北京积分落户2018年与2019年分析
本月度的第一天也就是6月1号,北京交通委发布了《北京市小客车数量调控暂行规定(修订草案征求意见稿)》、《〈北京市小客车数量调控暂行规定〉实施细则(修订征求意见稿)》、《关于一次性增发新能源小客车指标配置方案(征求意见稿)》三个文件公开征求意见。
公开征求意见简短成一句话就是:
北京摇号新增“无车家庭”
积分越高,中签机会越大
关于公开意见感兴趣的可以阅读:北京交通委发布最新通知
大多数北漂者,都希望把户口落在北京,北京户口带来的好处这里不加赘述。2018年北京首次公布了积分落户名单,到目前为止已经实行2年了。
这里将利用Python语言对2018年北京积分落户与2019年北京积分落后进行数据分析,希望通过数据分析能对北京落户形式如何,怎样的年龄、怎样的积分值、什么样的工作单位落户成功率较高,希望对想要通过积分落户的朋友形成指导,大概几年能达到积分落户要求,也希望对以后申请积分落户的朋友有些许帮助。
一、北京积分落户名单
北京2018年,2019年积分落户名单来源于官方网站 北京市人力资源和社会保障局
二、Python进行分析
2.1 导入相关的库
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:\Windows\Fonts\STXIHEI.TTF', size=16)2.2 加载数据集
luohu_2018 = pd.read_csv('北京市2018年积分落户公示名单.csv',index_col='序号')
luohu_2018.index.name=None
luohu_2018.head(10)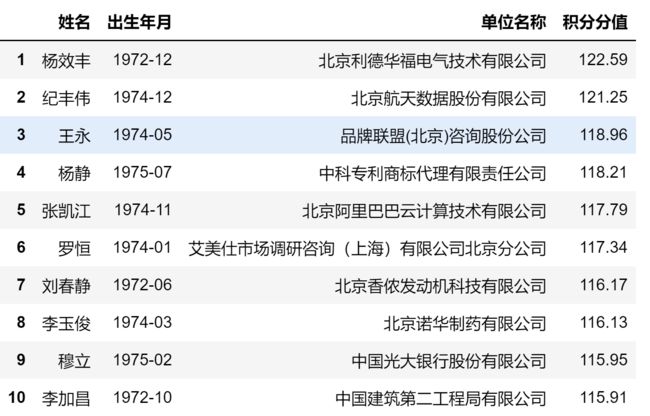
luohu_2019 = pd.read_csv('北京市2019年积分落户公示名单.csv',index_col='序号')
luohu_2019.index.name=None
luohu_2019.head(10)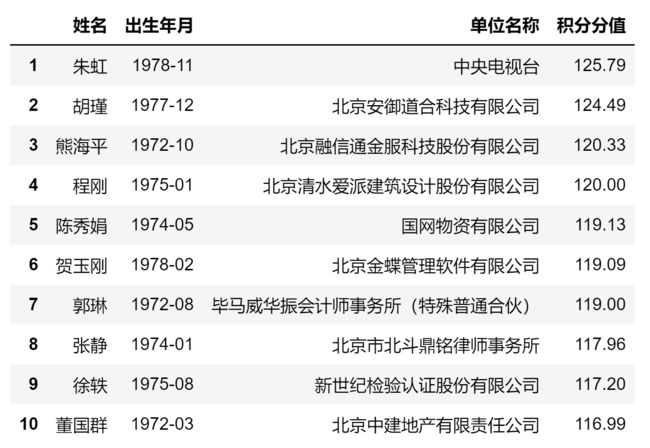
因为数据太多,这里只显示2018年和2019年积分落户名单各20条。
2.3 人数分析
sum_2018 = luohu_2018.shape[0]
sum_2019 = luohu_2019.shape[0]
x= ['2018年','2019年']
y = [sum_2018,sum_2019]
plt.figure(figsize=(8,6),dpi=80)
rects = plt.bar(x,y,color=['r', 'g'],width=0.3)
plt.xticks(x, fontproperties=my_font)
plt.xlabel('年份',fontproperties=my_font)
plt.ylabel('人数',fontproperties=my_font)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height + 1, str(height), ha="center",fontproperties=my_font)
plt.title("2018年,2019年北京积分落户人数对比", fontproperties=my_font)
plt.show()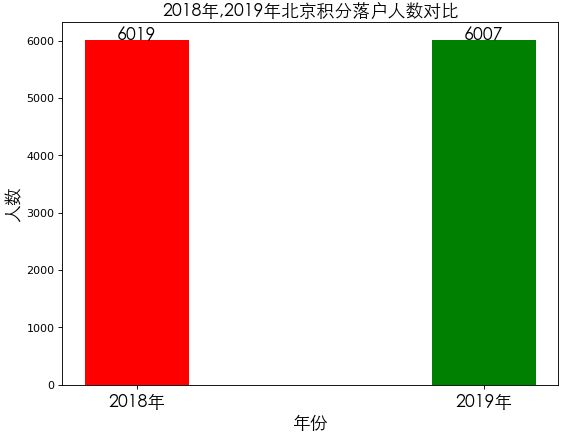
从条形图中,可以得出: 2018年北京积分落户人数有6019人,2019年北京积分落户人数有6007人。2019年比2018年减少了12人。
2.4 最高分与最低分
fraction_2018 = luohu_2018['积分分值']
fraction_2019 = luohu_2019['积分分值']
x = np.arange(2)
