Python爬虫实战--爬取网络小说并存放至txt文件
目录
前言
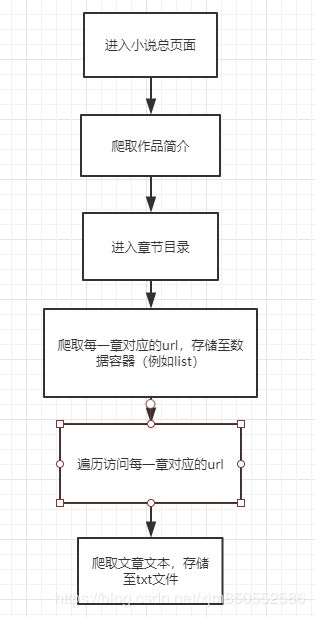
小说爬虫基本流程图
一.网站类型(1)
二.网站类型(2)
前言
本教程再次更新,希望做成一个完整系列。
读者阅读完毕便可以基本掌握爬取网络小说的步骤与方法。
实践出真知,真正的学会是使用教程中的方法去爬取一个全新的网站。
【在学习的过程中千万不要先完整的学习第三方扩展包教程,例如我先把beautifulsoup教程里的所有函数操作都熟练背诵下来。这样只会浪费你的时间,因为你一段时间不使用便会忘掉。我的建议是你可以大概浏览一下每个库里的常用函数,知道每个库都可以用来做什么,然后真正实战时再进行查阅即可~】
最后,希望大家可以学会爬虫,热爱爬虫。
如果您感到有所收获,希望给我点赞,或者评论区留言,谢谢!
小说爬虫基本流程图
一.网站类型(1)
从乐文小说网站上爬取小说相见欢,并存放至txt文件中
URL: 相见欢
(一)介绍
该类网站为静态网站。
特点:(1)章节目录直接加载所有章节内容【如下图所示】
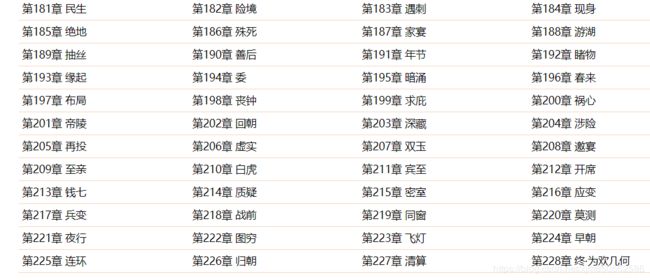
(2)章节链接暴露在html中(非动态js加载)

(3)章节内容静态加载(如下图所示)

爬取教程
一、库文件
re
sys
BeautifulSoup
urllib.request
time
二、实战
(2)Beautifu Soup库的简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
-
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
-
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
-
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
详细请戳这里:Beautiful Soup 4.2.0文档
(3)实战进行中……
【重要】:python想要使用汉字,需要在脚本最前面添加 #coding:utf-8,汉字使用的编码为utf-8,否则会出现错误)
首先,我们引入我们需要的库文件
#coding:utf-8
import re
import sys
from bs4 import BeautifulSoup
import urllib.request
import time
接下来,我们进行爬虫伪装(伪装报头)
(该网站没有反爬虫机制,可以选择跳过)
headers = ('User-Agent', 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1')
opener = urllib.request.build_opener()
opener.addheaders = {headers}
urllib.request.install_opener(opener)
我们从爬取单章开始,首先我们进入第一张的网址相见欢-第一章
url = "http://www.lewendu8.com/books/21/21335/6381842.html"
file = urllib.request.urlopen(url)
data = BeautifulSoup(file , from_encoding="utf8")
data = BeautifulSoup(file , from_encoding="utf8")
from_encoding="utf8"
我们需要将内容进行转码,否则中文将会以乱码形式出现
我们首先获取这章的名称
section_name = data.title.string
print(section_name)
运行结果:
![]()
section_name = data.title.string

