tenforflow实战谷歌深度学习框架
图像识别与卷积神经网络
- 神经网络:全连接层网络结构,卷积神经网络,循环神经网络(第八章介绍)
- 全连接层网络结构:神经网络层中的邻接层的节点都与相邻的节点相连接
- 卷积神经网络:和全连接层中的神经网络整体结构差不多,但是结构还是有很大的差别。卷积神经网络相邻两层之间只有部分节点相连,为了展示每一层神经元的维度,一般会将每一层卷积层的节点组成一个三位矩阵。卷积网络的输入层就可以是图像原始像素,输出层的每一个节点代表了不同类别的可信度,
- 两者的后面的区别在于神经网络中相邻两层的连接方式。
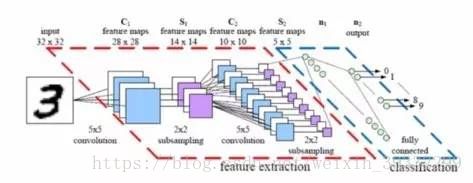
上图简单的介绍了卷积神经网络的架构图,包括卷积层,池化层,全连接层,softmax层
- 输入层:就是整个神经网络的输入,在RGB色彩模式下,图像深度为3,从输入层开始,卷积神经网络通过不同的神经网络结构将上一层三维矩阵转化为下一层的三维举证,直到最后的全连接层。
- 卷积层:卷积层每隔节点的输入只是上一层的一小块,这个小块一般是3或5的正方形,试图从更深层次地分析,而得到抽象程度更高地特征,一般来说,通过卷积层处理过的节点矩阵会变得更深
- 池化层:(pooling)池化层神经网络不会改变三维矩阵的深度,但是可以缩小矩阵的大小。可以简单的认为是将高分辨率的图变为低分辨率的图,可以缩小最后全连接层的节点个数,从而减少整个神经网络的参数。
- 全连接层:最后,在整个卷积神经网络架构中,还需要1-2个全连接层来进行分类,前面卷积和池化的过程可以看作是信息含量更高的特征,而后者可以将信息进行分类。
- sofemax层:也是主要用于分类的问题。
卷积层:
池化层:
之后,书上简单介绍了inception-v3模型及与之相关的一个迁移学习,
迁移学习: 将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。
下面是代码,
import glob
import os
import numpy as np
from tensorflow.python.platform import gfile
import random
import tensorflow as tf
BOTTLENECK_TENSOR_SIZE = 2048
# inception-v3 model's the bottleneck
# inception-v3模型中,张量名称是pool_3/_reshape:0
# 训练模型时,可以使用tensor.name来获取
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
# 图片输入张量所对应的名称
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
# 谷歌训练好的inception-v3模型的文件陌路
MODEL_DIR = 'F:\code\python\inception-v3-transfer_learning'
# 下载好的模型文件铭
MODEL_FILE = 'F://code//python//inception-v3-transfer_learning//inception_dec_2015//tensorflow_inception_graph.pb'
# 因为一个模型会使用很多次,所以可以将原始图像通过inception-v3模型计算得到特征
# 向量保存到文件中,
CACHE_DIR = '/tmp/bottleneck'
# 图片数据文件夹,在这个文件夹中的每隔子文件夹代表一个需要区分的类别,每隔子文件夹中存放了相应的图片
INPUT_DATA = 'F://code//python//inception-v3-transfer_learning//flower_photos//'
# 验证的数据百分比
VALIDATION_PERCENTAGE = 10
# 测试数据的百分比
TEST_PERCENTAGE = 10
# 定义神经网络的设置
LEARNING_RATE = 0.01
STEPS = 4000
BATCH = 100
# 这个函数从文件夹
# test_percentage和validation_percentage设置了测试数据集和验证数据集的大小
def creat_image_lists(testing_percentage, validation_percentage):
# 得到的所有图片都会存放在result,
result = {}
# 获取当前目录下的所有子目录
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# 得到的第一个目录为当前目录
is_root_dir = True
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
# 获取当前目录下所有有效图片文件
extensions = ['jpg', 'jpeg', 'png', 'JPG', "JPEG"]
file_list = []
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extension)
file_list.extend(glob.glob(file_glob))
if not file_list: continue
# 通过目录名获取类别的名称
label_name = dir_name.lower()
# 初始化当前类别的训练数据集,测试数据集,验证数据集
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name)
# 随机将数据分到训练数据集、测试数据集、验证数据集
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (testing_percentage + validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
# 将当前类别的数据放入结果字典
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images,
}
return result
"""
这个函数通过类别名称,所属数据集,和图片编号获取了一张图片的地址,
image_list gets the all information of the images
image_dir gives the root dir
label_name gives the name of label
index gives the number of the images
category gives the image is in the training_images , testing_images or validation_images
"""
def get_image_path(image_lists, image_dir, label_name, index, category):
# 获取给定类别中所有图片的信息
label_lists = image_lists[label_name]
# 根据所属的数据集名称获取集合中的全部图片信息
category_list = label_lists[category]
mod_index = index % len(category_list)
# 获取两个文件名
base_name = category_list[mod_index]
sub_dir = label_lists['dir']
# 最终的地址上为数据根目录加上类别的文件夹加上图片的名称
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path
# 这个函数通过类别名称,所属数据集,图片编号经过inception-v3模型处理后的特征向量的地址
def get_bottleneck_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + 'txt'
# 这个函数使用加载的训练好的模型处理一张图片,得到这个图片的特征向量
def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
# 这个过程将当前图片作为bottleneck的值,这个值就是这个图片新的特征向量
bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
# 经过卷积神经网络处理后的结果是一个四维数组,可以压缩成为一个特征向量
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values
