单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
此文是根据杨尚刚在【QCON高可用架构群】中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处。
杨尚刚,美图公司数据库高级DBA,负责美图后端数据存储平台建设和架构设计。前新浪高级数据库工程师,负责新浪微博核心数据库架构改造优化,以及数据库相关的服务器存储选型设计。
前言
MySQL数据库大家应该都很熟悉,而且随着前几年的阿里的去IOE,MySQL逐渐引起更多人的重视。
MySQL历史
1979年,Monty Widenius写了最初的版本,96年发布1.0
1995-2000年,MySQL AB成立,引入BDB
2000年4月,集成MyISAM和replication
2001年,Heikki Tuuri向MySQL建议集成InnoDB
2003发布5.0,提供了视图、存储过程等功能
2008年,MySQL AB被Sun收购,09年推出5.1
2009年4月,Oracle收购Sun,2010年12月推出5.5
2013年2月推出5.6 GA,5.7开发中
MySQL的优点
使用简单
开源免费
扩展性“好”,在一定阶段扩展性好
社区活跃
性能可以满足互联网存储和性能需求,离不开硬件支持
上面这几个因素也是大多数公司选择考虑MySQL的原因。不过MySQL本身存在的问题和限制也很多,有些问题点也经常被其他数据库吐槽或鄙视
MySQL存在的问题
优化器对复杂SQL支持不好
对SQL标准支持不好
大规模集群方案不成熟,主要指中间件
ID生成器,全局自增ID
异步逻辑复制,数据安全性问题
Online DDL
HA方案不完善
备份和恢复方案还是比较复杂,需要依赖外部组件
展现给用户信息过少,排查问题困难
众多分支,让人难以选择
看到了刚才讲的MySQL的优势和劣势,可以看到MySQL面临的问题还是远大于它的优势的,很多问题也是我们实际需要在运维中优化解决的,这也是MySQL DBA的一方面价值所在。并且MySQL的不断发展也离不开社区支持,比如Google最早提交的半同步patch,后来也合并到官方主线。Facebook Twitter等也都开源了内部使用MySQL分支版本,包含了他们内部使用的patch和特性。
数据库开发规范
数据库开发规范定义:开发规范是针对内部开发的一系列建议或规则, 由DBA制定(如果有DBA的话)。
开发规范本身也包含几部分:基本命名和约束规范,字段设计规范,索引规范,使用规范。
规范存在意义
保证线上数据库schema规范
减少出问题概率
方便自动化管理
规范需要长期坚持,对开发和DBA是一个双赢的事情
想想没有开发规范,有的开发写出各种全表扫描的SQL语句或者各种奇葩SQL语句,我们之前就看过开发写的SQL 可以打印出好几页纸。这种造成业务本身不稳定,也会让DBA天天忙于各种救火。
基本命名和约束规范
表字符集选择UTF8 ,如果需要存储emoj表情,需要使用UTF8mb4(MySQL 5.5.3以后支持)
存储引擎使用InnoDB
变长字符串尽量使用varchar varbinary
不在数据库中存储图片、文件等
单表数据量控制在1亿以下
库名、表名、字段名不使用保留字
库名、表名、字段名、索引名使用小写字母,以下划线分割 ,需要见名知意
库表名不要设计过长,尽可能用最少的字符表达出表的用途
字段规范
所有字段均定义为NOT NULL ,除非你真的想存Null
