手写WebServer服务器
文章目录
- 项目介绍
- 具体实现
- 初步搭建类和结构
- 测试浏览器与服务端的连接
- 服务端的三步曲
- 解析请求
- 处理请求
- 发送响应
- 状态码与对应的描述
- DOM4J读取xml文件
- 实现服务器功能之注册
- 实现服务器功能之登录
- 添加反射
- 结合服务器实战ATM项目遇到的问题
- 用户登入之后想立即看到自己的信息,如何实现
- 用户登入之后,可能会进行一系列的操作,比如修改个人的一些信息。当用户修改完后,点击返回主页面,如何将用户的信息立即同步到登录成功的主界面
- 心得总结
项目介绍
基于:Java EE、多线程、Socket网络编程、XML解析,反射
虽然要用到的东西不是很多,但是却充满了挑战。通过这个项目可以大致的了解浏览器与服务器之间的数据传递,请求是如何发送的,以及服务端又是如何处理请求,最后又是如何的发送响应。
具体实现
初步搭建类和结构
测试浏览器与服务端的连接
创建核心包 com.webserver.core
创建类WebServer,ClientHandler
package com.webserver.core;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
public class WebServer {
private ServerSocket server;
public WebServer() {
// 初始化server
try {
server = new ServerSocket(8088);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
try {
// 启动一个线程处理该客户端交互
Socket socket = server.accept();
//将socket传递给ClientHander
ClientHandler handler=new ClientHandler(socket);
Thread t=new Thread(handler);
t.start();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
WebServer server = new WebServer();
System.out.println("服务端开始启动");
server.start();
}
}
初始化server,启动线程处理与客户端的交互
package com.webserver.core;
import java.io.IOException;
import java.io.InputStream;
import java.net.Socket;
/**
* 用户处理客户端请求并予以响应的处理类
* http://localhost:8088/index.html
*/
public class ClientHandler implements Runnable{
private Socket socket;
public ClientHandler(Socket socket){
this.socket=socket;
}
public void run() {
System.out.println("一个客户端连接了");
try {
/**
* 获取输入流,用户读取客户端发送过来的内容,由于客户端(浏览器)发送过来的内容是Http协议规定的请求
* 请求的内容大部分为文本数据,且字符集为ISO8859-1,内容为英文很数字符号。还可能包含二进制数据
* 所以这里我们不能使用流链接字符的高级流,否则读取二进制数据部分时可能出现问题
*/
InputStream in=socket.getInputStream();
int d=-1;
while((d=in.read())!=-1){
char c=(char)d;
System.out.print(c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
测试一

打开浏览器,输入http://localhost:8088/index.html,可以看到,我们的WebServer成功的捕捉到了请求,同时我们也打印了浏览器发过来的请求。
服务端的三步曲
解析请求
科普HTTP请求格式
一个HTTP请求分为三部分组成:请求行,消息头,消息正文
1:请求行
请求行分为三部分:
请求方法 资源路径 协议(CRLF)
例如:
GET /index.html HTTP/1.1(CRLF)
请求行以CRLF结束
CR:回车符,asc编码中对应数字13
LF:换行符,asc编码中对应数字10
在ClientHander里面添加一个方法:readLine,用于测试通过输入流读取一行客户端发送过来的字符串
package com.webserver.core;
import java.io.IOException;
import java.io.InputStream;
import java.net.Socket;
/**
* 用户处理客户端请求并予以响应的处理类
*/
public class ClientHandler implements Runnable{
private Socket socket;
public ClientHandler(Socket socket){
this.socket=socket;
}
public void run() {
System.out.println("一个客户端连接了");
try {
/**
* 获取输入流,用户读取客户端发送过来的内容,由于客户端(浏览器)发送过来的内容是Http协议规定的请求
* 请求的内容大部分为文本数据,且字符集为ISO8859-1,内容为英文很数字符号。还可能包含二进制数据
* 所以这里我们不能使用流链接字符的高级流,否则读取二进制数据部分时可能出现问题
*/
InputStream in=socket.getInputStream();
String line=readLine(in);
System.out.println("line:"+line);
} catch (IOException e) {
e.printStackTrace();
}
}
//在ClientHander里面添加一个方法:readLine,用于测试通过输入流读取一行客户端发送过来的字符串
private String readLine(InputStream in) throws IOException{
StringBuilder builder=new StringBuilder();
int cur=-1;//本次读的字符串
int pre=-1;//上次读的字符串
while((cur=in.read())!=-1){
if(cur==10&&pre==13){
break;
}
builder.append((char)cur);
pre=cur;
}
return builder.toString().trim();
}
}
测试二

通过readLine方法,我们成功的拿到请求行
接下来进入了我们解析请求行了
新建一个包:com.webserver.http,在http包中新建类:HTTPRequest,即HTTP请求对象
在HttpRequest中定义请求对应的相关属性信息的构造方法,并且定义三个私有方法parseRequestLine, parseHeaders,parseContent
package com.webserver.http;
/**
* 请求对象
* 该类的每一个实例用于表示客户端发送过来的一个实际的HTTP请求内容
* 每个请求由三部分组成
* 1.请求行
* 2.消息头
* 3.消息正文(可以不包含)
* @author admin
*
*/
import java.io.IOException;
import java.io.InputStream;
import java.net.Socket;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HttpRequest {
/*
* 消息头的相关信息定义
*/
private Map<String,String> headers=new HashMap<String,String>();
/*
* 请求行相关消息定义
*/
//请求方式
private String method;
//请求路径
private String url;
//
private String protocol;
/*
* 定义与连接相关的属性
*/
private Socket socket;
private InputStream in;
public HttpRequest(Socket socket){
try {
this.socket=socket;
this.in=socket.getInputStream();
/*
*实例化一个HttpRequest要解析客户端发送过来的请求内容,并且分析其中每个部分
*1.解析请求行
*2.解析消息头
*3.解析消息正文
*/
parseRequestLine();
parseHeaders();
parseContext();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 解析请求行
*/
private void parseRequestLine(){
System.out.println("开始解析请求行");
/**
* 读一行字符串,即请求行的内容,将字符串按空格拆分三部分
* 分别设置到method,url,protocol属性上即可
*/
try {
String line=readLine(in);
System.out.println("请求行内容"+line);
/*
*下面代码可能抛出数组下标越界,这是由于空请求引起
*/