我们利用这句话获取文章的章名(我认为比较简便的一种方法)
接下来我们需要获取这章的内容!!(不然看什么小说呢?)
我们按F12进入开发者功能,找出存放内容的标签
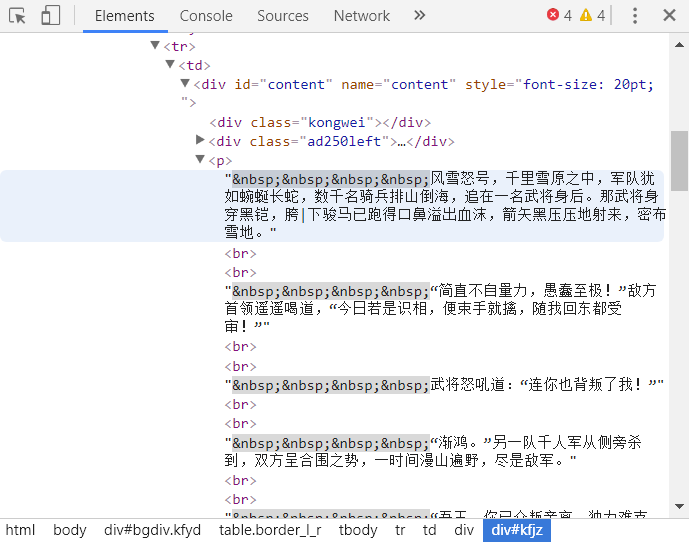
按照父子顺序细细划分
![]()
![]()
![]()
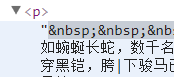
于是,我们寻找到了存放内容的标签
用下述语句将内容存放至section_text中
section_text = data.select('#bgdiv .border_l_r #content p')[0].text
按照指定格式替换章节内容,运用正则表达式
section_text=re.sub( '\s+', '\r\n\t', section_text).strip('\r\n')
运行结果

至此,我们单章爬取任务完成
接下来我们任务当然是获取整本小说的内容了!
首先我们来比较一下每一章的网址
第一章:http://www.lewendu8.com/books/21/21335/6381842.html
第二章:http://www.lewendu8.com/books/21/21335/6381843.html
……
因此URL的构成:http://www.lewendu8.com/books/21/21335/章节序号.html
我们观察网页源代码可以发现:

其中next_page = "6381843.html"便是下一章的章节序号
因此我们在每个网页访问结束时,便可以进行访问下一章的网址
这里我们使用正则匹配获取下一章的章节序号
pt_nexturl = 'var next_page = "(.*?)"'
nexturl_num = re.compile(pt_nexturl).findall(str(data))
nexturl_num = nexturl_num[0]
当我们访问到相见欢最后一章时

当访问到最后一章时,我们的小说已经全部爬取结束
此时正则匹配到的信息为:"http://www.lewendu8.com/books/21/21335/"
于是我们可以通过这个判断我们是否爬取结束
if(nexturl == 'http://www.lewendu8.com/books/21/21335/'):
break
当我们爬取到了内容当然要进行文件读写进行存放
fp = open('相见欢.txt','a')
section_text = section_text
fp.write(section_name+"\n")
fp.write(section_text+"\n")
至此,本次爬取结束~您就可以将txt文件存放到手机上,看小说喽~
三、完整代码
#coding:utf-8
#author:Ericam_
import re
import sys
from bs4 import BeautifulSoup
import urllib.request
import time
headers = ('User-Agent', 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1')
opener = urllib.request.build_opener()
opener.addheaders = {headers}
urllib.request.install_opener(opener)
def get_download(url):
file = urllib.request.urlopen(url)
data = BeautifulSoup(file , from_encoding="utf8")
section_name = data.title.string
section_text = data.select('#bgdiv .border_l_r #content p')[0].text
section_text=re.sub( '\s+', '\r\n\t', section_text).strip('\r\n')
fp = open('2.txt','a')
fp.write(section_name+"\n")
fp.write(section_text+"\n")
fp.close()
pt_nexturl = 'var next_page = "(.*?)"'
nexturl_num = re.compile(pt_nexturl).findall(str(data))
nexturl_num = nexturl_num[0]
return nexturl_num
if __name__ == '__main__':
url = "http://www.lewendu8.com/books/21/21335/6381842.html"
num = 228
index = 1
get_download(url)
while(True):
nexturl = get_download(url)
index += 1
sys.stdout.write("已下载:%.3f%%" % float(index/num*100) + '\n')
sys.stdout.flush()
url = "http://www.lewendu8.com/books/21/21335/"+nexturl
if(nexturl == 'http://www.lewendu8.com/books/21/21335/'):
break
print(time.clock())
二.网站类型(2)
URL:我们纯真的青春
特点:(1)章节目录页未加载全部章节