字段类型在满足需求条件下越小越好,使用UNSIGNED存储非负整数 ,实际使用时候存储负数场景不多
使用TIMESTAMP存储时间
使用varchar存储变长字符串 ,当然要注意varchar(M)里的M指的是字符数不是字节数;使用UNSIGNED INT存储IPv4 地址而不是CHAR(15) ,这种方式只能存储IPv4,存储不了IPv6
使用DECIMAL存储精确浮点数,用float有的时候会有问题
少用blob text
关于为什么定义不使用Null的原因
1、浪费存储空间,因为InnoDB需要有额外一个字节存储
2、表内默认值Null过多会影响优化器选择执行计划
关于使用datatime和timestamp,现在在5.6.4之后又有了变化,使用二者存储在存储空间上大差距越来越小 ,并且本身datatime存储范围就比timestamp大很多,timestamp只能存储到2038年。
索引规范
单个索引字段数不超过5,单表索引数量不超过5,索引设计遵循B+ Tree索引最左前缀匹配原则
选择区分度高的列作为索引
建立的索引能覆盖80%主要的查询,不求全,解决问题的主要矛盾
DML和order by和group by字段要建立合适的索引
避免索引的隐式转换
避免冗余索引
关于索引规范,一定要记住索引这个东西是一把双刃剑,在加速读的同时也引入了很多额外的写入和锁,降低写入能力,这也是为什么要控制索引数原因。之前看到过不少人给表里每个字段都建了索引,其实对查询可能起不到什么作用。
冗余索引例子
idx_abc(a,b,c)
idx_a(a) 冗余
idx_ab(a,b) 冗余
隐式转换例子
字段:remark varchar(50) NOT Null
MySQL>SELECT id, gift_code FROM gift WHERE deal_id = 640 AND remark=115127; 1 row in set (0.14 sec)
MySQL>SELECT id, gift_code FROM pool_gift WHEREdeal_id = 640 AND remark=‘115127’; 1 row in set (0.005 sec)
字段定义为varchar,但传入的值是个int,就会导致全表扫描,要求程序端要做好类型检查
SQL类规范
尽量不使用存储过程、触发器、函数等
避免使用大表的JOIN,MySQL优化器对join优化策略过于简单
避免在数据库中进行数学运算和其他大量计算任务
SQL合并,主要是指的DML时候多个value合并,减少和数据库交互
合理的分页,尤其大分页
UPDATE、DELETE语句不使用LIMIT ,容易造成主从不一致
数据库运维规范
运维规范主要内容
SQL审核,DDL审核和操作时间,尤其是OnlineDDL
高危操作检查,Drop前做好数据备份
权限控制和审计
日志分析,主要是指的MySQL慢日志和错误日志
高可用方案
数据备份方案
版本选择
MySQL社区版,用户群体最大
MySQL企业版,收费
Percona Server版,新特性多
MariaDB版,国内用户不多
建议选择优先级为:MySQL社区版 > Percona Server > MariaDB > MySQL 企业版,不过现在如果大家使用RDS服务,基本还以社区版为主。
Online DDL问题
原生MySQL执行DDL时需要锁表,且锁表期间业务是无法写入数据的,对服务影响很大,MySQL对这方面的支持是比较差的。大表做DDL对DBA来说是很痛苦的,相信很多人经历过。如何做到Online DDL呢,是不是就无解了呢?当然不是!
