ELK分布式日志平台搭建及其简单应用
文章目录
- 一、ELK简介
- 1、认识ELK
- 2、ELK架构图
- 3、ELFK架构
- ELFK架构图
- 二、ELK伪分布式日志平台搭建
- 搭建流程
- 1、在相应容器下载所需要软件
- 2、安装Elasticsearch
- 3、解决Elasticsearch启动报错
- 4、安装Kibana
- 5、安装Logstash
- 三、ELK收集标准输入日志,并在web界面显示
- 四、收集discuz论坛的访问日志
- 五、阿里云+腾讯云主机实现ES集群
作为运维人员,其价值不在于部署大量服务,而在于排错及服务性能优化,优化主要是考的是对服务配置及其参数的理解,而排错我们主要是借助日志文件,来完成的,早期我们借助sed、awk、grep三剑客在一般中小企业还是有很大的作用。但是在大企业的集群架构中,三剑客已经略显疲态,日志收集与处理的非常难,而且不方便。于是ELK分布式日志平台就应运而生!
大家可以用三剑客尝试模拟千万级别pv的日志分析,完全就是不可行的!百万级别的pv就已经很吃力了!
一、ELK简介
1、认识ELK
ELK并不是一款独立的软件服务,而是三个软件的统称,它们分别是Elasticserach、Logstash、Kibana。ELK主要用于对大量服务器的各种日志进行集中化管理,同时可以对日志进行分析。
- Elasticsearch是基于JAVA语言开发的,是分布式存储、搜索引擎,底层是使用lucene检索机制,主要是用于集中化管理日志、对日志内容进行分析和统计,实时、快速展示结果,ES可单独使用,也可以结合Logstash、Kibana。
- Kibana是基于Node.js框架语言开发的,主要是为Elasticsearch、Logstash提供web UI界面的,可以读取ES集群的日志数据,用户通过web界面可以轻松简单实现对日志的快速处理及查看。
- Logstash是基于JAVA语言开发的,主要是用于收集客户端的日志数据:系统日志、内核日志、应用日志、安全日志、审计日志等;还可以对日志内容进行过滤,最终将日志发送给ES集群。
注意:
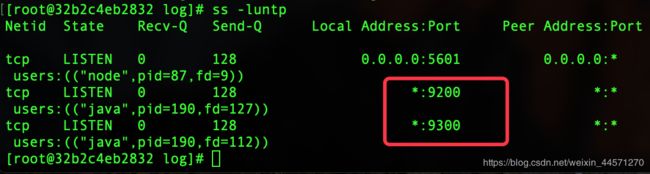 Elasticsearch开启了两个端口,其作用是:
Elasticsearch开启了两个端口,其作用是:
- 9200
是ES节点与外部通讯使用的端口。它是http协议的RESTful接口 - 9300
是ES节点之间通讯使用的端口。它是tcp通讯端口,集群间和TCPclient都走的它。(java程序中使用ES时,在配置文件中要配置该端口)
2、ELK架构图
 加入Redis队列后工作流程:
加入Redis队列后工作流程:
Logstash包含Index和Agent(shipper) ,Agent负责客户端监控和过滤日志,而Index负责收集日志并将日志交给ElasticSearch,ElasticSearch将日志存储本地,建立索引、提供搜索,kibana可以从ES集群中获取想要的日志信息。
3、ELFK架构
后面又出来了一个软件!
