磁盘IOPS
-----基础有时候总是枯燥,需要耐心的阅读和思考,本章知识大部来源于日常学习的积累-----
性能测试过程中经常会遇到磁盘的IOPS到达瓶颈,那么IOPS为什么会出现瓶颈呢,我们有该如何进行优化呢?还要从磁盘的基本知识说起。
首先,让我们一起来了解一下磁盘的一些基本知识:
存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
(1)硬盘有数个盘片,每盘片两个面,每个面一个磁头
(2)盘片被划分为多个扇形区域即扇区
(3)同一盘片不同半径的同心圆为磁道
(4)不同盘片相同半径构成的圆柱面即柱面
(5)公式: 存储容量=磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
(6)信息记录可表示为:××磁道(柱面),××磁头,××扇区
一般普通磁盘(每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息)(一般普通磁盘是最多16个ZBR(ZonedBitRecording分区域记录))(128B/256B/512B/1024B —1k/2048B —2k/4096B —4k/8192B —8k/16k/32k/64k/128K/256K/512K/1024K/2048k/4096K)
默认的情况下,在格式化的时侯,如果没有指定簇的大小,那么系统会根据分区的大小选择默认的簇值(NTFS支持512/1024/2048/4096/8192/16K/32K/64KB)
在文件系统中,簇的大小会影响到磁盘文件的排列,设置适当的簇大小,可以减少磁盘空间丢失和分区上碎片的数量。
上面提到的是磁盘的一般属性,这些属性再加上磁盘的转速,我们可以得到一个值:
磁盘转速x最小存储单元(簇)
例如:7200转(7200rpm)磁盘,NTFS文件系统64KB簇分区
吞吐量MAX:7200/60(S) x 64KB/1024 (MB)= 7.5 M/S
15K RPM磁盘,
吞吐量MAX:15000/60(S) x 64KB/1024 (MB)= 15M/S
当然这是理论上硬盘支持的最大值,而实际操作系统或软件系统对硬盘的读写会有不同的读写方式和方法,也就是算法。(简单来分就是同步IO和异步IO)(这里需要注意磁盘的IOPS 和主机/操作系统的IO是不一样的,后面再逐渐介绍)。
磁盘IOPS:是指存储设备(一般是磁盘或磁盘阵列)每秒可接受多少次主机发出的访问。主机的一次IO需要多次访问存储才可以完成。一般主机写入一个最小的数据块,也要经过“发送写入请求、写入数据、收到写入确认”等三个步骤,也就是3个存储端访问。
由于硬盘的限制,每个物理硬盘能处理的IOPS是有限制的,如:
10 K rpm 硬盘,一般情况下IOPS限制为100
15 K rpm 硬盘,一般情况下IOPS限制为150
普通ATA 硬盘,一般情况下IOPS限制为50
IOPS的高低主要取决于阵列的算法,cache命中率,以及磁盘个数。cache的命中率取决于数据的分布,cache size的大小,数据访问的规则,以及cache的算法。如果一个阵列,读cache的命中率越高越好,一般表示它可以支持更多的IOPS。
举一个(摘录来的)例子:
假定一个case,业务的iops是10000,读cache命中率是30%,读iops为60%,写iops为40%,磁盘个数为120,那么分别计算在raid5与raid10的情况下,每个磁盘的iops为多少。
raid5:
单块盘的iops = (10000*(1-0.3)*0.6 + 4 * (10000*0.4))/120
= (4200 + 16000)/120
= 168
这里的10000*(1-0.3)*0.6表示是读的iops,比例是0.6,除掉cache命中,实际只有4200个iops
而4 * (10000*0.4) 表示写的iops,因为每一个写,在raid5中,实际发生了4个io,所以写的iops为16000个
为了考虑raid5在写操作的时候,那2个读操作也可能发生命中,所以更精确的计算为:
单块盘的iops = (10000*(1-0.3)*0.6 + 2 * (10000*0.4)*(1-0.3) + 2 * (10000*0.4))/120
= (4200 + 5600 + 8000)/120
= 148
计算出来单个盘的iops为148个,基本达到磁盘极限
raid10
单块盘的iops = (10000*(1-0.3)*0.6 + 2 * (10000*0.4))/120
= (4200 + 8000)/120
= 102
可以看到,因为raid10对于一个写操作,只发生2次io,所以,同样的压力,同样的磁盘,每个盘的iops只有102个,还远远低于磁盘的极限iops。
在一个实际的case中,一个恢复压力很大的standby(这里主要是写,而且是小io的写),采用了raid5的方案,发现性能很差,通过分析,每个磁盘的iops在高峰时期,快达到200了,导致响应速度巨慢无比。后来改造成raid10,就避免了这个性能问题,每个磁盘的iops降到100左右。
当然,我们要做优化,除了需要了解磁盘和磁盘整列的算法以外,这些限制条件下,我们还可以对操作系统或者软件系统的算法进行优化,这就需要了解操纵系统的IO了。
操作系统IO
有很多资料上介绍了5种操作系统IO模型:阻塞IO/非阻塞IO/IO复用/信号驱动IO/异步IO。
在了解这些之前我们需要先了解一下操作系统的资源调度的一些概念,以Linux系统为例,我们来了解一下内核空间和用户空间:
Linux操作系统包括内核空间和用户空间(或者说内核态和用户态),内核空间主要存放的是内核代码和数据,是供系统进程使用的空间。而用户空间主要存放的是用户代码和数据,是供用户进程使用的空间。目前Linux系统简化了分段机制,使得虚拟地址与线性地址总是保持一致,因此,Linux系统的虚拟地址也是0~4G。Linux系统将这4G空间分为了两个部分:将最高的1G空间(从虚拟地址0xC0000000到0xFFFFFFFF)供内核使用,即为“内核空间”,而将较低的3G空间(从虚拟地址 0x00000000到0xBFFFFFFF)供用户进程使用,即为“用户空间”。同时由于每个用户进程都可以通过系统调用进入到内核空间,因此Linux的内核空间可以认为是被所有用户进程所共享的,因此对于一个具体用户进程来说,它可以访问的虚拟内存地址就是0~4G。另外Linux系统分为了四种特权级:0~3,主要是用来保护资源。0级特权最高,而3级则为最低,系统进程主要运行在0级,用户进程主要运行在3级。
一般来说,IO操作都分为两个阶段,就拿套接口的输入操作来说,它的两个阶段主要是:1)等待网络数据到来,当分组到来时,将其拷贝到内核空间的临时缓冲区中; 2)将内核空间临时缓冲区中的数据拷贝到用户空间缓冲区中;
5种操作系统IO模型
1、阻塞IO
默认情况下,所有套接口都是阻塞的。
假如recvfrom函数是一个系统调用:
###