上面表格里提到的 Facebook OSC和5.6 OSC也是目前两种比较靠谱的方案
MySQL 5.6的OSC方案还是解决不了DDL的时候到从库延时的问题,所以现在建议使用Facebook OSC这种思路更优雅
下图是Facebook OSC的思路 
后来Percona公司根据Facebook OSC思路,用perl重写了一版,就是我们现在用得很多的pt-online-schema-change,软件本身非常成熟,支持目前主流版本。
使用pt-online-schema-change的优点有:
无阻塞写入
完善的条件检测和延时负载策略控制
值得一提的是,腾讯互娱的DBA在内部分支上也实现了Online DDL,之前测试过确实不错,速度快,原理是通过修改InnoDB存储格式来实现。
使用pt-online-schema-change的限制有:
改表时间会比较长(相比直接alter table改表)
修改的表需要有唯一键或主键
在同一端口上的并发修改不能太多
可用性
关于可用性,我们今天分享一种无缝切主库方案,可以用于日常切换,使用思路也比较简单
在正常条件下如何无缝去做主库切换,核心思路是让新主库和从库停在相同位置,主要依赖slave start until 语句,结合双主结构,考虑自增问题。
MySQL集群方案:
集群方案主要是如何组织MySQL实例的方案
主流方案核心依然采用的是MySQL原生的复制方案
原生主从同步肯定存在着性能和安全性问题
MySQL半同步复制:
现在也有一些理论上可用性更高的其它方案
Percona XtraDB Cluster(没有足够的把控力度,不建议上)
MySQL Cluster(有官方支持,不过实际用的不多) 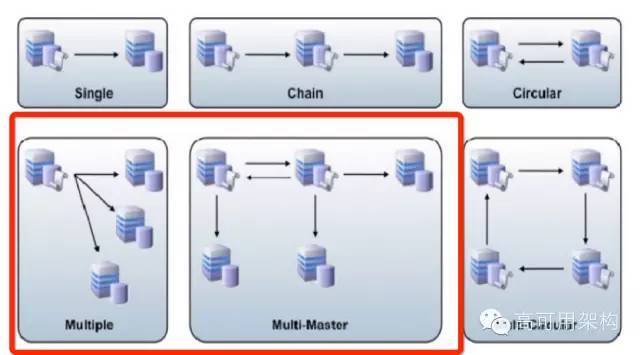
红框内是目前大家使用比较多的部署结构和方案。当然异常层面的HA也有很多第三方工具支持,比如MHA、MMM等,推荐使用MHA。
sharding拆分问题
Sharding is very complex, so itʼs best not to shard until itʼs obvious that you will actually need to!
sharding是按照一定规则数据重新分布的方式
主要解决单机写入压力过大和容量问题
主要有垂直拆分和水平拆分两种方式
拆分要适度,切勿过度拆分
有中间层控制拆分逻辑最好,否则拆分过细管理成本会很高
曾经管理的单表最大60亿+,单表数据文件大小1TB+,人有时候就要懒一些。 
上图是水平拆分和垂直拆分的示意图
数据库备份
首先要保证的,最核心的是数据库数据安全性。数据安全都保障不了的情况下谈其他的指标(如性能等),其实意义就不大了。
备份的意义是什么呢?
数据恢复!
数据恢复!
数据恢复!
目前备份方式的几个纬度:
全量备份 VS 增量备份
热备 VS 冷备
物理备份 VS 逻辑备份
延时备份
全量binlog备份
建议方式:
热备+物理备份
核心业务:延时备份+逻辑备份
全量binlog备份
借用一下某大型互联网公司做的备份系统数据:一年7000+次扩容,一年12+次数据恢复,日志量每天3TB,数据总量2PB,每天备份数据量百TB级,全年备份36万次,备份成功了99.9%。
主要做的几点:
备份策略集中式调度管理
xtrabackup热备
备份结果统计分析
备份数据一致性校验
采用分布式文件系统存储备份
备份系统采用分布式文件系统原因:
