机器学习——Knn算法实现图片验证码识别
最近,莫名其妙实验要写机器学习入门——简单图片验证码识别,一头雾水,网上搜了一些资料总算实现了,记录下我的历程叭~
(主要沿用了TensorFlow里面的算法源码)
先说下实验要求吧:
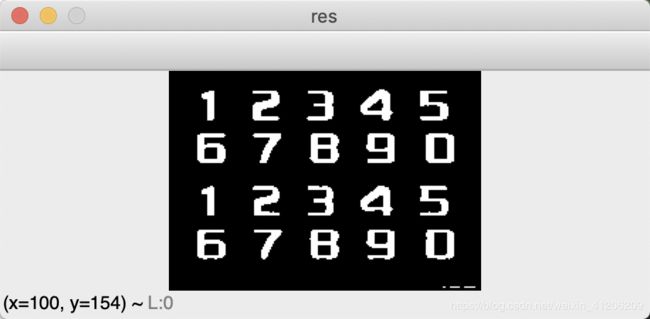
- 1.给了一张图片num01.jpg作为训练样本

- 2.从num02.jpg,num03.jpg中提取单个数字进行识别,并记录识别率


第一步:用OpenCV图像处理
1. 所使用的库:
pip3 install opencv-python
pip3 install numpy
2. 图片处理—对图片进行降噪、二值化处理:
(1)先读入样本图片,转为灰度图
im = cv2.imread(img_file)
im_gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
cv2.imshow('im_gray', im_gray)
cv2.waitKey(0)

(2) 二值化(像素值大于200被置成了0,小于200的被置成了255)
- 这里像素值是如何确定的呢?
鼠标点击即可查看图片中各点的像素,便于在二值化以及接下来的操作中设置阈值。
# 查看灰度值(以200为界)
def mouse_click(event, x, y, flags, para):
if event == cv2.EVENT_LBUTTONDOWN: # 左边鼠标点击
print('PIX:', x, y)
print("BGR:", im[y, x])
print("GRAY:", im_gray[y, x])
if __name__ == '__main__':
# 查看像素值,灰度值
'''
cv2.namedWindow("img")
cv2.setMouseCallback("img", mouse_click)
while True:
cv2.imshow('img', im_inv)
if cv2.waitKey() == ord('q'):
break
cv2.destroyAllWindows()

ret,im_inv = cv2.threshold(im_gray,235,255,cv2.THRESH_BINARY_INV)
cv2.imshow('inv',im_inv)
cv2.waitKey(0)
cv2.destroyAllWindows()

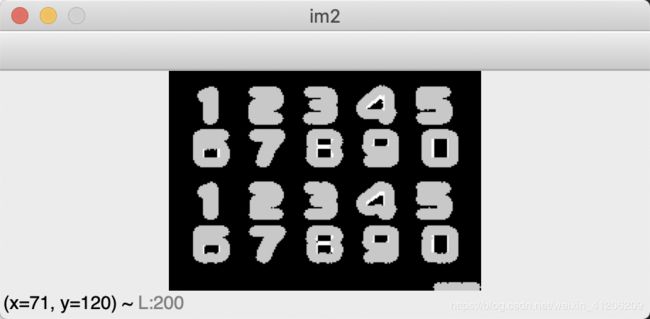
(3)降噪(应用高斯模糊对图片进行降噪),降噪后再一轮二值化
可以看到,降噪后一些颗粒化的噪声变得平滑了
但是事实上我最后测出来降噪后错误率反而比没降噪的高…
kernel = 1/16*np.array([[1,2,1], [2,4,2], [1,2,1]])
im_blur = cv2.filter2D(im_inv,-1,kernel)
ret, im_res = cv2.threshold(im_blur,127,255,cv2.THRESH_BINARY)
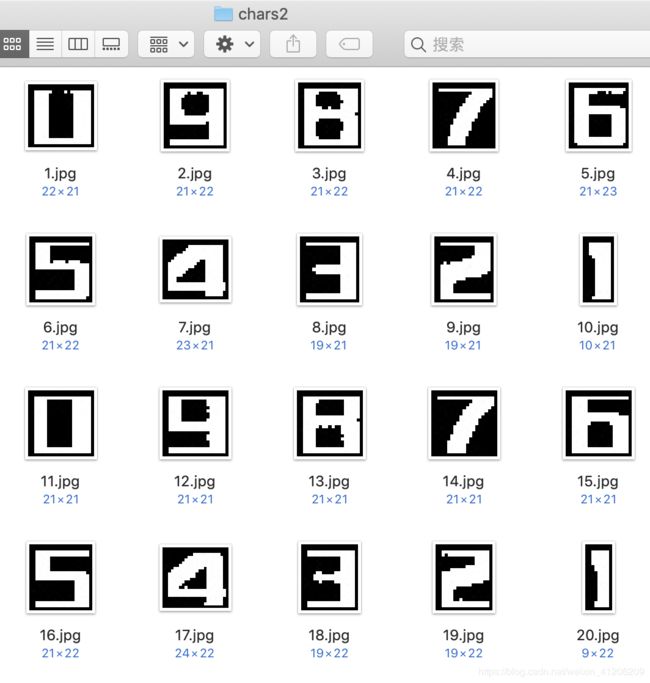
3. 切割——opencv最小外接矩阵形函数法
contours, hierarchy = cv2.findContours(im_inv, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# cv2.drawContours(im_inv,contours,-1,(200,200,0),5)
# cv2.imshow("im2", im_inv)
# cv2.waitKey(0)
flag = 1
for cnt in contours:
# 最小外接矩阵
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(im_inv, (x,y), (x+w,y+h), (0,100,0), 2)
# print((x, y, w, h))
size = im_inv[y:y+h, x:x+w].shape
# print(size)
if size > (20,20):
cv2.imwrite('/Users/freya/Downloads/Python的入门与/mnist/chars2/%s.jpg' % flag, im_inv[y:y+h, x:x+w])
flag +=1
这个就是画出来的最小外接矩阵
切割后在相应文件夹中进行验证:
4. 人工标注——每个数字建一个文件夹,里面每个数字有自己的编号