Filebeat:它是一个基于go语言编写的轻量级日志采集器,Filebeat属于beats家族6个成员之一,早期的ELK架构中使用Logstash收集、解析日志并且过滤日志,但是Logstash对CPU、内存、IO等资源消耗比较高,相比Logstash,Filebeat所占系统的CPU和内存几乎可以忽略不计;所以后面就出先了ELFK日志平台。
ELFK架构图
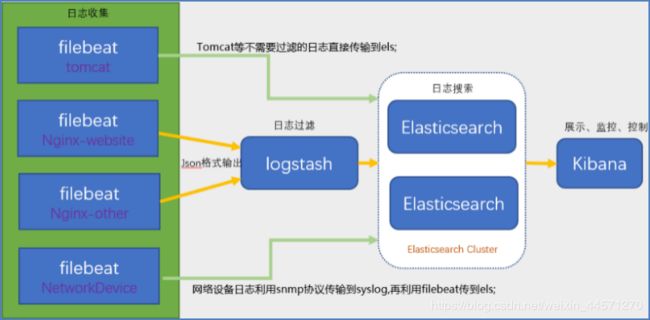 ELFK工作流程:
ELFK工作流程:
使用FileBeat获取Linux服务器上的日志。当启动Filebeat时,它将启动一个或多个Prospectors (检测者),查找服务器上指定的日志文件,作为日志的源头等待输出到Logstash。
Logstash从FileBeat获取日志文件。Filebeat作为Logstash的输入input将获取到的日志进行处理,Logstash将处理好的日志文件输出到Elasticsearch进行处理。
Elasticsearch得到Logstash的数据之后进行相应的搜索存储操作。将写入的数据可以被检索和聚合等以便于搜索操作,最后Kibana通过Elasticsearch提供的API将日志信息可视化的操作。
二、ELK伪分布式日志平台搭建
我用docker起了两个Centos容器:
docker1: 172.17.0.2 Elasticsearch+kibana
docker2: 172.17.0.3 Logstash
注意:开的两个容器必须给–privileged超级权限!
搭建流程
1、在相应容器下载所需要软件
docker1
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.3.0.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.3.0-linux-x86_64.tar.gz
#安装jdk1.8.0
wget wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u141-b15/336fa29ff2bb4ef291e347e091f7f4a7/jdk-8u141-linux-x64.tar.gz"
docker2
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.3.0.tar.gz
scp 172.17.0.2:/jdk-8u141-linux-x64.tar.gz /usr/local/
安装要点:
- 凡是用JAVA语言写的软件,要想使用必须得要安装jdk。安装方法详见:
https://blog.csdn.net/weixin_44571270/article/details/102939666
- ELK三个软件需要保持版本的高度一致!像我就安装的全是5.3.0版本的。另外jdk版本不能低于1.8.0。
2、安装Elasticsearch
#把ELK三个软件都移到各自容器的/usr/local/下
cd /usr/local
tar xvf elasticsearch-5.3.0.tar.gz
mv elasticsearch-5.3.0 elasticsearch
cd elasticsearch
vim /usr/local/elasticsearch/config/elasticsearch.yml #修改下面的参数

#启动elasticsearch,这个服务不能用root用户启动,只能使用普通用户启动它
useradd elasticsearch
chown —R elasticsearch:elasticsearch /usr/local/elasticsearch #为了避免该普通用户访问elasticsearch相关配置文件无权限,故授权!
su - elasticsearch
/usr/local/elasticsearch/bin/elasticsearch -d #启动elasticsearch
3、解决Elasticsearch启动报错
像上面这样配置!过一会儿后,你会发现elasticsearch进程并没有起来!接下来我们需要查看elasticsearch日志。
exit #从普通用户切回root用户
tail -n 50 /usr/local/elasticsearch/logs/
报错:
 解决:
解决:
vi /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
#注意上面这个配置文件是系统配置文件,如果你起容器的时候没给--privileged权限,这里就会报错,read only file system!

现在这种日志就说明已经成功启动了!