解决存储分配的问题
解决存储NFS备份效率低下问题
存储集中式管理
数据可靠性更好
使用分布式文件系统优化点:
Pbzip压缩,降低多副本存储带来的存储成本,降低网络带宽消耗
元数据节点HA,提高备份集群的可用性
erasure code方案调研
数据恢复方案
目前的MySQL数据恢复方案主要还是基于备份来恢复,可见备份的重要性。比如我今天下午15点删除了线上一张表,该如何恢复呢?首先确认删除语句,然后用备份扩容实例启动,假设备份时间点是凌晨3点,就还需要把凌晨3点到现在关于这个表的binlog导出来,然后应用到新扩容的实例上,确认好恢复的时间点,然后把删除表的数据导出来应用到线上。
性能优化
复制优化
MySQL复制:
是MySQL应用得最普遍的应用技术,扩展成本低
逻辑复制
单线程问题,从库延时问题
可以做备份或读复制
问题很多,但是能解决基本问题。
上图是MySQL复制原理图,红框内就是MySQL一直被人诟病的单线程问题。
单线程问题也是MySQL主从延时的一个重要原因,单线程解决方案:
官方5.6+多线程方案
Tungsten为代表的第三方并行复制工具
sharding 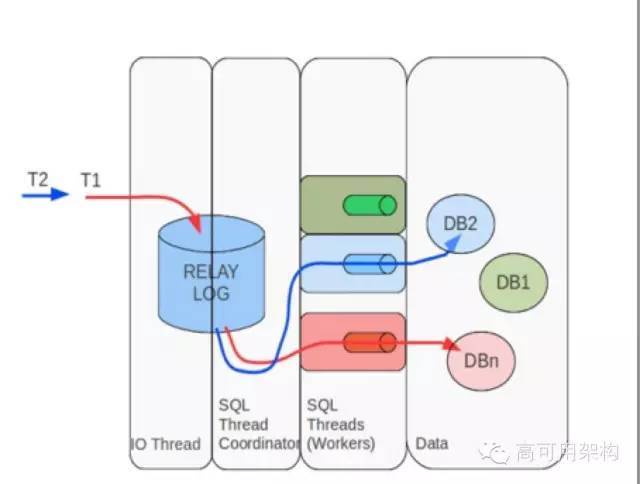
上图是MySQL5.6 目前实现的并行复制原理图,是基于库级别的复制,所以如果你只有一个库,使用这个意义不大。
当然MySQL也认识到5.6这种并行的瓶颈所在,所以在5.7引入了另外一种并行复制方式,基于logical timestamp的并行复制,并行复制不再受限于库的个数,效率会大大提升。 
上图是5.7的logical timestamp的复制原理图
刚才我也提到MySQL原来只支持异步复制,这种数据安全性是非常差的,所以后来引入了半同步复制,从5.5开始支持。 
上图是原生异步复制和半同步复制的区别。可以看到半同步通过从库返回ACK这种方式确认从库收到数据,数据安全性大大提高。
在5.7之后,半同步也可以配置你指定多个从库参与半同步复制,之前版本都是默认一个从库。
对于半同步复制效率问题有一个小的优化,就是使用5.6+的mysqlbinlog以daemon方式作为从库,同步效率会好很多。
关于更安全的复制,MySQL 5.7也是有方案的,方案名叫Group replication 官方多主方案,基于Corosync实现。 
主从延时问题
原因:一般都会做读写分离,其实从库压力反而比主库大/从库读写压力大非常容易导致延时。
解决方案:
首先定位延时瓶颈
如果是IO压力,可以通过升级硬件解决,比如替换SSD等
如果IO和CPU都不是瓶颈,非常有可能是SQL单线程问题,解决方案可以考虑刚才提到的并行复制方案
如果还有问题,可以考虑sharding拆分方案
提到延时不得不提到很坑人的Seconds behind master,使用过MySQL的应该很熟悉。
这个值的源码里算法
long time_diff= ((long)(time(0) – mi->rli.last_master_timestamp) – mi->clock_diff_with_master);
Secondsbehindmaster来判断延时不可靠,在网络抖动或者一些特殊参数配置情况下,会造成这个值是0但其实延时很大了。通过heartbeat表插入时间戳这种机制判断延时是更靠谱的
复制注意点:
Binlog格式,建议都采用row格式,数据一致性更好
Replication filter应用
主从数据一致性问题:
row格式下的数据恢复问题
InnoDB优化