String arr[]=line.split(" ");
method=arr[0];
url=arr[1];
protocol=arr[2];
System.out.println("method "+method);
System.out.println("url "+url);
System.out.println("protocol "+protocol);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("请求行解析完毕");
}
public String getMethod() {
return method;
}
public String getProtocol() {
return protocol;
}
public String getUrl() {
return url;
}
/**
* 解析消息头
*/
private void parseHeaders(){
System.out.println("开始解析消息头");
String line=null;
while(true){
try {
line=readLine(in);
} catch (IOException e) {
e.printStackTrace();
}
if("".equals(line)){
break;
}
/*
*将消息头按照":"拆分为两项,消息头的名字当做key,消息头的值当做value保存到headers中
*/
String arr[]=line.split(": ");
headers.put(arr[0], arr[1]);
}
System.out.println("消息头解析完毕");
System.out.println("headers:"+headers);
Set<Entry<String,String>> entrySet=headers.entrySet();
for(Entry<String,String> e:entrySet){
String key=e.getKey();
String value=e.getValue();
System.out.println(key+":"+value);
}
}
/**
* 解析消息正文
*/
private void parseContext(){
System.out.println("开始解析消息正文");
System.out.println("消息正文解析完毕");
}
/**
* 通过输入流读取客户端发送的一行字符串
* 该方法会连续的读取若干字符,当连续读到CRLF的时候停止读取,
* 并将之前读到的所有字符以一个字符串的形式返回
*
* @param in
* @return
* @throws IOException
*/
private String readLine(InputStream in) throws IOException{
StringBuilder builder=new StringBuilder();
int cur=-1;//本次读的字符串
int pre=-1;//上次读的字符串
while((cur=in.read())!=-1){
if(cur==10&&pre==13){
break;
}
builder.append((char)cur);
pre=cur;
}
return builder.toString().trim();
}
/**
* 根据给定的消息头获得对应的值
* @param name
* @return
*/
public String getHeader(String name){
return headers.get(name);
}
}
处理请求
1.在项目目录下新建所有保存所有网络应用的目录:webapps
2.在webapps目录下创建一个子目录,作为我们第一个网络应用名为:myweb
3.在myweb目录中新建该应用的第一个页面:index.html

简单的写一个.html
<html>
<head>
<meta charset="utf-8">
<title>我的首页title>
head>
<body>
<center>
<h1>百度h1>
<input type="text" size=32> <input type="button" value="百度一下" onclick="alert('点你妹啊')">
center>
body>
html>
在ClientHandler的run方法中添加处理请求的逻辑,根据request获取请求的抽象路径,然后再webapps目录中对应的抽象路径找到客户请求的资源 (添加分支,判断资源是否存在)
package com.webserver.core;
import java.io.File;
import java.net.Socket;
import com.webserver.http.HttpRequest;
/**
* 用户处理客户端请求并予以响应的处理类
*/
public class ClientHandler implements Runnable{
private Socket socket;
public ClientHandler(Socket socket){
this.socket=socket;
}
public void run() {
System.out.println("一个客户端连接了");
try {
/**
* 处理客户端的请求分三步
* 1.解析请求
* 2.处理请求
* 3.发送响应
*/
HttpRequest request=new HttpRequest(socket);
//获取请求的抽象路径
String path=request.getUrl();
//去webapps目录下面找对应的资源
File file=new File("webapps/myweb"+path);
System.out.println("path:"+path);
//判断资源是否存在
if(file.exists()){
System.out.println("资源找到了");
}else{
System.out.println("资源未找到");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试三
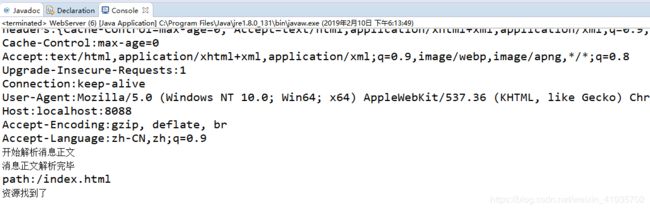
发送响应
在Http包中定义响应对象HttpResponse,用这个类的每一个实例表示一个实际发给客户端的响应内容
并在该类中定义方法:flush用于将当前响应的内容发送给客户端
flush方法中应当完成三部分的发送:转态行,响应头,响应正文
sendStatusLine();
sendHeaders();
sendContent();
package com.webserver.http;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.OutputStream;
import java.io.UnsupportedEncodingException;
import java.net.Socket;
/**
* 响应对象 该类的每个实例用于表示发送给客户端的一个HTTP响应内容
*
* @author admin
*
*/
public class HttpResponse {
/*
* 转态行相关信息定义
*/
/*
* 响应头相关信息定义
*/
/*
* 响应正文相关信息定义
*/
private File entity;// 响应的实体文件
/*
* 定义与连接相关的属性
*/
private Socket socket;
private OutputStream out;
public HttpResponse(Socket socket) {
try {
this.socket=socket;
out = socket.getOutputStream();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 将当前响应对象内容以HTTP响应格式发送给客户端
*/
public void flush() {
/*
* 发送状态行,响应头,响应正文
*/
sendStatusLine();
sendHeaders();
sendContent();
}
/**
* 发送状态行
*/
private void sendStatusLine() {
// 发送状态行
try {
String line = "HTTP/1.1 200 OK";
out.write(line.getBytes("ISO8859-1"));
out.write(13);
out.write(10);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("转态行发送完毕");
}
/**
* 发送响应头
*/
private void sendHeaders() {
try {
String line = "Content-Type: text/html";
out.write(line.getBytes("ISO8859-1"));
out.write(13);
out.write(10);
line = "Content-Length: " + entity.length();
out.write(line.getBytes("ISO8859-1"));
out.write(13);
out.write(10);
// 单独发送CRLF表示响应头发送完毕
out.write(13);
out.write(10);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("响应头发送完毕");
}
/**
* 发送响应正文
*/
private void sendContent() {
