前端基础(一):前端简介、HTTP协议介绍、HTML常用简单标签
下面是小凰凰的简介,看下吧!
人生态度:珍惜时间,渴望学习,热爱音乐,把握命运,享受生活
学习技能:网络 -> 云计算运维 -> python全栈( 当前正在学习中)
您的点赞、收藏、关注是对博主创作的最大鼓励,在此谢过!
有相关技能问题可以写在下方评论区,我们一起学习,一起进步。
后期会不断更新python全栈学习笔记,秉着质量博文为原则,写好每一篇博文。
文章目录
- 一、前端
- 1、什么是前端
- 2、前端学习历程
- 一、HTML介绍
- 1、Web服务本质
- 2、HTTP协议
- (1)什么是HTTP协议?
- (2)四大特性
- (3)请求数据格式
- (4)响应数据格式
- (5)响应状态码
- (6)请求方式
- 3、HTML是什么?
- 4、HTML注释
- 5、HTML文档结构
- 6、模拟浏览器给socket服务端请求数据
- 二、HTML常用标签
- 1、标签分类
- 2、head常用标签
- (1)Meta标签介绍
- (2) meta标签的http-equiv 属性
- (3) meta标签的name属性
- 3、body常用标签
- (1)特殊字符
- (2)分块标签
- (3)img标签
- (4)a标签
一、前端
1、什么是前端
任何与用户直接打交道的操作界面都可以称之为前端
比如:电脑界面 手机界面 平板界面
什么是后端?
后端类似于幕后操作者(一堆让人头皮发麻的代码)
不直接跟用户打交道
2、前端学习历程
1. HTML:网页的骨架 没有任何的样式
2. CSS:给骨架添加各种样式 变得好看
3. Java Script:控制网页的动态效果
4. 前端框架:BOOTSTRAP、JQuery、Vue
提前给你封装好了很多操作 你只需要按照固定的语法调用即可
一、HTML介绍
1、Web服务本质
浏览器中敲入回车发生了几件事?
1. 浏览器朝服务端发送请求
2. 服务端接收请求
3. 服务端返回相应的请求
4. 浏览器接收响应,根据特定的规则渲染页面展示给用户看
详细过程:
浏览器发请求 -->DNS域名解析(获取目标ip+port)–>TCP三次握手建立连接–>基于 HTTP协议发起get请求 --> 服务端接收并处理请求 --> 服务端返回请求的数据 --> 浏览器得到数据后渲染页面
DNS域名解析流程:先查找浏览器缓存,若没有,再向操作系统的hosts文件查找,若没有,再向本地域名服务器进行递归查找,若没有,再去根服务器迭代查询
2、HTTP协议
(1)什么是HTTP协议?
HTTP协议是超文本传输协议
规定了浏览器与服务端之间消息传输的数据格式
(2)四大特性
1.基于请求响应
2.基于TCP/IP之上的作用于应用层的协议
3.无状态(服务端不保存用户的状态,也就相当于客户端访问之后没有记录)
eg:一个人来了一千次 你都记不住 每次都当他如初见
由于HTTP协议是无状态的 所以后续出现了一些专门用来记录用户状态的技术
cookie、session、token...
4.无连接(请求来一次我响应一次 之后立马断开连接 两者之间就不再有任何关系了)
长链接:双方建立连接之后默认不断开 websocket(后面讲项目的时候会讲)
(3)请求数据格式
1.请求首行(标识HTTP协议版本,当前请求方式)
2.请求头(许多k,v键值对)
3.换行符(/r /n,此处应空着)
4.请求体(携带一些敏感信息,如密码)
(4)响应数据格式
1.响应首行
2.响应头
3.换行符(/r/n,此处应空着)
4.响应体(返回给浏览器页面的数据 通常响应体都是html页面)
(5)响应状态码
用一串简单的数字来表示一些复杂的状态或者提示信息
1XX:服务端已经成功接收了你的数据正在处理 你可以继续提交额外的数据
2XX:服务端成功响应 你想要的数据(请求成功200)
3XX:重定向(当你在访问一个需要登录之后才能访问的页面 你会发现窗口会自动调到登录页面 301 302)
4XX:请求错误(请求资源不存在404,请求不合法不符合内部规定会权限不够403)
5XX:服务器内部错误(500)
(6)请求方式
1.get请求
朝服务端要资源(比如浏览器窗口输入www.baidu.com)
2.post请求
朝服务端提交数据(比如用户登录 提交用户名和密码)
URL:统一资源定位符(也就是网址)
3、HTML是什么?