max_fraction = [fraction_2018.max(),fraction_2019.max()]
min_fraction = [fraction_2018.min(),fraction_2019.min()]
plt.figure(figsize=(14,7),dpi=80)
plt.bar(x,max_fraction,width=0.2,label='最高分')
plt.bar(x+0.2,min_fraction,width=0.2,color='green',label='最低分')
plt.xticks(x+0.1, ['2018年','2019年'], fontproperties=my_font)
plt.title('2018年,2019年北京积分落户最高(最低)分对比',fontproperties=my_font)
plt.legend(prop=my_font,loc='upper right')
plt.ylabel('积分分值',fontproperties=my_font)
for max_2018,max_2019 in enumerate(max_fraction):
plt.text(max_2018,max_2019+1.2,str(max_2019),ha='center',fontproperties=my_font)
for min_2018,min_2019 in enumerate(min_fraction):
plt.text(min_2018+0.2,min_2019+1.2,str(min_2019),ha='center',fontproperties=my_font)
plt.show()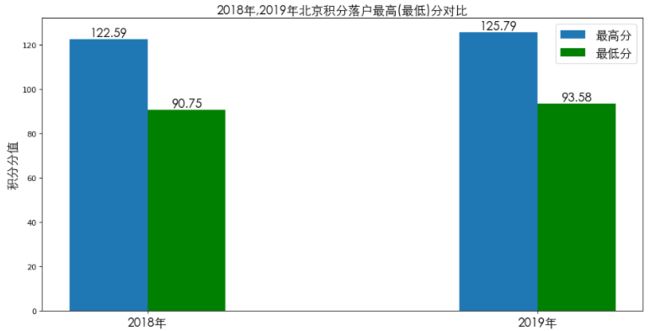
从图中可以得出:2019年北京积分落户的最高分值和最低分值都有所提高,涨幅大致相同。
2.5 申请公司数量
company_2018 = luohu_2018.drop_duplicates(['单位名称'],keep='first',inplace=False)
company_count_2018 = company_2018.shape[0]
company_2019 = luohu_2019.drop_duplicates(['单位名称'],keep='first',inplace=False)
company_count_2019 = company_2019.shape[0]
x= ['2018年','2019年']
y = [company_count_2018,company_count_2019]
plt.figure(figsize=(8,6),dpi=80)
rects = plt.bar(x,y,color=['r', 'g'],width=0.3)
plt.xticks(x, fontproperties=my_font)
plt.xlabel('年份',fontproperties=my_font)
plt.ylabel('公司数量',fontproperties=my_font)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height + 1, str(height), ha="center",fontproperties=my_font)
plt.title("2018年,2019年北京积分落户公司数量对比", fontproperties=my_font)
plt.show()
从条形图中,可以得出: 2018年北京积分落户公司数量有3429个,2019年北京积分落户公司数量有3714个。2019年比2018年增加了285个公司。
2.6 各公司申请人数
