使用keras实现CNN模型的THUCNews新闻文本分类
使用keras简单实现了基于CNN模型的THUCNews新闻文本分类,项目是在和鲸社区实现的已经公开,需要的同学可以去fork一下。
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D,BatchNormalization,concatenate,Flatten
from keras.optimizers import RMSprop
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from data_loader.cnews_loader import *
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
Using TensorFlow backend.
/opt/conda/lib/python3.6/site-packages/requests/__init__.py:80: RequestsDependencyWarning: urllib3 (1.25.8) or chardet (3.0.4) doesn't match a supported version!
RequestsDependencyWarning)
time: 4.56 s
本文中所用的数据集清华NLP组提供的THUCNews新闻文本分类数据集的一个子集(原始的数据集大约74万篇文档,训练起来需要花较长的时间)。
本次训练使用了其中的体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐10个分类,每个分类6500条,总共65000条新闻数据。项目在和鲸社区的平台上跑的,数据集直接引用了和鲸的数据集
数据的类别如下:,每个分类6500条,总共65000条新闻数据。
数据集划分如下:
cnews.train.txt: 训练集(50000条)
cnews.val.txt: 验证集(5000条)
cnews.test.txt: 测试集(10000条)
数据预处理
# 设置数据读取、模型、结果保存路径
base_dir = '/home/kesci/input/new3021'
train_dir = os.path.join(base_dir, 'cnews.train.txt')
test_dir = os.path.join(base_dir, 'cnews.test.txt')
val_dir = os.path.join(base_dir, 'cnews.val.txt')
vocab_dir = os.path.join(base_dir, 'cnews.vocab.txt')
save_dir = 'checkpoints/textcnn'
save_path = os.path.join(save_dir, 'best_validation')
time: 831 µs
if not os.path.exists(vocab_dir): # 如果不存在词汇表,重建
build_vocab(train_dir, vocab_dir, config.vocab_size)
time: 1.17 ms
# 创建数据类别映射、文本字典
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_dir)
vocab_size = len(words)
time: 3.5 ms
seq_length = 600 # 序列长度
x_train, y_train = process_file(train_dir, word_to_id, cat_to_id, seq_length)
x_val, y_val = process_file(val_dir, word_to_id, cat_to_id, seq_length)
time: 14.5 s
构建模型
#TextInception
main_input = Input(shape=(600,), dtype='float64')
embedder = Embedding(vocab_size + 1, 256, input_length = 600)
embed = embedder(main_input)
block1 = Convolution1D(128, 1, padding='same')(embed)
conv2_1 = Convolution1D(256, 1, padding='same')(embed)
bn2_1 = BatchNormalization()(conv2_1)
relu2_1 = Activation('relu')(bn2_1)
block2 = Convolution1D(128, 3, padding='same')(relu2_1)
inception = concatenate([block1, block2], axis=-1)
flat = Flatten()(inception)
fc = Dense(128)(flat)
drop = Dropout(0.5)(fc)
bn = BatchNormalization()(drop)
relu = Activation('relu')(bn)
main_output = Dense(10, activation='softmax')(relu)
model = Model(inputs = main_input, outputs = main_output)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
WARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
time: 357 ms
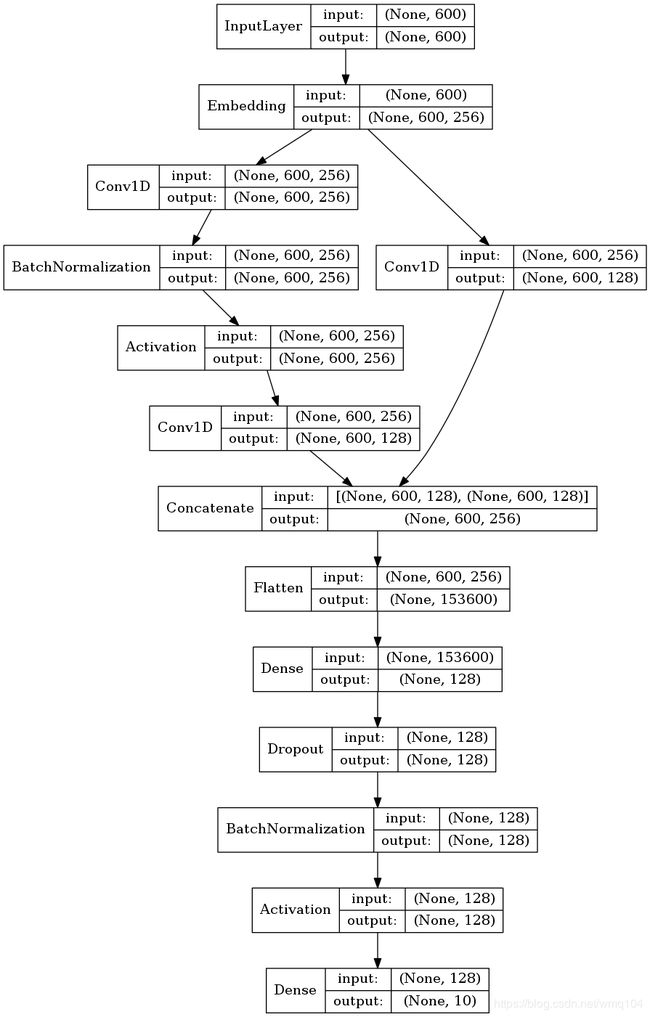
使用model.summary展示模型的结构,可以看到组成模型的层以及每个层的输出数据形状、参数、连接的下一个层。
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 600) 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 600, 256) 1280256 input_1[0][0]
