多变量线性回归模型——梯度下降法、随机梯度下降法之python实战
这篇文章主要讲述在多变量线性回归模型中运用梯度下降法与随机梯度下降法解决问题的方法。有关于梯度下降法的数学推导不做讲述的重点。在这篇文章里,我们将对一个包含50个样本的数据集使用多变量回归模型进行处理,通过实操来加深对梯度下降法的理解。
一、语言和IDE
python3.7 + pycharm
二、问题陈述
给定一个名为“dataForTraining.txt”的文件。该文件包含广东省广州市海珠区的房价信息,里面包含50个训练样本数据。文件有三列,第一列对应房的面积(单位:平方米),第二列对应房子距离双鸭山职业技术学院的距离(单位:千米),第三列对应房子的销售价格(单位:万元)。每一行对应一个训练样本。请使用提供的50个训练样本来训练多变量回归模型以便进行房价预测,请用(随机)梯度下降法的多变量线性回归模型进行建模。为了评估训练效果,另外给定测试数据集“dataForTesting.txt” (该测试文件里的数据跟训练样本具有相同的格式,即第一列对应房子面积,第二列对应距离,第三列对应房子总价)。
三、问题求解
A、梯度下降法
使用多变量线性回归模型求解,假设函数为
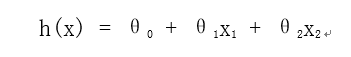
模型参数为3个。初始条件下,theta、theta1、theta2均设定为0,学习率设定为0.00015。使用梯度下降的方法进行训练,对theta0、theta1、theta2进行迭代,迭代规则如下:

误差计算公式如下:

迭代结果如下:
曲线图:

数据记录:
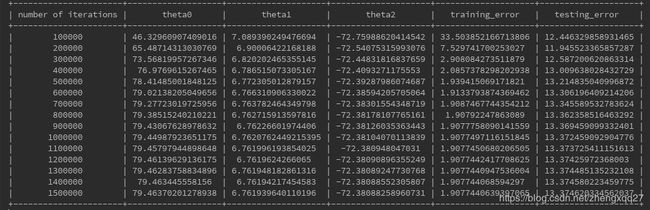
由以上结果可看到梯度下降法的效果很好,训练误差不断收敛,测试误差也保持一个较小的稳定值。
python源码
1. import numpy as np
2. import matplotlib.pyplot as plt
3. from prettytable import PrettyTable
4.
5.
6. def list_to_matrix(filename): # 这个函数将txt文件中的数据读取出来,存进一个matrix中
7. np.set_printoptions(suppress=True) # 使输出不为科学计数法形式
8. fr = open(filename)
9. arrayOLines = fr.readlines()
10. numberOFLines = len(arrayOLines) # 获取此list的行数
11. returnMat = np.zeros((numberOFLines, 3)) # 返回的矩阵是numberOFLines * 3 的
12. index = 0
13. for line in arrayOLines:
14. line = line.strip() # 移除每一行结尾的最后符号,即'\n'符;
15. listFromLine = line.split(' ') # 移除每一行中出现的' '符;
16. returnMat[index, :] = listFromLine[0:3]
17. index += 1
18. return returnMat
19.
20.
21. def gradient_descent():
22. alpha = 0.00015 # 设定学习率
23. theta0 = 0.0 # 初始化参数1为0.0
24. theta1 = 0.0 # 初始化参数2为0.0
25. theta2 = 0.0 # 初始化参数3位0.0
26. Mat = list_to_matrix('dataForTraining.txt') # 读取txt训练集,存放在matrix中
27. testing_mat = list_to_matrix('dataForTesting.txt') # 读取txt测试集,存放在matrix中
28.