(2)(翻页时)章节目录通过ajax加载。
简而言之就是,你翻页后,对应的url依然是
![]()
(3)其他特点如同网站类型1
爬取教程
【主要讲解如何获取所有章节对应的url】
1.首先打开浏览器的开发者工具(F12),点击如下按钮
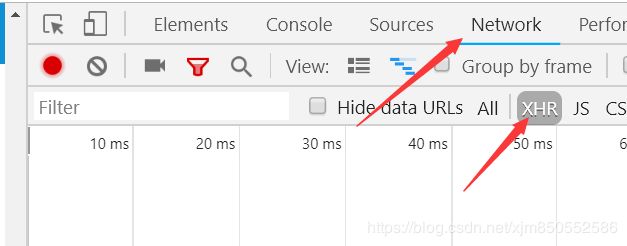
2.然后保持这个页面格局不要关闭,点击“下一页”按钮
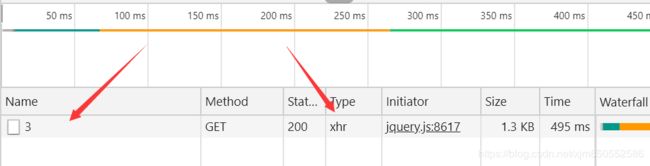
3.此时你会发现捕捉到了一条信息,点击加载详细内容
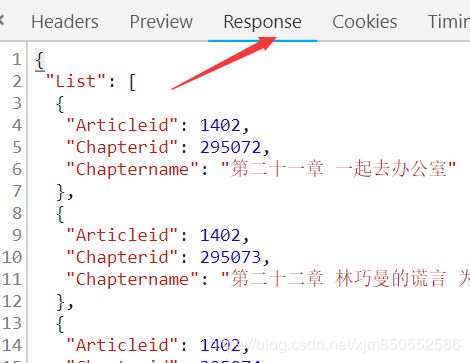
4.你会发现,该网站是通过该方式加载章节目录信息的【我们的方向没有错】
5.获取ajax请求的网址,抓取章节信息
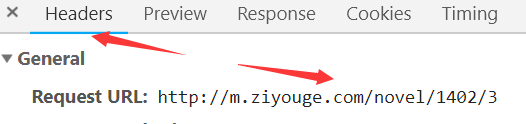
6.我们发现访问第三页,便是在原来的网址后添加了 /3
打开该url,如图所示

其中chapterid便是我们需要抓取的内容。
补充说明:你可以随便点击一个章节链接,会发现其原始url后会添加一个数字。【便是该id】
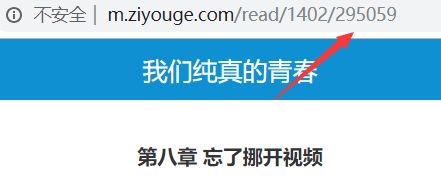
7.因为该页面的信息为纯文本,因此选择使用正则表达式进行抓取。
8.剩余的操作如同(网站类型1的教程)
完整源码
from urllib.request import urlopen
from requests.exceptions import RequestException
import re
from requests import get
from lxml import etree
urlfirst ="http://m.ziyouge.com/novel/1402/"
k=""
index = 1
for i in range(1,67):
print(i)
url = urlfirst + str(i)
try:
response = get(url)
if(response.status_code == 200):
text = response.text
except RequestException as e:
print(e)
pattern = "\"Chapterid\"\: ([\d]+)"
result = re.findall(pattern,text)
for id in result:
chapter = "http://m.ziyouge.com/read/1402/"+str(id)
try:
response = get(chapter)
html = etree.HTML(response.text)
result = html.xpath(".//article/text()")
for r in result:
k += r
except RequestException as e:
print(e)
with open("我们纯真的青春.txt","w+",encoding="utf8")as f:
f.write(k)