姿态估计0-03:DenseFusion(6D姿态估计)-白话给你讲论文-翻译无死角(1)
以下链接是个人关于DenseFusion(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解https://blog.csdn.net/weixin_43013761/article/details/103053585
以后的论文我都不一句句为大家翻译了,根据自己的理解做一些总结,不多说什么,现在就开始DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion的翻译。
Abstract
之前的网络都是分别从RGB图像和深度图像提出信息,需要做后期处理。Dense Fusion把RBG图像和depth图通过特征融合,做了一个统一的处理。很大程度上提高了速度,并且还提出iterative pose refinement:其能对初步预测的姿态进行提炼,内部实现是使用了一种循环迭代的方式。代码的实验是在YCB-Video和LineMOD上进行的。
1. Introduction
6D姿态的应用是十分广泛的,如机器人抓取,自动驾驶等。理论上来说,这些应用,对6D姿态的预测需要很强的鲁棒性,无论在大范围遮挡,低光等环境下,都要提供准确并且实时的姿态估算。知道RGB-D传感器的出现,促使我们有能力去解决这些问题。使用RGB-D传感器,去做姿态估算,一般来说,效果都是要好于基于RGB图像进行估算的方法。但是现在基于RGB-D图像进行估算的方法,都很难做到保证高准确率并且实时。
传统的方法,通过手工对RGB-D进行特征提取,然后进行特征匹配。在实际应用中,效果是比较差的,容易受到环境,如目标被遮挡,光照变化等影响。随着CNN的到来,出现出现了基于深度学习的姿态估计(输入:RGB-D),如PoseCNN 和MCN 。但是这些方法中,PoseCNN后期要经过ICP(Iterative Closest Point-比较耗时并且复杂)处理,MCN采用多视角假设方案(不用去深究)。因为这些处理,在实际应用中是没有办法做到实时的。
后来出现了PointNet和PointFusion,他们利用RGB-D进行端到端的训练,在相对比较高的准确率下,达到了实时。但是经过的验证之后,他们在物体重度遮挡的情况下,鲁棒性是十分的差的。
DenseFusion能够端到端的进行训练(输入为RGB-D),对已知的物体进行6自由态的姿态估计。核心的地方至于RGB图像的特征和向量,与点云的特征向量进行了每个像素级别的融合。这种像素基本的融合,能够很好的对物体的外貌和集合信息进行推断。进一步我们提出了一种迭代优化的方法,其也是能够端到端的训练,所以其速度也是很快的。
在YCB-Video以及LineMOD数据集上进行了实验,超过PoseCNN(后期经过ICP处理的)3.5%的准确率,推理速度更是快乐200倍。最后还证明了,我们的方法对遮挡物体的鲁棒性特别好(受益于密度融合),并且进行了机器人抓取物体实验。
总结,网络分为两个阶段:
1.融合RGB-D图像的颜色和深度信息,然后通过算法学习,让其映射成另外空间的特征向量,用这个特征向量进行姿态预测。
2.使用循坏迭优化(后面有详细的讲解)的方法,代替了后期的ICP处理步骤。
2. Related Work