其他报错情况:
(1)SecComp功能不支持;
ERROR: bootstrap checks failed
system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk;
因为Centos6不支持SecComp,而ES5.3.0默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。
解决方法:
在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
(2)内核参数设置问题;
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
max number of threads [1024] for user [hadoop] is too low, increase to at least [2048]
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:
vim /etc/security/limits.conf
soft nofile 65536
hard nofile 65536
vim /etc/security/limits.d/90-nproc.conf
soft nproc 2048
vim /etc/sysctl.conf
vm.max_map_count=655360
(2)JVM堆内存太大
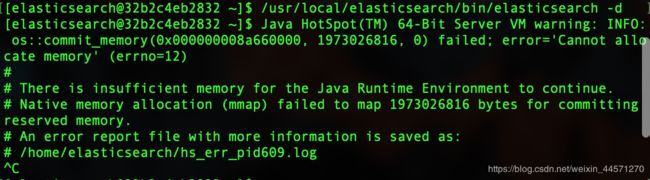 配置中给的内存大于原有物理内存。因为此虚拟机我只给了1G内存!
配置中给的内存大于原有物理内存。因为此虚拟机我只给了1G内存!
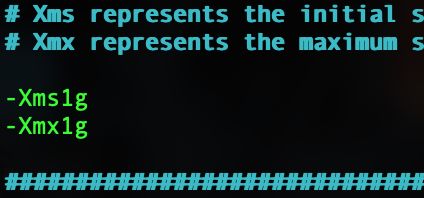
vim /usr/local/elasticsearch/config/jvm.options
4、安装Kibana
tar xvf kibana-5.3.0-linux-x86_64.tar.gz
mv kibana-5.3.0-linux-x86_64 /usr/local/kibana/
修改kibana配置文件信息:
vim /usr/local/kibana/config/kibana.yml
指定监听端口:

指定监听网卡,监听所有网卡:
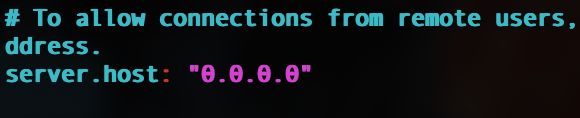
指定ES服务器的地址:
 启动命令:
启动命令:nohup /usr/local/kibana/bin/kibana &
5、安装Logstash
cd /usr/local
tar xvf logstash-5.3.0.tar.gz
mv logstash-5.3.0 logstash
注:这里就安装好了,至于启动logstash,启动它首先我们需要定义采集那些日志,在下面我们会做一个简单示例!
三、ELK收集标准输入日志,并在web界面显示
#创建收集日志配置目录;
mkdir -p /usr/local/logstash/config/etc/
cd /usr/local/logstash/config/etc/
创建ELK整合配置文件:vim stdin.conf,内容如下:
input {
stdin { }
}
output {
stdout {
codec => rubydebug {}
}
elasticsearch {
hosts => "172.17.0.2:9200"
}
}
启动logstash采集标准输入日志:
/usr/local/logstash/bin/logstash -f /usr/local/logstash/stdin.conf
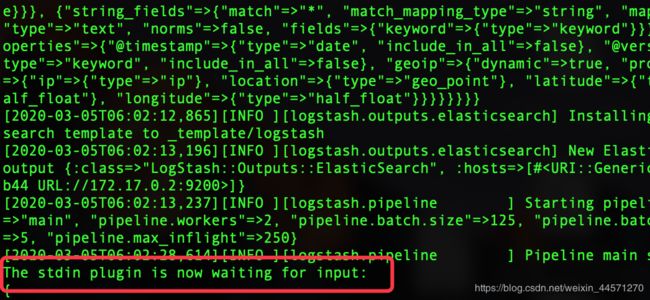

注:Logstash启动窗口中输入任意信息,会自动输出相应格式日志信息
达到上面这个效果了,之后在浏览器输入172.16.193.200:5601(这是我宿主机的ip,我是给虚拟机做了5601端口映射的)。
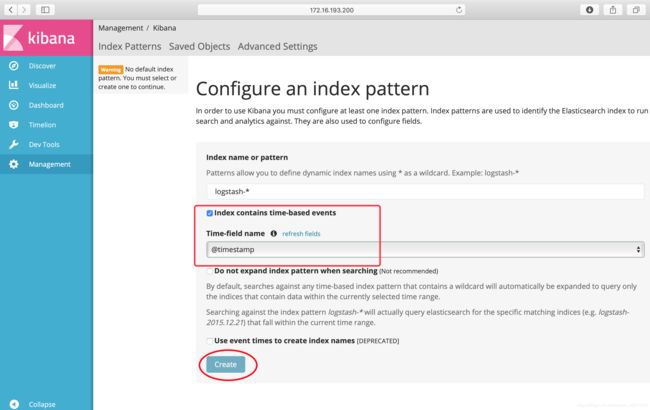 创建成功后,再次点击Discover:
创建成功后,再次点击Discover:
 标准输入日志获取成功,ELK日志平台搭建成功!