try (FileInputStream fis = new FileInputStream(entity);) {
int len = -1;
byte[] data = new byte[1024 * 10];
while ((len = fis.read(data)) != -1) {
out.write(data, 0, len);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("响应正文发送完毕");
}
public File getEntity() {
return entity;
}
public void setEntity(File entity) {
this.entity = entity;
}
}
HTTP响应格式也分为三部分:状态行,响应头,响应正文
状态行格式:
protorol status-code status-reason
协议版本 状态码 状态描述
修改ClientHandler创建HTTPResponse对象

测试四
运行WebServer,发现浏览器成功跳转

到这里,就差不多完成50%啦!!!有没有感觉很神奇。
状态码与对应的描述
创建对应的404界面:
当客户端请求的资源服务端无法找到的时候,应当响应客户端404转态码,以及一个404错误的提示页面
<html>
<head>
<meta charset="utf-8">
<title>404title>
head>
<body>
<h1 align="center">404,资源未找到h1>
body>
html>
修改ClientHandler,当用户请求的资源不存在的时候,直接刷404界面
package com.webserver.core;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.util.Date;
import java.util.Map;
import com.webserver.http.HttpContext;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 用户处理客户端请求并予以响应的处理类
*/
public class ClientHandler implements Runnable{
private Socket socket;
public ClientHandler(Socket socket){
this.socket=socket;
}
public void run() {
System.out.println("一个客户端连接了");
try {
/**
* 处理客户端的请求分三步
* 1.解析请求
* 2.处理请求
* 3.发送响应
*/
//解析请求
HttpRequest request=new HttpRequest(socket);
//创建响应对象
HttpResponse response=new HttpResponse(socket);
//获取请求的抽象路径
String path=request.getUrl();
//去webapps目录下面找对应的资源
File file=new File("webapps"+path);
//判断资源是否存在
if(file.exists()){
System.out.println("资源找到了");
/*
* 发送一个标准的Http响应给客户端
*/
//将要响应给客户端的资源设置到响应对象中
response.setEntity(file);
}else{
System.out.println("资源未找到");
//设置转态代码404
response.setStatusCode(404);
// response.setStatusReason("Not Found");
response.setEntity(new File("webapps/root/404.html"));
}
//响应该内容给客户端
response.flush();
} catch (Exception e) {
e.printStackTrace();
}finally {
//最后要与客户端断开连接
try {
socket.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
创建HttpContext类,来管辖这些与http协议的相关内容
1.修改要发送的转态代码,不再是写死的200,这个值要改变成可以设置的
2.不用的转态代码有不同的描述,我们定义一个map来保存转态代码和描述,然后设置转态代码后自动找到对应的描述
3.改进响应中的响应头操作,根据用户客户端请求的不同实际静态资源来响应其类型值
package com.webserver.http;
/**
* http协议规定的相关内容
* @author admin
*
*/
import java.util.HashMap;
import java.util.Map;
public class HttpContext {
/**
* 状态代码与对应的描述
* key:状态代码
* value:状态代码的描述
*/
private static Map<Integer, String> STATUS_MAPPING=new HashMap<Integer,String>();
/**
* 介质类型映射
* Key:文件名的后缀
* value:Content-Type对应的值
*/
private static Map<String, String> MIME_TYPE_MAPPING=new HashMap<String,String>();
public static Map<Integer, String> getSTATUS_MAPPING() {
return STATUS_MAPPING;
}
static{
//初始化
initStatusMapping();
initMineTypeMapping();
}
/**
* 初始化状态代码和对应的描述
*/
private static void initStatusMapping() {
STATUS_MAPPING.put(200, "ok");
STATUS_MAPPING.put(404, "Not Found");
STATUS_MAPPING.put(500, "Internal Server Error");
}
private static void initMineTypeMapping() {
MIME_TYPE_MAPPING.put("html", "text/html");
MIME_TYPE_MAPPING.put("css", "text/css");
MIME_TYPE_MAPPING.put("png", "image/png");
MIME_TYPE_MAPPING.put("gif", "image/gif");
MIME_TYPE_MAPPING.put("jpg", "image/jepg");
MIME_TYPE_MAPPING.put("js", "application/javascript");
}
/**
* 根据给定的状态代码获得对应的状态描述
*/
public static String getStatusReason(int code){
return STATUS_MAPPING.get(code);
}
/**
* 根据资源后缀获取相对应的Content-type值
* @param ext
* @return
*/
public static String getMimeType(String ext){
return MIME_TYPE_MAPPING.get(ext);
}
public static void main(String[] args) {
String fileName="jquery-1.8.3.min.js";
String ext=fileName.substring(fileName.lastIndexOf(".")+1);
String line=getMimeType(ext);
System.out.println(line);
}
}
通过map,我们可以修改sendHeaders方法,改成遍历headers来发送所有的响应头
修改以后的HttpResponse
package com.webserver.http;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.OutputStream;
import java.io.UnsupportedEncodingException;
import java.net.Socket;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.Map.Entry;
/**
* 响应对象 该类的每个实例用于表示发送给客户端的一个HTTP响应内容
*
* @author admin
*
*/
public class HttpResponse {
/*
* 状态行相关信息定义
*/
// 状态代码
private int StatusCode = 200;
// 状态描述
private String statusReason = "OK";
/*
* 响应头相关信息定义
*/
private Map<String, String> headers = new HashMap<String, String>();
/*
* 响应正文相关信息定义
*/
private File entity;// 响应的实体文件
/*
* 定义与连接相关的属性
*/
private Socket socket;
private OutputStream out;
public HttpResponse(Socket socket) {