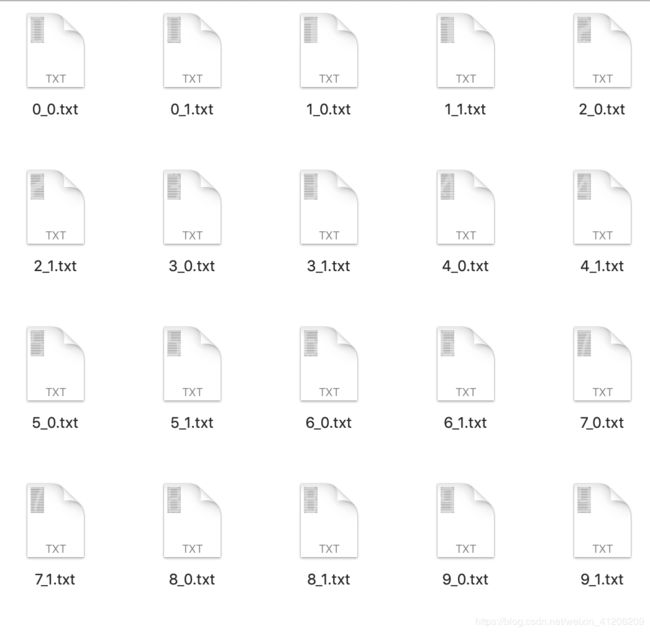
5. 图片数字化处理——转为二进制矩阵存为txt
def pictobin(n,m):
a = cv2.imread('/Users/freya/Downloads/Python的入门与/mnist/chars/%s/%s.jpg' % (n,m))
b = cv2.resize(a, (32, 32))
b = cv2.cvtColor(b, cv2.COLOR_BGR2GRAY)
ret, b = cv2.threshold(b, 240, 255, cv2.THRESH_BINARY_INV)
b = (b / 255).astype(np.int8)
b = 1 - b
f = open('/Users/freya/Downloads/Python的入门与/mnist/training/%s_%s.txt' % (n,m), 'w')
for i in b:
for j in i:
f.write(str(j))
f.write('\n')
f.close()
自动命名保存为txt文档:
最后,在主函数中可以分别把训练样本和测试样本的图片都预处理好保存在不同文件夹中
if __name__ == '__main__':
img_file = '/Users/freya/Downloads/Python的入门与/mnist/num01.jpg'
prectreat(img_file)
# 训练样本保存
for n in range(0,10):
for m in range(0,2):
pictobin(n,m)
# 测试样本保存
test_file = '/Users/freya/Downloads/Python的入门与/mnist/new_num03.jpg'
prectreat(test_file)
待测数据:

6.补充:前面做的都是白底黑字的灰度图,结果待测样本num03.jpg黑底白字,所以要对待测样本先做一个颜色反转
from PIL import Image
import PIL.ImageOps
#读入图片
image = Image.open('/Users/freya/Downloads/Python的入门与/mnist/num03.jpg')
#反转
inverted_image = PIL.ImageOps.invert(image)
#保存图片
inverted_image.save('new_num03.jpg')
效果如下:

然后重复上述步骤,直至待测样本的每个字符保存为txt文档在另一个文件夹中
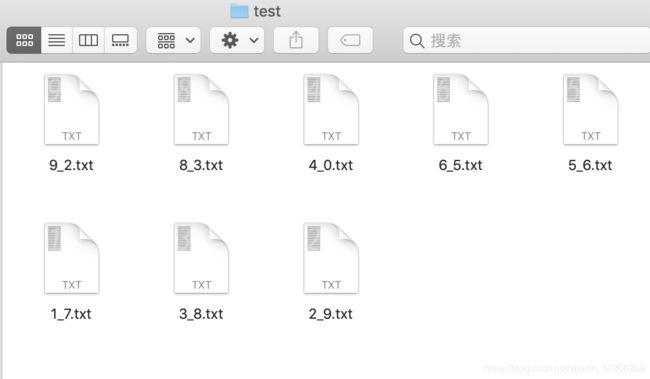
第二步:用KNN算法训练并测试
先简要说一下KNN算法的原理:
从训练样本集中选择k个与测试样本“距离”最近的样本,这k个样本中出现频率最高的类别即作为测试样本的类别。
-
KNN是属于有监督学习(因为训练集中每个数据都存在人工设置的标签——即类别)
-
那是如何进行分类的呢?
其实是用数据之间的欧氏距离来衡量它们的相似程度,距离越短,表示两个数据越相似。
欧式距离计算公式:
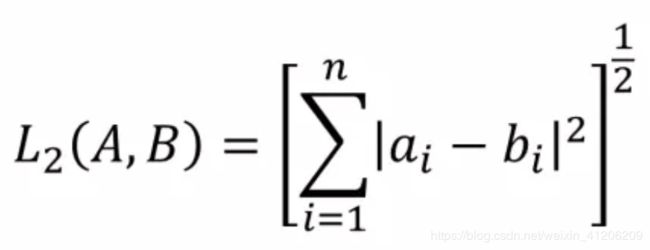
-
具体分类过程
(1)确定K值:通过寻找待测点的邻居
(2)根据欧氏距离,得出待分类数据点和所有已知类别的样本点中,距离最近的k个样本。
(3)统计这k个样本点中,各个类别的数量。由k个样本中数量最多的样本的类别,把这个数据点定为什么类别。
1.将每个图片(txt文本)转化为一个特征向量,即3232的数组转化为11024的数组
#文本向量化 32x32 -> 1x1024
def img2vector(filename):
returnVect = zeros((1,1024)) # 生成一个1*1024的array
fr = open(filename) # 使用open函数打开一个文本文件
for i in range(32): # 循环读取文件内容
lineStr = fr.readline() # 读取一行,返回字符串
for j in range(32): # 读取字符串0 或者 1
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
2.通过解析文件名获取分类类别
#从文件名中解析分类数字
def classnumCut(fileName):
fileStr = fileName.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
return classNumStr
3.构建训练集,将训练集图片合并成m*1024的大矩阵
# 构建训练集数据向量,及对应分类标签向量
def trainingDataSet():
# 定义一个列表,用于记录分类
hwLabels = []
trainingFileList = listdir('training') # 获取目录内容
m = len(trainingFileList) # 求文件长度
trainingMat = zeros((m,1024)) # m维向量的训练集:生成m*1024的array,每个文件分配1024个0
for i in range(m): # 对每个file
fileNameStr = trainingFileList[i] # 每个文件
hwLabels.append(classnumCut(fileNameStr))
trainingMat[i,:] = img2vector('training/%s' % fileNameStr) # 调用img2vector,将原文件写入trainingMat
return hwLabels,trainingMat
4. 计算欧式距离,并最终返回测试图片类别,即识别结果
def classify(inputPoint,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #已知分类的数据集(训练集)的行数
#先tile函数将输入点拓展成与训练集相同维数的矩阵,再计算欧氏距离
diffMat = tile(inputPoint,(dataSetSize,1))-dataSet #样本与训练集的差值矩阵
sqDiffMat = diffMat ** 2 #差值矩阵平方
sqDistances = sqDiffMat.sum(axis=1) #计算每一行上元素的和
distances = sqDistances ** 0.5 #开方得到欧拉距离矩阵
sortedDistIndicies = distances.argsort() #按distances中元素进行升序排序后得到的对应下标的列表
#选择距离最小的k个点
classCount = {}
for i in range(k):
voteIlabel = labels[ sortedDistIndicies[i] ]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
5. 测试函数
def handwritingTest():
hwLabels,trainingMat = trainingDataSet() #构建训练集
testFileList = listdir('test') #获取测试集
errorCount = 0.0 #错误数
mTest = len(testFileList) #测试集总样本数
t1 = time.time()
for i in range(mTest): # 遍历test文件
fileNameStr = testFileList[i] # test文件
classNumStr = classnumCut(fileNameStr)
# 转为1*1024
# 分类
vectorUnderTest = img2vector('test/%s' % fileNameStr)
#调用knn算法进行测试
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
# 计算误差
if (classifierResult != classNumStr):
