines (SVMs) 和 Naive Bayes 分类程序,当然,还有决策树分类,及k-最近邻算法。
- 无监督学习的任务是发挥数据的意义,而不管数据的正确与否。它最常应用于将类似的输入集成到逻辑分组中。它还可以用于减少数据集中的维度数据,以便只专注于最有用的属性,或者用于探明趋势。无监督学习的常见方法包括K-Means,分层集群和自组织地图。
再举个例子,正如人们通过已知病例学习诊断技术那样,计算机要通过学习才能具有识别各种事物和现象的能力。用来进行学习的材料就是与被识别对象属于同类的有限数量样本。监督学习中在给予计算机学习样本的同时,还告诉计算各个样本所属的类别。若所给的学习样本不带有类别信息,就是无监督学习(浅显点说:同样是学习训练,监督学习中,给的样例比如是已经标注了如心脏病的,肝炎的;而无监督学习中,就是给你一大堆的样例,没有标明是何种病例的)。
而在支持向量机导论一书给监督学习下的定义是:当样例是输入/输出对给出时,称为监督学习,有关输入/输出函数关系的样例称为训练数据。而在无监督学习中,其数据不包含输出值,学习的任务是理解数据产生的过程。
第一部分、决策树学习
1.1、什么是决策树
咱们直接切入正题。所谓决策树,顾名思义,是一种树,一种依托于策略抉择而建立起来的树。
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。
来理论的太过抽象,下面举两个浅显易懂的例子:
第一个例子
套用俗语,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑:

也就是说,决策树的简单策略就是,好比公司招聘面试过程中筛选一个人的简历,如果你的条件相当好比如说某985/211重点大学博士毕业,那么二话不说,直接叫过来面试,如果非重点大学毕业,但实际项目经验丰富,那么也要考虑叫过来面试一下,即所谓具体情况具体分析、决策。
第二个例子
此例子来自Tom M.Mitchell著的机器学习一书:
小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,他了解到人们决定是否打球的原因最主要取决于天气情况。而天气状况有晴,云和雨;气温用华氏温度表示;相对湿度用百分比;还有有无风。如此,我们便可以构造一棵决策树,如下(根据天气这个分类决策这天是否合适打网球):
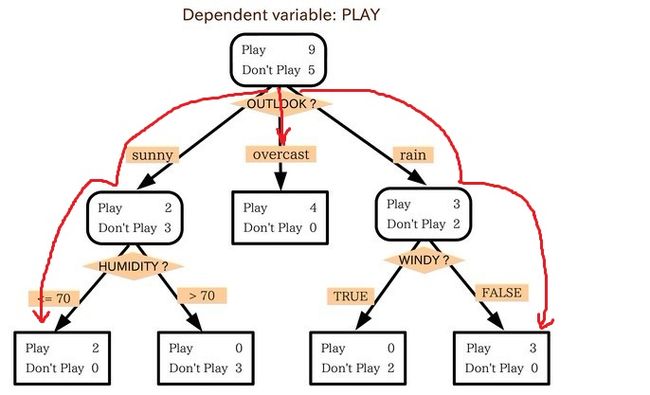
上述决策树对应于以下表达式:
(Outlook=Sunny ^Humidity<=70)V (Outlook = Overcast)V (Outlook=Rain ^ Wind=Weak)
1.2、ID3算法
1.2.1、决策树学习之ID3算法
ID3算法是决策树算法的一种。想了解什么是ID3算法之前,我们得先明白一个概念:奥卡姆剃刀。
- 奥卡姆剃刀(Occam's Razor, Ockham's Razor),又称“奥坎的剃刀”,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。简单点说,便是:be simple。
OK,从信息论知识中我们知道,期望信息越小,信息增益越大,从而纯度越高。ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益(很快,由下文你就会知道信息增益又是怎么一回事)最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策树空间。
所以,ID3的思想便是:
- 自顶向下的贪婪搜索遍历可能的决策树空间构造决策树(此方法是ID3算法和C4.5算法的基础);
- 从“哪一个属性将在树的根节点被测试”开始;
- 使用统计测试来确定每一个实例属性单独分类训练样例的能力,分类能力最好的属性作为树的根结点测试(如何定义或者评判一个属性是分类能力最好的呢?这便是下文将要介绍的信息增益,or 信息增益率)。
- 然后为根结点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支(也就是说,样例的该属性值对应的分支)之下。
- 重复这个过程,用每个分支结点关联的训练样例来选取在该点被测试的最佳属性。
这形成了对合格决策树的贪婪搜索,也就是算法从不回溯重新考虑以前的选择。
下图所示即是用于学习布尔函数的ID3算法概要:

1.2.2、哪个属性是最佳的分类属性
为了精确地定义信息增益,我们先定义信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度(purity)。给定包含关于某个目标概念的正反样例的样例集S,那么S相对这个布尔型分类的熵为:
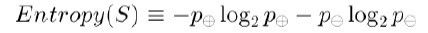
上述公式中,p+代表正样例,比如在本文开头第二个例子中p+则意味着去打羽毛球,而p-则代表反样例,不去打球(在有关熵的所有计算中我们定义0log0为0)。
如果写代码实现熵的计算,则如下所示:
//根据具体属性和值来计算熵 double ComputeEntropy(vector举例来说,假设S是一个关于布尔概念的有14个样例的集合,它包括9个正例和5个反例(我们采用记号[9+,5-]来概括这样的数据样例),那么S相对于这个布尔样例的熵为:
Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。

Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例。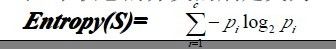
2、信息增益度量期望的熵降低
信息增益Gain(S,A)定义
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准。这个标准被称为“信息增益(information gain)”。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低(或者说,样本按照某属性划分时造成熵减少的期望)。更精确地讲,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:

其中 Values(A)是属性A所有可能值的集合,是S中属性A的值为v的子集。换句话来讲,Gain(S,A)是由于给定属性A的值而得到的关于目标函数值的信息。当对S的一个任意成员的目标值编码时,Gain(S,A)的值是在知道属性A的值后可以节省的二进制位数。
接下来,有必要提醒读者一下:关于下面这两个概念 or 公式,
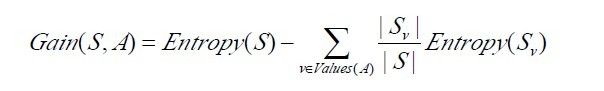
下面,举个例子,假定S是一套有关天气的训练样例,描述它的属性包括可能是具有Weak和Strong两个值的Wind。像前面一样,假定S包含14个样例,[9+,5-]。在这14个样例中,假定正例中的6个和反例中的2个有Wind =Weak,其他的有Wind=Strong。由于按照属性Wind分类14个样例得到的信息增益可以计算如下。

运用在本文开头举得第二个根据天气情况是否决定打羽毛球的例子上,得到的最佳分类属性如下图所示:
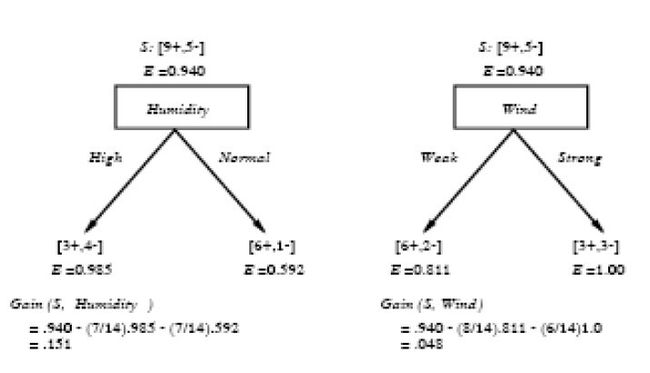
在上图中,计算了两个不同属性:湿度(humidity)和风力(wind)的信息增益,最终humidity这种分类的信息增益0.151>wind增益的0.048。说白了,就是在星期六上午是否适合打网球的问题诀策中,采取humidity较wind作为分类属性更佳,决策树由此而来。
//计算信息增益,DFS构建决策树 //current_node为当前的节点 //remain_state为剩余待分类的样例 //remian_attribute为剩余还没有考虑的属性 //返回根结点指针 Node * BulidDecisionTreeDFS(Node * p, vector1.2.3、ID3算法决策树的形成
OK,下图为ID3算法第一步后形成的部分决策树。这样综合起来看,就容易理解多了。1、overcast样例必为正,所以为叶子结点,总为yes;2、ID3无回溯,局部最优,而非全局最优,还有另一种树后修剪决策树。下图是ID3算法第一步后形成的部分决策树:
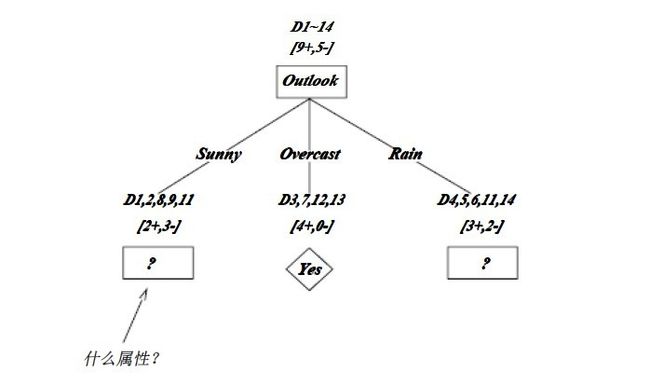
如上图,训练样例被排列到对应的分支结点。分支Overcast的所有样例都是正例,所以成为目标分类为Yes的叶结点。另两个结点将被进一步展开,方法是按照新的样例子集选取信息增益最高的属性。
1.3、C4.5算法
C4.5,是机器学习算法中的另一个分类决策树算法,它是决策树(决策树也就是做决策的节点间的组织方式像一棵树,其实是一个倒树)核心算法,也是上文1.2节所介绍的ID3的改进算法,所以基本上了解了一半决策树构造方法就能构造它。
决策树构造方法其实就是每次选择一个好的特征以及分裂点作为当前节点的分类条件。
既然说C4.5算法是ID3的改进算法,那么C4.5相比于ID3改进的地方有哪些呢?:
- 用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(entropy,熵是一种不纯度度量准则),也就是熵的变化值,而C4.5用的是信息增益率。对,区别就在于一个是信息增益,一个是信息增益率。
- 在树构造过程中进行剪枝,在构造决策树的时候,那些挂着几个元素的节点,不考虑最好,不然容易导致overfitting。