company_data_2018 = luohu_2018.groupby(by='单位名称',as_index=False).count()[['单位名称','姓名']]
company_data_2018.rename(columns={"单位名称":"单位名称","姓名":"申请人数"},inplace=True)
company_data_2018.head(20)
company_data_2019 = luohu_2019.groupby(by='单位名称',as_index=False).count()[['单位名称','姓名']]
company_data_2019.rename(columns={"单位名称":"单位名称","姓名":"申请人数"},inplace=True)
company_data_2019.head(20)
因为数据太多,这里只显示2018年和2019年各20条。
2.7 申请人数最多的公司
company_data_2018.sort_values(by='申请人数',ascending=False).iloc[0:20]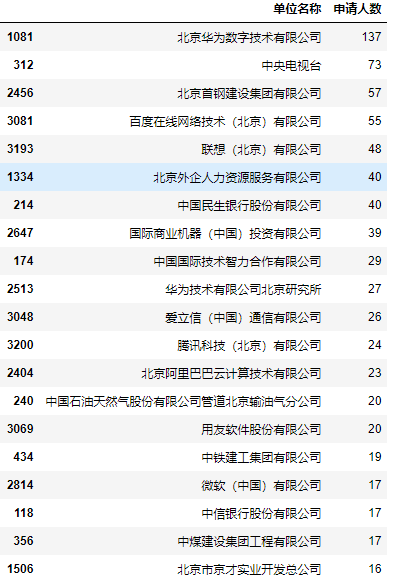
company_data_2019.sort_values(by='申请人数',ascending=False).iloc[0:20]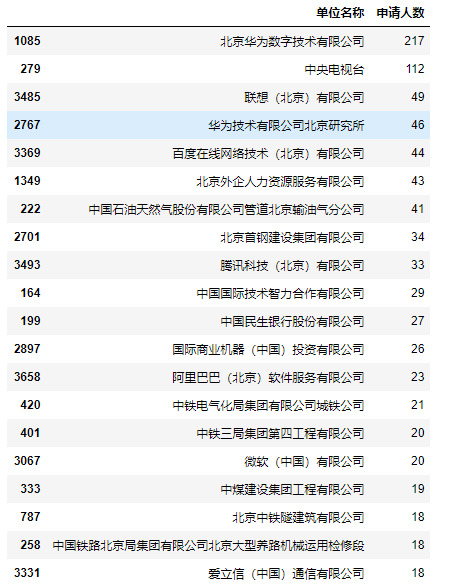
从图中可以得出:无论是2018年还是2019年,申请人数最多的前20家公司里大多数都是非常出名的互联网公司和大型央企。特别是华为连续2年登陆了榜首。
2.8 只有一人申请公司
company_people_one_2018 = company_data_2018[company_data_2018['申请人数']== 1]
company_people_one_2018.head(20)
company_people_one_2019 = company_data_2019[company_data_2019['申请人数']== 1]
company_people_one_2019.head(20)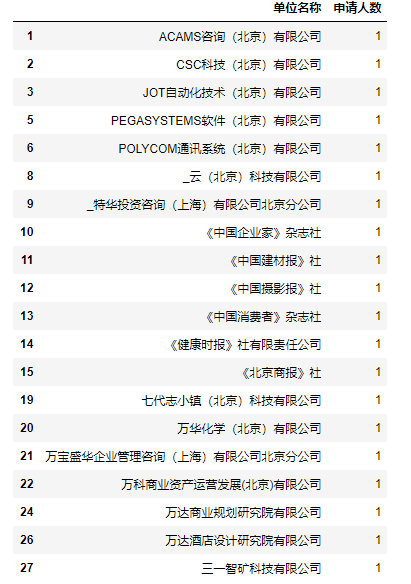
根据显示的图形来看,只有一人申请的公司大多数是不怎么出名的公司而且以报社居多。
我随机去天眼查随机抽查了几家公司。


x= ['2018年','2019年']
y = [company_people_one_2018.shape[0],company_people_one_2019.shape[0]]
plt.figure(figsize=(8,6),dpi=80)
rects = plt.bar(x,y,color=['r', 'g'],width=0.3)
plt.xticks(x, fontproperties=my_font)
plt.xlabel('年份',fontproperties=my_font)
plt.ylabel('公司数量',fontproperties=my_font)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height + 1, str(height), ha="center",fontproperties=my_font)
plt.title("2018年,2019年北京积分落户一人申请公司数量对比", fontproperties=my_font)
plt.show()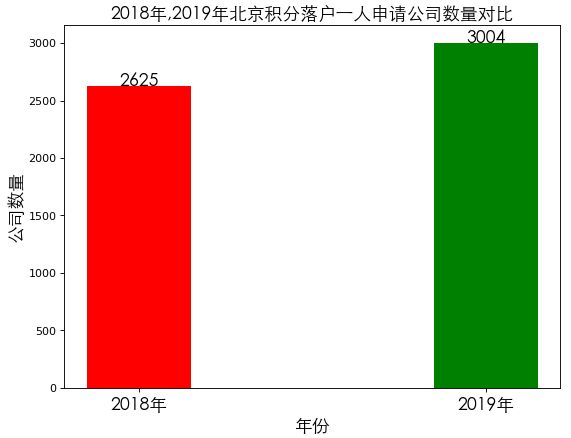
2019年申请一人的公司数量比2018年申请一人的公司数量多了379个。
前面我们得出结论:2019年比2018年增加了285个公司。这379个人大部分很有可能来自新增的285个公司。
2.9 一人申请公司占比情况
