deepCNN--“卷积神经网络用于基于图像检索”文章阅读
图像检索:http://www.zhihu.com/question/19726630知乎的一个通俗解释
http://baike.baidu.com/view/5529743.htm?fr=aladdin#1百度的一个解释
基础知识:C1,C2层介绍
C1:response normalization layers
C2: a max pooling layers
http://www.cnblogs.com/tornadomeet/archive/2013/05/05/3061457.html
C3,C4,C5卷积层
几篇挺好的blog
http://blog.csdn.net/zouxy09/article/details/8781543
http://www.360doc.com/content/13/1123/02/9482_331447040.shtml
http://www.colabug.com/thread-1123059-1-1.html
Krizhevsky 2012年文章
Imagenet classification with deep convolutional neural networks.
http://www.docin.com/p-657388714.html
入门介绍文章
http://blog.csdn.net/zouxy09/article/details/8781543
文章中提到的八层神经网络:
输入:inuput RGB value of impixl(像素)
卷积层有五层:第一、第二层卷积层后均加上max pooling、responded normalization来进行下采样与正则化或者是归一化,不晓得这个怎么翻译的。max pooling生成高层特征,减少特征,把特征分到pooling中,正则化用于抑制过拟合over filtting。在这之前,卷积层后,神经元使用激励函数ReLU,文中使用的这个激励函数比sogiment好在,可以防止梯度消失,八层算是比较多的,会造成梯度消失,严重影响训练结果。ReLU在Lrizhevsky有很好的表述,是一种非线性映射,训练时间也要短。
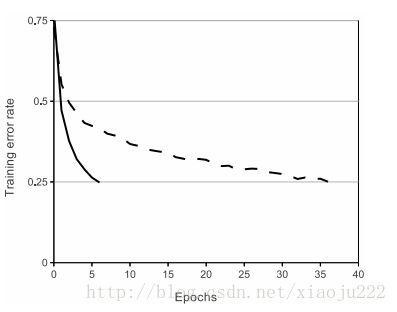
Local Response Normalization的公式如下
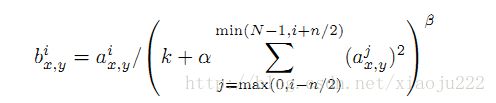
Denoting by aix;y the activity of a neuron computed by applying kernel i at position(x; y) and then applying the ReLU nonlinearity, the response-normalized activity bix;y is given by the expression。
第三、四卷积层后不使用pooling与normalization,第五层输出max pooling。第6,7,8是全连接层,在这篇文章中的意义没有深究。

回到原来的文章,这篇文章是用八层卷积神经网络在图像检索上的应用。用于消除‘长期存在的一个问题’-语意鸿沟的问题‘,语意鸿沟:计算机检测的跟底层视觉特征相似,视觉相似;人识别:描述对象或事件的语意理解上,图像相似性判别,语意相似,所以人眼识别和计算机识别之间有个距离成为语意鸿沟。所以本文把卷积神经网络用在CBIR(基于文本的图像检索)中
the framework of deep learning for CBIR,对于deep learning学习出来的特征用距离函数来计算代替引文中的分类识别。
神经网络的输出为特征,然后要选取方法对特征进行表达,以适用于新的图像检索中来。
1)后三层全连接神经网络层 输出的 direct feature (FC1, FC2, and FC3 )as the feature representations。
本文定义这三个特征向量为“DF.FC1”, “DF.FC2”。DF.FC3 is the feature taken from the final output layer, DF.FC2 is the features taken from the final hidden layer, and DF.FC1 is the activations of the layer before DF.FC2.这些特征也可以用于输入分类如SVM,进行分类识别。应用范围:the retrieval domain is similar to the original dataset for training the CNN model.
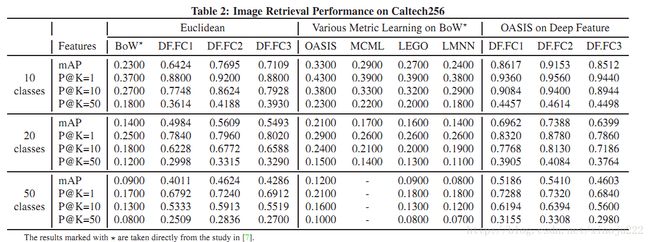
检测类型:
检测效果:

2)Refining by Similarity Learning。imilarity learning (SL) algorithms
OASIS算法:learns a bilinear similarity measure over sparse representations
这个算法是2010年提出的,参考 Large scale online learning of image similarity through ranking. Journal of Machine Learning Research
双线性相似测量对于稀疏表达
在三个约束下,定义X集合为:其中S包含相关部分,D包含不相关部分。
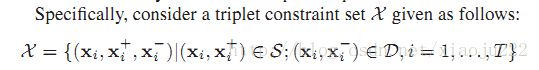
两个样本的相似度函数用双线性形式:
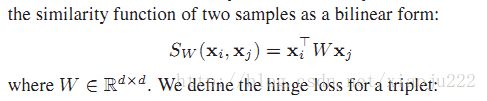
定义三种限制下的损失函数为:
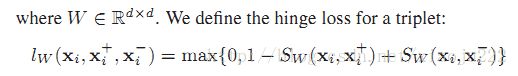
总的损失为;

关于OASIS算法见上面的文章里的

其中的权重矩阵与算法思想参考经典的PA算法

OASIS到此结束,我们定义第二种特征表达“DF.FC1+SL”,“DF.FC2+SL”, and “DF.FC3+SL”,用于地标图像的检测

检测效果
第三种特征表述:适用于检测未知的新样本
有两种方法:Refining with class labels.Refining with side information
“ReDSL.FC1”, “ReDSL.FC2”, and“ReDSL.FC3”,表达第二种方法
http://dl.acm.org/citation.cfm?id=2502112
这种方法主要用于人脸检测,

检测效果:
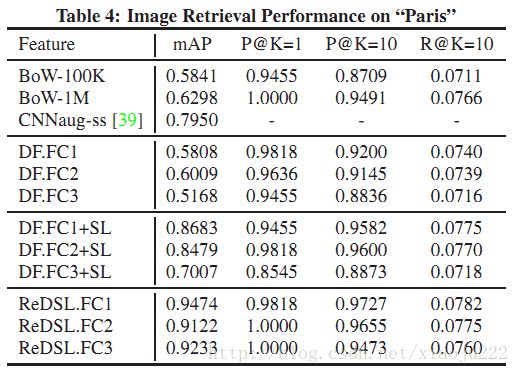
第三种参见文献