- 对非离散数据也能处理。
- 能够对不完整数据进行处理
针对上述第一点,解释下:一般来说率就是用来取平衡用的,就像方差起的作用差不多,比如有两个跑步的人,一个起点是10m/s的人、其10s后为20m/s;另一个人起速是1m/s、其1s后为2m/s。如果紧紧算差值那么两个差距就很大了,如果使用速度增加率(加速度,即都是为1m/s^2)来衡量,2个人就是一样的加速度。因此,C4.5克服了ID3用信息增益选择属性时偏向选择取值多的属性的不足。
C4.5算法之信息增益率
OK,既然上文中提到C4.5用的是信息增益率,那增益率的具体是如何定义的呢?:
是的,在这里,C4.5算法不再是通过信息增益来选择决策属性。一个可以选择的度量标准是增益比率gain ratio(Quinlan 1986)。增益比率度量是用前面的增益度量Gain(S,A)和分裂信息度量SplitInformation(S,A)来共同定义的,如下所示:
其中,分裂信息度量被定义为( 分裂信息用来衡量属性分裂数据的广度和均匀):
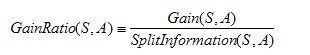
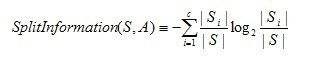
其中S1到Sc是c个值的属性A分割S而形成的c个样例子集。注意分裂信息实际上就是S关于属性A的各值的熵。这与我们前面对熵的使用不同,在那里我们只考虑S关于学习到的树要预测的目标属性的值的熵。
请注意,分裂信息项阻碍选择值为均匀分布的属性。例如,考虑一个含有n个样例的集合被属性A彻底分割(译注:分成n组,即一个样例一组)。这时分裂信息的值为log2n。相反,一个布尔属性B分割同样的n个实例,如果恰好平分两半,那么分裂信息是1。如果属性A和B产生同样的信息增益,那么根据增益比率度量,明显B会得分更高。
使用增益比率代替增益来选择属性产生的一个实际问题是,当某个Si接近S(|Si|»|S|)时分母可能为0或非常小。如果某个属性对于S的所有样例有几乎同样的值,这时要么导致增益比率未定义,要么是增益比率非常大。为了避免选择这种属性,我们可以采用这样一些启发式规则,比如先计算每个属性的增益,然后仅对那些增益高过平均值的属性应用增益比率测试(Quinlan 1986)。
除了信息增益,Lopez de Mantaras(1991)介绍了另一种直接针对上述问题而设计的度量,它是基于距离的(distance-based)。这个度量标准基于所定义的一个数据划分间的距离尺度。具体更多请参看:Tom M.Mitchhell所著的机器学习之3.7.3节。
1.3.2、C4.5算法构造决策树的过程
1.3.3、C4.5算法实现中的几个关键步骤
在上文中,我们已经知道了决策树学习C4.5算法中4个重要概念的表达,如下:
1.4、读者点评
- form Wind:决策树使用于特征取值离散的情况,连续的特征一般也要处理成离散的(而很多文章没有表达出决策树的关键特征or概念)。实际应用中,决策树overfitting比较的严重,一般要做boosting。分类器的性能上不去,很主要的原因在于特征的鉴别性不足,而不是分类器的好坏,好的特征才有好的分类效果,分类器只是弱相关。
- 那如何提高 特征的鉴别性呢?一是设计特征时尽量引入domain knowledge,二是对提取出来的特征做选择、变换和再学习,这一点是机器学习算法不管的部分(我说的这些不是针对决策树的,因此不能说是决策树的特点,只是一些机器学习算法在应用过程中的经验体会)。
第二部分、贝叶斯分类
昔人已乘黄鹤去,此地空余黄鹤楼;黄鹤一去不复返,白云千载空悠悠。
后便大为折服,已无什兴致再提了(偶现在就是这感觉),然文章还得继续写。So,本文第二部分之大部分基本整理自未鹏兄之手(做了部分改动),若有任何不妥之处,还望读者和未鹏兄海涵,谢谢。
2.1、什么是贝叶斯分类
贝叶斯定理:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:。
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理(公式被网友指出有问题,待后续验证改正):
2.2 贝叶斯公式如何而来
贝叶斯公式是怎么来的?下面是wikipedia 上的一个例子:
一所学校里面有 60% 的男生,40% 的女生。男生总是穿长裤,女生则一半穿长裤一半穿裙子。有了这些信息之后我们可以容易地计算“随机选取一个学生,他(她)穿长裤的概率和穿裙子的概率是多大”,这个就是前面说的“正向概率”的计算。然而,假设你走在校园中,迎面走来一个穿长裤的学生(很不幸的是你高度近似,你只看得见他(她)穿的是否长裤,而无法确定他(她)的性别),你能够推断出他(她)是男生的概率是多大吗?