# 这个函数获取会获取一个图片,先去寻找特征向量,如果找不到的话,则会自己训练,之后产生新的特征向量,保存
def get_or_create_bottleneck(
sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):
# 获取一张图片,对应的特征向量文件的路径
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR, sub_dir)
if not os.path.exists(sub_dir_path): os.makedirs(sub_dir_path)
bottleneck_path = get_bottleneck_path(
image_lists, label_name, index, category
)
# 如果这个特征文件不存在,测创建一个
if not os.path.exists(bottleneck_path):
# 获取原始图片的路径
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
# 获取图片内容
image_data = gfile.FastGFile(image_path, 'rb').read()
# 通过inception模型获得特征向量
bottleneck_values = run_bottleneck_on_image(
sess, image_data, jpeg_data_tensor, bottleneck_tensor
)
# 将计算所得的特征向量存入文件
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
# 直接从文件中获取相应的特征向量
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
# return bottleneck_values
return bottleneck_values
# 随机获取一个batch的图片作为训练数据
def get_random_cached_bottlenecks(
sess, n_classes, image_lists, how_many, category, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
# 随机一个类别和图片的编号,加入当前的训练数据
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(65536)
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index, category, jpeg_data_tensor,
bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
# 这个函数获取全部的测试数据,在最终测试的时候需要在所有的数据上测试正确率
def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
label_name_list = list(image_lists.keys())
# 枚举所有的类别和每隔类别中的测试图片
for label_index, label_name in enumerate(label_name_list):
category = 'testing'
for index, unused_base_name in enumerate(image_lists[label_name][category]):
# 通过inception模型计算图片对应的特征向量,并将其加入最终数据的列表
bottleneck = get_or_create_bottleneck(sess,image_lists, label_name, index, category, jpeg_data_tensor,
bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths
def main(_):
# 读取所有图片
image_lists = creat_image_lists(TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
n_classes = len(image_lists.keys())
with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def, return_elements=[BOTTLENECK_TENSOR_NAME,
JPEG_DATA_TENSOR_NAME])
# 定义新的神经网输入,这个输入就是图片经过模型叨叨bottleneck layer的节点取值,可以将这一过程理解为特征提取
bottleneck_input = tf.placeholder(
tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder'
)
# 定义标准答案输入
ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')
# 定义一个全连接层
with tf.name_scope('final_training_op'):
weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.001))
bias = tf.Variable(tf.zeros([n_classes]))
logits = tf.matmul(bottleneck_input, weights) + bias
final_tensor = tf.nn.softmax(logits)
# 定义cross-entropy
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
# 计算正确率
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
# training procedure
for i in range(STEPS):
# 每次获取一个batch的数据
train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(sess, n_classes, image_lists, BATCH,
'training', jpeg_data_tensor,
bottleneck_tensor)
sess.run(train_step,
feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})
# 验证数据上测试的正确率
if i % 100 == 0 or i + 1 == STEPS:
validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'validation', jpeg_data_tensor, bottleneck_tensor
)
validation_accuracy = sess.run(
evaluation_step, feed_dict={
bottleneck_input: validation_bottlenecks,
ground_truth_input: validation_ground_truth
}
)
print('Step %d: Validtion accuracy on random sampled, %d examples = %.1f%%' % (
i, BATCH, validation_accuracy * 100))
# 最后的测试数据上测试正确率
test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor,
bottleneck_tensor)
test_accuracy = sess.run(evaluation_step, feed_dict={
bottleneck_input: test_bottlenecks,
ground_truth_input: test_ground_truth
})
print('Final test accuracy = %.1f%%' % (test_accuracy * 100))
if __name__ == '__main__':
tf.app.run()里面的东西可能需要修改一些路径,然后需要的数据在下面
结果如下
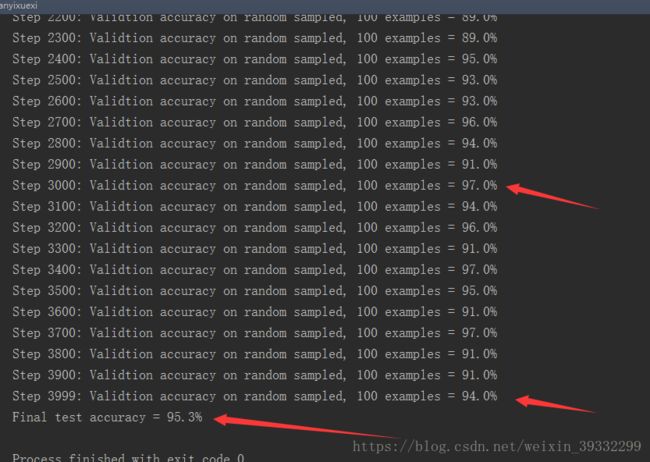
可以看出精确度不是很高