成熟开源事务存储引擎,支持ACID,支持事务四个隔离级别,更好的数据安全性,高性能高并发,MVCC,细粒度锁,支持O_DIRECT。
主要优化参数:
innodbfileper_table =1
innodbbufferpool_size,根据数据量和内存合理设置
innodbflushlog_attrxcommit= 0 1 2
innodblogfile_size,可以设置大一些
innodbpagesize
Innodbflushmethod = o_direct
innodbundodirectory 放到高速设备(5.6+)
innodbbufferpool_dump
atshutdown ,bufferpool dump (5.6+) 
上图是5.5 4G的redo log和5.6 设置大于4G redo log文件性能对比,可以看到稳定性更好了。innodblogfile_size设置还是很有意义的。
InnoDB比较好的特性:
Bufferpool预热和动态调整大小,动态调整大小需要5.7支持
Page size自定义调整,适应目前硬件
InnoDB压缩,大大降低数据容量,一般可以压缩50%,节省存储空间和IO,用CPU换空间
Transportable tablespaces,迁移ibd文件,用于快速单表恢复
Memcached API,full text,GIS等
InnoDB在SSD上的优化:
在5.5以上,提高innodbwriteiothreads和innodbreadiothreads
innodbiocapacity需要调大*
日志文件和redo放到机械硬盘,undo放到SSD,建议这样,但必要性不大
atomic write,不需要Double Write Buffer
InnoDB压缩
单机多实例
也要搞清楚InnoDB哪些文件是顺序读写,哪些是随机读写。
随机读写:
datadir
innodbdata file_path
innodbundo directory
顺序读写:
innodbloggrouphomedir
log-bin
InnoDB VS MyISAM:
数据安全性至关重要,InnoDB完胜,曾经遇到过一次90G的MyISAM表repair,花了两天时间,如果在线上几乎不可忍受
并发度高
MySQL 5.5默认引擎改为InnoDB,标志着MyISAM时代的落幕
TokuDB:
支持事务 ACID 特性,支持多版本控制(MVCC)
基于Fractal Tree Index,非常适合写入密集场景
高压缩比,原生支持Online DDL
主流分支都支持,收费转开源 。目前可以和InnoDB媲美的存储引擎
目前主流使用TokuDB主要是看中了它的高压缩比,Tokudb有三种压缩方式:quicklz、zlib、lzma,压缩比依次更高。现在很多使用zabbix的后端数据表都采用的TokuDB,写入性能好,压缩比高。
下图是我之前做的测试对比和InnoDB 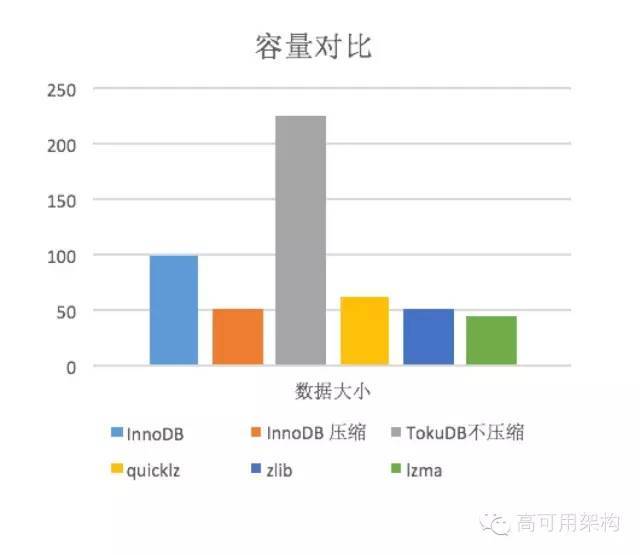

上图是sysbench测试的和InnoDB性能对比图,可以看到TokuDB在测试过程中写入稳定性是非常好的。
tokudb存在的问题:
官方分支还没很好的支持
热备方案问题,目前只有企业版才有
还是有bug的,版本更新比较快,不建议在核心业务上用
比如我们之前遇到过一个问题:TokuDB的内部状态显示上一次完成的checkpoint时间是“Jul 17 12:04:11 2014”,距离当时发现现在都快5个月了,结果堆积了大量redo log不能删除,后来只能重启实例,结果重启还花了七八个小时。