__________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 600, 256) 65792 embedding_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 600, 256) 1024 conv1d_2[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 600, 256) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 600, 128) 32896 embedding_1[0][0]
__________________________________________________________________________________________________
conv1d_3 (Conv1D) (None, 600, 128) 98432 activation_1[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 600, 256) 0 conv1d_1[0][0]
conv1d_3[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 153600) 0 concatenate_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 19660928 flatten_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 128) 0 dense_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 128) 512 dropout_1[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 128) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 10) 1290 activation_2[0][0]
==================================================================================================
Total params: 21,141,130
Trainable params: 21,140,362
Non-trainable params: 768
__________________________________________________________________________________________________
time: 2.08 ms
利用plot_model函数绘制模型结构
from keras.utils import plot_model
from PIL import Image
#生成一个模型图,第一个参数为模型,第二个参数为要生成图片的路径及文件名,还可以指定两个参数:
#show_shapes:指定是否显示输出数据的形状,默认为False
#show_layer_names:指定是否显示层名称,默认为True
plot_model(model,to_file='model.png',show_shapes=True,show_layer_names=False)
#显示模型
display(Image.open('model.png'))
time: 266 ms
模型训练
模型训练非常简单,只需要将训练数据输入fit函数,同时可以设置训练批次大小,训练周期数,如果输入校验数据,训练过程中,每个训练周期的末尾会输出校验结果。函数的返回值是训练过程记录的参数,将其赋值给history可以用来对训练过程损失的变化进行研究。
history = model.fit(x_train, y_train,
batch_size=32,
epochs=3,
validation_data=(x_val, y_val))
WARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Train on 50000 samples, validate on 5001 samples
Epoch 1/3
50000/50000 [==============================] - 2564s 51ms/step - loss: 0.3790 - acc: 0.8894 - val_loss: 0.4955 - val_acc: 0.8600
Epoch 2/3
50000/50000 [==============================] - 2557s 51ms/step - loss: 0.1453 - acc: 0.9585 - val_loss: 0.6658 - val_acc: 0.8352
Epoch 3/3
50000/50000 [==============================] - 2551s 51ms/step - loss: 0.0969 - acc: 0.9707 - val_loss: 0.4320 - val_acc: 0.8860
time: 2h 7min 53s
绘制训练过程参数的变化
# plot accuracy and loss
def plot_acc_loss(history):
plt.subplot(211)
plt.title("Accuracy")
plt.plot(history.history["acc"], color="g", label="Train")
plt.plot(history.history["val_acc"], color="b", label="Test")
plt.legend(loc="best")
plt.subplot(212)
plt.title("Loss")
plt.plot(history.history["loss"], color="g", label="Train")
plt.plot(history.history["val_loss"], color="b", label="Test")
plt.legend(loc="best")
plt.tight_layout()
plt.show()
plot_acc_loss(history)

time: 534 ms
由图可以看到训练过程中,模型在训练集上的精度不断升高、损失不断降低,但是在校验集上第三个epoch校验精度反而有所下降,可能是模型过拟合了?需要进一步研究。
