李宏毅机器学习(一)
一、机器学习三步骤:
Step1: Define a set of function
Model:定义一些函数 f 1 f 2 . . . f_1 f_2... f1f2...
Step2: Goodness of function
使用训练数据,根据输入输出判断函数的好坏。
Step3: Pick the best function
通过Testing挑选出最好的函数。
二、Learning Map:
scenario(学习情境) task(要解决的问题) method(解决方法)
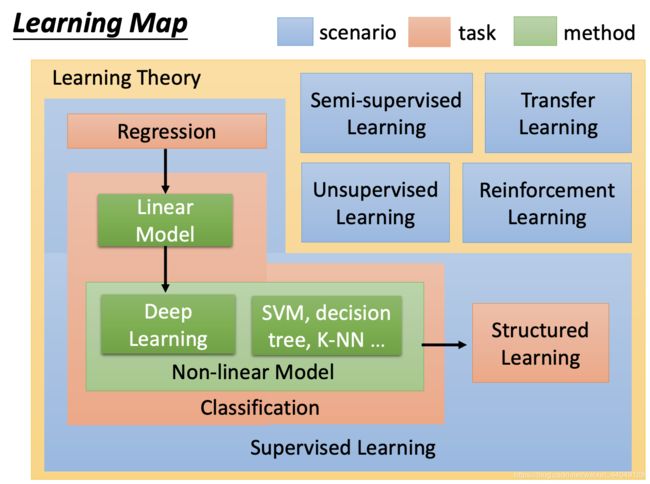
1、Supervised Learning(监督学习)
(1)Regression(回归)
**定义:**The output of the target function f f f is “scalar”
**例子:**预测PM2.5


(2)Classification(分类)
-
Binary Classification
垃圾邮件分类:输入训练数据,告诉函数邮件是否是垃圾邮件。最后能自己判断邮件情况。
-
Multi-class Classification
文档分类:输入训练数据,对数据进行多个分类:政治、体育、财经…….
(3)Struct Learning(结构化预测)
------Beyond Classification
输出的是有结构性的复杂的东西。例如语音识别,根据声音信号的输入输出文字;机器翻译,根据中文输出,输出英文;人脸识别,识别出每个人脸来。
1. Non-Linear Model(非线性模型)
主要是Deep Learning、SVM、决策树、K-NN。这种模型的函数十分复杂,可以用来进行图像分类问题。
2. Linear Model(线性模型)
(4) Training Data
数据输入和输出之间有什么联系,输出(output)是数据的标签(label)。大量的label比较难获取。
2、Unsupervised Learning(非监督学习)
Machine Reading(机器阅读):机器通过阅读大量的文章,从而学习词语的意思。只有输入数据,但是没有输出。
Machine Drawing(机器绘画):训练数据是一堆图片,但是没有做标记。
3、Semi-supervised Learning
识别猫狗,有一些数据是给猫图数据标记为猫、狗图数据标记为狗。但是一堆没有给猫狗图做标签的数据,对学习也有帮助。
4、Transfer Learning:
识别猫狗,一些标记了的数据,另外一些是标记或者没标记的其它不相关的数据,也能够带来帮助。
5、Reinforcement Learning(强化学习)
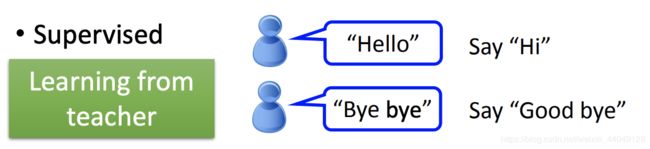
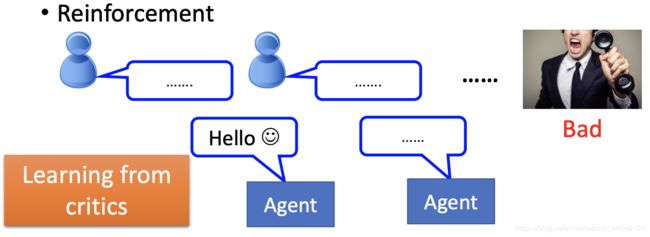
(1 )Supervised v.s. Reinforcement
Supervised:按照人为监督机器进行学习。
Reinforcement:不会告诉机器怎么做,只会给机器学习后的结果做评分。
1. Regression(回归)
(1) 例子
- 股票预测:找一个函数,输入股票数据,得出明天的股票指数。
- 自动驾驶汽车:找一个函数,根据情境,调整方向盘角度。
- 推荐系统:找一个函数,输入使用者A和商品B,得出使用者A购买B的可能性。
(2) 预测宝可梦的CP(Combat Power)值
- 找一个函数,输入宝可梦,得出宝可梦进化后的CP值。
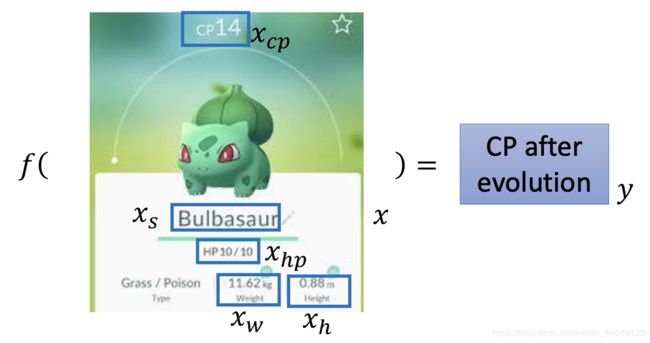
Step 1:Model(function set)
(1) y = b + w . x c p y =b + w.x_{cp} \tag{1} y=b+w.xcp(1)
其中 w w w和 b b b都是参数可以是任意值, x c p x_{cp} xcp是预测之前的CP值, y y y是预测之后的CP值。