29. result_table = PrettyTable(["number of iterations", "theta0",
30. "theta1", "theta2", "training_error", "testing_error"])
31. training_error_arr = []
32. iter_times_arr = []
33. testing_error_arr = []
34. m = len(Mat)
35. n = len(testing_mat)
36. count = 1
37. for j in range(1500000): # 迭代1500000次
38. sum_0 = 0
39. sum_1 = 0
40. sum_2 = 0
41. for i in range(m): # 根据迭代规则更新参数
42. hx = theta0 + theta1*Mat[i][0] + theta2*Mat[i][1]
43. diff = Mat[i][2] - hx #标记1:这里的正负号反了
44. sum_0 += diff * 1
45. sum_1 += diff * Mat[i][0] # 这个数值有可能会特别大
46. sum_2 += diff * Mat[i][1]
47. theta0 = theta0 + alpha * (1/m) * sum_0 #根据迭代规则更新theta0,注意由于标记1处的正负号反了,这里应用加号而不是减号
48. theta1 = theta1 + alpha * (1/m) * sum_1
49. theta2 = theta2 + alpha * (1/m) * sum_2
50.
51. if j % 99999 == 0 and j >= 99999: # 当迭代次数为100000的整数倍时,计算训练误差和测试误差
52. iter_times_arr.append(j+count)
53. temp = 0
54. testing_temp = 0
55. for i in range(m): #计算训练误差
56. Hx = theta0 + theta1*Mat[i][0] + theta2*Mat[i][1]
57. temp += np.square(Hx-Mat[i][2])
58. training_error = 0.5 * (1/m) * temp
59. training_error_arr.append(training_error)
60.
61. for t in range(n): #计算测试误差
62. Hx = theta0 + theta1*testing_mat[t][0] + theta2*testing_mat[t][1]
63. testing_temp += np.square(Hx-testing_mat[t][2])
64. testing_error = 0.5 * (1/m) * testing_temp
65. testing_error_arr.append(testing_error)
66.
67. result_table.add_row([j+count, theta0, theta1, theta2, training_error, testing_error])
68. count += 1
69.
70. print(result_table)
71. plt.figure()
72. plt.plot(iter_times_arr, training_error_arr, 'x-', c='b', linewidth=1, label="training error")
73. plt.plot(iter_times_arr, testing_error_arr, '+-', c='r', linewidth=1, label="testing error")
74. plt.xlabel("iteration times") # X轴标签
75. plt.ylabel("error") # Y轴标签
76. plt.legend() # 显示图例
77. plt.show()
78.
79.
80. gradient_descent()