**Pose from RGB images(通过RCB图像进行姿态估算)**传统的方法,主要依赖已知模型的检测和关键点匹配。后面出现了对2D关键点进行预测的方法,但是纹理比较低,分辨率低的图像,其效果十分的差。至于其他的一些方法,都是把注意力集中在方向的预测上,如通过多视角,去预测一个视觉的姿态。我们的方法是结合的3维数据和图片信息,一起进行端到端的学习。
Pose from depth / point cloud(通过点云数据或深度信息进行姿态估算) 最近的研究,利用体素,配合3D卷积。虽然这种方法能够很好的提取到3D几何信息,但是太慢了,没帧图片的处理要20秒。再近一点的方法,直接对3D点云数据进行学习。比如PointNets和VoxelNet,其VoxelNet用了一个类似于PointNets的架构,在KITTI达到了目前最相近的效果。
与单点云就能提供足够信息的城市驾驶技术不同,对于YCBVideo 数据集,我们还需要对他的外观进行推理。我们通过2D-3D传感器融合的方式,解决上面问题。
Pose from RGB-D data(通过RGB-D进行姿态估算) 最近的一些方法,如 PoseCNN直接通过图像进行姿态预测,更进一步的,为CNN添加了一个通道用于深度信息的输入,这些方法为了重发的利用输入信息,不得不使用昂贵的后期处理方式。我们的方法,融合了3D数据和2D外观特性,充分的保留了几何信息,在YCB-Video 数据集上,不做后期处理,也取得了比较好的效果。
我们的方法依赖于PointFusion,其几何信息和外观信息被融合在一个复杂的特征向量之中,然后再使用迭代提炼的方式,对初始预测的姿态进行优化。
3. Model
我们的目标是对,凌乱复杂RGB-D图像的物体进行姿态估算。 和平常的方式一样,6D姿态使用一个平次转化的矩阵表示, p ∈ S E ( 3 ) p\in SE(3) p∈SE(3)。也就是说 p p p是由一个旋转 R ∈ S O ( 3 ) R \in SO(3) R∈SO(3)和一个偏移 t ∈ R 3 t \in \mathbb{R}^3 t∈R3, P = [ R ∣ t ] P=[R|t] P=[R∣t]。因为估算的是来着摄像头的图片,所以姿态是根据摄像的坐标来定义的。
在比较复杂的情况下(如遮挡,低光等),对已知物体进行姿态估算,只有结合颜色图片和深度图片。但是这两种图像是来自不同的空间,对于这种来源不同的数据,进行特征融合是当前技术面临的挑战。
对于这个挑战,我们通过如下方式解决了:
1.使用不同的架构分别处理颜色和深度信息,保留数据的原特征信息。
2.利用两种数据源本身固有的属性,进行像素级别的融合
3.使用迭代优化的方式,对初始估算的姿态进行提炼
3.1. Architecture Overview
下图Fig. 2,是整个网络框架结构,其主要分为两个阶段:
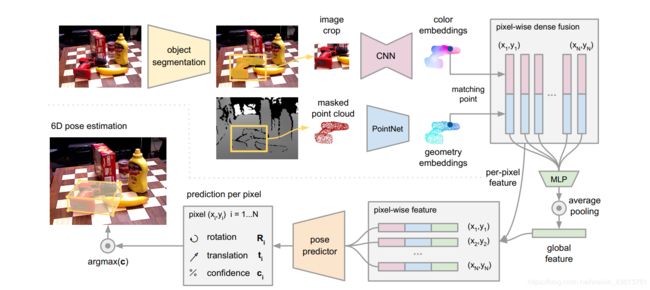
1.通过语义分割,分割出我们需要进行姿态估算的目标,只用语义分割的mask确定目标在深度图的位置,然后对把深度图的目标所在区域的深度信息,转化为点云信息。此时获得的image crop和masled point cloud都当做网络第二阶段的输入。
2.第二阶段就是根据输入的image crop和masled point cloud进行姿态估算,其分为四个部分。a.通过一个全卷积网络,把image crop的每个像素信息映射到color embeddings。b.使用PointNet处理经过mask获得目标点云的数据,映射成一个带有几何信息的geometry embeddings。c.把color embeddings和geometry embeddings进行像素级别的融合,然后基于无监督的置信度(后续有详细讲解-就是对每个像素进行姿态预测之后,该预测对应一个置信度),进行姿态估算。d.对初步估算的姿态结果进行提炼优化。
其中d步骤的图示Figure 3如下:

3.2. Semantic Segmentation
他们使用的语义切割的方式是:
Y. Xiang, T. Schmidt, V. Narayanan, and D. Fox,