Linear model(线性方程): y = b + ∑ w i x i y = b+\sum w_ix_i y=b+∑wixi
( x i x_i xi是输入的一种属性, w i w_i wi是weight权重, b b b表示bias偏置值)
Step 2:Goodness of Function
训练数据:10个宝可梦. ( x 1 , y ^ 1 ) (x^1, \hat y^1) (x1,y^1)、 ( x 2 , y ^ 2 ) (x^2, \hat y^2) (x2,y^2)、 ( x 3 , y ^ 3 ) (x^3, \hat y^3) (x3,y^3)… x 10 , y ^ 10 ) x^{10}, \hat y^{10}) x10,y^10)
https://www.openintro.org/stat/data?data=pokemon
通过训练数据可以定义一个函数的好坏:
(2) L ( f ) = L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w . x c p n ) ) 2 L(f) = L(w, b) = \sum_{n=1}^{10}(\hat y^n-(b+w.x_{cp}^n))^2 \tag{2} L(f)=L(w,b)=n=1∑10(y^n−(b+w.xcpn))2(2)
(真正的数值减去当前函数预测的数值再取平方,就是估测的误差,再把10个数据误差加起来)
使用Loss function L L L,输入是一个函数,输出是输入函数的不好的程度,然后选择出一个最好的函数。穷举所有的 w b w\;b wb,然后选出使损失函数值为最小的,就找到了最好的函数。
f ∗ = a r g m i n L ( f ) f^* = arg \; minL(f) f∗=argminL(f)
w ∗ , b ∗ = a r g m i n L ( w , b ) w^*,b^* = arg \; minL(w, b) w∗,b∗=argminL(w,b)
a r g m i n ∑ n = 1 10 ( y ^ n − ( b + w . x c p n ) arg \; min \sum_{n=1}^{10}(\hat y^n- (b+w.x_{cp}^n) argmin∑n=110(y^n−(b+w.xcpn)
Step 3:Gradient Descent(梯度下降)
通过一个参数 w w w,考虑损失函数:
- 随机选取一个初始值 w 0 w^0 w0
- 计算 d L d w ∣ w = w 0 \frac{dL}{dw}|_w = w^0 dwdL∣w=w0,如果斜率是负的,那么增加w的值;如果斜率是正的,那么增加w的值。
- 计算新的权重 w 1 = w 0 − η d L d w ∣ w = w 0 w^1 = w^0-\eta \frac{dL}{dw}|_{w=w_0} w1=w0−ηdwdL∣w=w0,其中的 η \eta η就是学习率"learning rata"。
- 重复步骤,计算 w 2 = w 1 − η d L d w ∣ w = w 1 w^2 = w^1-\eta \frac{dL}{dw}|_{w=w_1} w2=w1−ηdwdL∣w=w1
- 经过多次迭代
- 遇到鞍点(局部最优点而非全局最优点),可能会导致梯度停止更新。
经过多次迭代后,能够找到局部最优和全局最优。
上面讨论的是一个参数的问题,下面讨论两个参数 w w w和 b b b:
- 随机选取两个参数 w 0 w^0 w0和 b 0 b^0 b0
- 计算两个偏微分: d L d w ∣ w = w 0 \frac{dL}{dw}|_{w=w^0} dwdL∣w=w0, d L d b ∣ w = w 0 , b = b 0 \frac{dL}{db}|_{w=w^0,b=b^0} dbdL∣w=w0,b=b0