try {
this.socket = socket;
out = socket.getOutputStream();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 将当前响应对象内容以HTTP响应格式发送给客户端
*/
public void flush() {
/*
* 发送状态行,响应头,响应正文
*/
sendStatusLine();
sendHeaders();
sendContent();
}
/**
* 发送状态行
*/
private void sendStatusLine() {
// 发送状态行
try {
String line = "HTTP/1.1" + " " + StatusCode + " " + statusReason;
out.write(line.getBytes("ISO8859-1"));
out.write(13);
out.write(10);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("转态行发送完毕");
}
/**
* 发送响应头
*/
private void sendHeaders() {
try {
//遍历headers将所有的响应头发送给客户端
Set<Entry<String, String>> header=headers.entrySet();
for(Entry<String, String> e:header){
String name=e.getKey();
String value=e.getValue();
String line=name+": "+value;
out.write(line.getBytes("ISO8859-1"));
out.write(13);
out.write(10);
}
// 单独发送CRLF表示响应头发送完毕
out.write(13);
out.write(10);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("响应头发送完毕");
}
/**
* 发送响应正文
*/
private void sendContent() {
try (FileInputStream fis = new FileInputStream(entity);) {
int len = -1;
byte[] data = new byte[1024 * 10];
while ((len = fis.read(data)) != -1) {
out.write(data, 0, len);
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("响应正文发送完毕");
}
public File getEntity() {
return entity;
}
/**
* 设置响应正文的实体文件
* 设置该文件,则意味着这个响应是包含正文的,而一个响应只要包含正文,一定会包含两个响应头
* Content-Type和Content-Length,用于告知客户端正文的数据类型以及字节量
*
* @param entity
*/
public void setEntity(File entity) {
this.entity = entity;
//Content-Length
headers.put("Content-Length", entity.length()+"");
//Content-Type
//1获取该资源文件的后缀名
String fileName=entity.getName();
int index=fileName.lastIndexOf(".")+1;
String ext=fileName.substring(index);
//2根据后缀获得对应的Content-Type的值
String line=HttpContext.getMimeType(ext);
headers.put("Content-Type", line);
}
/**
* 设置指定的状态代码,同时会制动设置对应的状态描述
*
* @param statusCode
*/
public void setStatusCode(int statusCode) {
StatusCode = statusCode;
this.statusReason = HttpContext.getStatusReason(statusCode);
}
public void setStatusReason(String statusReason) {
this.statusReason = statusReason;
}
public int getStatusCode() {
return StatusCode;
}
public String getStatusReason() {
return statusReason;
}
/**
* 添加指定响应头
*
* @param name
* @param value
*/
public void putHeader(String name, String value) {
this.headers.put(name, value);
}
/**
* 获取指定的响应头的值
*
* @param name
* @return
*/
public String getHeader(String name) {
return this.headers.get(name);
}
}
最后将我们的WebServer进行修改,套上一个while,让服务器一直处于启动的转态,可以不断的接收浏览器发送来的请求
同时每次服务器请求完了以后我们就可以断开socket
package com.webserver.core;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
public class WebServer {
private ServerSocket server;
public WebServer() {
// 初始化server
try {
server = new ServerSocket(8088);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
try {
while (true) {
// 启动一个线程处理该客户端交互
Socket socket = server.accept();
// 将socket传递给ClientHander
ClientHandler handler = new ClientHandler(socket);
Thread t = new Thread(handler);
t.start();
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
WebServer server = new WebServer();
System.out.println("服务端开始启动");
server.start();
}
}
测试五
导入别人写好的界面,然后直接启动WebServer服务器,然后用自己的浏览器访问
在我的资源里面有

(如果没有合适的界面来测试可以联系我的QQ939785177)
测试结果
界面是可以成功的跑起来,各个界面的跳转也是没问题的

DOM4J读取xml文件
现在我们的服务器虽然可以成功的解析界面,但是Content-Type 写死的不好,各种值都是手动输入

使用TOMCAt提供的配置文件,使我们的WebServer支持所有的Content-Type
1.拷贝web.xml文件到我们项目的conf中
2.重写HTTPContext中的方法
使用DOM4J先读取xml文件,先把为的子标签读取出来,并将其子标签中间的文本作为key
子标签中间的文本作为value保存到map中完成初始化
package com.webserver.http;
/**
* http协议规定的相关内容
* @author admin
*
*/
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class HttpContext {
/**
* 状态代码与对应的描述
* key:状态代码
* value:状态代码的描述
*/
private static Map<Integer, String> STATUS_MAPPING=new HashMap<Integer,String>();
/**
* 介质类型映射
* Key:文件名的后缀
* value:Content-Type对应的值
*/
private static Map<String, String> MIME_TYPE_MAPPING=new HashMap<String,String>();
public static Map<Integer, String> getSTATUS_MAPPING() {
return STATUS_MAPPING;
}
static{
//初始化
initStatusMapping();
initMineTypeMapping();
}
/**
* 初始化状态代码和对应的描述
*/
private static void initStatusMapping() {
STATUS_MAPPING.put(200, "ok");
STATUS_MAPPING.put(404, "Not Found");
STATUS_MAPPING.put(500, "Internal Server Error");
}
private static void initMineTypeMapping() {
// MIME_TYPE_MAPPING.put("html", "text/html");
// MIME_TYPE_MAPPING.put("css", "text/css");