保存模型
## 模型的保存和导入
from keras.models import load_model
# 保存模型
if not os.path.exists(save_dir):
os.makedirs(save_dir)
model.save(os.path.join(save_dir,'my_model.h5'))
del model # deletes the existing model
time: 1.35 s
模型重新加载及预测
# 导入已经训练好的模型
model1 = load_model('my_model.h5')
time: 4.33 s
## 对测试集进行预测
y_pre = model1.predict(x_val)
time: 1min
分析预测结果
使用sklearn库中的metrics函数计算模型不同分类的精度、召回率、f1分值。
metrics.classification_report(np.argmax(y_pre,axis=1),np.argmax(y_val,axis=1), digits=4, output_dict=True)
{'0': {'precision': 0.9760479041916168,
'recall': 0.9939024390243902,
'f1-score': 0.9848942598187312,
'support': 492},
'1': {'precision': 0.994,
'recall': 0.8598615916955017,
'f1-score': 0.922077922077922,
'support': 578},
'2': {'precision': 0.742,
'recall': 0.9946380697050938,
'f1-score': 0.849942726231386,
'support': 373},
'3': {'precision': 0.558,
'recall': 0.9029126213592233,
'f1-score': 0.6897404202719407,
'support': 309},
'4': {'precision': 0.884,
'recall': 0.8170055452865065,
'f1-score': 0.8491834774255523,
'support': 541},
'5': {'precision': 0.964,
'recall': 0.8310344827586207,
'f1-score': 0.8925925925925925,
'support': 580},
'6': {'precision': 0.978,
'recall': 0.7749603803486529,
'f1-score': 0.8647214854111406,
'support': 631},
'7': {'precision': 0.896,
'recall': 0.8801571709233792,
'f1-score': 0.88800792864222,
'support': 509},
'8': {'precision': 0.976,
'recall': 0.8119800332778702,
'f1-score': 0.8864668483197093,
'support': 601},
'9': {'precision': 0.762,
'recall': 0.9844961240310077,
'f1-score': 0.859075535512965,
'support': 387},
'accuracy': 0.8730253949210158,
'macro avg': {'precision': 0.8730047904191617,
'recall': 0.8850948458410247,
'f1-score': 0.868670319630416,
'support': 5001},
'weighted avg': {'precision': 0.8990105116701211,
'recall': 0.8730253949210158,
'f1-score': 0.8773572300716059,
'support': 5001}}
time: 10.2 ms
使用混淆矩阵展示预测结果
## 评价预测效果,计算混淆矩阵
confm = metrics.confusion_matrix(np.argmax(y_pre,axis=1),np.argmax(y_val,axis=1))
time: 5 ms
## 混淆矩阵可视化
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt='d', cbar=False,linewidths=.8,
cmap="YlGnBu")
plt.xlabel('True label',size = 14)
plt.ylabel('Predicted label',size = 14)
plt.xticks(np.arange(10)+0.5,categories,size = 12)
plt.yticks(np.arange(10)+0.3,categories,
size = 12)
# plt.xticks(np.arange(10)+0.5,categories,fontproperties = fonts,size = 12)
# plt.yticks(np.arange(10)+0.3,categories,fontproperties = fonts,size = 12)
plt.show()
print(metrics.classification_report(np.argmax(y_pre,axis=1),np.argmax(y_val,axis=1)))

precision recall f1-score support
0 0.98 0.99 0.98 492
1 0.99 0.86 0.92 578
2 0.74 0.99 0.85 373
3 0.56 0.90 0.69 309
4 0.88 0.82 0.85 541
5 0.96 0.83 0.89 580
6 0.98 0.77 0.86 631
7 0.90 0.88 0.89 509
8 0.98 0.81 0.89 601
9 0.76 0.98 0.86 387
accuracy 0.87 5001
macro avg 0.87 0.89 0.87 5001
weighted avg 0.90 0.87 0.88 5001
time: 799 ms