说明:任何一个系统调用都会产生一个由用户态到内核态切换,再从内核态到用户态切换的过程,而进程(后面再逐渐介绍操作系统的进程调度)上下文切换是通过系统中断程序来实现的,需要保存当前进程的上下文状态,这是一个极其费力的过程。
2、非阻塞IO
当我们把套接口设置成非阻塞时,就是由用户进程不停地询问内核某种操作是否准备就绪,这就是我们常说的“轮询”。这同样是一件比较浪费CPU的方式。
###

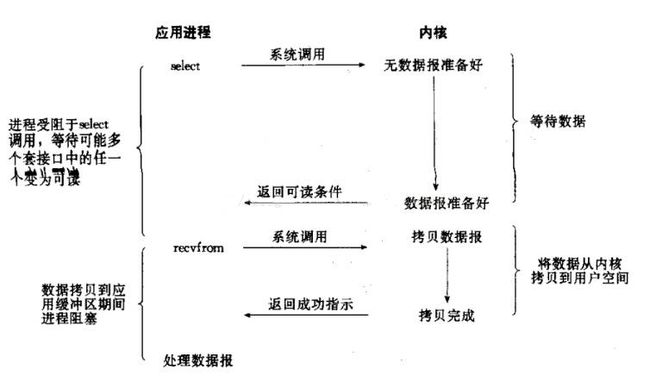
3、IO复用
我们常用到的IO复用,主要是select和poll。这里同样是会阻塞进程的,但是这里进程是阻塞在select或者poll这两个系统调用上,而不是阻塞在真正的IO操作上。
另外还有一点不同于阻塞IO的就是,尽管看起来与阻塞IO相比,这里阻塞了两次,但是第一次阻塞在select上时,select可以监控多个套接口上是否已有IO操作准备就绪的,而不是像阻塞IO那种,一次性只能监控一个套接口。
#####
4、信号驱动IO
信号驱动IO就是说我们可以通过sigaction系统调用注册一个信号处理程序,然后主程序可以继续向下执行,当我们所监控的套接口有IO操作准备就绪时,由内核通知触发前面注册的信号处理程序执行,然后将我们所需要的数据从内核空间拷贝到用户空间。
####

5、异步IO
异步IO与信号驱动IO最主要的区别就是信号驱动IO是由内核通知我们何时可以进行IO操作了,而异步IO则是由内核告诉我们IO操作何时完成了。具体来说就是,信号驱动IO当内核通知触发信号处理程序时,信号处理程序还需要阻塞在从内核空间缓冲区拷贝数据到用户空间缓冲区这个阶段,而异步IO直接是在第二个阶段完成后内核直接通知可以进程后续操作了。
######
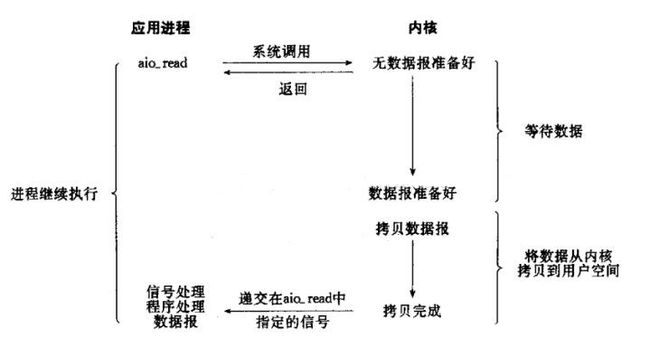
我们发现 前四种IO模型的主要区别是在第一阶段,因为它们的第二阶段都是在阻塞等待数据由内核空间拷贝到用户空间;而异步IO很明显与前面四种有所不同,它在第一阶段和第二阶段都不会阻塞。具体参考如下:
####

最后,总结下同步IO与异步IO的区别:
1)同步IO操作会引起进程阻塞直到IO操作完成。
2)异步IO操作不引起进程阻塞。
由上面引用这么多知识,我们大概可以了解到:
性能测试中IOPS是一项重要的性能监控指标,磁盘IO限制和操作系统以及软件系统的IO算法都会对我们整个的业务系统产生性能影响,我们在做性能测试的时候,要综合考虑从这些方面:
(1) 硬件磁盘的转速(硬件设备)
(2) 磁盘个数(硬件设备)
(3) 磁盘阵列(算法)
(4) 磁盘的文件系统(分区结构算法)
(5) 操作系统和软件系统读写(异步读写,批量读写等)
来进行优化。