一些认知科学的研究表明(《决策与判断》以及《Rationality for Mortals》第12章:小孩也可以解决贝叶斯问题),我们对形式化的贝叶斯问题不擅长,但对于以频率形式呈现的等价问题却很擅长。在这里,我们不妨把问题重新叙述成:你在校园里面随机游走,遇到了 N 个穿长裤的人(仍然假设你无法直接观察到他们的性别),问这 N 个人里面有多少个女生多少个男生。
你说,这还不简单:算出学校里面有多少穿长裤的,然后在这些人里面再算出有多少女生,不就行了?
我们来算一算:假设学校里面人的总数是 U 个。60% 的男生都穿长裤,于是我们得到了 U * P(Boy) * P(Pants|Boy) 个穿长裤的(男生)(其中 P(Boy) 是男生的概率 = 60%,这里可以简单的理解为男生的比例;P(Pants|Boy) 是条件概率,即在 Boy 这个条件下穿长裤的概率是多大,这里是 100% ,因为所有男生都穿长裤)。40% 的女生里面又有一半(50%)是穿长裤的,于是我们又得到了 U * P(Girl) * P(Pants|Girl) 个穿长裤的(女生)。加起来一共是 U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl) 个穿长裤的,其中有 U * P(Girl) * P(Pants|Girl) 个女生。两者一比就是你要求的答案。
下面我们把这个答案形式化一下:我们要求的是 P(Girl|Pants) (穿长裤的人里面有多少女生),我们计算的结果是 U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)] 。容易发现这里校园内人的总数是无关的,两边同时消去U,于是得到
P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
注意,如果把上式收缩起来,分母其实就是 P(Pants) ,分子其实就是 P(Pants, Girl) 。而这个比例很自然地就读作:在穿长裤的人( P(Pants) )里面有多少(穿长裤)的女孩( P(Pants, Girl) )。
上式中的 Pants 和 Boy/Girl 可以指代一切东西,So,其一般形式就是:
P(B|A) = P(A|B) * P(B) / [P(A|B) * P(B) + P(A|~B) * P(~B) ]
收缩起来就是:
P(B|A) = P(AB) / P(A)
其实这个就等于:
P(B|A) * P(A) = P(AB)
更进一步阐述,P(B|A)便是在条件A的情况下,B出现的概率是多大。然看似这么平凡的贝叶斯公式,背后却隐含着非常深刻的原理。
2.3、拼写纠正
经典著作《人工智能:现代方法》的作者之一 Peter Norvig 曾经写过一篇介绍如何写一个拼写检查/纠正器的文章,里面用到的就是贝叶斯方法,下面,将其核心思想简单描述下。
首先,我们需要询问的是:“问题是什么?”
问题是我们看到用户输入了一个不在字典中的单词,我们需要去猜测:“这个家伙到底真正想输入的单词是什么呢?”用刚才我们形式化的语言来叙述就是,我们需要求:
P(我们猜测他想输入的单词 | 他实际输入的单词)
这个概率。并找出那个使得这个概率最大的猜测单词。显然,我们的猜测未必是唯一的,就像前面举的那个自然语言的歧义性的例子一样;这里,比如用户输入: thew ,那么他到底是想输入 the ,还是想输入 thaw ?到底哪个猜测可能性更大呢?幸运的是我们可以用贝叶斯公式来直接出它们各自的概率,我们不妨将我们的多个猜测记为 h1 h2 .. ( h 代表 hypothesis),它们都属于一个有限且离散的猜测空间 H (单词总共就那么多而已),将用户实际输入的单词记为 D ( D 代表 Data ,即观测数据),于是
P(我们的猜测1 | 他实际输入的单词)
可以抽象地记为:
P(h1 | D)
类似地,对于我们的猜测2,则是 P(h2 | D)。不妨统一记为:
P(h | D)
运用一次贝叶斯公式,我们得到:
P(h | D) = P(h) * P(D | h) / P(D)
对于不同的具体猜测 h1 h2 h3 .. ,P(D) 都是一样的,所以在比较 P(h1 | D) 和 P(h2 | D) 的时候我们可以忽略这个常数。即我们只需要知道:
P(h | D) ∝ P(h) * P(D | h) (注:那个符号的意思是“正比例于”,不是无穷大,注意符号右端是有一个小缺口的。)
这个式子的抽象含义是:对于给定观测数据,一个猜测是好是坏,取决于“这个猜测本身独立的可能性大小(先验概率,Prior )”和“这个猜测生成我们观测到的数据的可能性大小”(似然,Likelihood )的乘积。具体到我们的那个 thew 例子上,含义就是,用户实际是想输入 the 的可能性大小取决于 the 本身在词汇表中被使用的可能性(频繁程度)大小(先验概率)和 想打 the 却打成 thew 的可能性大小(似然)的乘积。
剩下的事情就很简单了,对于我们猜测为可能的每个单词计算一下 P(h) * P(D | h) 这个值,然后取最大的,得到的就是最靠谱的猜测。更多细节请参看未鹏兄之原文。
2.4、贝叶斯的应用
2.4.1、中文分词
贝叶斯是机器学习的核心方法之一。比如中文分词领域就用到了贝叶斯。浪潮之巅的作者吴军在《数学之美》系列中就有一篇是介绍中文分词的。这里介绍一下核心的思想,不做赘述,详细请参考吴军的原文。
分词问题的描述为:给定一个句子(字串),如:
南京市长江大桥
如何对这个句子进行分词(词串)才是最靠谱的。例如:
1. 南京市/长江大桥
2. 南京/市长/江大桥
这两个分词,到底哪个更靠谱呢?