- w 1 = w 0 − η d L d w ∣ w = w 0 , b = b 0 w^1 = w^0-\eta \frac{dL}{dw}|_{w=w^0, b=b^0} w1=w0−ηdwdL∣w=w0,b=b0, b 1 = b 0 − η d L d b ∣ w = w 0 , b = b 0 b^1=b^0-\eta\frac{dL}{db}|_{w=w^0,b=b^0} b1=b0−ηdbdL∣w=w0,b=b0
- 再计算两个偏微分: d L d w ∣ w = w 1 , b = b 1 \frac{dL}{dw}|_{w=w^1, b=b^1} dwdL∣w=w1,b=b1, d L d b ∣ w = w 1 , b = b 1 \frac{dL}{db}|_{w=w^1,b=b^1} dbdL∣w=w1,b=b1
- 更新参数, w 2 = w 1 − η d L d w ∣ w = w 1 , b = b 1 w^2 = w^1-\eta \frac{dL}{dw}|_{w=w^1, b=b^1} w2=w1−ηdwdL∣w=w1,b=b1, b 2 = b 1 − η d L d b ∣ w = w 1 , b = b 1 b^2=b^1-\eta\frac{dL}{db}|_{w=w^1,b=b^1} b2=b1−ηdbdL∣w=w1,b=b1
下面使用一张图说明怎么调整包含两个参数的值:
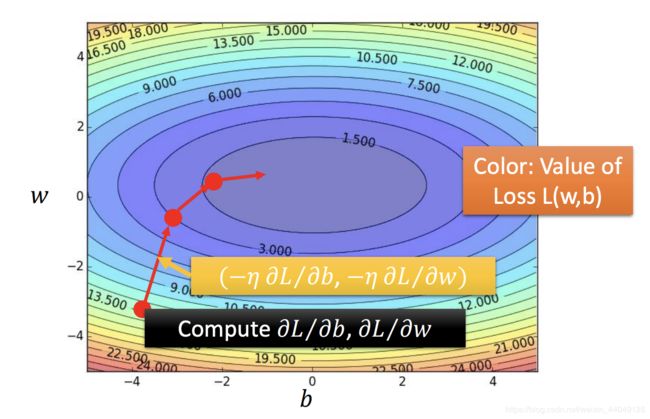
首先,随机选择一个(w, b),然后计算L对w和b的偏微分,根据结果调整梯度大小。下面展开L对w和b的偏微分:
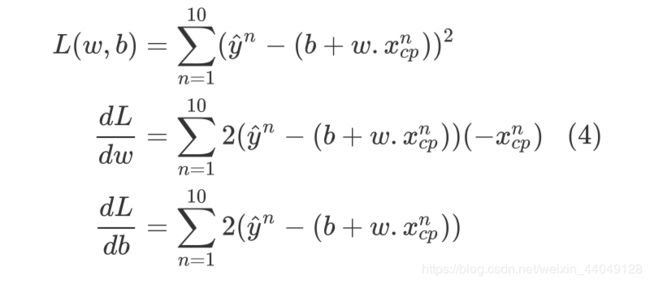
Result
经训练, y = b + w . x c p y=b+w.x_{cp} y=b+w.xcp的结果:
b = − 188.4 w = 2.7 a _ e = 31.9 b = -188.4 \\ w = 2.7 \\ a\_e = 31.9 b=−188.4w=2.7a_e=31.9
但是真正关心的average—error在于在新的宝可梦上的准确率。在新的10只宝可梦数据测试后, a e = 35.0 > 31.9 a_e=35.0>31.9 ae=35.0>31.9。如果要函数想要做得更好,应该再设计一下model:
(5) y = b + w 1 . x c p + w 2 . ( x c p ) 2 y = b+w_1.x_{cp}+w_2.(x_{cp})^2 \tag{5} y=b+w1.xcp+w2.(xcp)2(5)
经过训练之后,结果如下:
b = − 10.3 w 1 = 1.0 w 2 = 2.7 × 1 0 − 3 a _ e = 15.4 b = -10.3 \\ w_1 = 1.0 \\ w_2 = 2.7 \times 10^{-3} \\ a\_e = 15.4 b=−10.3w1=1.0w2=2.7×10−3a_e=15.4
但是测试的average_error是18.4。此时average_error已经很低了,但是如果想要更好的function,需要再增加 x x x的次方数:
(5) y = b + w 1 . x c p + w 2 . ( x c p ) 2 + w 3 . ( x c p ) 3 y = b+w_1.x_{cp}+w_2.(x_{cp})^2+w_3.(x_{cp})^3 \tag{5} y=b+w1.xcp+w2.(xcp)2+w3.(xcp)3(5)
经过训练之后,结果如下:
b = − 6.4 w 1 = 0.66 w 2 = 4.3 × 1 0 − 3 w 2 = − 1.8 × 1 0 − 6 a _ e = 15.3 b = -6.4 \\ w_1 = 0.66 \\ w_2 = 4.3 \times 10^{-3} \\ w_2 = -1.8 \times 10^{-6} \\ a\_e = 15.3 b=−6.4w1=0.66w2=4.3×10−3w2=−1.8×10−6a_e=15.3
测试的average_error是18.1。最好的函数或许是一个更加复杂的函数?