“Posecnn:A convolutional neural network for 6d object pose estimation in cluttered scenes,”
ArXiv preprint arXiv:1711.00199,-2017,
有兴趣的朋友可以去了解一下
3.3. Dense Feature Extraction
技术的难点,在于正确的提取出color和depth图像的特征信息,虽然在RGB-D图像中,他们的形式比较相近,但是数据信息分别是来自不同空间的,所以把它分开处理,分别映射成color features和geometric features,这样更好的保留了,属于原本空间的信息。
Dense 3D point cloud feature embedding: 之前的方法,把深度图当做图像的一个通道,添加到RBG图像中(3通道的RGB图像,变成4通道),这种方法,把深度图当初2D信息来处理了,忽略了其中的3D结构信息,所以我们先根据: 已 知 的 摄 像 头 内 参 , 把 其 转 化 为 点 云 数 据 \color{red}{已知的摄像头内参,把其转化为点云数据} 已知的摄像头内参,把其转化为点云数据然后通过类似于PointNet的网络进行处理。
原本的PointNet网络建议使用symmetric function(max-pooling),对无序的点云数据进行处理(利用了3D点云的排列不变形)。原本的架构中,是学习对点云数据集的编码,把每个点邻近的信息作为一个整体进行编码。实验表面,该方法对分类,语义分割,以及姿态估算都有很好的作用。
我们使用一种和PointNet类似的网络结构,是把输入的 每 个 点 云 \color{red}{每个点云} 每个点云 P P P映射到一个另外一个空间成为 d g e o d_{geo} dgeo,我们变异的PointNet使用的是average-pooling代替原本的max-pooling作为 symmetric reduction function(我也比较懵逼,不过似乎并不影响下面的理解)。该部分也就是
Fig. 2如下部分:

总的来说,就是把每个像素,都抽象成维度是 d g e o d_{geo} dgeo的向量。其中包含的是这个点云数据被抽象出来的空间信息。
Dense color image feature embedding: 这color embedding network就是把 R B G 图 像 的 每 个 像 素 \color{red}{RBG图像的每个像素} RBG图像的每个像素通过CNN网络映射到另外一个空间,生成color embedding ,其中过程为Fig. 2中如下部分:

网络的输入为 H × W × 3 H × W × 3 H×W×3输出为 H × W × d r g b H × W × d_{rgb} H×W×drgb,输入图像的每一个像素都对应一个 d r g b d_{rgb} drgb。也就是说,每个像素都被抽象成了 d r g b d_{rgb} drgb维度的特征向量。可以理解为图片最后输出的通道数目。其包含的是每个像素的在对应位置的外观信息。
3.4. Pixel-wise Dense Fusion
通过上面的介绍,我们获得抽取出来的密集(因为是像素级别的提取,所以说他是密集的)color color embedding以及geometry embeddings,既然他们是基于像素级别的提取,那么我们现在也对他进行像素级别的融合,但是由于之前的步骤,由于降低语义分割的差错,或者重度遮挡的原因,其提取的特征,可能包含了其他的物体,或者背景的信息。盲目的进行融合会降低姿态估算的准确度。下面,我们设计一种pixel-wise密度融合的方式(其原理,主要是利用了2D图像到3D点云的一一对应映射的原理),其很好的融合geometry embeddings与color embedding,尤其是在重度遮挡和语义分割有差错的情况下。