HTML是一种超文本标记语言,是一种用于创建网页的标记语言
网页能正常显示出来,必须遵循html标记语法,所以浏览器显示出来的页面,内部都是html代码
它不是一种编程语言,HTML使用标签来描述网页
4、HTML注释
注释是代码之母
一般情况下html的注释都会按照下面这个方式来写
5、HTML文档结构
<html>
<head>head>:head内的标签不是给用户看的 而是定义一些配置主要是给浏览器看的
<body>body>:body内的标签 写什么浏览器就渲染什么 用户就能看到什么
html>
最基本的html文档
<html lang="en">
<title>Titletitle>
head>
<body>
body>
html>
声明为HTML文档。
<html>、html> 是文档的开始标记和结束的标记。是HTML页面的根元素,在它们之间是文档的头部(head)和主体(body)。
<head>、head> 定义了HTML文档的开头部分。它们之间的内容不会在浏览器的文档窗口显示。包含了文档的元(meta)数据。
<title>、title> 定义了网页标题,在浏览器标题栏显示。
<body>、body> 之间的文本是可见的网页主体内容。
注意:对于中文网页需要使用 <meta charset="utf-8"> 声明编码,否则会出现乱码。有些浏览器会设置 GBK 为默认编码,则你需要设置为 <meta charset="gbk">
6、模拟浏览器给socket服务端请求数据
# index.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>吴晋丞先生,您好!</h1>
</body>
</html>
import socket
server = socket.socket()
server.bind(('127.0.0.1',8082))
server.listen(5)
while True:
conn,addr = server.accept()
msg = conn.recv(1024)
print(msg)
conn.send(b'HTTP/1.1 200 ok\r\n\r\n') # http的传输数据的格式,相当于报头,这个必须要有,在请求首行里面
with open('index.html','rb') as read_f:
msg = read_f.read()
conn.send(msg)
conn.close()


二、HTML常用标签
1、标签分类
1. 双标签(例如:<h1></h1> <a></a>)
2. 单标签(自闭和标签 例如:<img/>)
3. 块级标签(独占浏览器一行,例如:<div> <p> <h>)
块儿级标签可以修改长宽
块儿级标签内部可以嵌套任意的块级标签
但是p标签虽然是块儿级标签 ,但是他不能够嵌套其他块儿级标签,包括自身
所以:只要是块儿级标签 都可以嵌套行内标签
p标签只能嵌套行内 其他块儿级可以嵌套任意的块儿级标签
4. 行内标签(自身文本多大就占多大,例如:<span> <b> <s> <i> <u>)
# 其中div和span通常都是用来构建网页布局的
2、head常用标签
<title>title>:显示网页标题
-------------------------------------------------------
<style>
h1 {
color: greenyellow;
}
style> 内部用来书写css代码或引用css代码文件
-------------------------------------------------------
<script>
alert(123)
script> 内部用来书写js代码或引用js代码文件
-------------------------------------------------------
<link/>:专门用来引入外部的css文件或网站图标
css文件:<link rel="stylesheet" type="text/css" href="style.css">link>
网站图标:<link rel="shortcut icon" type="images/x-icon" href="http://www.baidu.com/favicon.ico">
(1)Meta标签介绍
<meta>元素可提供有关页面的元信息(meta-information),针对搜索引擎和更新频度的描述和关键词。
<meta>标签位于文档的头部,不包含任何内容。
<meta>提供的信息是用户不可见的。
meta标签的组成:
meta标签共有两个属性,它们分别'http-equiv 属性'和'name 属性',不同的属性又有不同的参数值,这些不同的参数值就实现了不同的网页功能。
(2) meta标签的http-equiv 属性
相当于http的文件头作用,它可以向浏览器传回一些有用的信息,以帮助正确地显示网页内容,与之对应的属性值为content,content中的内容其实就是各个参数的变量值。
<meta http-equiv="content-Type" charset="UTF8">
<meta http-equiv="refresh" content="2;URL=https://www.oldboyedu.com">
<meta http-equiv="x-ua-compatible" content="IE=edge,chrome=1">
(3) meta标签的name属性
主要用于描述网页,与之对应的属性值为content,content中的内容主要是便于搜索引擎机器人查找信息和分类信息用的。
<meta name="keywords" content="meta总结,html meta,meta属性,meta跳转">
# 定义搜索引擎搜索到本网站的关键字
<meta name="description" content="老男孩教育Python学院">
下面图中红框框部分的内容,就是写在description的content中的

3、body常用标签
<b>加粗b>
<i>斜体i>
<u>下划线u>
<s>删除s>
<p>段落标签p>
<h1>标题1h1>
<h2>标题2h2>
<h3>标题3h3>
<h4>标题4h4>
<h5>标题5h5>
<h6>标题6h6>
<br>
<hr>
(1)特殊字符
空格:
>: >
<: <
<=: ≤
>=: ≥
&: &
¥: ¥
版权: ©
注册: ®
注意:上面大家发现,大于、小于、大于等于、小于等于都有相应的特殊表示,但是等于没有,这是为了不与标签符号<>冲突,height = 800px,这个=不就是等于的意思!=号不会冲突!