MySQL优化相关的case
Query cache,MySQL内置的查询加速缓存,理念是好的,但设计不够合理,有点out。
锁的粒度非常大MySQL 5.6默认已经关闭
When the query cache helps, it can help a lot. When it hurts, it can hurt a lot.明显前半句已经没有太大用处,在高并发下非常容易遇到瓶颈。
关于事务隔离级别 ,InnoDB默认隔离级别是可重复读级别,当然InnoDB虽然是设置的可重复读,但是也是解决了幻读的,建议改成读已提交级别,可以满足大多数场景需求,有利于更高的并发,修改transaction-isolation。 
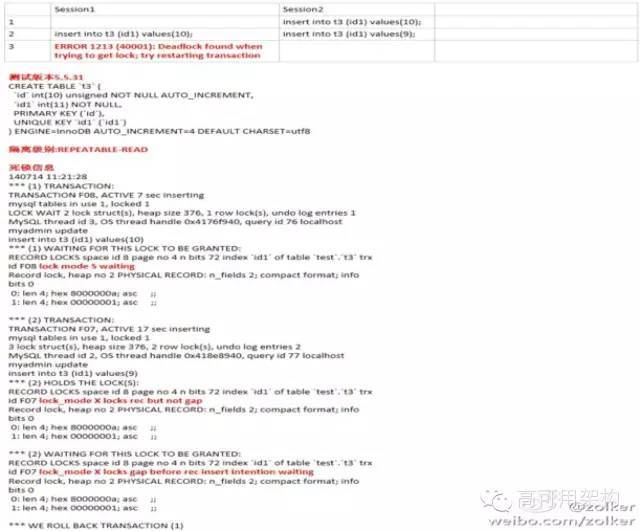
上图是一个比较经典的死锁case,有兴趣可以测试下。
关于SSD
关于SSD,还是提一下吧。某知名大V说过“最近10年对数据库性能影响最大的是闪存”,稳定性和性能可靠性已经得到大规模验证,多块SATA SSD做Raid5,推荐使用。采用PCIe SSD,主流云平台都提供SSD云硬盘支持。
最后说一下大家关注的单表60亿记录问题,表里数据也是线上比较核心的。
先说下当时情况,表结构比较简单,都是bigint这种整型,索引比较多,应该有2-3个,单表行数60亿+,单表容量1.2TB左右,当然内部肯定是有碎片的。
形成原因:历史遗留问题,按照我们前面讲的开发规范,这个应该早拆分了,当然不拆有几个原因:
性能未遇到瓶颈 ,主要原因
DBA比较“懒“
想看看InnoDB的极限,挑战一下。不过风险也是很大的,想想如果在一个1.2TB表上加个字段加个索引,那感觉绝对酸爽。还有就是单表恢复的问题,恢复时间不可控。
我们后续做的优化 ,采用了刚才提到的TokuDB,单表容量在InnoDB下1TB+,使用Tokudb的lzma压缩到80GB,压缩效果非常好。这样也解决了单表过大恢复时间问题,也支持online DDL,基本达到我们预期。
今天讲的主要针对MySQL本身优化和规范性质的东西,还有一些比较好的运维经验,希望大家能有所收获。今天这些内容是为后续数据库做平台化的基础。我今天分享就到这里,谢谢大家。
QA
Q1:use schema;select from table; 和select from schema.table;两种写法有什么不一样吗?会对主从同步有影响吗?
对于主从复制来说执行效率上差别不大,不过在使用replication filter时候这种情况需要小心,应该要使用ReplicateWildIgnoreTable这种参数,如果不使用带wildignore,第一种方式会有问题,过滤不起作用。
Q2:对于用于MySQL的ssd,测试方式和ssd的参数配置方面,有没有好的建议?主要针对ssd的配置哈
关于SATA SSD配置参数,建议使用Raid5,想更保险使用Raid50,更土豪使用Raid 10 
上图是主要的参数优化,性能提升最大的是第一个修改调度算法的
Q3:数据库规范已制定好,如何保证开发人员必须按照规范来开发?
关于数据库规范实施问题,也是有两个方面吧,第一、定期给开发培训开发规范,让开发能更了解。第二、还是在流程上规范,比如把我们日常通用的建表和字段策略固化到程序,做成自动化审核系统。这两方面结合 效果会比较好。
Q4:如何最大限度提高innodb的命中率?