我们用贝叶斯公式来形式化地描述这个问题,令 X 为字串(句子),Y 为词串(一种特定的分词假设)。我们就是需要寻找使得 P(Y|X) 最大的 Y ,使用一次贝叶斯可得:
P(Y|X) ∝ P(Y)*P(X|Y)
用自然语言来说就是 这种分词方式(词串)的可能性 乘以 这个词串生成我们的句子的可能性。我们进一步容易看到:可以近似地将 P(X|Y) 看作是恒等于 1 的,因为任意假想的一种分词方式之下生成我们的句子总是精准地生成的(只需把分词之间的分界符号扔掉即可)。于是,我们就变成了去最大化 P(Y) ,也就是寻找一种分词使得这个词串(句子)的概率最大化。而如何计算一个词串:
W1, W2, W3, W4 ..
的可能性呢?我们知道,根据联合概率的公式展开:P(W1, W2, W3, W4 ..) = P(W1) * P(W2|W1) * P(W3|W2, W1) * P(W4|W1,W2,W3) * .. 于是我们可以通过一系列的条件概率(右式)的乘积来求整个联合概率。然而不幸的是随着条件数目的增加(P(Wn|Wn-1,Wn-2,..,W1) 的条件有 n-1 个),数据稀疏问题也会越来越严重,即便语料库再大也无法统计出一个靠谱的 P(Wn|Wn-1,Wn-2,..,W1) 来。为了缓解这个问题,计算机科学家们一如既往地使用了“天真”假设:我们假设句子中一个词的出现概率只依赖于它前面的有限的 k 个词(k 一般不超过 3,如果只依赖于前面的一个词,就是2元语言模型(2-gram),同理有 3-gram 、 4-gram 等),这个就是所谓的“有限地平线”假设。
虽然上面这个假设很傻很天真,但结果却表明它的结果往往是很好很强大的,后面要提到的朴素贝叶斯方法使用的假设跟这个精神上是完全一致的,我们会解释为什么像这样一个天真的假设能够得到强大的结果。目前我们只要知道,有了这个假设,刚才那个乘积就可以改写成: P(W1) * P(W2|W1) * P(W3|W2) * P(W4|W3) .. (假设每个词只依赖于它前面的一个词)。而统计 P(W2|W1) 就不再受到数据稀疏问题的困扰了。对于我们上面提到的例子“南京市长江大桥”,如果按照自左到右的贪婪方法分词的话,结果就成了“南京市长/江大桥”。但如果按照贝叶斯分词的话(假设使用 3-gram),由于“南京市长”和“江大桥”在语料库中一起出现的频率为 0 ,这个整句的概率便会被判定为 0 。 从而使得“南京市/长江大桥”这一分词方式胜出。
2.4.2、贝叶斯图像识别,Analysis by Synthesis
贝叶斯方法是一个非常 general 的推理框架。其核心理念可以描述成:Analysis by Synthesis (通过合成来分析)。06 年的认知科学新进展上有一篇 paper 就是讲用贝叶斯推理来解释视觉识别的,一图胜千言,下图就是摘自这篇 paper :

首先是视觉系统提取图形的边角特征,然后使用这些特征自底向上地激活高层的抽象概念(比如是 E 还是 F 还是等号),然后使用一个自顶向下的验证来比较到底哪个概念最佳地解释了观察到的图像。
2.4.3、最大似然与最小二乘

学过线性代数的大概都知道经典的最小二乘方法来做线性回归。问题描述是:给定平面上 N 个点,(这里不妨假设我们想用一条直线来拟合这些点——回归可以看作是拟合的特例,即允许误差的拟合),找出一条最佳描述了这些点的直线。
一个接踵而来的问题就是,我们如何定义最佳?我们设每个点的坐标为 (Xi, Yi) 。如果直线为 y = f(x) 。那么 (Xi, Yi) 跟直线对这个点的“预测”:(Xi, f(Xi)) 就相差了一个 ΔYi = |Yi – f(Xi)| 。最小二乘就是说寻找直线使得 (ΔY1)^2 + (ΔY2)^2 + .. (即误差的平方和)最小,至于为什么是误差的平方和而不是误差的绝对值和,统计学上也没有什么好的解释。然而贝叶斯方法却能对此提供一个完美的解释。