(6) y = b + w 1 . x c p + w 2 . ( x c p ) 2 + w 3 . ( x c p ) 3 + w 4 . ( x c p ) 4 y = b+w_1.x_{cp}+w_2.(x_{cp})^2+w_3.(x_{cp})^3+w_4.(x_{cp})^4 \tag{6} y=b+w1.xcp+w2.(xcp)2+w3.(xcp)3+w4.(xcp)4(6)
训练之后的 a _ e = 14.9 a\_e=14.9 a_e=14.9,但是测试数据上的结果是 a e = 28.8 a_e = 28.8 ae=28.8,在新数据上拟合更差了。再加次方数,在测试数据上更糟糕。
因此,可以得出规律:model更复杂,在训练数据上的误差值就越低,但是在测试数据上不一样,误差值会逐渐降低之后暴增。
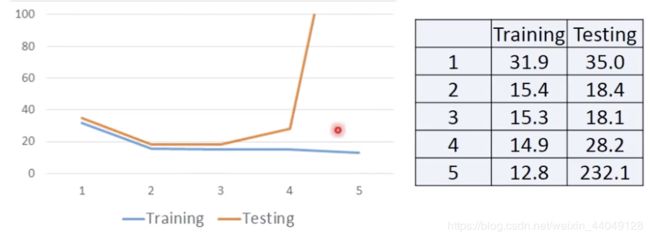
这种情况就是"Over fitting",即为过拟合,不是模型越复杂越好,应该选择一个合适的模型。
或许存在一些隐藏因素影响进化后的CP值?
Back to Step 1:
重新设计Model(考虑物种因素):
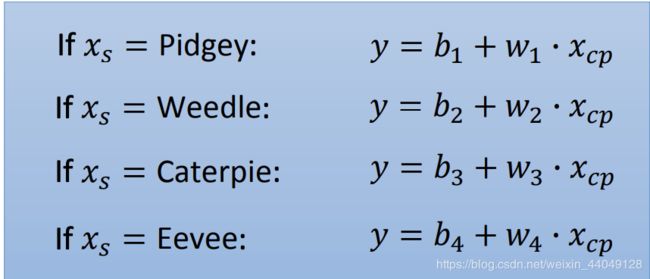
除去if,写出函数形式:
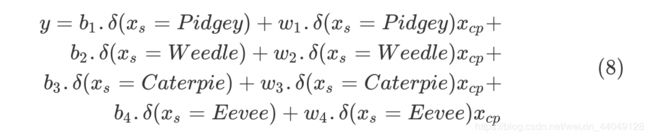
如果输入数据是某种宝可梦,该宝可梦对应的 δ ( x s ) \delta(x_s) δ(xs)是1,其余的是0。
考虑到种类之后,在训练数据上的 a _ e = 3.8 a\_e = 3.8 a_e=3.8,在测试数据上 a _ e = 14.3 a\_e = 14.3 a_e=14.3。如果还要完善,则把相关的影响因素全部加入到model中:考虑进化前CP值( x c p x_{cp} xcp)、种类( x s x_s xs)、HP值( x h p x_{hp} xhp)、高度( x h x_h xh)、体重( x w x_w xw)。
用这个Model在训练数据上的 a _ e = 1.9 a\_e = 1.9 a_e=1.9,但是在测试数据上是 102.3 102.3 102.3。
Back to Step 2:Regularization
给Loss function加入正则化:
(9) y = b + ∑ w i x i L = ∑ n ( y ^ n − ( b + ∑ w i x i ) ) 2 + λ ∑ ( w i ) 2 y = b+\sum{w_ix_i} \\ L = \sum_n(\hat y^n-(b+\sum w_ix_i))^2 + \lambda\sum(w_i)^2 \tag{9} y=b+∑wixiL=n∑(y^n−(b+∑wixi))2+λ∑(wi)2(9)
根据公式(9),可以看出损失函数需要的更优结果是 ∣ w i ∣ |w_i| ∣wi∣更小,因此函数会更加平滑,对输入数据更不敏感,变化越小,更不容易被噪音noise影响到,能防止在新数据上偏差大,得到一个比较好的结果。但是也不能太平滑,还是需要调整一个合适的 λ \lambda λ,如下图所示:
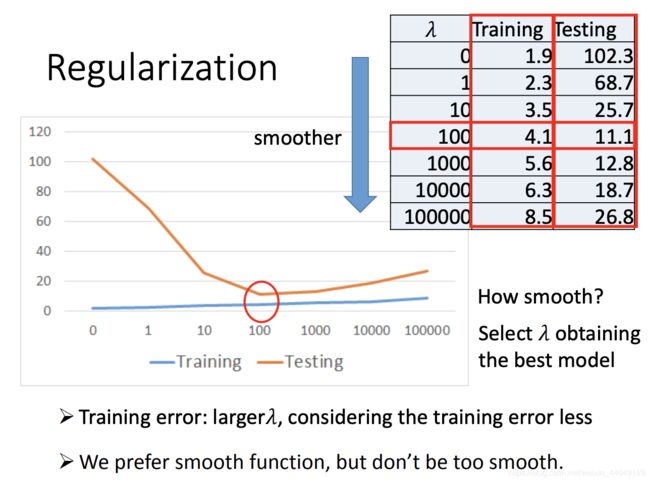
正则化为什么不考虑b——因为函数的平滑与否,跟它没关系。
相关学习
1 中心极限定理
(1)定义
- 样本的平均值约等于总体的平均值。
- 不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的整体平均值周围,并且呈正态分布。
(2) 理解
- 随机抽取1个样本,样本大小为100,求该样本的平均值。(根据经验,样本大小必须达到30,中心极限定理才保证成立)
- 将第1步样本抽取的工作重复再三,不断地从总体随机抽取样本,例如我抽取了5个样本,每个大小为100,并计算出每个样本的平均值,那么5个样本,就会有5个平均值。因此,样本数量为5。
- 根据中心极限定理,这些样本平均值中的绝大部分都极为接近总体的平均值。有一些会稍高一点,有一些会稍低一点,只有极少数的样本平均值大大高于或低于群体平均值。
- 中心极限定理告诉我们,不论所研究的群体是怎样分布的,这些样本平均值会在总体平均值周围呈现一个正态分布。
(3) 样本估计整体
-
标准差:数据集中数值与平均值的偏离程度。
-
一般样本数据更加紧密聚集在均值周围,所以样本的标准差是要小于总体标准差。
-
所以,为了更好的用样本估计总体的标准差,统计学家就将标准差的公式做了像下面公式中这样的改造。
数据集标准差 σ \sigma σ:
(1) σ = ∑ ( x − μ ) 2 n \sigma = \sqrt{\frac{\sum(x-\mu)^2}{n}} \tag{1} σ=n∑(x−μ)2(1)