one_people_2018_gai = round(company_people_one_2018.shape[0] / company_count_2018,2)
one_people_2019_gai = round(company_people_one_2019.shape[0] / company_count_2019,2)
print("2018年北京积分落户申请公司数量为{},申请一人的公司数量为{},一人申请公司占比{}%".format(company_count_2018,company_people_one_2018.shape[0],one_people_2018_gai*100))
print("2019年北京积分落户申请公司数量为{},申请一人的公司数量为{},一人申请公司占比{}%".format(company_count_2019,company_people_one_2019.shape[0],one_people_2019_gai*100))![]()
2.10 积分分值分布
import seaborn as sns
bin_counts = pd.cut(luohu_2018['积分分值'],bins=np.arange(90,130,5))
score_counts = luohu_2018['积分分值'].groupby(bin_counts).count()
x = [str(x.left)+'~'+str(x.right) for x in score_counts.index]
bar = sns.barplot(x=x,y=score_counts.values)
plt.xlabel('积分分值',fontproperties=my_font)
plt.ylabel('个人数量',fontproperties=my_font)
plt.title('2018年北京积分落户积分值人数分布情况',fontproperties=my_font)
plt.show()
import seaborn as sns
bin_counts = pd.cut(luohu_2019['积分分值'],bins=np.arange(90,130,5))
score_counts = luohu_2019['积分分值'].groupby(bin_counts).count()
x = [str(x.left)+'~'+str(x.right) for x in score_counts.index]
bar = sns.barplot(x=x,y=score_counts.values)
plt.xlabel('积分分值',fontproperties=my_font)
plt.ylabel('个人数量',fontproperties=my_font)
plt.title('2019年北京积分落户积分值人数分布情况',fontproperties=my_font)
plt.show()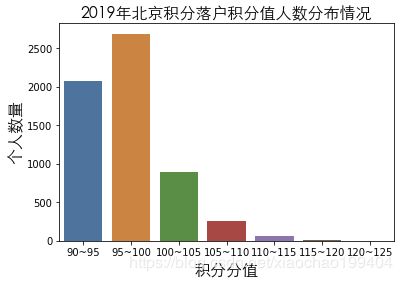
2018年积分落户的主要分值分布在90~95分,其次95~100分。
2019年积分落户的主要分值分布在95~100分,其次是90~95分。
2019年90~95分之间人数下降厉害,95分~100分之间人数上涨较多,100分~105分,105分~110分之间的人数也上涨了点。
2.11 年龄分布
import time
now_time = time.strftime('%Y-%m',time.localtime(time.time()))
now_time = pd.to_datetime(now_time)
luohu_2019['年龄'] = (now_time - pd.to_datetime(luohu_2019['出生年月'])) / pd.Timedelta('365 days')