我们假设直线对于坐标 Xi 给出的预测 f(Xi) 是最靠谱的预测,所有纵坐标偏离 f(Xi) 的那些数据点都含有噪音,是噪音使得它们偏离了完美的一条直线,一个合理的假设就是偏离路线越远的概率越小,具体小多少,可以用一个正态分布曲线来模拟,这个分布曲线以直线对 Xi 给出的预测 f(Xi) 为中心,实际纵坐标为 Yi 的点 (Xi, Yi) 发生的概率就正比于 EXP[-(ΔYi)^2]。(EXP(..) 代表以常数 e 为底的多少次方)。
现在我们回到问题的贝叶斯方面,我们要想最大化的后验概率是:
P(h|D) ∝ P(h) * P(D|h)
又见贝叶斯!这里 h 就是指一条特定的直线,D 就是指这 N 个数据点。我们需要寻找一条直线 h 使得 P(h) * P(D|h) 最大。很显然,P(h) 这个先验概率是均匀的,因为哪条直线也不比另一条更优越。所以我们只需要看 P(D|h) 这一项,这一项是指这条直线生成这些数据点的概率,刚才说过了,生成数据点 (Xi, Yi) 的概率为 EXP[-(ΔYi)^2] 乘以一个常数。而 P(D|h) = P(d1|h) * P(d2|h) * .. 即假设各个数据点是独立生成的,所以可以把每个概率乘起来。于是生成 N 个数据点的概率为 EXP[-(ΔY1)^2] * EXP[-(ΔY2)^2] * EXP[-(ΔY3)^2] * .. = EXP{-[(ΔY1)^2 + (ΔY2)^2 + (ΔY3)^2 + ..]} 最大化这个概率就是要最小化 (ΔY1)^2 + (ΔY2)^2 + (ΔY3)^2 + .. 。 熟悉这个式子吗?
除了以上所介绍的之外,贝叶斯还在词义消岐,语言模型的平滑方法中都有一定应用。下节,咱们再来简单看下朴素贝叶斯方法。
2.5、朴素贝叶斯方法
朴素贝叶斯方法是一个很特别的方法,所以值得介绍一下。在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBC)。 朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
接下来,我们用朴素贝叶斯在垃圾邮件过滤中的应用来举例说明。
2.5.1、贝叶斯垃圾邮件过滤器
问题是什么?问题是,给定一封邮件,判定它是否属于垃圾邮件。按照先例,我们还是用 D 来表示这封邮件,注意 D 由 N 个单词组成。我们用 h+ 来表示垃圾邮件,h- 表示正常邮件。问题可以形式化地描述为求:
P(h+|D) = P(h+) * P(D|h+) / P(D)
P(h-|D) = P(h-) * P(D|h-) / P(D)
其中 P(h+) 和 P(h-) 这两个先验概率都是很容易求出来的,只需要计算一个邮件库里面垃圾邮件和正常邮件的比例就行了。然而 P(D|h+) 却不容易求,因为 D 里面含有 N 个单词 d1, d2, d3, .. ,所以P(D|h+) = P(d1,d2,..,dn|h+) 。我们又一次遇到了数据稀疏性,为什么这么说呢?P(d1,d2,..,dn|h+) 就是说在垃圾邮件当中出现跟我们目前这封邮件一模一样的一封邮件的概率是多大!开玩笑,每封邮件都是不同的,世界上有无穷多封邮件。瞧,这就是数据稀疏性,因为可以肯定地说,你收集的训练数据库不管里面含了多少封邮件,也不可能找出一封跟目前这封一模一样的。结果呢?我们又该如何来计算 P(d1,d2,..,dn|h+) 呢?