在梯度下降法中,参数theta的初始值一般都设定为0,学习率根据不同的情况设定不同的值。接下来我们尝试改变学习率为0.0002,结果如下:

可以看到结果为nan。nan为无法表示(涉及无穷),这里我们猜测是因为梯度下降没有收敛;尝试将迭代次数缩小10倍,结果如下:
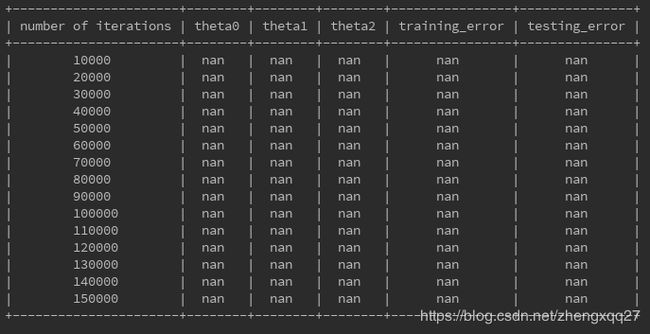
可以看到结果仍然是nan。这个时候我开始怀疑不收敛的原因是因为初始数据不够好,所以采取一种措施:数据预处理,将给出的数据归一化,使其分布在0-1范围内,结果如下:
曲线图:
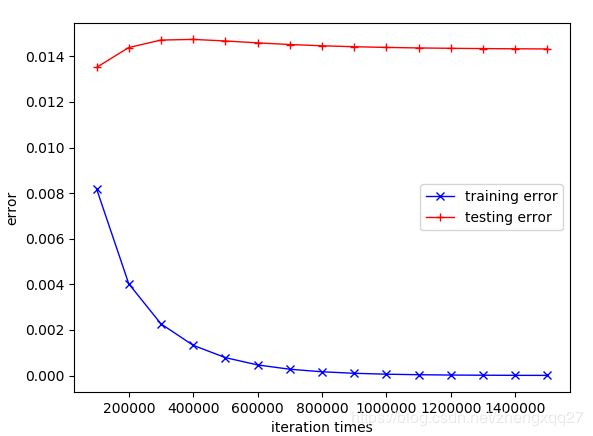
数据记录:

可以看到此时梯度下降法在训练集中很明显是收敛的,训练误差不断减少。在测试集中测试误差保持一定的数值变化不大(差不多稳定在0.014左右),此种误差我们可认为是比较精确的,因此在对数据进行归一化处理之后,梯度下降法同样适用于学习率为0.0002的情况。
归一化处理的代码如下(其他代码与上面的代码相同):
1. Mat = list_to_matrix('dataForTraining.txt') # 读取txt训练集,存放在matrix中
2. testing_mat = list_to_matrix('dataForTesting.txt') # 读取txt测试集,存放在matrix中
3. m = len(Mat)
4. n = len(testing_mat)
5. training_col_max_arr = np.max(Mat, axis=0) # 找出训练集中每个feature的最大值
6. testing_col_max_arr = np.max(testing_mat, axis=0) # 找出测试集中每个feature的最大值
7. print(testing_col_max_arr)
8. for t in range(m): # 特征缩放,归一化
9. Mat[t][0] = Mat[t][0] / training_col_max_arr[0]
10. Mat[t][1] = Mat[t][1] / training_col_max_arr[1]
11. Mat[t][2] = Mat[t][2] / training_col_max_arr[2]
12. for t in range(n): # 特征缩放,归一化
13. testing_mat[t][0] = testing_mat[t][0] / testing_col_max_arr[0]
14. testing_mat[t][1] = testing_mat[t][1] / testing_col_max_arr[1]
testing_mat[t][2] = testing_mat[t][2] / testing_col_max_arr[2]
B、随机梯度下降法
随机梯度下降法的大体步骤和梯度下降法其实是一样的,唯一不同的地方是随机梯度下降法在更新θ的时候,并不使用所有样本的数据进行计算,而是随机选取其中一个样本的数据来更新θ。使用随机梯度下降法的结果如下(这里使用的迭代次数仍是1500000次,每隔100000次迭代计算一次误差):
曲线图:
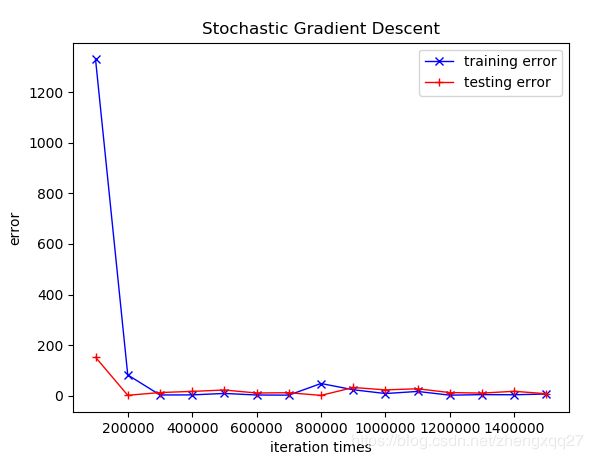
数据记录:
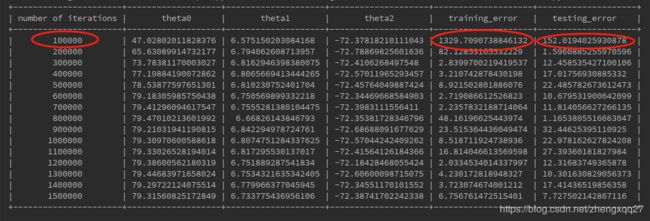
可以看到随机梯度下降法最后也获得了和梯度下降法几乎一样的结果,但是有一点值得注意的是,观察上图中使用随机梯度下降法迭代100000次之后的结果,训练误差为1329,测试误差为152;比起使用梯度下降法迭代100000次时误差要大得多,这是因为随机梯度下降每次更新参数用的都是一个随机样本的值,存在一定的随机性,因而可能其收敛速度不像梯度下降法那般快,但是当迭代次数足够多时,随机梯度下降法一般都能够获得和梯度下降法一样好的结果,这在这个例子中就体现地极为明显。并且,使用随机梯度下降法的计算量仅为梯度下降法的1/m,大大减少了计算量,因此随机梯度下降法是一个很有用的方法。
python源码
1. import numpy as np
2. import matplotlib.pyplot as plt
3. from prettytable import PrettyTable
4. import random
5.