Pixel-wise dense fusion: 该设计的核心思想,就是对每个融合的像素/点云,对进行姿态的估算,然后从这些所有像素/点云的预测结果中,找到最好的一个结果。作为最终姿态的预测结果。这样,就能极大程度上解决物体被遮挡,以及分割错误的干扰。详细的说有下面几个步骤。
1.利用已知的摄像头参数,把3D点云和对应的在img图像中的位置,建立好关系。
2.把获得的特征都对接起来,然后提供给另外的网络处理,然后生成一个固定大小的全局特征。虽然我们是对每个像素/点云级别预测,但是为一每个都提供了全局信息,丰富了每个像素/点云特征的全局语义信息。
3.预测出来的姿态是一个集合(因为对每个像素/点云都有预测),接下来讲解如何从这么多的预测结果中,找到最好的哪个预测姿态。
总来来说,就是这个意思,假设我们从一个目标物体中挑取500个点云(一般来说,一个目标的物体有很多点云),根据映射关系,利用点云和RGB图像对应的关系,挑选出对应位置,从RGB抽取出来的特征向量进行融合。融合之后之后呢,对这500个点云或者说像素,都进行姿态估算。接下来的任务就是从这500个估算的姿态中,找到最好的哪个,其使用的是一种自监督的方式,如下。
Per-pixel self-supervised confidence: 我们希望网路根据环境,自己去决定哪个预测的结果最好。所以在对姿态进行预测的时候,对于每个像素/点云的姿态预测,还添加了一个置信度评分 c i c_i ci的预测。把他当做我们第二个学习的目标,接下来,可以看到他的详细介绍。
3.5. 6D Object Pose Estimation
这 里 是 重 点 , 别 读 一 下 就 过 去 了 , 好 好 琢 磨 \color{red}{这里是重点,别读一下就过去了,好好琢磨} 这里是重点,别读一下就过去了,好好琢磨
定义的loss非常简单,就是目标模型(一般在视频第一帧中的目标物体,定义为目标模型,也就是一段视频中,后续建模出来的点云数据,都是以第一帧的目标物体为标准)。目标模型根据拍摄其他视角图片时保存的摄像头参数(一般含有旋转矩阵和偏转矩阵-也就是标准的姿态参数),求得当前帧(或者说当前视角)的点云数据。总的来说也就是把目标模型的点云,依据按照最标准的参数(旋转和偏移)转换成其他视角的点云数据。这样每个点云都进行了标准的变换,这里标准的旋转和偏移,我们可以称为ground truth pose。loss定义如下:
L i p = 1 M ∑ j ∣ ∣ ( R x j + t ) − ( R ^ i x j + t ^ i ) ∣ ∣ L^p_i = \frac{1}{M} \sum_j||(Rx_j+t)-(\hat R_{i}x_j+\hat t_i)|| Lip=M1j∑∣∣(Rxj+t)−(R^ixj+t^i)∣∣
1. ~ M表示的是从目标从目标模型中随机挑选出来的点云, x j x_j xj 表示是M点云中,第 i i i个点云。
2. ~ p = [ R ∣ t ] p=[R|t] p=[R∣t]表示的是ground truth pose, p ^ = [ R ^ ∣ t ^ ] \hat p=[\hat R|\hat t] p^=[R^∣t^]表示经过网络预测出来的predicted pose
上面这个公式大家不要以为很简单,上面的 L i p L^p_i Lip表示的是对第 i i i个点云计算loss,可以看到每一个 i i i对应着 j j j个姿态。因为预测的时候,是每个像素,都进行了姿态预测,我们又要挑选出最好的一个。那么我们当然需要,把目标模型挑选出来的每个点云,和所有预测的姿态参数分别进行转换。最后让他们相加起来的 l o s s loss loss达到最小。如果不是很懂,继续往下看,有个例子