errorCount += 1.0
print("\nthe total number of tests is: %d" % (mTest)) # 输出测试总样本数
print("the total number of errors is: %d" % errorCount) # 输出测试错误样本数
print("the total error rate is: %f" % (errorCount/float(mTest))) # 输出错误率
t2 = time.time()
print("Cost time: %.2fmin, %.4fs."%((t2-t1)//60,(t2-t1)%60)) # 测试耗时
全部代码:
#-*- coding: utf-8 -*-
from numpy import *
import operator
import time
from os import listdir
def classify(inputPoint,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #已知分类的数据集(训练集)的行数
#先tile函数将输入点拓展成与训练集相同维数的矩阵,再计算欧氏距离
diffMat = tile(inputPoint,(dataSetSize,1))-dataSet #样本与训练集的差值矩阵
sqDiffMat = diffMat ** 2 #差值矩阵平方
sqDistances = sqDiffMat.sum(axis=1) #计算每一行上元素的和
distances = sqDistances ** 0.5 #开方得到欧拉距离矩阵
sortedDistIndicies = distances.argsort() #按distances中元素进行升序排序后得到的对应下标的列表
#选择距离最小的k个点
classCount = {}
for i in range(k):
voteIlabel = labels[ sortedDistIndicies[i] ]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
#文本向量化 32x32 -> 1x1024
def img2vector(filename):
returnVect = zeros((1,1024)) # 生成一个1*1024的array
fr = open(filename) # 使用open函数打开一个文本文件
for i in range(32): # 循环读取文件内容
lineStr = fr.readline() # 读取一行,返回字符串
for j in range(32): # 读取字符串0 或者 1
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
#从文件名中解析分类数字
def classnumCut(fileName):
fileStr = fileName.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
return classNumStr
# 构建训练集数据向量,及对应分类标签向量
def trainingDataSet():
# 定义一个列表,用于记录分类
hwLabels = []
trainingFileList = listdir('training') # 获取目录内容
m = len(trainingFileList) # 求文件长度
trainingMat = zeros((m,1024)) # m维向量的训练集:生成m*1024的array,每个文件分配1024个0
for i in range(m): # 对每个file
fileNameStr = trainingFileList[i] # 每个文件
hwLabels.append(classnumCut(fileNameStr))
trainingMat[i,:] = img2vector('training/%s' % fileNameStr) # 调用img2vector,将原文件写入trainingMat
return hwLabels,trainingMat
#测试函数
def handwritingTest():
hwLabels,trainingMat = trainingDataSet() #构建训练集
testFileList = listdir('test') #获取测试集
errorCount = 0.0 #错误数
mTest = len(testFileList) #测试集总样本数
t1 = time.time()
for i in range(mTest): # 遍历test文件
fileNameStr = testFileList[i] # test文件
classNumStr = classnumCut(fileNameStr)
# 转为1*1024
# 分类
vectorUnderTest = img2vector('test/%s' % fileNameStr)
#调用knn算法进行测试
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
# 计算误差
if (classifierResult != classNumStr):
errorCount += 1.0
print("\nthe total number of tests is: %d" % (mTest)) # 输出测试总样本数
print("the total number of errors is: %d" % errorCount) # 输出测试错误样本数
print("the total error rate is: %f" % (errorCount/float(mTest))) # 输出错误率
t2 = time.time()
print("Cost time: %.2fmin, %.4fs."%((t2-t1)//60,(t2-t1)%60)) # 测试耗时
if __name__ == "__main__":
handwritingTest()
num03.jpg测试结果:

num02.jpg测试结果(翻车):