// MIME_TYPE_MAPPING.put("png", "image/png");
// MIME_TYPE_MAPPING.put("gif", "image/gif");
// MIME_TYPE_MAPPING.put("jpg", "image/jepg");
// MIME_TYPE_MAPPING.put("js", "application/javascript");
try{
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("conf/web.xml"));
//获取跟标签"web-app" "mime-mapping"
Element root=doc.getRootElement();
String ename=root.getName();
List<Element> list=root.elements("mime-mapping");
for(Element e:list){
String key=e.elementTextTrim("extension");
String value=e.elementTextTrim("mime-type");
MIME_TYPE_MAPPING.put(key, value);
}
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 根据给定的状态代码获得对应的状态描述
*/
public static String getStatusReason(int code){
return STATUS_MAPPING.get(code);
}
/**
* 根据资源后缀获取相对应的Content-type值
* @param ext
* @return
*/
public static String getMimeType(String ext){
return MIME_TYPE_MAPPING.get(ext);
}
public static void main(String[] args) {
String fileName="jquery-1.8.3.min.js";
String ext=fileName.substring(fileName.lastIndexOf(".")+1);
String line=getMimeType(ext);
System.out.println(line);
}
}
测试六
运行HttpContext通过main测试,能够成功的解析文件的后缀即可

实现服务器功能之注册
在上面我们已经完了服务器的初级搭建,基本的功能也完成的差不多了,可以解析各种界面,但是我们还没在服务器上面添加我们的业务功能。
第一步:准备一张简单的注册界面,在webapps/myweb目录下新建一个注册页面:reg.html
<html>
<head>
<meta charset="UTF-8">
<title>用户注册title>
head>
<body>
<center>
<h1>用户注册h1>
<form action="reg" method="get">
<table border="1">
<tr>
<td>用户名td>
<td><input name="username" type="text">td>
tr>
<tr>
<td>密码td>
<td><input name="password" type="password">td>
tr>
<tr>
<td>昵称td>
<td><input name="nickname" type="text">td>
tr>
<tr>
<td>年龄td>
<td><input name="age" type="text">td>
tr>
<tr>
<td align="center" colspan="2">
<input type="submit" value="注册">
td>
tr>
table>
form>
center>
body>
html>
效果如图

当浏览器form表单以GET形式提交用户传递的参数时,会将所有参数包含在URL中。 那么URL的格式就变为了如:
http://localhost:8088/myweb/reg?username=xxx&password=xxx…
URL中的"?“是用来分割请求路径部分和参数部分,而每个参数的各式为:name=value,参数之间以”&"分割 因此,我们在解析请求的请求行时,得到抽象路径部分后要进一步对其处理,将参数部分解析出来(如果含有)
在HttpRequest中再添加三个属性
String requestURI: url中"?“左侧的请求部分
String queryString: url中”?"右侧的参数部分
Map parameters: 保存具体的每一个参数
再添加一个方法,用来进一步解析url:parseURL
在解析请求行的操作parseRequestLine方法中,当解析出url部分后,调用parseURL,对其进一步解析。
package com.webserver.http;
import java.io.IOException;
import java.io.InputStream;
import java.net.Socket;
import java.util.HashMap;
import java.util.Map;
/**
* 请求对象 该类的每一个实例用于表示客户端发送过来的一个实际的HTTP 请求内容。 每个请求由三部分组成: 1:请求行 2:消息头
* 3:消息正文(可以不包含)
*
* @author ta
*
*/
public class HttpRequest {
/*
* 请求行相关信息定义
*/
// 请求的方式
private String method;
// 请求的抽象路径
private String url;
// 请求使用的协议版本
private String protocol;
// url中的请求路径部分
private String requestURI;
// url中的参数部分
private String queryString;
// 每一个参数
private Map<String, String> parameters = new HashMap<>();
/*
* 消息头相关信息定义
*/
private Map<String, String> headers = new HashMap<String, String>();
/*
* 消息正文相关信息定义
*/
/*
* 与连接相关的属性
*/
private Socket socket;
private InputStream in;
public HttpRequest(Socket socket) {
try {
this.socket = socket;
this.in = socket.getInputStream();
/*
* 实例化一个HttpRequest要解析客户端发送 过来的请求内容,并分别解析其中的每部分 1:解析请求行 2:解析消息头 3:解析消息正文
*/
// 1
parseRequestLine();
// 2
parseHeaders();
// 3
parseContent();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 解析请求行
*/
private void parseRequestLine() {
System.out.println("开始解析请求行...");
/*
* 解析请求行: 1:读取一行字符串,即:请求行的内容 2:将字符串按照"空格"拆分为三部分 3:将拆分的三部分内容分别设置到
* method,url,protocol属性上即可
*/
try {
String line = readLine();
System.out.println("请求行内容:" + line);
/*
* 下面的代码可能抛出数组下标越界异常 这是由于“空请求”引起的,后期遇到后再 解决
*/
String[] data = line.split(" ");
this.method = data[0];
this.url = data[1];
this.protocol = data[2];
// 进一步解析url
parseURL();
System.out.println("method:" + method);
System.out.println("url:" + url);
System.out.println("protocol:" + protocol);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("请求行解析完毕!");
}
/**
* 进一步解析url
*/
private void parseURL() {
System.out.println("进一步解析URL...");
/*
* 实现思路 首先判断当前url是否需要进一步解析 而判定的标准是看url中是否含有"?",如果含有 则说明需要解析,若没有则不需要进一步解析
*
* 如果不需要进一步解析,那么直接将url的值赋值 给requestURI即可。
*
* 若需要解析,则应进行如下操作 先将url按照"?"拆分为两部分 第一部分设置到requestURI上,第二部分设置到 queryString属性上
*
* 然后进一步拆分参数: 将queryString按照"&"拆分为若干个参数。 每个参数再按照"="拆分为参数名与参数值,再将
* 各参数的名字作为key,参数的值作为value保存 到parameters这个Map类型的属性上。
*
* url可能存在的情况如下: /myweb/reg.html /myweb/reg?username=xxx&password=xxx&....