标准输入日志获取成功,ELK日志平台搭建成功!
四、收集discuz论坛的访问日志
和前面不一样的只是把stdin.conf文件改动一下即可!
vim discuz.conf
#收集论坛访问日志
input {
file {
type => "nginx-access"
path => "/var/log/nginx/access.log"
}
}
#收集MariaDB数据库日志
input {
file {
type => "MySQL-logs"
path => "/var/log/mariadb/mariadb.log"
}
}
#收集内核日志
input {
file {
type => "Kernel-logs"
path => "/var/log/messages"
}
}
output {
elasticsearch {
hosts => "172.17.0.2:9200"
}
}
无论你监控内核日志,还是应用日志等等,直接type可以随便填,path填日志路径即可!!
#我们后台启动即可,因为不需要输入啥,所以放在后台自己运行即可。
nohup /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/getlog.conf.d/discuz.conf &
#输出的内容都在当前目录下的nohup.out文件中,查看nohup.out文件可以看是否成功运行logstash。
tail -fn 50 nohup.out

成功收集到nginx和mariadb日志!
注意这里有可能会报错:

这个是由于logstash和elasticsearch通信有问题造成的。
可能是9200端口防火墙是拒绝访问的,还有就是logstash或者elasticsearch没有起来造成的。注意你的内存是否足够启动这两个进程。不够就修改jvm.option这个文件
注:如果你的logstash配置在其他云主机,进行分布式收集日志。那么你的其他云主机上的logstash需要修改配置文件中的监听地址为0.0.0.0。还需要在安全组中打开其他云主机上的logstash监听端口9600.此端口9600是和elasticsearch的9200端口进行交互的。
五、阿里云+腾讯云主机实现ES集群
实验环境:
阿里云服务器 公网IP:39.97.176.117
腾讯云服务器 公网IP:106.54.72.122
这个和上面伪分布式唯一的区别,就在elasticsearch配置文件上,其他都一样的,两个云主机都要配置,且需要打开安全组中的9200,9300端口。
阿里云elasticsearch.yml文件配置:
cluster.name: my-application #集群中的所有服务器需一致
node.name: master-node #这个必须不一样
node.master: true #是否是ES集群的主节点
node.data: true #是否是ES集群中的数据节点,不是数据节点一般就会定义为主节点,数据节点是专门存储数据的,但也可以同时为数据和主节点
path.data: /usr/local/elasticsearch/data #数据存储位置,ELK中即为logstash收集的日志数据的存储位置
path.logs: /usr/local/elasticsearch/logs #elasticsearch的日志存储位置
network.host: 0.0.0.0 #监听地址
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["39.97.176.117", "106.54.72.122"]
discovery.zen.minimum_master_nodes: 1 #该属性定义的是为了形成一个集群,有主节点资格并互相连接的节点的最小数目。
腾讯云elasticsearch.yml文件配置:
和阿里云差不多,下面几个参数不一样而已。
node.name: data-node
node.master: false
node.data: true
两个云主机的ES都启动成功后,查看集群状态
curl '39.97.176.117:9200/_cluster/state?pretty'