上面的物体很好的定义了,纹理比较好,不对称物体的学习方法,但是对于对称,没有纹理的物体,这样的定义是不行的。比如一个圆铁球,他无论姿态怎么变化,实际上我们看上去似乎没有变换,比如他在原的位置转了一圈。对于类似这样的物体上面的loss会造成网络的模糊学习。类似于,这种情况,网络说,明明我提取特征是一模一样的,你非要强迫我告你姿态发生了什么样的变化,机器感到是很为难的。
所以针对于对称的物体,使用下面的这种方式代替了:
L i p = 1 M ∑ j min 0 < k < M ∣ ∣ ( R x j + t ) − ( R ^ i x k + t ^ i ) ∣ ∣ L^p_i = \frac{1}{M} \sum_j \min_{0
其原理是这个样子的, ( R x j + t ) (Rx_j+t) (Rxj+t)是经过标准 ground truth pose转行得到的标准点云,用这个点云去和预测出来的500(假设我们选择了500个点云)个点云进行距离做差,然后找到最小的一个。总的来说,就是这个意思,要为ground truth的500个点云,分别为他们找到在测出来的500个点云中,距离最近的那一个。也就是说一个ground truth点云要对比500次,那么500个就要对比250000次。他的核心思想是,如果物体不对称,目标模型通过 预测出来的pose变换之后,已经不知道你这个点变到哪里去了,但是这个点肯定是ground truth中的某个点要最近,亦或者说重合(哎,这个鬼,好像不太好解释-没关系后续在源码解析中为大家讲解)。
在网络学习的过程中,就是去把losses: L = 1 N ∑ i L i P L=\frac{1}{N} \sum_iL^P_i L=N1∑iLiP(上面的公式,都是针对一个像素的,这里是一个求和的过程)进行优化,让他达到最小。
但是到这里,我们还要解决一个问题,那就是置信度的问题,我们要从所有的预测中(每个像素/点云都有预测),找出最好的哪个,作为最终的结果。所以每个像素进行姿态估算的时候,还要预测其置信度。所以在每个像素/点云计算loss的时候,我们添加了一个权重如下:
L = 1 N ∑ i ( L i P c i − w log ( c i ) L=\frac{1}{N} \sum_i(L^P_ic_i-w\log(c_i) L=N1i∑(LiPci−wlog(ci)
其上的N表示的是从融合之后的数目(等价于从目标模型随机选取点云的数目), w w w是一个超参数。第一眼看上去,当置信度越大的时候, l o s s loss loss似乎很大,但是要注意其后面的惩罚项 w log ( c i ) w\log(c_i) wlog(ci),置信度越大,该值也会越大,然后结合参数 w w w,可以让整体保持一个单调递减的状态,也就是说, c i ci ci越大, l o s s 越 小 loss越小 loss越小。
3.6. Iterative Refinement
ICP(iterative closest point )算法,对于6D姿态的估算来说,是一个比较好的提炼方法(对初始估算的姿态进行提炼)。但是太慢了,不能实时,我们提出了一种方法,能够实时,并且应用于机器人抓取的任务。
目标是创建一个网络,能通过迭代去纠正一些预测的错误。既然是一个迭代优化的过程,那么我们就需要把上一次的输出,当做这一次的输入,这一次的输出,当做下一次的输入。我们的关键思想是如下:
重 难 点 来 了 , 没 有 你 想 的 那 么 简 单 , 我 也 不 确 定 能 不 能 讲 解 清 楚 , 欢 迎 讨 论 \color{red}{重难点来了,没有你想的那么简单,我也不确定能不能讲解清楚,欢迎讨论} 重难点来了,没有你想的那么简单,我也不确定能不能讲解清楚,欢迎讨论
1.将之前估算的姿态pose看作是相对于目标对象标准帧(参考帧)的估计
2.我们根据估算出来的姿态pose,把输入的点云转换到标准帧对应的点云(看做一个姿态估计逆过程)
3.然后把这个转换(经过逆操作)之后的点云,喂食到反馈网络
其上是一个可以迭代的过程,如下插图:

我们构建了一个残差网络,对主干网络初始估算的姿态进行提炼。
1.每次迭代过程中,其上color embeddings是没有改变的(由主干网络提取出来,主要包含的是颜色外观信息)
2.color embeddings和新产生的geometry embeddings(主要包含了几何信息)进行稠密(像素级)融合。
3.他们融合之后获得一个带有全局(颜色外观+几何空间)信息,利用其进行新的姿态估算。
4.通过上面的描述经过K次迭代之后,我们获得最后的姿态,如下:
p ^ = [ R K ∣ t K ] ⋅ [ R K − 1 ∣ t K − 1 ] ⋅ [ R K − 2 ∣ t K − 2 ] ⋅ ⋅ ⋅ ⋅ ⋅ [ R K ∣ t K ] \hat p=[R_K|t_K]·[R_{K-1}|t_{K-1}]·[R_{K-2}|t_{K-2}] ~·····~[R_K|t_K] p^=[RK∣tK]⋅[RK−1∣tK−1]⋅[RK−2∣tK−2] ⋅⋅⋅⋅⋅ [RK∣tK]
好了,既然是重难点,我来给大家好好分析一下(装逼时间到):
认 真 看 啊 , 认 真 看 , 不 然 后 面 你 看 代 码 就 有 得 受 了 \color{red}{认真看啊,认真看,不然后面你看代码就有得受了} 认真看啊,认真看,不然后面你看代码就有得受了
首先,我们输入一张图片src_img,和对应的点云数据src_cloud(以第一帧为标准),然后通过主干网络的进行特征抽取,得到了color embeddings和geometry embeddings,并且主干网络对当前的图片src_img(或者src_cloud)进行的姿态估算得到poses(包含了很多个-每个点云都有预测),我们从poses中拿到置信度最高的pose当做我们最后的结果。
现在呢,图片src_img在结合其对应的深度图,构建出以摄像头坐标为标准(这里不是第一帧)的点云cur_cloud,我们对这个cur_cloud做一个逆操作,把这个转换到第一帧模型所在的点云去。相当于下面这个操作:

退回到第一帧模型所在的点云之后,再通过PointNet得到geometry embeddings,马上结合color embeddings进行像素级别的融合,得到golal feature送入到一个残差网络进行姿态估算,如下所示:
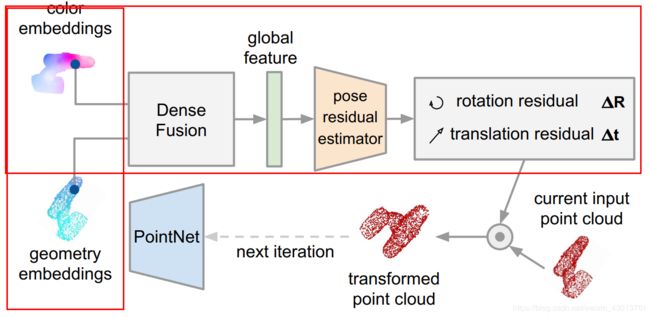
这里预测结果,实际是很接近之前估算的pose,因为自己翻转回去,又进行预测。得到新的pose之后,我们把翻转回去的点云根据这个新的pose进行转换(就是又翻转回来了),得到transformed point cloud,transformed point cloud又用过PointNet得到geometry embeddings,如下过程:
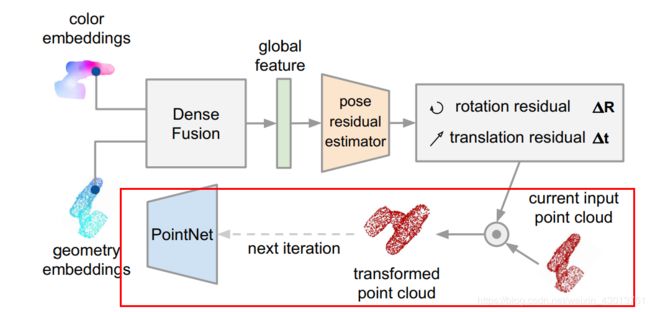
总的来说,这个迭代过程,就是如下标记部分,翻转过来,又翻转回去,又翻转过来…不停的进行迭代:

绿色的两个标记,,表示几何关系相近。
那么问题来了,这是干啥啊,傻乎乎的,翻来又翻去,有什么用吗?容我卖个关子,在详解代码的章节为大家讲解。大家接着看下篇博客吧,我会把剩余部分翻译完。