样本标准差 s s s:
(2) s = ∑ ( x − μ ) 2 n − 1 s = \sqrt{\frac{\sum(x-\mu)^2}{n-1}} \tag{2} s=n−1∑(x−μ)2(2) -
原来的标准差公式是除以 n n n,为了用样本估计总体标准差,现在是除以 n − 1 n-1 n−1。这样就是的标准略大。
-
如果只是想计算一个数据集的标准差,那么就除以n;如果想把这个数据集当成一个样本,用这个样本来估计出总体的标准差,那么就除以n-1的标准差公式。
(4) 标准误差
-
定义:标准误差其实也是标准差,只不过它是所有样本平均值的标准差。怎么理解呢?其实就是你选取多个样本,对每个样本求平均值,每个平均值又组成了一个新的数据集,然后对这些平均值计算标准差,就是标准误差。概括成一句话:求样本平均值的标准差就是标准误差。
-
作用:用来衡量样本平均值的波动大小。
-
计算公式:
(3) S E = s n SE = \frac{s}{\sqrt{n}} \tag{3} SE=ns(3)
标准误差 S E SE SE等于总体标准差除以 n n n的开,可以用样本来估计出总体标准差的公式 s s s。
(5) 中心极限定理的作用
- 在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体
- 根据总体的平均值和标准差,判断某个样本是否属于总体
(6) 中心极限定理的代码模拟
本代码来源:https://github.com/sijichun/MathStatsCode/blob/master/notebook_python/LLN_CLT.ipynb
import numpy as np
from numpy import random as nprd
def sampling(N):
## 产生一组样本,以0.5的概率为z+3,0.5的概率为z-3,其中z~N(0,1)
d = nprd.rand(N)<0.5
z=nprd.randn(N)
x=np.array([z[i]+3 if d[i] else z[i]-3 for i in range(N)])
return x
N=[2,3,4,10,100,1000] # sample size
M=2000
MEANS=[]
for n in N:
mean_x=np.zeros(M)
for i in range(M):
x=sampling(n)
mean_x[i]=np.mean(x)/np.sqrt(10/n) ## 标准化,因为var(x)=10
MEANS.append(mean_x)
## 导入matplotlib
import matplotlib.pyplot as plt
import matplotlib.mlab as mlab
## 使图形直接插入到jupyter中
%matplotlib inline
# 设定图像大小
plt.rcParams['figure.figsize'] = (10.0, 8.0)
x=sampling(1000)
plt.xlabel('x')
plt.ylabel('Density')
plt.title('Histogram of Mixed Normal')
plt.hist(x,bins=30,normed=1) ## histgram
plt.show() ## 画图
## 均值
ax1 = plt.subplot(2,3,1)
ax2 = plt.subplot(2,3,2)
ax3 = plt.subplot(2,3,3)
ax4 = plt.subplot(2,3,4)
ax5 = plt.subplot(2,3,5)
ax6 = plt.subplot(2,3,6)
## normal density
x=np.linspace(-3,3,100)
d=[1.0/np.sqrt(2*np.pi)*np.exp(-i**2/2) for i in x]
def plot_density(ax,data,N):
ax.hist(data,bins=30,normed=1) ## histgram
ax.plot(x,d)
ax.set_title(r'Histogram of $\bar{x}$:N=%d' % N)
plot_density(ax1,MEANS[0],N[0])
plot_density(ax2,MEANS[1],N[1])
plot_density(ax3,MEANS[2],N[2])
plot_density(ax4,MEANS[3],N[3])
plot_density(ax5,MEANS[4],N[4])
plot_density(ax6,MEANS[5],N[5])
plt.show() ## 画图
2 正态分布
-