*
*/
// 是否含有"?"
if (url.indexOf("?") != -1) {
String[] data = url.split("\\?");
requestURI = data[0];
if (data.length > 1) {
queryString = data[1];
// 拆分每一个参数
data = queryString.split("&");
// paraLine: username=zhangsan
for (String paraLine : data) {
String[] paras = paraLine.split("=");
if (paras.length > 1) {
parameters.put(paras[0], paras[1]);
} else {
parameters.put(paras[0], null);
}
}
}
} else {
// 不含有"?"
requestURI = url;
}
System.out.println("requestURI:" + requestURI);
System.out.println("queryString:" + queryString);
System.out.println("parameters:" + parameters);
System.out.println("进一步解析URL完毕");
}
/**
* 解析消息头
*/
private void parseHeaders() {
System.out.println("开始解析消息头...");
try {
String line = null;
while (true) {
line = readLine();
if ("".equals(line)) {
// 单独读取了CRLF
break;
}
/*
* 将消息头按照": "拆分为两项 将详细头名字作为key,消息头的值作为 value保存到headers中
*/
String[] data = line.split(": ");
headers.put(data[0], data[1]);
}
System.out.println("headers:" + headers);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("消息头解析完毕!");
}
/**
* 解析消息正文
*/
private void parseContent() {
System.out.println("开始解析消息正文...");
System.out.println("消息正文解析完毕!");
}
/**
* 通过输入流读取客户端发送的一行字符串. 该方法会连续读取若干字符,当连续读取到CR,LF 时停止读取,并将回车符与换行符之前的所有字符
* 以一个字符串的形式返回。
*
* @return
* @throws IOException
*/
private String readLine() throws IOException {
StringBuilder builder = new StringBuilder();
int cur = -1;// 本次读取的字符
int pre = -1;// 上次读取的字符
while ((cur = in.read()) != -1) {
// 若上次读取回车符,本次读取换行符就停止读取
if (pre == 13 && cur == 10) {
break;
}
builder.append((char) cur);
pre = cur;
}
// 返回时要去除空白字符(最后会有一个回车符)
return builder.toString().trim();
}
public String getMethod() {
return method;
}
public String getUrl() {
return url;
}
public String getProtocol() {
return protocol;
}
/**
* 根据给定的消息头名字获取对应的值
*
* @param name
* @return
*/
public String getHeader(String name) {
return headers.get(name);
}
public String getRequestURI() {
return requestURI;
}
public String getQueryString() {
return queryString;
}
/**
* 根据给定的参数名获取对应的参数值
*
* @param name
* @return
*/
public String getParameter(String name) {
return parameters.get(name);
}
}
这样我们就可以把用户提交过来的具体参数,全部解析出来,然后保存到map里面。
在WebServer里面创建具体的业务包com.webserver.servlet,在包里面创建我们的RegServlet
package com.webserver.servlet;
import java.io.File;
import java.io.RandomAccessFile;
import java.util.Arrays;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 用于处理用户注册业务
*
* @author ta
*
*/
public class RegServlet {
public void service(HttpRequest request, HttpResponse response) {
System.out.println("RegServlet:开始用户注册...");
/*
* 1:获取用户在页面上输入的注册信息 2:将用户注册信息写入到文件user.dat 3:设置response响应注册成功页面
*/
// 1
String username = request.getParameter("username");
String password = request.getParameter("password");
String nickname = request.getParameter("nickname");
int age = Integer.parseInt(request.getParameter("age"));
System.out.println("username:" + username);
System.out.println("password:" + password);
System.out.println("nickname:" + nickname);
System.out.println("age:" + age);
// 2
try (RandomAccessFile raf = new RandomAccessFile("user.dat", "rw");) {
/*
* 首先要判断该用户是否已经存在 这里循环读取每条记录的用户名,若用户名已经 存在,则直接跳转用户名已存在的提示页面。 若文件中没有该用户,再执行注册操作
* 1:循环读取user.dat文件每条记录 2:首先将指针移动到每条记录开始位置(用户名位置) 3:连续读取32字节,并转换为字符串,读取用户名
* 然后跟用户输入的本次注册信息的用户名比对,若 不一致则执行下次循环 若一致说明找到该用户,那么设置response响应
* 页面为reg_fail.html,并使方法返回,不再执行 后续操作 4:若循环正常结束,说明该用户不存在,那么则 执行后续的注册操作。
*/
for (int i = 0; i < raf.length() / 100; i++) {
raf.seek(i * 100);
byte[] data = new byte[32];
raf.read(data);
String name = new String(data, "UTF-8").trim();
if (name.equals(username)) {
// 重复用户
response.setEntity(new File("webapps/myweb/reg_fail.html"));
return;
}
}
// 将指针移动到文件末尾
raf.seek(raf.length());
// 写用户名
byte[] data = username.getBytes("UTF-8");
// 将字节数组扩容到32个长度
data = Arrays.copyOf(data, 32);
raf.write(data);
// 写密码
data = password.getBytes("UTF-8");
// 将字节数组扩容到32个长度
data = Arrays.copyOf(data, 32);
raf.write(data);
// 写昵称
data = nickname.getBytes("UTF-8");
// 将字节数组扩容到32个长度
data = Arrays.copyOf(data, 32);
raf.write(data);
// 写年龄
raf.writeInt(age);
// 3 响应客户端注册成功
response.setEntity(new File("webapps/myweb/reg_success.html"));
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("RegServlet:用户注册完毕!");
}
}
修改ClientHandler在处理请求的环节中添加一个新的分支判断,根据请求路径判断是否为请求一个业务,若是,则调用该业务处理类完成工作。否则再执行原有的分支判断是否请求webapps下的一个静态资源
//1.1解析请求