这个问题前提是你的数据要有热点,读写热点要有交集,否则命中率很难提高。在有热点的前提下,也要求你的你的内存要足够大,能够存更多的热点数据。尽量不要做一些可能污染bufferpool的操作,比如全表扫描这种。
Q5:主从复制的情况下,如果有CAS这样的需求,是不是只能强制连主库?因为有延迟的存在,如果读写不在一起的话,会有脏数据。
如果有CAS需求,确实还是直接读主库好一些,因为异步复制还是会有延迟的。只要SQL优化的比较好,读写都在主库也是没什么问题的。
Q6:关于开发规范,是否有必要买国标?
这个国标是什么东西,不太了解。不过从字面看,国标应该也是偏学术方面的,在具体工程实施时候未必能用好。
Q7:主从集群能不能再细化一点那?不知道这样问合适不?
看具体哪方面吧。主从集群每个小集群一般都是采用一主多从方式,每个小集群对应特定的一组业务。然后监控备份和HA都是在每个小集群实现。
Q8:如何跟踪数据库table某个字段值发生变化?
追踪字段值变化可以通过分析row格式binlog好一些。比如以前同事就是通过自己开发的工具来解析row格式binlog,跟踪数据行变化。
Q9:对超大表水平拆分,在使用MySQL中间件方面有什么建议和经验分享?
对于超大表水平拆分,在中间件上经验不是很多,早期人肉搞过几次。也使用过自己研发的数据库中间件,不过线上应用的规模不大。关于目前众多的开源中间件里,360的atlas是目前还不错的,他们公司内部应用的比较多。
Q10:我们用的MySQL proxy做读负载,但是少量数据压力下并没有负载,请问有这回事吗?
少量数据压力下,并没有负载 ,这个没测试过,不好评价
Q11:对于binlog格式,为什么只推荐row,而不用网上大部分文章推荐的Mix ?
这个主要是考虑数据复制的可靠性,row更好。mixed含义是指如果有一些容易导致主从不一致的SQL ,比如包含UUID函数的这种,转换为row。既然要革命,就搞的彻底一些。这种mix的中间状态最坑人了。
Q12: 读写分离,一般是在程序里做,还是用proxy ,用proxy的话一般用哪个?
这个还是独立写程序好一些,与程序解耦方便后期维护。proxy国内目前开源的比较多,选择也要慎重。
Q13: 我想问一下关于mysql线程池相关的问题,什么情况下适合使用线程池,相关的参数应该如何配置,老师有这方面的最佳实践没有?
线程池这个我也没测试过。从原理上来说,短链接更适合用线程池方式,减少建立连接的消耗。这个方面的最佳配置,我还没测试过,后面测试有进展可以再聊聊。
Q14: 误删数据这种,数据恢复流程是怎么样的(从库也被同步删除的情况)?
看你删除数据的情况,如果只是一张表,单表在几GB或几十GB。如果能有延时备份,对于数据恢复速度是很有好处的。恢复流程可以参考我刚才分享的部分。目前的MySQL数据恢复方案主要还是基于备份来恢复 ,可见备份的重要性。比如我今天下午15点删除了线上一张表,该如何恢复呢。首先确认删除语句,然后用备份扩容实例启动,假设备份时间点是凌晨3点。就还需要把凌晨3点到现在关于这个表的binlog导出来,然后应用到新扩容的实例上。确认好恢复的时间点,然后把删除表的数据导出来应用到线上。
Q15: 关于备份,binlog备份自然不用说了,物理备份有很多方式,有没有推荐的一种,逻辑备份在量大的时候恢复速度比较慢,一般用在什么场景?
物理备份采用xtrabackup热备方案比较好。逻辑备份一般用在单表恢复效果会非常好。比如你删了一个2G表,但你总数据量2T,用物理备份就会要慢了,逻辑备份就非常有用了。
大家可以点击加入群:478052716【JAVA高级程序员】里面有Java高级大牛直播讲解知识点走的就是高端路线(如果你想跳槽换工作但是技术又不够或者工作上遇到了瓶颈我这里有一个JAVA的免费直播课程讲的是高端的知识点基础不好的误入哟 只要你有1-5年的开发经验可以加群找我要课堂链接注意:是免费的 没有开发经验误入哦)