定义:若随机变量 X X X服从一个位置参数为 μ \mu μ,尺度参数为 σ \sigma σ的正态分布,记为:
(4) X ∼ N ( μ , σ 2 ) f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 X \sim N(\mu, \sigma^2) \\ f(x) = \frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} \tag{4} X∼N(μ,σ2)f(x)=σ2π1e−2σ2(x−μ)2(4) -
正态分布中一些值得注意的量:
- 密度函数关于平均值对称
- 平均值与它的众数以及中位数是同一数值。
- 函数曲线下68.268949%的面积在平均数左右的一个标准差范围内。
- 95.449974%的面积在平均数左右两个标准差 2 σ 2\sigma 2σ的范围内。
- 99.730020%的面积在平均数左右三个标准差 3 σ 3\sigma 3σ的范围内。
- 99.993666%的面积在平均数左右四个标准差 4 σ 4\sigma 4σ的范围内。
- 函数曲线的拐点为离平均数一个标准差距离的位置。
3 最大似然估计
- 定义:利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”的方法。
- 似然函数:对于函数 P ( x ∣ θ ) P(x|\theta) P(x∣θ),输入 x x x表示某一个具体的数据, θ \theta θ表示模型的参数。如果 θ θ θ是已知确定的, x x x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点 x x x,其出现概率是多少。如果 x x x是已知确定的, θ θ θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现 x x x这个样本点的概率是多少。
- 最大似然估计(MLE):是求参数 θ θ θ, 使似然函数 P ( x 0 ∣ θ ) P(x_0|θ) P(x0∣θ)最大。
- 例子:假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?
很明显是70%。 - 解释:设例子中100次抽样的结果概率表示为P(样本结果|Model) = p 70 . ( 1 − p ) 30 p^{70}.(1-p)^{30} p70.(1−p)30,其中 p p p表示白球的比例。要求的是模型的参数,也就是求式中的 p p p。 p p p是可以有无数种分布的,例如 p = 50 % p=50\% p=50%,此时结果 p 70 . ( 1 − p ) 30 = 7.8 ∗ 1 0 − 31 p^{70}.(1-p)^{30}=7.8 * 10^{-31} p70.(1−p)30=7.8∗10−31 结果是;当 p = 70 p=70% p=70, p 70 . ( 1 − p ) 30 = 2.95 ∗ 1 0 − 27 p^{70}.(1-p)^{30}=2.95*10^{-27} p70.(1−p)30=2.95∗10−27.从这里就能看出,极大似然估计是按照让这个样本结果出现的可能性最大的方法选择Model参数值。
4 损失函数与凸函数之间的关系
在线性回归中,损失函数 L L L一定是凸函数。但是其它函数可能是非凸函数,这会导致损失函数存在局部最优解,导致无法找到全局最优解。
5 泰勒展开
- 定义:若函数 f ( x ) f(x) f(x)在包含 x 0 x_0 x0的某个闭区间 [ a , b ] [a,b] [a,b]上具有n阶导数,且在开区间 ( a , b ) (a,b) (a,b)上具有(n+1)阶导数,则对闭区间 [ a , b ] [a,b] [a,b]上任意一点 x x x,成立下式:
f ( x ) = f ( x 0 ) + f ‘ ( x 0 ) 1 ! ( x − x 0 ) + f ‘ ‘ x 0 ) 2 ! ( x − x 0 ) 2 + . . . + f ( n ) ( x 0 ) n ! ( x − x 0 ) n + R n ( x ) f(x) = f(x_0)+\frac{f^`(x_0)}{1!}(x-x_0)+\frac{f^{``}x_0)}{2!}(x-x_0)^2+...+\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n+R_n(x) f(x)=f(x0)+1!f‘(x0)(x−x0)+2!f‘‘x0)(x−x0)2+...+n!f(n)(x0)(x−x0)n+Rn(x)
6 L2-Norm,L1-Norm,L0-Norm
-
