这个系列已经拖更好久了, 今天就来第二讲吧, 这里声明一下, 没有特殊说明的情况下, 我们这个系列用的都是伪代码, 这样可以减少大家的学习成本, 任何语言都不影响学习算法
概念
- 时间复杂度: 执行算法所需要的计算工作量
- 空间复杂度: 执行算法所需要的内存空间
一般情况下, 尤其是算法面试中, 我们更侧重于考虑时间复杂度, 所以我们今天的重点是讨论时间复杂度
从一个简单的问题开始
从数组中查找一个数
这里我们考虑最差的情况, 我们要查的这个数在数组的最后一个位置上, 我们假设每查找数组中的一个数需要1ms
- 数组长度为10的时候, 我们需要10ms能得到这个数
- 数组长度为10000的时候, 我们需要10000ms能得到这个数
- 数组长度为1000000的时候, 我们需要100000ms能得到这个数
从上面的例子我们可以看出, 我们得到这个数所需要的事件取决于这个数组的长度, 或者取决于我们操作数组查询的次数, 我们假设数组的长度为n, 那么我们得到想要的数需要的时间就是n,抛开具体的单位和数组长度, 抽象出来的这个n就是我们的时间复杂度
什么是时间复杂度
- 在计算机科学中, 算法的时间复杂度是一个函数, 他定量描述了该算法的运行时间
- 以算法输入值规模n为自变量的函数:
T(n) = O(f(n))
上面这两个定义我估计可能大家也看不懂, 当然能看懂最好, 看不懂倒也没太大影响, 一般情况下我们表示函数的边界有下面三个符号:

-
big O表示函数的上界 -
big Ω表示函数的下界 -
big θ表示函数的确界
通常我们描述的时间复杂度就是big O
big O(这个是字母O, 不是数字0) 的例子
假设我们有以下时间复杂度
- 当n=1, 4n2比2n项大2倍
- 当n=500时, 4n2比2n大1000倍
- 随着n的增大, 4n2会远远大于2n, 2n对于表达式值得影响可以忽略不计
所以我们得到big O的方法就是去除低阶项, 保留高阶项目, 并忽略系数
这个复杂度的高阶项是4n2, 所以2n+1就被去除了, 并且要忽略系数, 所以4也就不需要了
最终这个时间复杂度就剩下了n2, 因此我们有以下结论:
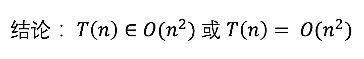
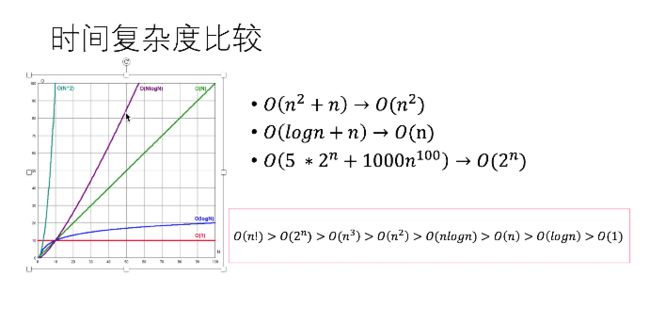
下面给出各种常用时间复杂度的比较
最好情况, 最坏情况, 期望情况
还是用上面数组中查找一个数的例子
- 最好情况: 目标值是数组第一个元素, T(n)=O(1)
- 最坏情况: 目标值是数组最后一个元素: T(n)=O(n)
- 期望情况(平均情况): T(n) = O(n)
一般情况下, 最好情况对于我们研究算法复杂度没有实际意义, 一般我们只讨论最坏情况和期望情况, 大部分情况下这两中情况复杂度是一样的, 但是也有部分特殊情况, 比如快排这两种情况下的复杂度就不相同
一般问题的时间复杂度计算
我们一般分三个部分考虑:
- 基本操作的时间复杂度
- 丢弃常数项
- 丢弃次要项
- 基本操作被执行了多少次(for/while循环)
- 复合操作: 加还是乘
丢弃常数项的情况
下面有两组代码:
int min = Integer.MAX_VALUE;
int nax = Integer.MIN_VALUE;
for(int num : array) {
if(num < min) min = num;
if(num > min) max = num;
}
int min = Integer.MAX_VALUE;
int nax = Integer.MIN_VALUE;
for(int num : array) {
if(num < min) min = num;
}
for(int num : array) {
if(num > min) max = num;
}
第一组代码, for循环的时间复杂度O(n), 进行了一次所以时间复杂度是O(n)
第二组代码, 进行了量词循环所以时间复杂度是O(2n),我们说过算复杂度的时候要忽略系数, 所以时间复杂度也是O(n)
丢弃次要项的情况
O(5 * 2n + 1000 * n2)
从上面时间复杂度比较的图我们知道, 2^n 比 n^2 高阶, 所以去掉n^2, 所以时间复杂度是O(2n)
复合操作: 加还是乘
假设我们算法有两步, 每一个的时间复杂度分别为O(A)和O(B)
for(int a : arrA) {
print(a)
}
for (int b: arrB) {
print(b)
}
上面的代码, 我们分别遍历一次A数组和B数组, 遍历A数组的时间复杂度为O(A), 遍历B数组的时间复杂度为O(B)
这种情况下时间复杂度就是O(A+B)
for(int a: arrA) {
for(int b: arrB) {
print(b)
}
print(a)
}
上面的代码, 我每进入一次数组A循环, 就要整个遍历一遍B数组, 所以这种情况下时间复杂度是O(A*B)
我们来一个例子, 看大家到底有没有理解一般情况的时间复杂度的计算
for(i=0; i我们来用最笨的办法来分析:
这道题我们每进入一次i循环, j循环的总数就少一次, 什么意思呢假设n=5,
第一次进入i循环
j = 1, 所以打印四次a
第二次进入自循环
j = 2, 所以打印三次a
以此类推, 第三次打印两次a
第四次打印一次a
所以我们总共进行了4+3+2+1次操作,假设我们n为不确定的数, 那么我们操作的总数就是(n-1)+(n-2)+(n-3)+...+3+2+1
细心的同学肯定发现了这是一个等差数列, 所以这个时间复杂度就是O(n*(n-1)/2), 根据我们上面学习的只要高阶项, 不要低阶项, 忽略系数, 所以化简后的时间复杂度是O(n2)
递归问题的时间复杂度计算
递归: 在函数的定义中使用函数自身
function cal(n) {
if(n <= 0) {
return 1
}
return cal(n - 1) + cal(n - 1)
}
我们把上面这个递归代码进行分解
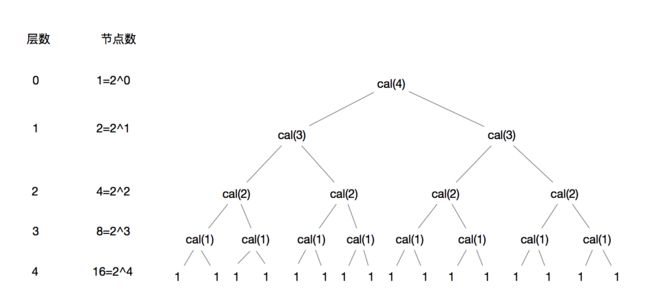
由图可知, 我们总操作数为20+21+22+23+24次, 我们依然假设n为不确定数
所以我们的总操作数为20+21+22+23+24+...+2n-1+2n
细心的同学会发现这是一个等比数列, 根据等比数列求和公式可以得到时间复杂度为O(2n)
经验性结论:
递归问题的时间复杂度通常(并不总是)看起来形如O(branchesdepth)
其中branches指递归分支的总数, depth指递归调用深度
时间复杂度计算 - 主定理
从数学的角度来说, 所有的复杂度我们都可以化成以下格式

我们以二分搜索为例

空间复杂度
- 时间复杂度不是衡量算法的唯一指标, 有时候还需要考虑空间复杂度
- 创建长度为n的数组, 需要O(n)的空间, 创建n*n的二维数组, 需要O(n2)的空间
- 一般情况下我们更侧重于考虑时间复杂度, 甚至有时候需要用空间换时间
关于算法复杂度就说这么多了, 下次我们讨论一个最常见的数据类型, 数组