python中的各种错误集结(不断增加中······)
1.urllib.error.ContentTooShortError:urlretrieve下载文件不完整造成的
可以接受这种异常重新写一个方法处理这个问题,可以在去调用这个方法重新去下载,也可以重新用requests下载。
因为重新调用这个方法,有时下载会超时。参考博客https://blog.csdn.net/jclian91/article/details/77513289
不过没有采用博主的方法,我只是还是用urllib.request.urlretrieve方法,超过次数以后自动停止并打印错误信息。
2. ValueError: source code string cannot contain null bytes

我们纳闷,找不到问题在哪,而且没有详细的错误提示。经过Google以后,我发现我的这个库有一个模块只有一个换行符\n。这个文件就是wikicorpus/__init__.py。所以每次进口的时候就会运行这个空文件。导致错误ValueError: source code string cannot contain null bytes。只要删除空行就行了。
3.Python-PackagesNotFoundError: The following packages are not available from current channels

换用以下命令就行了:
conda install -c conda-forge typeguard4.tensorflow.python.framework.errors_impl.InternalError: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runtime version
![]()
CUDA driver version is insufficient for CUDA runtime version 翻译过来就是CUDA的驱动程序版本跟CUDA的运行时版本不匹配!
1.CUDA driver version(驱动版本):就是NVIDIA GPU的驱动程序版本;
查看命令:nvidia-smi
我们看到我的GPU的驱动程序版本是:384.81
2.CUDA runtime version(运行时版本):是在python中安装的cudatoolkit和cudnn程序包的版本
查看命令:pip list
python安装的cudatoolkit和cudnn程序包版本是:9.2
3.nvidia 驱动和cuda runtime 版本对应关系(TensorFlow安装时需要cuda+对应的显卡驱动。这里给出英伟达官方的cuda和驱动的对应:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html)
运行时版本 驱动版本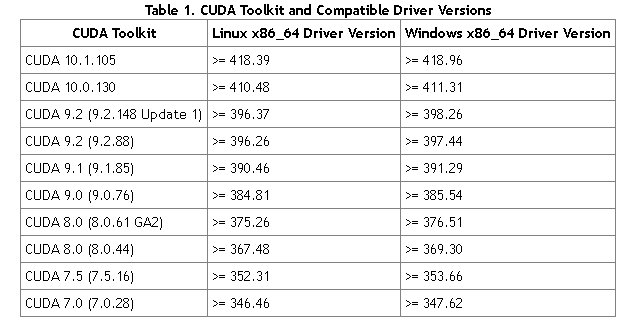
CUDA 6.5 340.xx
CUDA 6.0 331.xx
CUDA 5.5 319.xx
CUDA 5.0 304.xx
CUDA 4.2 295.41
CUDA 4.1 285.05.33
CUDA 4.0 270.41.19
CUDA 3.2 260.19.26
CUDA 3.1 256.40
CUDA 3.0 195.36.15
然后在这里可下载最新的显卡驱动(英伟达公版的驱动,程序员友好型):https://www.nvidia.cn/Download/index.aspx?lang=cn
4.解决方案
从驱动和运行时的版本对应关系来看,版本为384.81的驱动程序 对应的 运行时版本是9.0,也就是说我们在python中安装cudatoolkit和cudnn程序包版本9.2是过高了。
因为系统中依赖GPU驱动的程序比较多,一般出现这种情况,我们都是更改cudatoolkit和cudnn程序包的版本。
于是,先卸载python中安装cudatoolkit和cudnn程序包:pip uninstall cudnn ; pip uninstall cudatoolkit
然后安装对应版本的cudatoolkit和cudnn程序包:pip install cudatoolkit=9.0;pip install cudnn
5.为什么会出现这种情况呢:
一般出现这种情况是因为在python中安装tensorflow的gpu版本时,pip会检查tensorflow依赖的其他的包,如果依赖的包没有安装,则会先安装最新版本的依赖包。这时候tensorflow的gpu版本依赖cudatoolkit和cudnn程序包,pip就会安装最新版本的cudatoolkit和cudnn程序包,最终导致gpu驱动版本和cuda运行时版本不匹配。
5.tensorflow:OOM when allocating tensor with shape[225,256,256,36] and type float on /job:localhost/re
使用keras库进行模型训练时,出现以下错误:
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[10,256,400,528]
1
解决方法如下:
[10,256,400,528]的第一个参数表示batch_size的大小,第二个参数表示某层卷积核的个数,第三个参数表示图像的高,第四个参数表示图像的长
这里出现这种错误的原因时超出内存了,因此可以适当减小batch_size的大小即可解决
6.错误ValueError: Object arrays cannot be loaded when allow_pickle=False的解决
今天在试使用Google Colab中的IMDb数据集来实现二进制分类示例。我以前实现过这个模型。但是当我试图在几天后再次执行它时,它返回了一个ValueError: Object arrays cannot be loaded when allow_pickle=False错误。
Numpy 1.16.3几天前发布了。从发行版本中说明:“函数np.load()和np.lib.format.read_array()采用allow_pickle关键字,现在默认为False以响应CVE-2019-6446 < nvd.nist.gov/vuln/detail / CVE-2019-6446 >“。降级到1.16.2对我有帮助,因为错误发生在一些library内部。
解决办法如下:
直接将numpy回到旧版本1.16.1或1.16.2版本即可
conda install numpy=1.16.2
或
pip install numpy=1.16.2