这三者是机器学习中的正则化,常用来:1)保证模型尽可能的简单,避免过拟合;2)约束模型特性,加入一些先验知识,例如稀疏、低秩等。L1表示曼哈顿距离,L2表示欧式距离。
-
L0范数是指向量中非零元素的个数,如果用L0规则化一个参数矩阵 W W W,就是希望 W W W中大部分元素是零,实现稀疏。L1范数是指向量中各个元素的绝对值之和,也叫”系数规则算子(Lasso regularization)“。L1范数也可以实现稀疏,通过将无用特征对应的参数 W W W置为零实现。L0和L1都可以实现稀疏化,不过一般选用L1而不用L0。L2范数是指向量各元素的平方和然后开方,用在回归模型中也称为岭回归(Ridge regression)。L2避免过拟合的原理是:让L2范数的规则项 ∣ ∣ W ∣ ∣ 2 ||W||_2 ∣∣W∣∣2 尽可能小,可以使得W每个元素都很小,接近于零,但是与L1不同的是,不会等于0;这样得到的模型抗干扰能力强,参数很小时,即使样本数据 x x x发生很大的变化,模型预测值 y y y的变化也会很有限。
7 正则化及其推导
1)L1正则化
大部分的正则化方法是在经验风险或者经验损失 L e m p L_{emp} Lemp(emprirical loss)上加上一个结构化风险,我们的结构化风险用参数范数惩罚 Ω ( θ ) Ω(θ) Ω(θ),用来限制模型的学习能力、通过防止过拟合来提高泛化能力。所以总的损失函数(也叫目标函数)为:
(1.1) J ( θ ; X , y ) = L e m p ( θ ; X , y ) + α Ω ( θ ) J(θ;X,y)=L_{emp}(θ;X,y)+αΩ(θ) \tag{1.1} J(θ;X,y)=Lemp(θ;X,y)+αΩ(θ)(1.1)
其中 X X X是输入数据, y y y是标签, θ θ θ是参数, α ∈ [ 0 , + ∞ ] α∈[0,+∞] α∈[0,+∞]是用来调整参数范数惩罚与经验损失的相对贡献的超参数,当 α = 0 α=0 α=0时表示没有正则化, α α α越大对应该的正则化惩罚就越大。对于L1正则化,我们有:
(1.2) Ω ( θ ) = ‖ w ‖ 1 Ω(θ)=‖w‖_1 \tag{1.2} Ω(θ)=‖w‖1(1.2)
根据上两式,可以推导出L1正则化的目标函数:
(1.3) J ( w ; X , y ) = L e m p ( w ; X , y ) + α ‖ w ‖ 1 J(w;X,y)=L_{emp}(w;X,y)+α‖w‖_1 \tag{1.3} J(w;X,y)=Lemp(w;X,y)+α‖w‖1(1.3)
我们的目的是求得使目标函数取最小值的 w ∗ w^∗ w∗,上式对 w w w求导可得:
(1.4) ∇ w J ( w ; X , y ) = ∇ w L e m p ( w ; X , y ) + α ⋅ s i g n ( w ) ∇_wJ(w;X,y)=∇_wL_{emp}(w;X,y)+α⋅sign(w)\tag{1.4} ∇wJ(w;X,y)=∇wLemp(w;X,y)+α⋅sign(w)(1.4)
其中若 w > 0 w>0 w>0,则 s i g n ( w ) = 1 sign(w) = 1 sign(w)=1;若 w < 0 w<0 w<0,则 s i g n ( w ) = − 1 sign(w)=−1 sign(w)=−1;若 w = 0 w=0 w=0,则 s i g n ( w ) = 0 sign(w)=0 sign(w)=0。当 α = 0 α=0 α=0,假设我们得到最优的目标解是 w ∗ w^∗ w∗,用泰勒公式在 w ∗ w^∗ w∗处展开可以得到:
(1.5) J ( w ; X , y ) = J ( w ∗ ; X , y ) + 1 2 ( w − w ∗ ) H ( w − w ∗ ) J(w;X,y)=J(w^∗;X,y)+\frac12(w−w^∗)H(w−w^∗) \tag{1.5} J(w;X,y)=J(w∗;X,y)+21(w−w∗)H(w−w∗)(1.5)
其中 H H H是关于 w w w的Hessian矩阵,为了得到更直观的解,我们简化H,假设H是对角矩阵,则有:
(1.6) H = d i a g ( [ H 1 , 1 , H 2 , 2 . . . H n , n ] ) H=diag([H_{1,1}, H_{2,2}...H_{n,n}]) \tag{1.6} H=diag([H1,1,H2,2...Hn,n])(1.6)
将上式代入到式(1.3)中可以得到,我们简化后的目标函数可以写成这样:
(1.7) J ( w ; X , y ) = J ( w ∗ ; X , y ) + ∑ i [ 1 2 H i , i ( w i − w i ∗ ) 2 + α i ∣ w i ∣ ] J(w;X,y)=J(w^∗;X,y)+∑_i[\frac12 H_{i,i}(w_i−w^∗_i)^2+α_i|w_i|] \tag{1.7} J(w;X,y)=J(w∗;X,y)+i∑[21Hi,i(wi−wi∗)2+αi∣wi∣](1.7)