我们将 P(d1,d2,..,dn|h+) 扩展为: P(d1|h+) * P(d2|d1, h+) * P(d3|d2,d1, h+) * .. 。熟悉这个式子吗?这里我们会使用一个更激进的假设,我们假设 di 与 di-1 是完全条件无关的,于是式子就简化为 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 。这个就是所谓的条件独立假设,也正是朴素贝叶斯方法的朴素之处。而计算 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 就太简单了,只要统计 di 这个单词在垃圾邮件中出现的频率即可。关于贝叶斯垃圾邮件过滤更多的内容可以参考这个条目,注意其中提到的其他资料。
2.6、层级贝叶斯模型

层级贝叶斯模型是现代贝叶斯方法的标志性建筑之一。前面讲的贝叶斯,都是在同一个事物层次上的各个因素之间进行统计推理,然而层次贝叶斯模型在哲学上更深入了一层,将这些因素背后的因素(原因的原因,原因的原因,以此类推)囊括进来。一个教科书例子是:如果你手头有 N 枚硬币,它们是同一个工厂铸出来的,你把每一枚硬币掷出一个结果,然后基于这 N 个结果对这 N 个硬币的 θ (出现正面的比例)进行推理。如果根据最大似然,每个硬币的 θ 不是 1 就是 0 (这个前面提到过的),然而我们又知道每个硬币的 p(θ) 是有一个先验概率的,也许是一个 beta 分布。也就是说,每个硬币的实际投掷结果 Xi 服从以 θ 为中心的正态分布,而 θ 又服从另一个以 Ψ 为中心的 beta 分布。层层因果关系就体现出来了。进而 Ψ 还可能依赖于因果链上更上层的因素,以此类推。
第三部分、从EM算法到隐马可夫模型(HMM)
3.1、EM 算法与基于模型的聚类
在统计计算中,最大期望 (EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variabl)。最大期望经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。
通常来说,聚类是一种无指导的机器学习问题,如此问题描述:给你一堆数据点,让你将它们最靠谱地分成一堆一堆的。聚类算法很多,不同的算法适应于不同的问题,这里仅介绍一个基于模型的聚类,该聚类算法对数据点的假设是,这些数据点分别是围绕 K 个核心的 K 个正态分布源所随机生成的,使用 Han JiaWei 的《Data Ming: Concepts and Techniques》中的图:

图中有两个正态分布核心,生成了大致两堆点。我们的聚类算法就是需要根据给出来的那些点,算出这两个正态分布的核心在什么位置,以及分布的参数是多少。这很明显又是一个贝叶斯问题,但这次不同的是,答案是连续的且有无穷多种可能性,更糟的是,只有当我们知道了哪些点属于同一个正态分布圈的时候才能够对这个分布的参数作出靠谱的预测,现在两堆点混在一块我们又不知道哪些点属于第一个正态分布,哪些属于第二个。反过来,只有当我们对分布的参数作出了靠谱的预测时候,才能知道到底哪些点属于第一个分布,那些点属于第二个分布。这就成了一个先有鸡还是先有蛋的问题了。为了解决这个循环依赖,总有一方要先打破僵局,说,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终收敛到一个解。这就是 EM 算法。
EM 的意思是“Expectation-Maximazation”,在这个聚类问题里面,我们是先随便猜一下这两个正态分布的参数:如核心在什么地方,方差是多少。然后计算出每个数据点更可能属于第一个还是第二个正态分布圈,这个是属于 Expectation 一步。有了每个数据点的归属,我们就可以根据属于第一个分布的数据点来重新评估第一个分布的参数(从蛋再回到鸡),这个是 Maximazation 。如此往复,直到参数基本不再发生变化为止。这个迭代收敛过程中的贝叶斯方法在第二步,根据数据点求分布的参数上面。
3.2、隐马可夫模型(HMM)
大多的书籍或论文都讲不清楚这个隐马可夫模型(HMM),包括未鹏兄之原文也讲得不够具体明白。接下来,我尽量用直白易懂的语言阐述这个模型。然在介绍隐马可夫模型之前,有必要先行介绍下单纯的马可夫模型(本节主要引用:统计自然语言处理,宗成庆编著一书上的相关内容)。
3.2.1、马可夫模型
我们知道,随机过程又称随机函数,是随时间而随机变化的过程。马可夫模型便是描述了一类重要的随机过程。我们常常需要考察一个随机变量序列,这些随机变量并不是相互独立的(注意:理解这个非相互独立,即相互之间有千丝万缕的联系)。
如果此时,我也搞一大推状态方程式,恐怕我也很难逃脱越讲越复杂的怪圈了。所以,直接举例子吧,如,一段文字中名词、动词、形容词三类词性出现的情况可由三个状态的马尔科夫模型描述如下:
状态s1:名词
状态s2:动词
状态s3:形容词
假设状态之间的转移矩阵如下:
s1 s2 s3s1 0.3 0.5 0.2
A = [aij] = s2 0.5 0.3 0.2
s3 0.4 0.2 0.4
如果在该段文字中某一个句子的第一个词为名词,那么根据这一模型M,在该句子中这三类词出现顺序为O="名动形名”的概率为:
P(O|M)=P(s1,s2,s3,s1 | M) = P(s1) × P(s2 | s1) * P(s3 | s2)*P(s1 | s3)=1* a12 * a23 * a31=0.5*0.2*0.4=0.004