(2)分块标签
div 块级标签
span 行内标签
p 段落标签
上述的两个标签是在构造页面初期最常使用的, 主要通过CSS样式为其赋予不同的表现。
# 页面的布局一般先用div和span占位之后再去调整样式
尤其是div使用非常的频繁
div你可以把它看成是一块区域 也就意味着用div来提前规定所有的区域,之后往该区域内部填写内容即可
而普通的文本用span标签
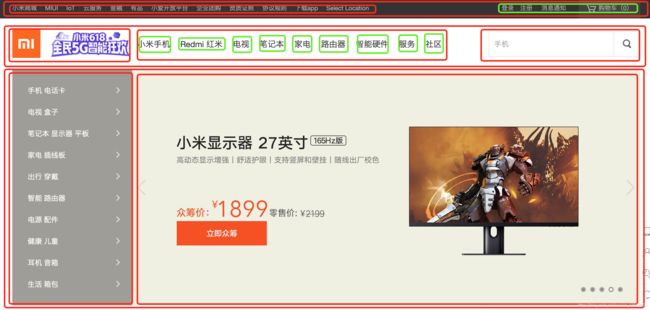 上图是小米的官网,
上图是小米的官网,一个红框框就是一个div标签,一个绿框框就是一个span标签,可能有没画完的,明白就行了!
因此可以得到,关于标签嵌套:
通常,块级元素可以包含内联元素或某些块级元素,但内联元素不能包含块级元素,它只能包含其它内联元素。
'块标签中的有个特例,p标签不能包含块级标签,p标签也不能包含p标签。'
(3)img标签
# 图片标签
<img src="" alt="">
#【属性】
src=" 图片路径"
1.图片的路径 可以是本地的也可以是网上的
2.url:自动朝该url发送get请求获取数据
(什么是URL?URL是统一资源定位器(Uniform Resource Locator)的缩写,也被称为网页地址,是因特网上标准的资源的地址。)
alt="图片描述信息"
当图片加载不出来的时候 给图片的描述性信息
title="鼠标悬浮停留时,自动提示信息"
当鼠标悬浮到图片上之后 自动展示的提示信息
height="800px"
width=""
'高度和宽度当你只修改一个的时候 另外一个参数会等比例缩放'
如果你修改了两个参数 并且没有考虑比例的问题 那么图片就会失真
(4)a标签
超链接标签: 所谓的超链接是指从一个网页指向一个目标的连接关系,这个目标可以是另一个网页,也可以是相同网页上的不同位置,还可以是一个图片,一个电子邮件地址,一个文件,甚至是一个应用程序。
1. 链接标签
<a href=" " target=" " ></a>
"""
当a标签指定的网址从来没有被点击过 那么a标签的字体颜色是蓝色
如果点击过了就会是紫色(浏览器给你记忆了)
"""
2.【属性】
(1) href=" "
1.放url,用户点击就会跳转到该url页面
2.放其他标签的id值 点击即可跳转到对应的标签位置
(2) target=" "
默认a标签是在当前页面完成跳转 target="_self"
新建页面跳转 target="_blank"
# 每一个标签都应该有三个比较重要的属性
1.id值 该值就类似于人的身份证号 在用一个html文档id应该保证唯一不重复
2.class值 该值就类似于面向对象里面的继承 可以写多个
3.style(不是必备) 支持在标签内直接写css代码 属于行内样式 优先级最高,'一般css都不用这个!'
eg:点击一个文本标题 页面自动跳转到标题对应的内容区域
<a href="" id="d1">顶部a>
<h1 id="d111">hello worldh1>
<div style="height: 1000px;background-color: red">div>
<a href="" id="d2">中间a>
<div style="height: 1000px;background-color: greenyellow">div>
<a href="#d1">底部a>
<a href="#d2">回到中间a>
<a href="#d111">回到中间a>
# 标签既可以有默认的属性,也可以有自定义的属性
<p id="d1" class="c1" username="jason" password="123"></p>