从上式可以看出,w各个方向的导数是不相关的,所以可以分别独立求导并使之为0,可得:
(1.8) H i , i ( w i − w i ∗ ) + α ⋅ s i g n ( w i ) = 0 H_{i,i}(w_i−w^∗_i)+α⋅sign(w_i)=0 \tag{1.8} Hi,i(wi−wi∗)+α⋅sign(wi)=0(1.8)
我们先直接给出上式的解,再来看推导过程:
(1.9) w i = s i g n ( w ∗ ) m a x { ∣ w i ∗ ∣ − α H i , i , 0 } w_i=sign(w^∗)max\{|w^∗_i|−\fracαH_{i,i},0\} \tag{1.9} wi=sign(w∗)max{∣wi∗∣−Hαi,i,0}(1.9)
从式(1.7)与式(1.8)可以得到两点:
-
可以看到式(1.7)中的二次函数是关于 w ∗ w^∗ w∗对称的,所以若要使式(1.7)最小,那么必有: ∣ w i ∣ < ∣ w ∗ ∣ |w_i|<|w^∗| ∣wi∣<∣w∗∣,因为在二次函数值不变的程序下,这样可以使得 α ∣ w i ∣ α|w_i| α∣wi∣更小。
-
s i g n ( w i ) = s i g n ( w i ∗ ) sign(w_i)=sign(w^∗_i) sign(wi)=sign(wi∗)或 w 1 = 0 w_1=0 w1=0,因为在 α ∣ w i ∣ α|w_i| α∣wi∣不变的情况下,
s i g n ( w i ) = s i g n ( w i ∗ ) sign(w_i)=sign(w_i^∗) sign(wi)=sign(wi∗)或 w i = 0 w_i=0 wi=0可以使式(1.7)更小。
由式(1.8)与上述的第2点,可以得到:
(1.10) 0 = H i , i ( w i − w i ∗ ) + α ⋅ s i g n ( w i ∗ ) w i = w i ∗ − α H i , i s i g n ( w i ∗ ) w i = s i g n ( w i ∗ ) ∣ w i ∗ ∣ − α H i , i s i g n ( w ∗ i ) = s i g n ( w i ∗ ) ( ∣ w i ∗ ∣ − α H i , i ) 0=H_{i,i}(w_i−w^∗_i)+α⋅sign(w^∗_i) \\ w_i=w^∗_i−\fracαH_{i,i}sign(w^∗_i) \\ w_i=sign(w^∗_i)|w^∗_i|−αH_{i,i}sign(w^∗i) \\ =sign(w^∗_i)(|w^∗_i|−\fracαH_{i,i}) \tag{1.10} 0=Hi,i(wi−wi∗)+α⋅sign(wi∗)wi=wi∗−Hαi,isign(wi∗)wi=sign(wi∗)∣wi∗∣−αHi,isign(w∗i)=sign(wi∗)(∣wi∗∣−Hαi,i)(1.10)
我们再来看一下第2点: s i g n ( w i ) = s i g n ( w i ∗ ) sign(w_i)=sign(w^∗_i) sign(wi)=sign(wi∗)或 w 1 = 0 w_1=0 w1=0,若 ∣ w i ∗ ∣ < α H i , i |w^∗_i|<\frac αH_{i,i} ∣wi∗∣<Hαi,i,那么有 s i g n ( w i ) ≠ s i g n ( w ∗ i ) sign(w_i)≠sign(w^∗i) sign(wi)̸=sign(w∗i),所以这时有 w 1 = 0 w_1=0 w1=0,由于可以直接得到解式(1.9)。从这个解可以得到两个可能的结果:
- 若 ∣ w ∗ i ∣ ≤ α H i , i |w^∗i|≤αH_{i,i} ∣w∗i∣≤αHi,i,正则化后目标中的 w i w_i wi的最优解是 w i = 0 w_i=0 wi=0。因为这个方向上 L e m p ( w ; X , y ) L_{emp}(w;X,y) Lemp(w;X,y)的影响被正则化的抵消了。
- 若 ∣ w i ∗ ∣ > α H i , i |w^∗_i|>\fracαH_{i,i} ∣wi∗∣>Hαi,i,正则化不会推最优解推向0,而是在这个方面上向原点移动了αHi,iαHi,i的距离。
8 L1-Norm代替L0-Norm
原因包括:
(1)L0范数很难优化求解(NP难);
(2)L1是L0的最优凸近似,比L0更容易优化求解。
9 为什么只对w/Θ做限制,不对b做限制
因为影响梯度大小的只有 w w w值,而与 b b b无关。