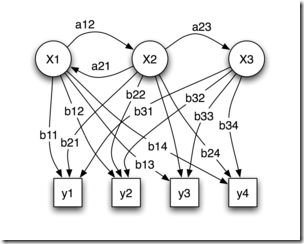
马尔可夫模型又可视为随机的有限状态机。马尔柯夫链可以表示成状态图(转移弧上有概率的非确定的有限状态自动机),如下图所示,
在上图中,圆圈表示状态,状态之间的转移用带箭头的弧表示,弧上的数字为状态转移的概率,初始状态用标记为start的输入箭头表示,假设任何状态都可作为终止状态。图中零概率的转移弧省略,且每个节点上所有发出弧的概率之和等于1。从上图可以看出,马尔可夫模型可以看做是一个转移弧上有概率的非确定的有限状态自动机。
3.2.2、隐马可夫模型(HMM)
在上文介绍的马可夫模型中,每个状态代表了一个可观察的事件,所以,马可夫模型有时又称作视马可夫模型(VMM),这在某种程度上限制了模型的适应性。而在我们的隐马可夫模型(HMM)中,我们不知道模型所经过的状态序列,只知道状态的概率函数,也就是说,观察到的事件是状态的随机函数,因此改模型是一个双重的随机过程。其中,模型的状态转换是不可观察的,即隐蔽的,可观察事件的随机过程是隐蔽的状态过程的随机函数。
理论多说无益,接下来,留个思考题给读者:N 个袋子,每个袋子中有M 种不同颜色的球。一实验员根据某一概率分布选择一个袋子,然后根据袋子中不同颜色球的概率分布随机取出一个球,并报告该球的颜色。对局外人:可观察的过程是不同颜色球的序列,而袋子的序列是不可观察的。每只袋子对应HMM中的一个状态;球的颜色对应于HMM 中状态的输出。
3.2.2、HMM在中文分词、机器翻译等方面的具体应用
隐马可夫模型在很多方面都有着具体的应用,如由于隐马可夫模型HMM提供了一个可以综合利用多种语言信息的统计框架,因此,我们完全可以讲汉语自动分词与词性标注统一考察,建立基于HMM的分词与词性标注的一体化系统。
根据上文对HMM的介绍,一个HMM通常可以看做由两部分组成:一个是状态转移模型,一个是状态到观察序列的生成模型。具体到中文分词这一问题中,可以把汉字串或句子S作为输入,单词串Sw为状态的输出,即观察序列,Sw=w1w2w3...wN(N>=1),词性序列St为状态序列,每个词性标记ct对应HMM中的一个状态qi,Sc=c1c2c3...cn。
那么,利用HMM处理问题问题恰好对应于解决HMM的三个基本问题:
- 估计模型的参数;
- 对于一个给定的输入S及其可能的输出序列Sw和模型u=(A,B,*),快速地计算P(Sw|u),所有可能的Sw中使概率P(Sw|u)最大的解就是要找的分词效果;
- 快速地选择最优的状态序列或词性序列,使其最好地解释观察序列。
参考文献
- 机器学习,Tom M.Mitchhell著;
- 数据挖掘导论,[美] Pang-Ning Tan / Michael Steinbach / Vipin Kumar 著;
- 数据挖掘领域十大经典算法初探;
- 数学之美番外篇:平凡而又神奇的贝叶斯方法(本文第二部分、贝叶斯分类主要来自此文)。
- http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html;
- 数学之美:http://www.google.com.hk/ggblog/googlechinablog/2006/04/blog-post_2507.html;
- 决策树ID3分类算法的C++实现 & yangliuy:http://blog.csdn.net/yangliuy/article/details/7322015;
- 统计自然语言处理,宗成庆编著(本文第三部分之HMM主要参考此书);
- 推荐引擎算法学习导论;
- 支持向量机导论,[美] Nello Cristianini / John Shawe-Taylor 著;
- 一堆 Wikipedia 条目,一堆 paper ,《机器学习与人工智能资源导引》。
后记
促成自己写这篇文章乃至整个聚类 & 分类算法系列的有3个因素,
- 一的确是如本文开头所说,在最近参加的一些面试中被问到描述自己所知道或了解的聚类 & 分类算法(当然,这完全不代表你将来的面试中会遇到此类问题,只是因为我的简历上写了句:熟悉常见的聚类 & 分类算法而已),
- 二则是之前去一家公司面试,他们有数据挖掘工程师的岗位,原来是真有那么一群人是专门负责数据分析,算法决策与调研的,情不自禁的对数据挖掘产生了兴趣;
- 三则是手头上有两本这样的经典书籍:机器学习 & 数据挖掘导论,看看又何妨呢,看的同时写写文章,做做笔记,备忘录又有何不可呢?
(Machine Learning & Data Mining交流群:8986884,需严格验证,非专业者拒入)
研究了一年有余的数据结构方面的算法,现在可以逐渐转向应用方面(机器学习 & 数据挖掘)的算法学习了。OK,本文或本聚类 & 分类算法系列中任何一篇文章有任何问题,漏洞,或bug,欢迎任何读者随时不吝赐教 & 指正,感谢大家,谢谢。完。July、二零一二年五月十八日凌晨二点半。
这些东西现在只是一个大致粗略的预览学习,以后若有机会,都会逐一更进一步深入(每一个分类方法或算法都足以写成一本书)。
预告
- 下一篇写支持向量机SVM与神经网络。其中,SVM理论较为复杂,一方面既然要写我讨厌仅对其浅尝辄止,另一方面,我更讨厌一篇文章除了堆砌数学公式看不到其它(在我眼里,这类paper基本属于只供孤芳自赏的废品),故我打算写SVM时分三个层次,什么样的人理解到什么样的层次上,如此,照顾深浅度不同的读者。July、二零一二年五月二十二日凌晨二点半。