6.
7. def list_to_matrix(filename): # 这个函数将txt文件中的数据读取出来,存进一个matrix中
8. np.set_printoptions(suppress=True) # 使输出不为科学计数法形式
9. fr = open(filename)
10. arrayOLines = fr.readlines()
11. numberOFLines = len(arrayOLines) # 获取此list的行数
12. returnMat = np.zeros((numberOFLines, 3)) # 返回的矩阵是numberOFLines * 3 的
13. index = 0
14. for line in arrayOLines:
15. line = line.strip() # 移除每一行结尾的最后符号,即'\n'符;
16. listFromLine = line.split(' ') # 移除每一行中出现的' '符;
17. returnMat[index, :] = listFromLine[0:3]
18. index += 1
19. return returnMat
20.
21.
22. def gradient_descent():
23. alpha = 0.00015 # 设定学习率
24. theta0 = 0.0 # 初始化参数1为0.0
25. theta1 = 0.0 # 初始化参数2为0.0
26. theta2 = 0.0 # 初始化参数3位0.0
27. Mat = list_to_matrix('dataForTraining.txt') # 读取txt训练集,存放在matrix中
28. testing_mat = list_to_matrix('dataForTesting.txt') # 读取txt测试集,存放在matrix中
29.
30. result_table = PrettyTable(["number of iterations", "theta0",
31. "theta1", "theta2", "training_error", "testing_error"])
32. training_error_arr = []
33. iter_times_arr = []
34. testing_error_arr = []
35. m = len(Mat)
36. n = len(testing_mat)
37. count = 1
38. for j in range(1500000): # 迭代1500000次
39. index = random.randint(0, m-1) # 随机选取一个样本进行梯度下降
40. hx = theta0 + theta1 * Mat[index][0] + theta2 * Mat[index][1]
41. theta0 = theta0 - alpha * (hx - Mat[index][2]) * 1 # 标记1的符号是反的所以这里的减要变成加
42. theta1 = theta1 - alpha * (hx - Mat[index][2]) * Mat[index][0]
43. theta2 = theta2 - alpha * (hx - Mat[index][2]) * Mat[index][1]
44.
45. if j % 99999 == 0 and j >= 99999: # 当迭代次数为100000的整数倍时,计算训练误差和测试误差
46. iter_times_arr.append(j + count)
47. temp = 0
48. testing_temp = 0
49. for i in range(m):
50. Hx = theta0 + theta1 * Mat[i][0] + theta2 * Mat[i][1]
51. temp += np.square(Hx - Mat[i][2])
52. training_error = 0.5 * (1 / m) * temp
53. training_error_arr.append(training_error)
54.
55. for t in range(n):
56. Hx = theta0 + theta1 * testing_mat[t][0] + theta2 * testing_mat[t][1]
57. testing_temp += np.square(Hx - testing_mat[t][2])
58. testing_error = 0.5 * (1 / m) * testing_temp
59. testing_error_arr.append(testing_error)
60.
61. result_table.add_row([j + count, theta0, theta1, theta2, training_error, testing_error])
62. count += 1
63.
64. print(result_table)
65. plt.figure()
66. plt.plot(iter_times_arr, training_error_arr, 'x-', c='b', linewidth=1, label="training error")
67. plt.plot(iter_times_arr, testing_error_arr, '+-', c='r', linewidth=1, label="testing error")
68. plt.xlabel("iteration times") # X轴标签
69. plt.ylabel("error") # Y轴标签
70. plt.legend() # 显示图例
71. plt.title("Stochastic Gradient Descent")
72. plt.show()
73.
74.
75. gradient_descent()
四、结尾
数据集获取