luohu_2018['年龄'] = (now_time - pd.to_datetime(luohu_2018['出生年月'])) / pd.Timedelta('365 days')bins_count = pd.cut(luohu_2019['年龄'],bins=np.arange(30,70,5))
age_count = luohu_2019['年龄'].groupby(bins_count).count()
x = [str(i.left)+'~'+str(i.right) for i in age_count.index]
sns.barplot(x,age_count.values)
plt.xlabel("年龄段分布",fontproperties=my_font)
plt.ylabel('个人数量',fontproperties=my_font)
plt.title('2019年北京积分落户年龄段人数分布情况',fontproperties=my_font)
plt.show()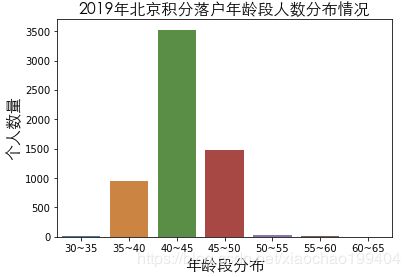
bins_count = pd.cut(luohu_2018['年龄'],bins=np.arange(30,70,5))
age_count = luohu_2018['年龄'].groupby(bins_count).count()
x = [str(i.left)+'~'+str(i.right) for i in age_count.index]
sns.barplot(x,age_count.values)
plt.xlabel("年龄段分布",fontproperties=my_font)
plt.ylabel('个人数量',fontproperties=my_font)
plt.title('2018年北京积分落户年龄段人数分布情况',fontproperties=my_font)
plt.show()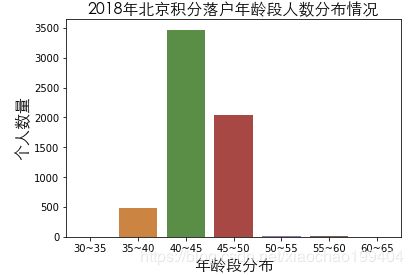
2018年与2019年积分落户年龄段分布没有多大变化,40岁~45岁仍然是北京积分落户的主力,其次是45岁~50岁。
三、北京积分落户政策
从网上找了一些北京积分落户的政策,希望对有需要的朋友有所帮助。
3.1 资格条件
- 持有北京市居住证
- 不超过法定退休年龄
- 在京连续缴纳社会保险7年及以上
- 无刑事犯罪记录
3.2 九项积分指标
合法稳定就业指标 |
|
| 每连续缴纳社保满一年 | +3 |
合法稳定住所指标 |
|
| 在自有产权住所每连续居住累计满1年 | +1 |
| 在合法租赁住所和单位宿舍每连续居住累计满1年 | +1 |
教育背景指标 |
|
| 大学专科(含高职) | +10.5 |
| 大学本科学历并取得学士学位 | +15 |
| 研究生学历并取得硕士学位 | +26 |
| 研究生学历并取得博士学位 | +37 |
职住区域指标 |
|
| 居住地从城六区转移到其他行政区域的,每满1年 | +2,最高6 |
| 就业地和居住地均从城六区转移到本市其他行政区域的,每满1年 | +4,最高12 |
创新创业指标 |
|
| 获得国家级奖项的 | 最高+12 |
| 获北京市市级奖项的 | 最高+6 |
纳税指标 |
|
| 近3年连续个税平均每年在10万元及以上,或是企业投资人、股东或出资人,以其出资比例计算企业纳税额,平均每年纳税20万元及以上 | +6 |
年龄指标 |
|
| 年龄不得超过45周岁的 | +20 |
荣誉表彰指标 |
|
| 获得首都见义勇为好市民、首都道德模范、省部级以上劳动模范、全国道德模范、全国见义勇为英雄模范等荣誉表彰之一的 | +20 |