CS224N笔记(十):问答系统
公众号关注 “ML_NLP”
设为 “星标”,重磅干货,第一时间送达!

来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/67214500
作者 | 川陀学者
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
问答系统(Question Answering)实际需求很多,比如我们常用的谷歌搜索就可看做是问答系统。通常我们可以将问答系统看做两部分:从海量的文件中,找到与问题相关的可能包含回答的文件,这一过程是传统的information retrieval;从文件或段落中找到相关的答案,这一过程也被称作Reading Comprehension阅读理解,也是这一讲关注的重点。
SQuAD

Stanford Attentive Reader
接下来讲的是Manning组的关于QA的模型Stanford Attentive Reader。
其思路是对于Question,先利用Bidirectional LSTM提取其特征向量。

再对Passage中的每个单词进行Bidirectional LSTM提取其特征向量, 并对每个单词对应的特征向量与问题的特征向量进行Attention操作,分别得到推测答案起始位置与终止位置的attention score,损失函数为![]() 。
。

之后还在该模型基础上进行了改进:
-
对于question部分,不仅仅是LSTM最后的输出,而是用了类似于self-attention的weighted sum来表示,并且增多了BiLSTM的层数。
-
对于passage的encoding,除了利用Glove得到的word embedding之外,还加入了一些语言学的特征,如POS(part of speech)和NER(named entity recognition) tag以及term frequency。另外还加入了比较简单的特征如段落中单词是否出现在问题中的binary feature,对于这种match,又分为三种即exact match, uncased match(不区分大小写), lemma match(如drive和driving)。更进一步,还引入了aligned question embedding, 与exact match相比,这可以看做是对于相似却不完全相同的单词(如car与vehicle)的soft alignment
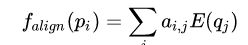 ,其中aij代表了段落中单词pi与问题中单词 的相似度。
,其中aij代表了段落中单词pi与问题中单词 的相似度。

BiDAF
另一个比较重要的QA模型是BiDAF(Bi-Directional Attention Flow),其模型结构如下。
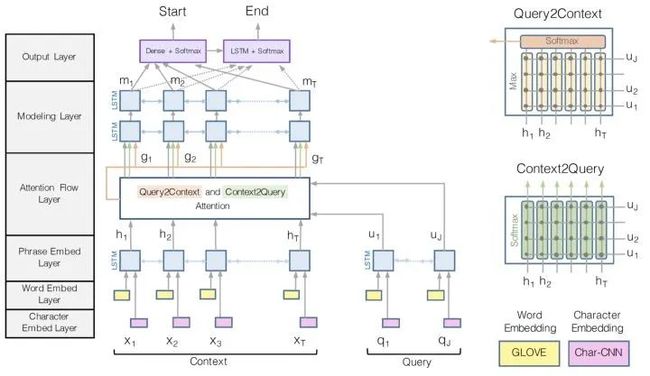
其核心思想是Attention应该是双向的,既有从Context(即passage)到Query(即Question)的attention,又有从Query到Context的attention。
首先计算similarity matrix

其中ci, qj分别代表context vector与query vector。
对于Context2Query Attention,我们想要知道对于每个context word,哪些query word比较重要,因此得到attention score及weighted vector:

而对于Query2Context Attention,我们想要知道对于query,哪些context words与任意一个query words相似度较高,我们得到对于query来说最关键的context words的加权求和:

由此,我们得到了Attention Flow Layer 的输出
![]()
再对其进行多层LSTM与Softmax得到相应的输出。
更近期的发展基本上是更复杂的结构以及attention的各种结合。对于embedding的提取方面,也更多采用contextual embedding,收到了很好的效果,关于contextual embedding如Elmo,BERT等会在第13讲详细讲解。
参考资料
第十讲讲义web.stanford.edu/class/
补充材料web.stanford.edu/class/
第十讲视频youtu.be/yIdF-17HwSk
论文
A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task
Reading Wikipedia to Answer Open-Domain Questions
Bidirectional Attention Flow for Machine Comprehension
重磅!忆臻自然语言处理-学术微信交流群已成立
可以扫描下方二维码,小助手将会邀请您入群交流,
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!

推荐阅读:
PyTorch Cookbook(常用代码段整理合集)
通俗易懂!使用Excel和TF实现Transformer!
深度学习中的多任务学习(Multi-task-learning)——keras实现