HttpRequest request = new HttpRequest(socket);
//1.2创建响应对象
HttpResponse response = new HttpResponse(socket);
//2
//2.1获取请求的抽象路径
String path = request.getRequestURI();
//是否为请求一个业务
if("/myweb/reg".equals(path)) {
//用户注册业务
RegServlet servlet = new RegServlet();
servlet.service(request, response);
}else {
//2.2去webapps目录下找到对应资源
File file = new File("webapps"+path);
//2.3判断该资源是否真实存在
if(file.exists()) {
System.out.println("资源已找到!");
//将要响应给客户端的资源设置到响应对象中
response.setEntity(file);
}else {
System.out.println("资源未找到!");
//设置状态代码为404
response.setStatusCode(404);
//响应404页面
response.setEntity(new File("webapps/root/404.html"));
}
}
实现服务器功能之登录
在webapps/myweb目录下新建3个页面
login.html -------------------------- 登录页面
<html>
<head>
<meta charset="UTF-8">
<title>用户登录title>
head>
<body>
<center>
<h1>用户登录h1>
<form action="login" method="get">
<table border="1">
<tr>
<td>用户名td>
<td><input name="username" type="text">td>
tr>
<tr>
<td>密码td>
<td><input name="password" type="password">td>
tr>
<tr>
<td align="center" colspan="2">
<input type="submit" value="登录">
td>
tr>
table>
form>
center>
body>
html>
login_success.html ------------- 登录成功提示页面
<html>
<head>
<meta charset="UTF-8">
<title>成功title>
head>
<body>
<h1 align="center">恭喜您,登录成功!h1>
body>
html>
login_fail.html --------------------- 登录失败提示页面
<html>
<head>
<meta charset="UTF-8">
<title>失败title>
head>
<body>
<center>
<h1>用户名或密码不正确!h1>
<a href="login.html">重新登录a>
center>
body>
html>
当我们拿到用户输入的内容的时候,服务端根据user.dat文件,检查该用户的登录信息是否匹配。然后根据匹配结果跳转登录成功或登录失败页面。
在包com.webserver.servlet,下面创建处理登入请求的类LoginServlet
package com.webserver.servlet;
import java.io.File;
import java.io.RandomAccessFile;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 处理登录业务
* @author ta
*
*/
public class LoginServlet {
public void service(HttpRequest request,HttpResponse response) {
//1获取用户信息
String username = request.getParameter("username");
String password = request.getParameter("password");
System.out.println("username:"+username);
System.out.println("password:"+password);
//2
try (
RandomAccessFile raf
= new RandomAccessFile("user.dat","r");
){
//表示登录是否成功
boolean check = false;
for(int i=0;i<raf.length()/100;i++) {
//移动指针到每条记录的开始位置
raf.seek(i*100);
//读取用户名
byte[] data = new byte[32];
raf.read(data);
String name = new String(data,"UTF-8").trim();
//判断是否为此用户
if(name.equals(username)) {
//匹配密码
raf.read(data);
String pwd = new String(data,"UTF-8").trim();
if(pwd.equals(password)) {
//登录成功
response.setEntity(new File("webapps/myweb/login_success.html"));
check = true;
}
break;
}
}
//判断登录失败
if(!check) {
//跳转登录失败页面
response.setEntity(new File("webapps/myweb/login_fail.html"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
同时修改ClientHandler,添加对应的请求处理,根据不同的请求new不同的对象
//1.1解析请求
HttpRequest request = new HttpRequest(socket);
//1.2创建响应对象
HttpResponse response = new HttpResponse(socket);
//2
//2.1获取请求的抽象路径
String path = request.getRequestURI();
//是否为请求一个业务
if("/myweb/reg".equals(path)) {
//用户注册业务
RegServlet servlet = new RegServlet();
servlet.service(request, response);
}else if("/myweb/login".equals(path)){
LoginServlet servlet = new LoginServlet();
servlet.service(request, response);
}else {
//2.2去webapps目录下找到对应资源
File file = new File("webapps"+path);
//2.3判断该资源是否真实存在
if(file.exists()) {
System.out.println("资源已找到!");
//将要响应给客户端的资源设置到响应对象中
response.setEntity(file);
}else {
System.out.println("资源未找到!");
//设置状态代码为404
response.setStatusCode(404);
//响应404页面
response.setEntity(new File("webapps/root/404.html"));
}
}
添加反射
利用反射机制加载Servlet来解决添加不同业务时每次对ClientHandler的修改。
我们设计一个Map,key保存请求路径,value保存对应的Servlet的名字。然后ClientHandler在得到一个请求路径后先作为key在该Map中查看是否对应Servlet若是则获取该Servlet的名字,利用反射机制加载这个类并实例化,然后调用其service方法进行处理。
而这个Map的数据可以来源于一个xml文件。从而做到
请求与对应Servlet可以进行配置。
<servlets>
<servlet url="/myweb/reg" className="com.webserver.servlets.RegServlet"/>
<servlet url="/myweb/login" className="com.webserver.servlets.LoginServlet"/>
<servlet url="/myweb/update" className="com.webserver.servlets.UpdateServlet"/>
servlets>
修改ClientHandler,利用反射创建实例
// 1准备工作
// 1.1解析请求,创建请求对象
HttpRequest request = new HttpRequest(socket);
// 1.2创建响应对象
HttpResponse response = new HttpResponse(socket);
// 2处理请求
// 2.1:获取请求的资源路径
String url = request.getRequestURI();
// 判断该请求是否为请求业务
String servletName = ServerContext.getServletName(url);
if (servletName != null) {
