基于python的简单爬虫开发(附源码,完整套餐)
本文参考IMMOC中的python”开发简单爬虫“:https://www.imooc.com/video/10674。如果不足,希望指正
本文为原创,转载请注明出处:https://blog.csdn.net/yg970514/article/details/80135779
GIT源码地址:https://github.com/solor-yang/Rain
环境:
操作系统:win10
语言:python3.6.5
文本编辑器:eclipse\pydev
爬虫:一段自动抓取互联网信息的程序
价值:互联网数据,为我所用!
爬虫步骤:
·简单爬虫架构
`URL管理器
·网页下载器,urllib2
·网页解析器,BeautifulSoup
·实战编写爬取百度百科页面
·这只是最简单的爬虫!
——需登录、验证码、Ajax、服务器防爬虫、多线程、分布式
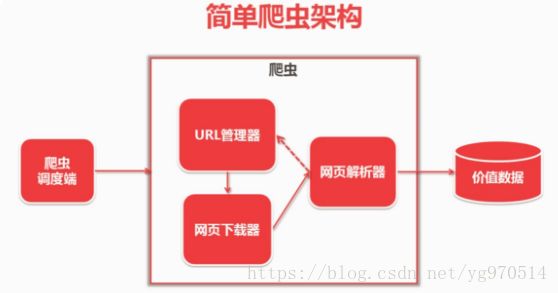
简单爬虫架构:
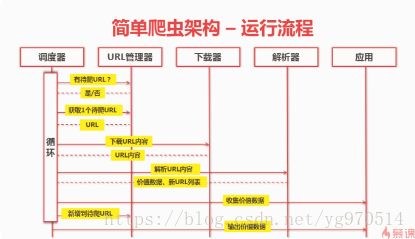
运行流程:
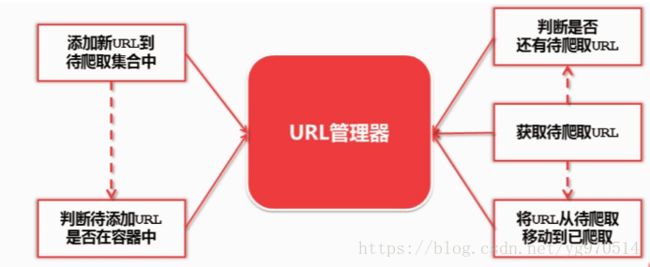
URL管理器:管理待抓取URL集合和已抓取URL集合
作用:防止重复抓取、防止循环抓取
网页下载器:
将互联网上URL对应的网页下载到本地的工具

python:
python有哪几种网页下载器?(我们已urllib2为例)
URLlib2下载网页方法0:最简洁方法
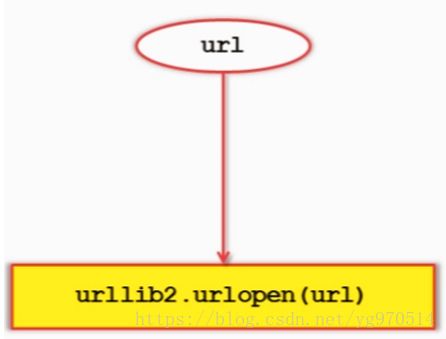
urllib2下载网页方法2:添加data、http header
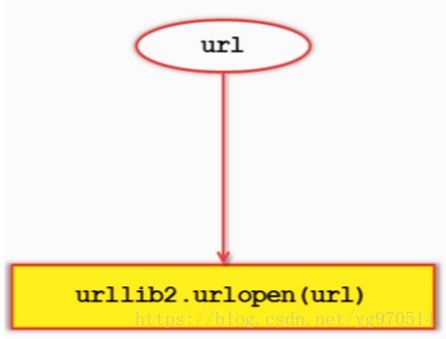
urllib2下载网页方法3:添加特殊情景的处理器

网页解析器:
从网页中提取出有价值数据的工具
python有哪几种网页解析器:

结构化解析-DOM:
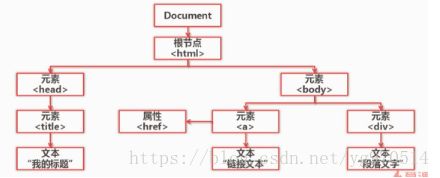
beautiful Soup-语法

ex:(href:超链接)

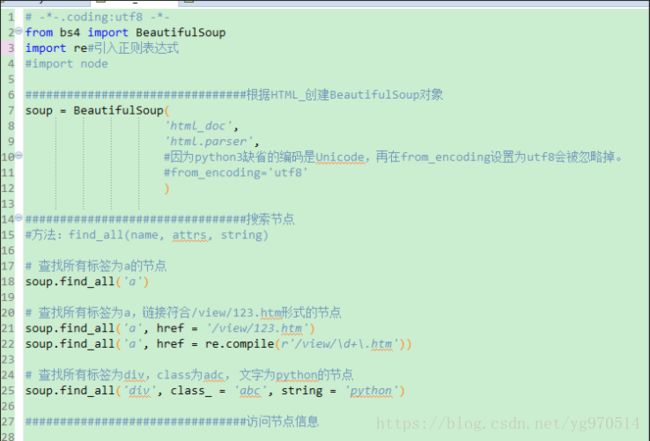
实力爬虫:

注解:
pip安装时,需要在python安装目录下的scripts进行(ex: pip install beautifulsoup4)