System.out.println("ClientHandler:正在加载" + servletName);
Class cls = Class.forName(servletName);
HttpServlet servlet = (HttpServlet) cls.newInstance();
servlet.service(request, response);
} else {
// 2.2:根据资源路径去webapps目录中寻找该资源
File file = new File("webapps" + url);
if (file.exists()) {
System.out.println("找到该资源!");
// 向响应对象中设置要响应的资源内容
response.setEntity(file);
} else {
// 设置状态代码404
response.setStatusCode(404);
// 设置404页面
response.setEntity(new File("webapps/root/404.html"));
System.out.println("资源不存在!");
}
}
// 3响应客户端
response.flush();
结合服务器实战ATM项目遇到的问题
用户登入之后想立即看到自己的信息,如何实现
在还没有学session,cookie的时候,这里该如何解决。之前我们的项目都是直接写好静态界面,当验证成功的时候,直接将静态页面刷给用户,上面直接显示登入成功。但是现在,不同的用户登录,他们的信息是不一样的,我们要如何实现动态加载页面。当时是想了一个标记的方法,现在我们的静态界面中提前用一些特殊的符号吧位置占住。比如姓名使用 $name 表示,年龄使用 $age表示,地址使用 $address表示,以此类推。这样我们可以提前准备好静态界面。当用户登入成功的时候,立即遍历该用户的信息,将该用户的信息存在map里面,对应的键值对就是 $name 对应 用户姓名 , $age 对应用户的年龄.这样用户的信息就被完整的保存到map里面。然后再服务器刷这张静态页面的时候,我们可以使用IO,按行的刷,当读取到事先存在静态页面中的关键字 $name, $age…就立马将 $name当做key获得map里面保存的值,然后map中拿到的value替换掉。
boolean b = jdbcdao.login(username, password);
System.out.println("b" + b);
if (b) {
System.out.println("登入成功");
System.out.println("username" + username + "password" + password);
try {
map = jdbcdao.getmap(username, password);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
forward("/myweb/login_success.html", request, response, map);
return map;
} else {
System.out.println("登入失败");
forward("/myweb/login_fail.html", request, response);
return null;
}
登入成功之后,立即调用dao里面事先准备好的getmap方法获得对象所有信息,然后刷界面的时候,也将map传递过去。
// 用map传递用户的信息,通过在流里面的关键字的替换来将用户的信息显示在我们的界面上
try (FileInputStream fis = new FileInputStream(entity)) {
BufferedReader br = new BufferedReader(new InputStreamReader(fis, "UTF-8"));
String str = null;
while ((str = br.readLine()) != null) {
str = str.replace("$name", context.get("name"));
str = str.replace("$password", context.get("password"));
str = str.replace("$idcard", context.get("idcard"));
str = str.replace("$address", context.get("address"));
str = str.replace("$email", context.get("email"));
str = str.replace("$money", context.get("money"));
System.out.println(str);
byte[] data = str.getBytes("UTF-8");
out.write(data);
}
用户登入之后,可能会进行一系列的操作,比如修改个人的一些信息。当用户修改完后,点击返回主页面,如何将用户的信息立即同步到登录成功的主界面
当然这个也是在没有使用session和cookie的时候完成的。每次用户点击按钮的时候都会向服务器发送请求。所以我们准备了一个加密算法,当调用算法一次的时候,用户的信息会进行加密,调用两次的时候则会进行解密,很神奇。
加密代码如下,同时也准备了一个main的测试方法
package com.webserver.dao;
public class md5j {
public static String convertMD5(String inStr) {
char[] a = inStr.toCharArray();
for (int i = 0; i < a.length; i++) {
a[i] = (char) (a[i] ^ 't');
}
String s = new String(a);
return s;
}
public static void main(String[] args) {
String str = "aaa";
System.out.println("第一次加密"+convertMD5(str));
System.out.println("第二次加密"+convertMD5(convertMD5(str)));
}
}
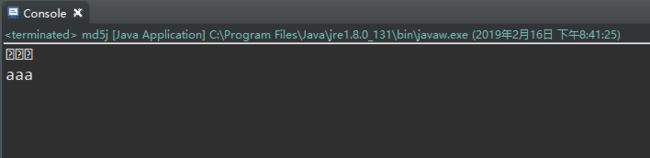
可以看得出,加密之前str给的值是aaa,加密之后就是一串看不懂的东西了,但是我们如果再次进行加密,则会还原。
这样的话,每次用户进行一系列的操作之后,我们只需要再次调用登入的方法即可。但是我们马上会遇到一个新的问题,我们不可能每次都让用户输入账号秘密,所以我们会将加密后的数据返回给用户,但是由于是乱码,所以,安全性还是有的。当用户进行操作的时候我们通过转态来判断用户是第一次登入还是已经登入过了呢
登入代码如下,通过on来记录
/**
* 登入操作
* @param request
* @param response
*/
public Map<String, String> loginservice(HttpRequest request, HttpResponse response) {
// 1 获取用户登录信息
String username = request.getParameter("username");
String password = request.getParameter("password");
try {
String on=request.getParameter("on");
System.out.println("on的转态"+on);
if(on.equals("1")) {
password=md5j.convertMD5(password);
System.out.println("再次访问密码解密"+password);
}
}catch(Exception e) {
System.out.println("第一次登入");
}
System.out.println(password);
boolean b = jdbcdao.login(username, password);
System.out.println("b" + b);
if (b) {
System.out.println("登入成功");
System.out.println("username" + username + "password" + password);
try {
map = jdbcdao.getmap(username, password);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
forward("/myweb/login_success.html", request, response, map);
return map;
} else {
System.out.println("登入失败");
forward("/myweb/login_fail.html", request, response);
return null;
}
}
如果用户不是第一次登入,我们就会将用户的原来加密的信息再次加密,也就是解密,然后再次通过数据库,拿到用户的所有信息。
心得总结
如果说java基础到飞机大战,感觉是一步蜕变。将学的变成看的见的用的,那么服务器绝对也是进一步的蜕变。虽然整个过程有点痛苦,可能刚开始的时候也不知道为什么要这样。但是后面写了几遍之后,结合了一些实战。感觉又打开了一扇新世界的大门。以及后面花费了很多心思去想着升级ATM的项目,但是掌握的知识很少,直到后面学了jsp,session之后才发现以前那些困惑想各种方法解决的,其实都很简单,调用一些方法就能实现。现在反过头来看以前的这一些,感觉很傻,但是却是一段不错的回忆,利用仅知道的java基础和javaEE的api居然能实现这么多东西。